整个事件的起源还要从笔者最近入职了一家区块链金融公司来说起(为了保密性,不便透露公司名字),公司业务发展比较迅猛,突破百万用户也是近在眼前。整个系统都在阿里云上运行,每天都能看到用户的不断增长,即兴奋又担忧,为什么这么说呢?
由于笔者过来的时候这里业务就已经上线了,系统接过来之后,快速了解了所有的应用服务都是在docker swarm跑起来的,也包括mysql数据库,以至于笔者就有了迁库的想法,按照这种用户量发展下去,mysql在容器中运行用不了多久肯定会撑不住。
笔者就开始隐隐的担忧起来,毕竟不想每天提心吊胆的做运维。所以立马重新规划了新的方案和大家一起探讨,最终总监和相关技术负责人都敲定用RDS做为数据库新的方案,周星驰的功夫中也说道过:“天下武功,唯快不破”。就立马开始动身干起来。
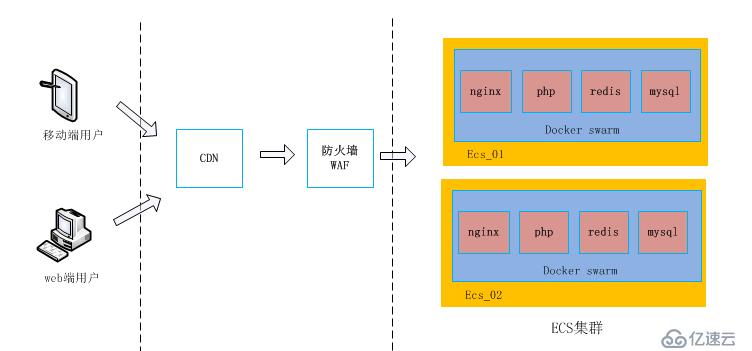
1、从入口层(CDN)---> 到安全层(WAF) ---> 最后到达应用层 (ECS集群);
2、Docker Swarm打通了ECS集群中的每台服务器,在每台ECS宿主机安装Docker engine并部署了公司需要的应用服务和数据库(nginx、php、redis、mysql等);
3、mysql容器通过宿主机的本地(目录)挂载到容器中实现数据持久化;
4、业务项目以php为主,php也是运行在容器中,通过php指定的配置文件连接到mysql容器中。
笔者就随便展示一下其中一个库的yaml文件,比较简单:
version: "3"
services:
ussbao:
