Spring Cloud Gateway(下文以SCG代替), 顾名思义这是由Spring 官方出品的一款网关产品,是Spring Cloud的子项目。
This project provides a library for building an API Gateway on top of Spring MVC. Spring Cloud Gateway aims to provide a simple, yet effective way to route to APIs and provide cross cutting concerns to them such as: security, monitoring/metrics, and resiliency.
官方介绍主要突出了路由功能的简单有效,同时可以在安全、监控以及扩展性方面提供不错的支持,毕竟靠着Spring Cloud这棵大树。
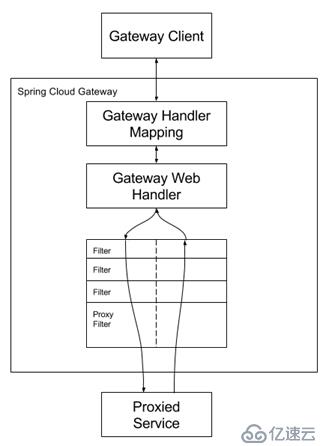
这是官方网站的工作原理示意图,从上图可以看出SCG在整个流程中主要担任反向代理的角色。客户端请求抵达SCG后,SCG通过Handler Mapping将请求路由到Web Handler,Web Handler再通过Filter对原始请求进行处理,最终发送到被代理的服务端。
在研究SCG之前,我们发现Spring Cloud下面已经有一个成熟的API套件Spring Cloud Netflix,提供了服务注册发现(Eureka),熔断器(Hystrix),智能路由(Zuul)和客户端负载均衡(Ribbon)等特性,其中就有我们需要的路由功能Zuul。
那为什么在集成一个路由功能后,Spring Cloud还要自己开发一个用于路由的Gateway项目呢?我们来看看他们的一些对比,由于Spring Cloud只集成了Zuul1.0,所以比较也集中在Zuul1.0和SCG之间。
| 连接方式 | 支持服务器 | 功能 | |
|---|---|---|---|
| Zuul1.0 | Servlet API | Tomcat,undertow | 基本路由规则,仅支持Path的路由 |
| SCG | Reactor | Netty | 较多路由规则,可以支持header,cookie,query,method等丰富的predict定义 |
从上面的对比来看,SCG基于Project Reactor可以获得更优秀的吞吐,在功能方面相当于Zuul的优化,更加灵活的配置可以满足几乎所有的网关路由需求。
虽然说Zuul2.0也是基于Netty开发,并增强了路由和过滤器功能,然而他的多次跳票最终让Spring下决心自己做一款网关路由产品,并表示不会将Zuul2.0集成进以后的Spring Cloud中,也算一段趣闻吧。
下面我们实际动手实现一个网关,结合过程中遇到的问题来熟悉SCG的各项特性。
我们新建一个基于Spring Boot的Maven项目,添加SCG的依赖,主要是下面两个
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>这里选择的是最新的Spring Boot Release版本(2.1.4)以及支持2.1的Spring Cloud分支Greenwich。
最后建一个SpringBootApplication,参照首页的Demo去掉Hystrix和RateLimit相关的内容就可以跑起来了(https://spring.io/projects/spring-cloud-gateway)。
光有个Demo肯定不行,我们的网关是要实际投产使用的,在分析了实际需求之后我们发现急需的第一个功能是动态路由。
在文档中提供了两种方式的路由配置方式
通过java API
直接通过RouteLocatorBuilder构建如下:
builder.routes().route("path_route",
r -> r.path("/get").uri("http://httpbin.org")).build();通过配置文件
通过YAML文件构建路由如下:
spring:
cloud:
gateway:
routes:
- id: host_route
uri: https://example.org
predicates:
- Path=/foo/{segment},/bar/{segment}但是实际需求中存在动态分配路由的场景,以上两种方式显然都不能满足需求。
