互联网发展到现在,由于数据量大、操作并发高等问题,大部分网站项目都采用分布式的架构。而分布式系统最大的特点数据分散,在不同网络节点在某些时刻(数据未同步完,数据丢失),数据会不一致。
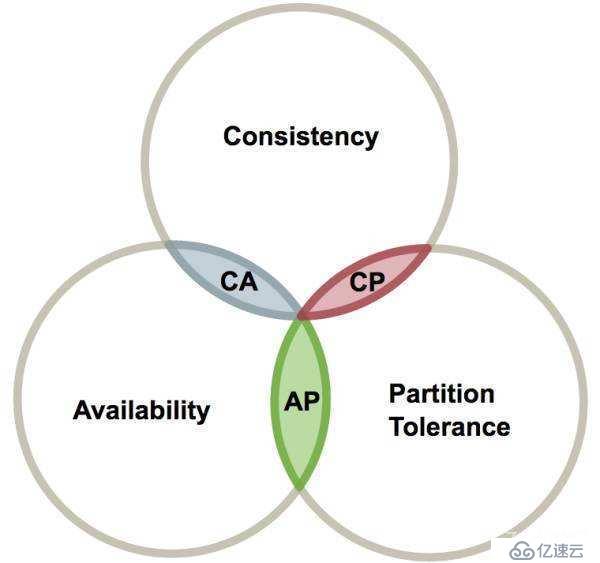
在2000年,Eric Brewer教授在PODC的研讨会上提出了一个猜想:一致性、可用性和分区容错性三者无法在分布式系统中被同时满足,并且最多只能满足其中两个!
在2002年,Lynch证明其猜想,上升为定理。被这就是大家所认知的CAP定理。
CAP是所有分布式数据库的设计标准。例如Zookeeper、Redis、HBase等的设计都是基于CAP理论的。
所谓的CAP就是分布式系统的三个特性:
有A、B、C三个分布式数据库。
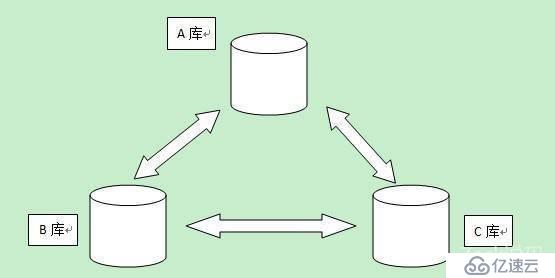
当A、B、C的数据是完全相同,那么就符合定理中的Consistency(一致性)。
假如A的数据与B的数据不相同,但是整体的服务(包含A、B、C的整体)没有宕机,依然可以对外系统服务,那么就符合定理中的Availability(可用性)。
分布式数据库是没有办法百分百时刻保持各个节点数据一致的。假设一个用户再A库上更新了一条记录,在更新完这一刻,A与B、C库的数据是不一致的。这种情况在分布式数据库上是必然存在的。这就是Partition tolerance(分区容错性)
当数据不一致的时候,必定是满足分区容错性,如果不满足,那么这个就不是一个可靠的分布式系统。
然而在数据不一致的情况下,系统要么选择优先保持数据一致性,这样的话。系统首先要做的是数据的同步操作,此时需要暂停系统的响应。这就是满足CP。
若系统优先选择可用性,那么在数据不一致的情况下,会在第一时间放弃一致性,让整体系统依然能运转工作。这就是AP。
所以,分布式系统在通常情况下,要不就满足CP,要不就满足AP。
那么有没有满足CA的呢?有,当分布式节点为1的时候,不存在P,自然就会满足CA了。
上面说到,分区容错性是分布式系统中必定要满足的,需要权衡的是系统的一致性与可用性。那么常见的分布式系统是基于怎样的权衡设计的。
更多技术文章、精彩干货,请关注
个人博客:zackku.com
微信公众号:Zack说码 
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





