为什么要持久化?在不考虑服务器宕机的情况下,是不需要把内存中的数据保存到磁盘,来做持久化的。
持久化,就是专门为宕机准备的补救措施。redis有rdb和aof两种持久化机制。
原理:
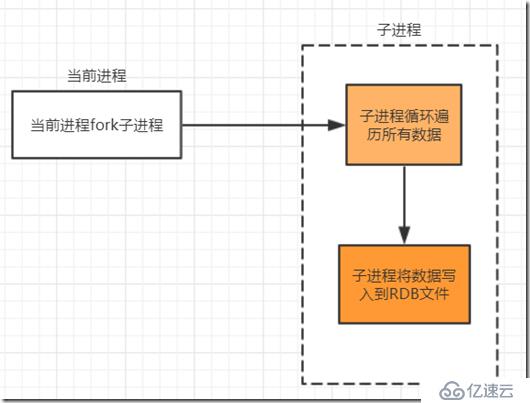
当前进程fork出一个子进程,子进程循环遍历所有的数据,并将数据保存到RDB文件。
时机:
按照配置文件设置的策略,来持久化数据。
配置:
save 900 1
save 300 10
save 60 10000
原理:
redis会将收到的,客户端发送过来的每一个写命令,都追加到aof文件的最后。
时机:
每次写命令,都会记录下操作。
配置:
appendonly yes
#默认不需要修改,最低64m开始重排,重排比率是上次的一倍,128m,256m,512m这样。
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
持久化:
RDB等待写入条件,频率低,如果一次写入的数据较多,有可能带来服务器卡顿。
AOF马上记录每次写命令,频率高,每次写入的数据很少;生成的文件会比RDB生成的大。
AOF记录数据更及时,丢数据的可能更小。
数据恢复:
RDB恢复数据时,直接从RDB文件读取数据,非常快速。
AOF恢复数据时,需要一条一条命令,操作redis服务器,效率较低。
aof的指令为什么需要重排:
set aa 1
set aa 2
set aa 3
三条指令,其实只需要保存最后一条就可以了,指令重排的意义就是,将三条变成一条set aa 3。
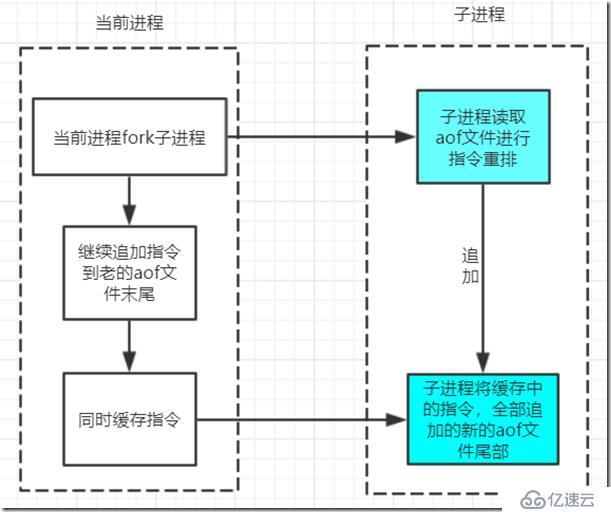
当前进程fork出一个子进程,由子进程完成指令重排。
需要注意的是,在子进程进行指令重排的过程中,如果出现新的指令,主进程做两件事情:
1.将指令追加到老的aof文件末尾;
2.将指令保存到缓存中。缓存中的数据,在子进程完成指令重排之后,全部追加到新的aof文件尾部。
经过上面的分析,我们已经知道rdb和aof各自的优势和缺点。可以根据具体的业务场景,选择合适的方式。
当然,同时使用两种方式也是可以的。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。