# replace username/repo:tag with your name and image details
image: 隐藏此镜像信息
deploy:
replicas: 1
restart_policy:
condition: on-failure
environment:
MYSQL_ROOT_PASSWORD: 隐藏此信息
volumes:
- "/data//mysql/db1/:/var/lib/mysql/"
- "/etc/localtime:/etc/localtime"
- "/etc/timezone:/etc/timezone"
networks:
default:
external:
name: 隐藏此信息从上面的信息可以看出来,每个库只运行了一个mysql容器,并没有主从或读写分离的方案。而且也没有对数据库进行做任何优化,数据库这样跑下去让笔者很担忧,正常来说,都会把数据库独立部署运行。
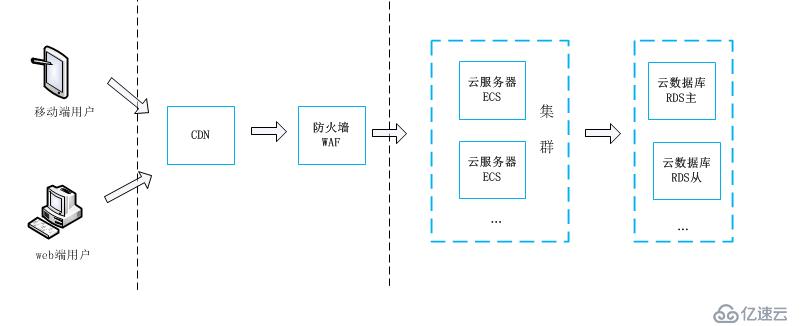
从上图可以看出来,笔者只是把mysql独立出来了,开通RDS实例来跑数据库,当然还开通了其它的一些服务(比如oss、云redis等),这些不是本文的重点,就没有画出来。nginx和php服务还是在docker swarm中运行。本文只是对迁移后出了问题的库进行分享,下面来看看迁移的方案吧。
开通RDS实例 ---> 备份sql ----> 导入到RDS ---> 修改数据库配置文件 --->测试验证
1、根据业务量规划开通RDS实例,创建数据库和用户;
2、提前做好RDS白名单,添加允许访问RDS的IP地址;
3、mysqldump 备份docker 中的mysql;