通过查看源代码发现SCG加载路由是通过RouteDefinitionLocator接口实现,有以下默认实现(框掉的部分可以暂时忽略,这是我们自己的实现):
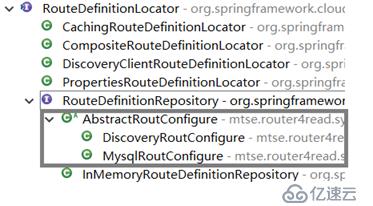
在GatewayAutoConfiguration中通过Primary的方式指定CompositeRouteDefinitionLocator作为路由定义加载的入口,通过组合模式将所有的RouteDefinitionLocator代理。最终通过CompositeRouteDefinitionLocator的getRouteDefinitions方法将所有定义加载出来。
@Bean
@Primary
public RouteDefinitionLocator routeDefinitionLocator(
List<RouteDefinitionLocator> routeDefinitionLocators) {
return new CompositeRouteDefinitionLocator(
Flux.fromIterable(routeDefinitionLocators));
}public class CompositeRouteDefinitionLocator implements RouteDefinitionLocator {
private final Flux<RouteDefinitionLocator> delegates;
public CompositeRouteDefinitionLocator(Flux<RouteDefinitionLocator> delegates) {
this.delegates = delegates;
}
@Override
public Flux<RouteDefinition> getRouteDefinitions() {
return this.delegates.flatMap(RouteDefinitionLocator::getRouteDefinitions);
}
}通过源代码的解读,我们发现如果需要定义新的路由加载方式,只需要增加一个RouteDefinitionLocator的实现即可,在实际操作中为了方便路由更新我们仿照已有的实现
InMemoryRouteDefinitionRepository进行实现,类图如下: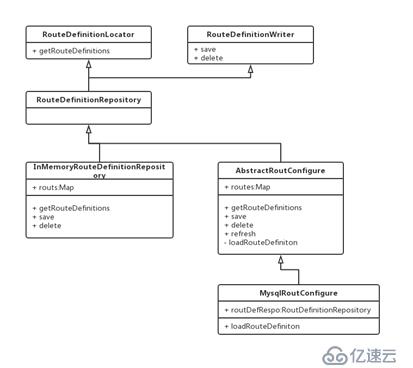
我们通过新增了一个抽象类类完成RouteDefinitionRepository的扩展,在抽象类里我们实现了基本的get, save, delete方法,另外新增了refresh方法用于刷新缓存,而缓存的实现参考了InMemory的实现方式。
在需要进行扩展的时候我们可以通过继承AbstractRoutConfigure来增加我们自己的configure loader,再通过Configuration方式注入即可: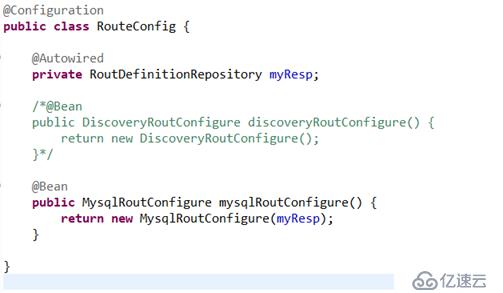
最终的实现效果是我们通过数据库变更配置后,通过restful接口来调用refresh方法即可完成路由的动态刷新。
通过上面动态路由的基本实现,我们数据库中的配置是这样的
但是我们是要做微服务和集群的网关,直接写地址显然是不行的。
针对这种情况,SCG提供了一种URI的格式:lb://main-service,其中main-service是我们微服务在注册中心的name。
当URI以lb开头,则在进行URI解析的时候会去寻找zookeeper,consul,eureka 对应的客户端实现。我们使用的是eureka,并且在数据库中加上以下配置
这样我们就可以成功代理微服务提供的接口了。
容错管理从以下两方面进行考虑
1, 路由未定义
针对路由未找到的情况,提供有意义的报错信息进行有效反馈。
实现层面主要通过定义一个NotFound的路由,通过设置order确保NotFound路由在所有的路由之后执行,这样当所有的路由都没有匹配上的时候就会被路由到NotFound路由,从而反馈有意义的报错信息。
数据库定义,
代码部分:
/**未找到路由的时候提示错误信息*/
@RequestMapping(value = "/notfoundcontroller")
public Mono<Map<String, String>> notFoundController() {