4、把备份好的.sql文件导入到RDS中;
5、修改php项目的数据库配置文件;
6、清空php项目的缓存文件或目录;
7、测试验证;
8、RDS定时备份;
具体迁移细节就不展示了,笔者是在夜深人静的时候进行迁移操作的,确定大半夜没人访问我们的APP和网站了才开干的。
我们的业务情况还有点像股市,我们是晚上12点不许操作和交易,第2天早上9点开盘,9点钟是并发的高峰期,就像朝阳大悦城上午开门一样,大批的顾客同时并发过来了。
所以那天晚上在12点15分准时开干,按计划和提前准备的配置、命令、脚本进行操作的。把docker 中运行的mysql迁移到RDS上非常顺利,好几个库迁移不到半个小时就结束了,并且把网站和APP的流程都跑了一遍,也都是妥妥的,最终把提前准备好备份脚本放在crontab中定时执行,可以来看下脚本内容:
#!/bin/bash
#数据库IP
dbserver='*******'
#数据库用户名
dbuser='ganbing'
#数据库密码
dbpasswd='************'
#备份数据库,多个库用空格隔开
dbname='db1 db2 db3'
#备份时间
backtime=`date +%Y%m%d%H%M`
out_time=`date +%Y%m%d%H%M%S`
#备份输出路径
backpath='/data/backup/mysql/'
logpath=''/data/backup/logs/'
echo "################## ${backtime} #############################"
echo "开始备份"
#日志记录头部
echo "" >> ${logpath}/${dbname}_back.log
echo "-------------------------------------------------" >> ${logpath}/${dbname}_back.log
echo "备份时间为${backtime},备份数据库 ${dbname} 开始" >> ${logpath}/${dbname}_back.log
#正式备份数据库
for DB in $dbname; do
source=`/usr/bin/mysqldump -h ${dbserver} -u ${dbuser} -p${dbpasswd} ${DB} > ${backpath}/${DB}-${out_time}.sql` 2>> ${backpath}/mysqlback.log;
#备份成功以下操作
if [ "$?" == 0 ];then
cd $backpath
#为节约硬盘空间,将数据库压缩
tar zcf ${DB}-${backtime}.tar.gz ${DB}-${backtime}.sql > /dev/null
#删除原始文件,只留压缩后文件
rm -f ${DB}-${backtime}.sql
#删除15天前备份,也就是只保存15天内的备份
find $backpath -name "*.tar.gz" -type f -mtime +15 -exec rm -rf {} \; > /dev/null 2>&1
echo "数据库 ${dbname} 备份成功!!" >> ${logpath}/${dbname}_back.log
else
#备份失败则进行以下操作
echo "数据库 ${dbname} 备份失败!!" >> ${logpath}/${dbname}_back.log
fi
done
echo "完成备份"
echo "################## ${backtime} #############################"到了1点钟,确定没问题后发通知到群里,发微信给领导表示已迁移完成,进行很顺利,然后笔者打车回家,睡觉。
其实这一晚笔者睡得也不踏实,到了8点半就醒了,因为我们9点钟开盘,会有大量的客户涌进,每天开始产生新的交易(买入和卖出),给大家看下截图:
果不其然,9点过后,笔者打开APP,一切正常,点击切换几个界面后,发现其中一个功能的请求超时了,一直在转,然后紧接着其它功能也超时了。完了,出问题了。赶紧开笔记本查问题,过了一会儿群里就开始沸腾了(反映好多客户打开APP都显示请求超时了),我的电话也立马响了,技术总监打来的,问我怎么回事,我说正在开笔记本排查。
这个时候,我要说明一下:运维人员此时需要冷静并且安静的处理问题,公司领导千万别催得太急以免打乱处理人的思路。我们总监临场处理能力做得真是非常到位,马上跟我说不用担心上面压力,有他扛着,叫我只管排查和解决问题。
笔记本打开后,首先想到的就是RDS数据库出了问题,登录阿里云,进入RDS中的DMS数据管理控制台,一进去就傻眼了 “CPU爆了”,这么多连接数,如下图: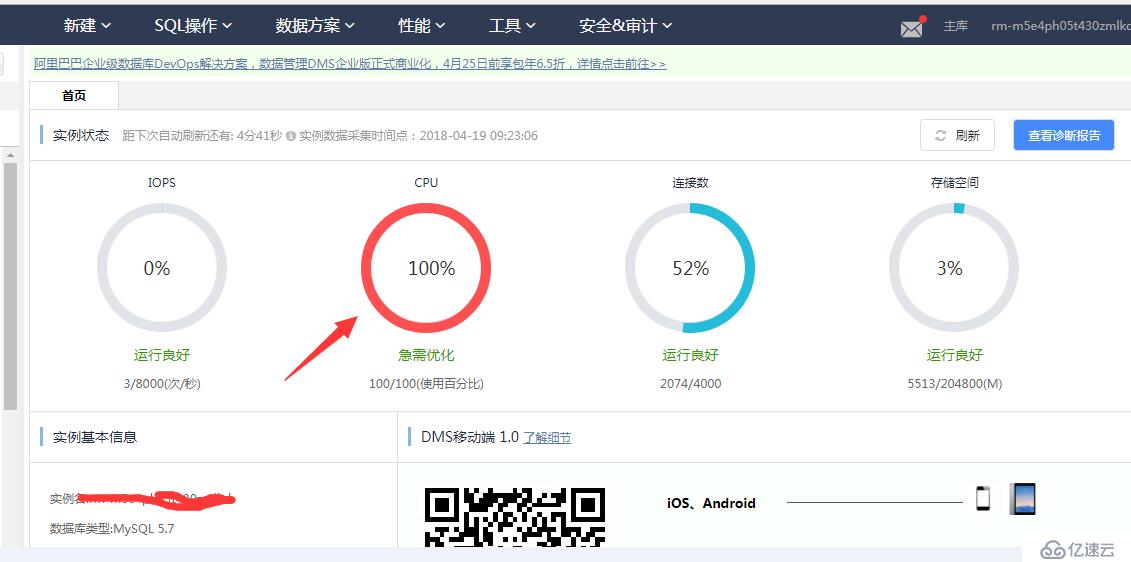
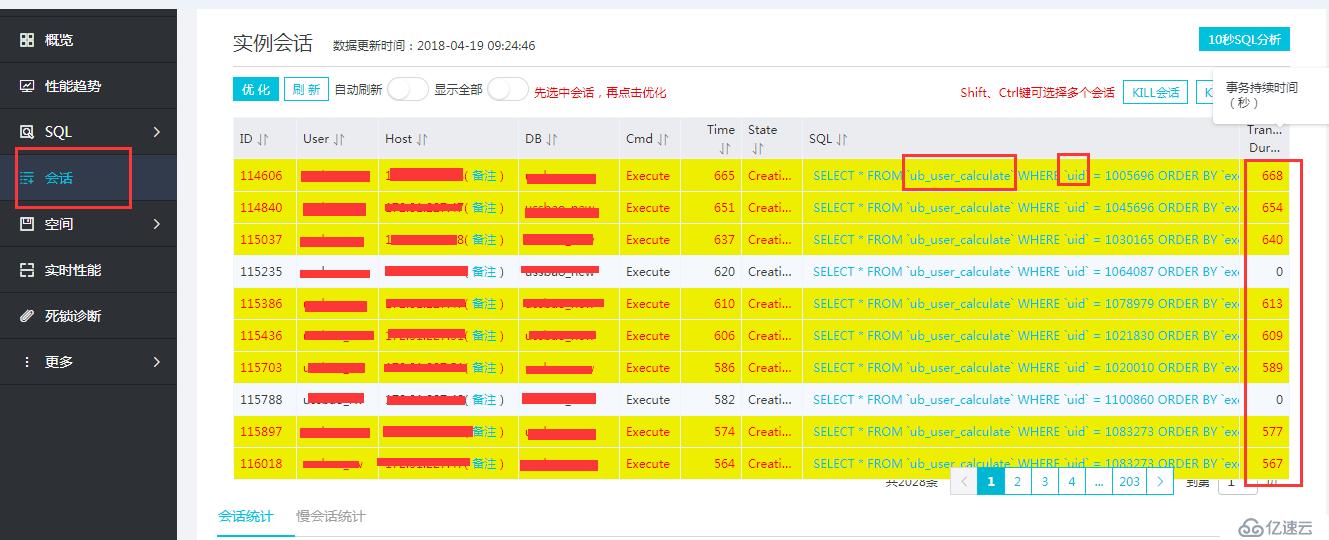