Map<String, String> res = new HashMap<>();
res.put("code", "-404");
res.put("data", "route definition not found");
return Mono.just(res);
}2, 熔断器Hystrix
熔断器主要应用于请求超时,服务端错误等使用场景,SCG提供了Hystrix的集成,我们只需要在YAML配置文件里面配置default filter并加入fallbackUri的实现即可。
YAML
spring:
cloud:
gateway:
default-filters:
- name: Hystrix
args:
name: fallbackcmd
fallbackUri: forward:/fallbackcontrollerfallbackUri
/**断路器对应的服务降级地址,对于请求失败进行处理*/
@RequestMapping(value = "/fallbackcontroller")
public Mono<Map<String, String>> fallBackController() {
Map<String, String> res = new HashMap<>();
res.put("code", "-100");
res.put("data", "service not available");
return Mono.just(res);
}通过上面两点的配置,我们在请求出错如超时、服务宕机的情况都可以得到对应的错误信息,确保了网关服务的鲁棒性。
SCG使用的限流机制(Rate Limiter)基于令牌桶算法,我们先大致了解一下令牌桶算法。
从上图可以看出,令牌桶算法的主要数据结构是个缓冲区。通过匀速生成的令牌来填充缓冲区相当于生产者,而实际流量则相当于消费者来消费缓冲区中的令牌。
我们再结合SCG中的实现来看看令牌桶算法如何限流的。
SCG使用RateLimiter需要引入spring-boot-starter-data-redis-reactive,所以SCG的令牌桶实现是基于Redis的,这样可以满足分布式的要求。
SCG在使用过程中需要设置三个参数replenishRate ,burstCapacity和KeyResolver。
replenishRate表示的是装桶的速率,也就是令牌生成的速率;
burstCapacity表示瞬间高爆发的容量,官方文档解释是一秒内允许的最大流量又补充了一句是令牌桶可以装下的令牌数。
KeyResolver很好理解,通过key的定义可以明确规定限流的层级,用户级还是IP级别等等。
对于burstCapacity的理解,只有当replenishRate和burstCapacity相等时也就是请求处理基本是匀速的情况下,burstCapacity才表示一秒内允许的最大流量,否则解释为令牌桶的容量更加贴切。
代码实现主要通过RedisRateLimiter.class和request_rate_limiter.lua两个文件,而主要逻辑是通过脚本文件实现。
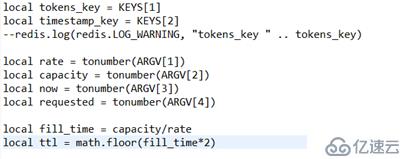
这里主要获取java传过来的参数,计算出ttl,ttl的逻辑是桶装满所需时间的两倍。
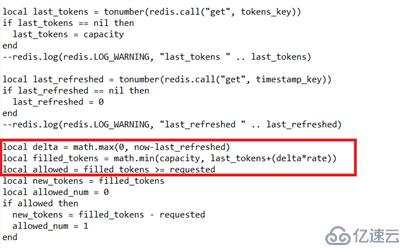
上面这段代码是实现限流的关键,每次都会通过当前时间和上次刷新时间的间隔计算填充的令牌,只有填充后的令牌 >= 请求的令牌数才符合条件允许令牌获取。
当新的请求获取令牌后,更新令牌桶的令牌数和最后刷新时间。
在实际引用中我们根据我们服务器的压力来设定rate和capacity,通过不停的调节来寻求吞吐和负载的平衡。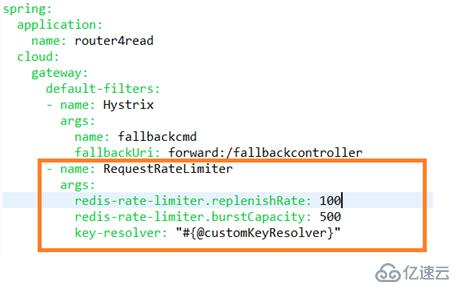
日志配置方面除了基本的logback配置,需要加入access_log的配置,根据官方文档我们需要在logback配置文件中加入logger和appender的配置。
<appender name="accessLog" class="ch.qos.logback.core.FileAppender">
<file>access_log.log</file>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="async" class="ch.qos.logback.classic.AsyncAppender">
<appender-ref ref="accessLog" />
</appender>
<logger name="reactor.netty.http.server.AccessLog" level="INFO" additivity="false">
<appender-ref ref="async"/>
</logger>如上所示,通过定义logger接收netty的AccessLog,通过异步发射器发送到accessLog Appender。
这里需要注意的是Netty AccessLog的配置要到reactor-netty0.7.9之后才支持,所以在使用这个功能之前需要确保我们netty的版本满足要求,项目目前使用的spring版本如下,对应的reactor-netty版本为0.8.6。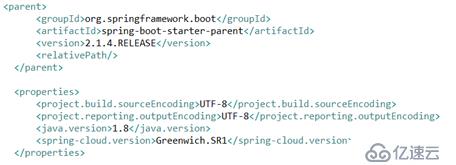
配置了这么多,然而access.log文件还是空空如也,因为你漏掉了很重要的一步:
在启动参数中添加 -Dreactor.netty.http.server.accessLogEnabled=true. 注意这个属性是java系统属性而不是spring配置属性,也就是说只能通过启动参数注入。
我们通过一些简单的介绍了解了SCG的出现背景,然后通过实际的网关搭建实践来一步步的理解SCG的架构理念和实现细节。
通过动态路由部分我们见证了SCG的可扩展性架构,在服务路由和容错管理部分我们主要和Spring Cloud已有组件(eureka, hystrix)进行集成,而在限流机制部分我们通过阅读源代码理解了基于令牌桶的限流算法以及如何结合Redis实现分布式系统限流,在日志配置部分主要是结合Netty的日志机制来完成网关的访问日志配置。
在我们的实践中我们没有用上SCG的所有特性,但是就目前的情况用于我们自己的API 网关已经够用。
在启动spring boot程序的时候发现了下面两句话
2019-05-20 13:56:32,381 [main] INFO com.zaxxer.hikari.HikariDataSource - HikariPool-1 - Starting...
2019-05-20 13:56:32,875 [main] INFO com.zaxxer.hikari.HikariDataSource - HikariPool-1 - Start completed.
于是怀着好奇心去看了看这个HikariDataSource是何方神圣。
不看不知道一看吓一跳,这个从来没听过的东西居然是spring boot默认的连接池,作为连接池他的性能居然能超过druid。限于篇幅,我们会另开一篇来研究一下。
在前面的源码分析中我们看到,RouteDefinitionLocator是采用的代理模式,通过一个组合器将所有代理locator中定义的route加载出来,核心代码: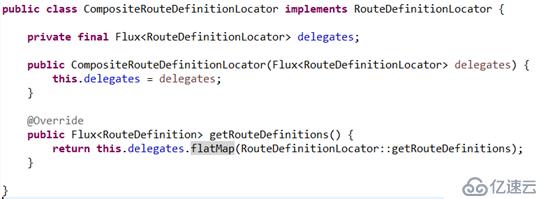
所以当我们定义了多个locator的时候(如MySql的locator, Json的locator),SCG是如何对这些locator进行merge的呢?
通过GatewayAutoConfiguration.class 我们发现定义为Primary的RouteLocator是CachingRouteLocator。
而在CachingRouteLocator中通过装饰者模式对所有locator获得的route进行了排序,排序的依据是order字段。
综上所述,如果定义了多个routeDefinitionLocator,则对于里面的route会根据order进行排序,如果order未定义则按照默认order为0处理。
排序完成后按照先后顺序逐个匹配请求,如果满足则不继续匹配,也就是说全局来说定义的order越小则优先级越高,不管出自哪个locator。
这个错误是配置了断路器之后出现的,当配置的fallbackuri没有定义或者无法匹配的时候会出现。我们实践中的起因是配置了fallbackuri的method为GET,而实际引起错误的请求是通过POST发送过来的。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