进入会话去看看,发现会话“炸锅了”,发现几百页的select都挤在ub_user_calculate这个表中,这个表是数据量相对大一些,这张表目前有200多万条数据:
![]
自然反应就是去查看此表的结构,发现此表没有索引,被惊讶到了,竟然没有索引,这...... 然后笔者返回源数据库查看这张表,也发现没有索引,由此可以确定我导过来的这张表就是没有创建索引,如下图: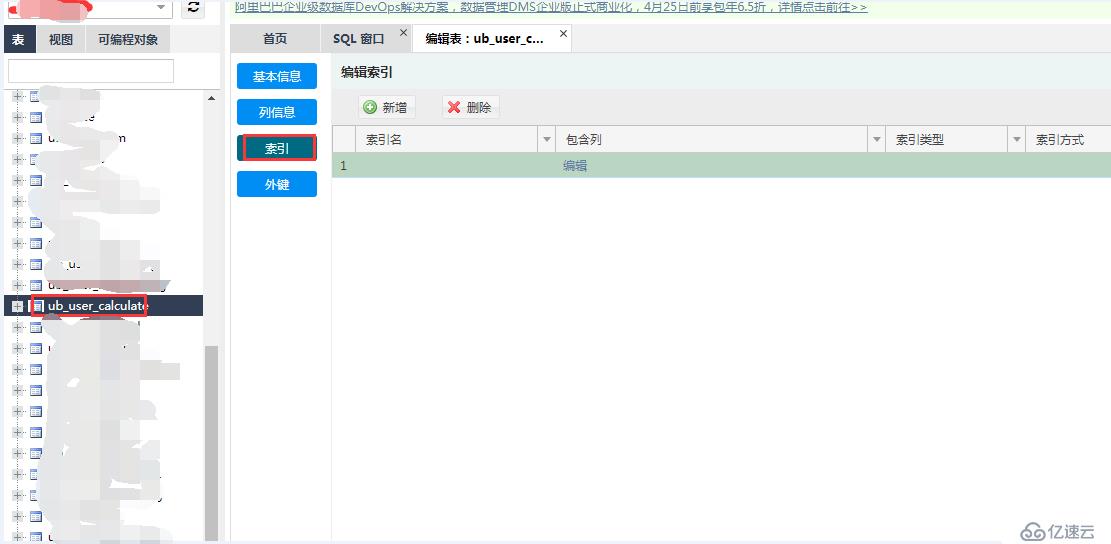
分析:当数据库中出现访问表的SQL没创建索引导致全表扫描,如果表的数据量很大扫描大量的数据,执行效率过慢,占用数据库连接,连接数堆积很快达到数据库的最大连接数设置,新的应用请求将会被拒绝导致故障发生。
赶紧把此事反应给开发负责人,表明问题根源找到了,会话锁死了,由其中的一张表没有索引而导致的,问询问需要给哪几个字段加索引。然后接着操作增加索引: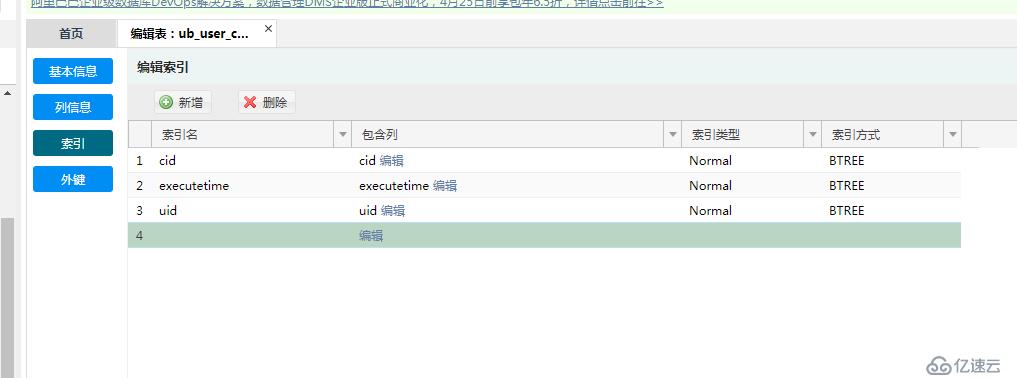
点击保存后,发现创建索引的sql一直卡死着,,如下图所示: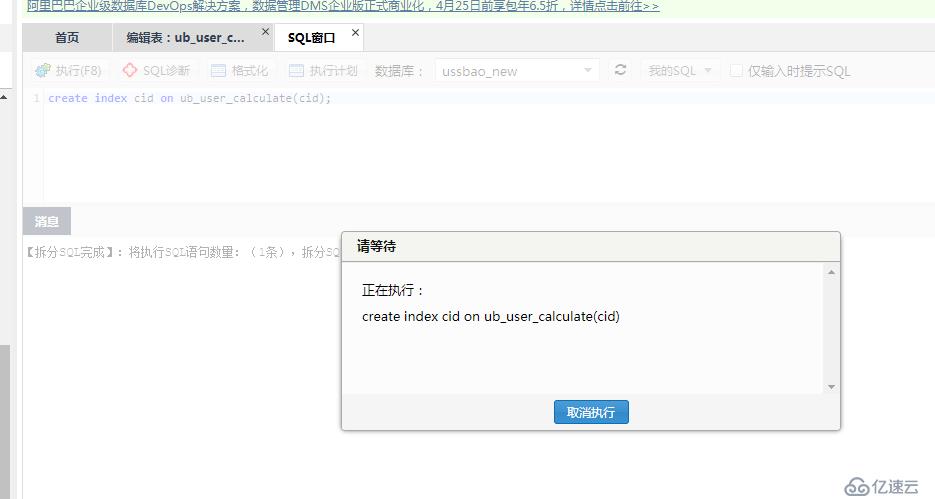
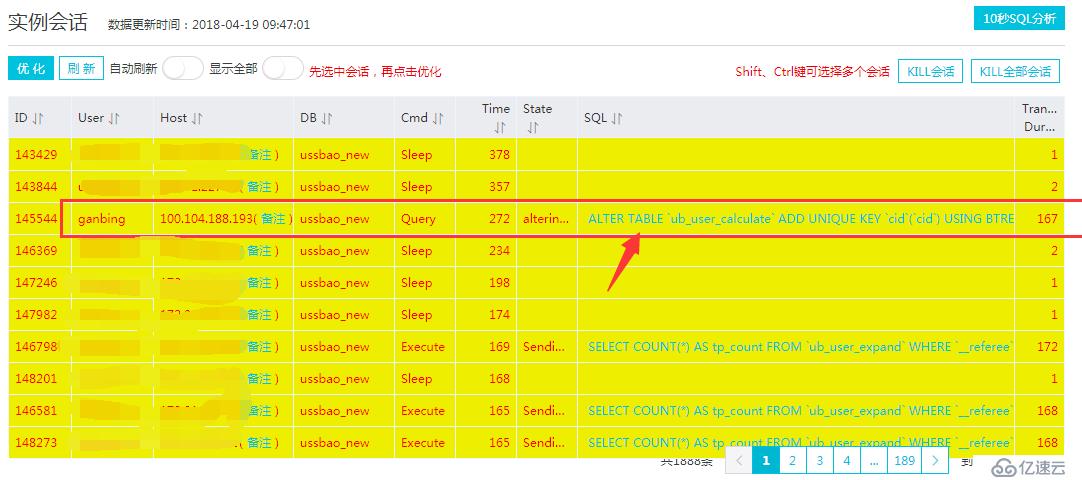
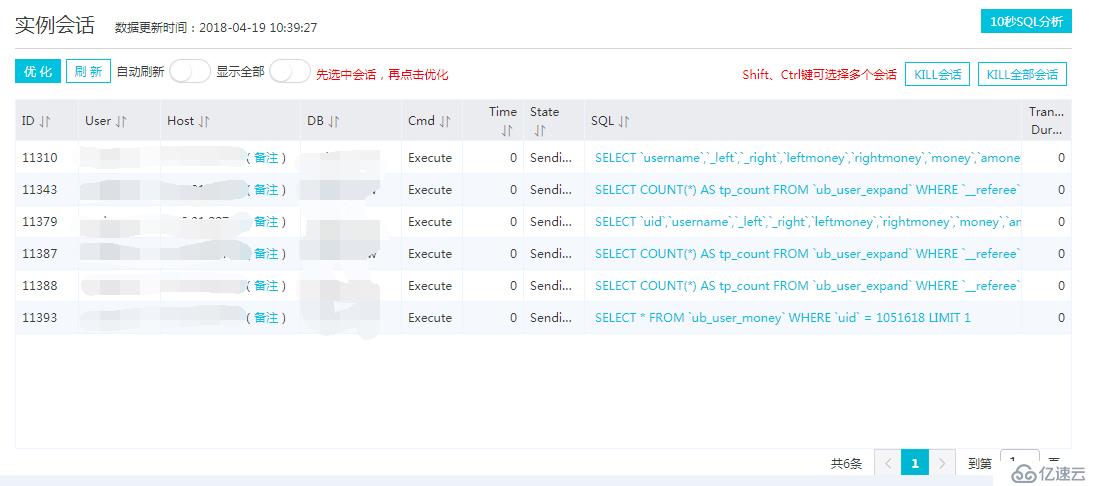
突然想起来还有一堆会话在那里,先kill 掉所有会话吧,不然索引肯定创建不了,然后又发现会话根本杀不完,如下图:
怎么办呢?会话杀不完...
没办法,先把访问入口切断吧,反正现在用户访问也超时,就毅然绝对先把域名停了,访问入口给切断了,然后在增加索引,索引加上了。
入口也断了,索引也加上了,发现CPU还下去,如下图:
为了快速让CPU降下去,重启这个实例吧: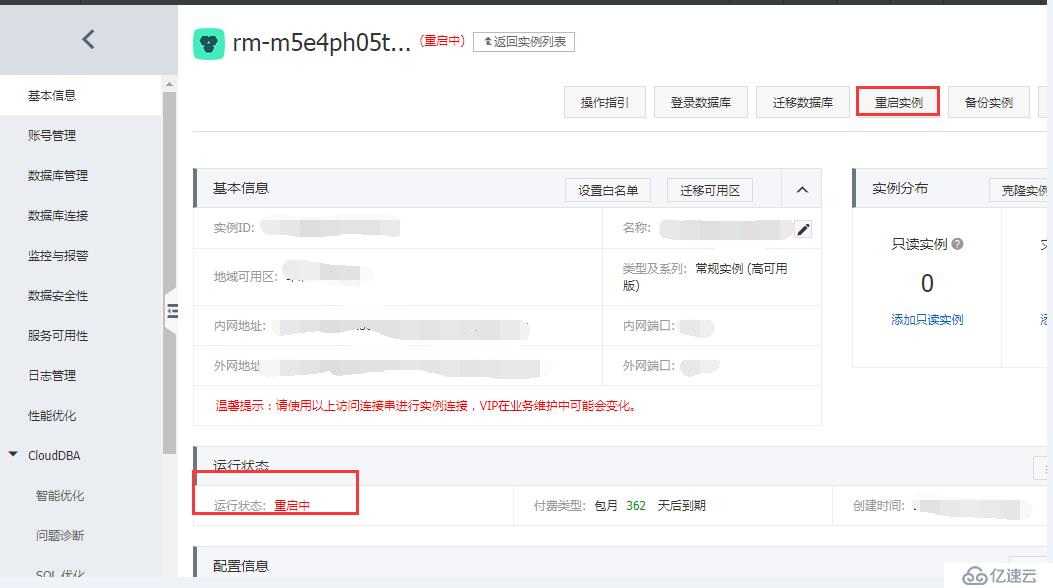
实例重启完后,CPU下去了,会话也下去了: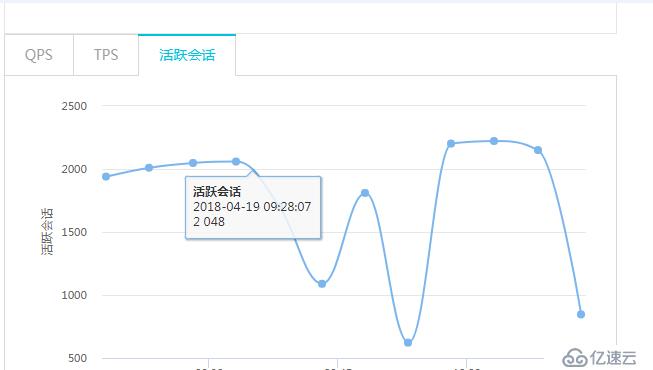
开启入口层的域名访问吧,在次观察现在的会话和CPU等况,如下图: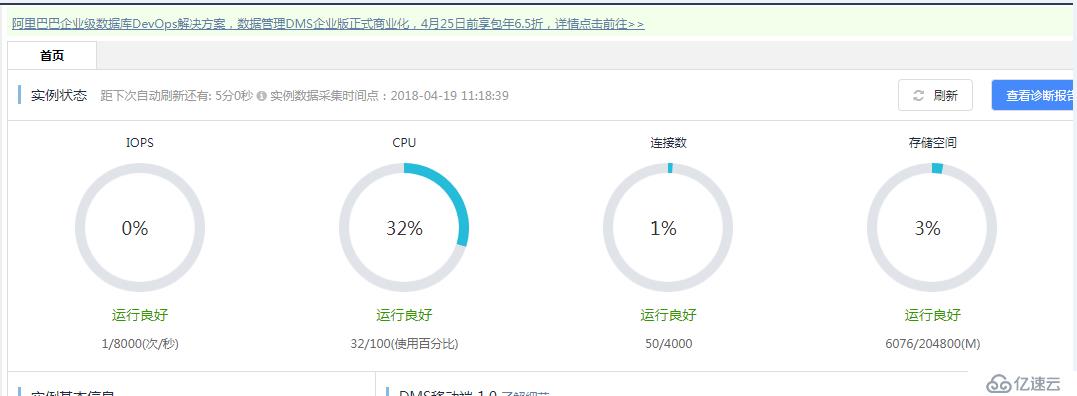
这就对了,会话也正常了,通知领导业务恢复。。。
笔者后期补的一张图:在来看一下服务器CPU情况(迁移MYSQL后的情况),明显逐渐好转。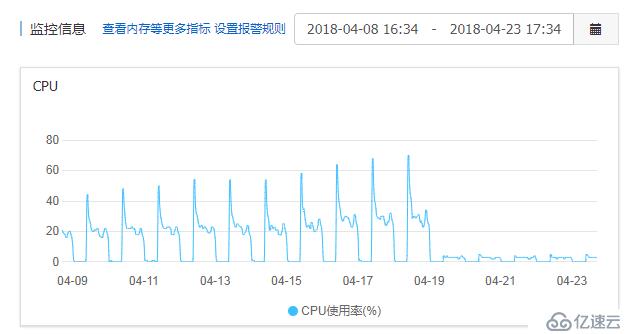
参考:https://help.aliyun.com/document_detail/52274.html?spm=a2c4g.11174283.6.812.ZGPyBQ
1、此次故障虽然是表没有索引造成的,但是笔者是有责任的,没有挨个表检查一下表的结构;
2、通过此次故障也可以看出来开发在设计表的真的要非常的重视,注意细节;
3、还有就是之前在容器中运行的mysql也时不时的出现CPU瓶颈(比如CPU使用率偶尔会达到80%以上),笔者应该就要提前发现这些问题,彻底排查找出问题所在原因在进行迁库的操作。
本章内容到此结束,喜欢我的文章,请点击最上方右角处的《关注》!!!

亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



