背景介绍:
作为一名 Infra,管理平台的各种基础组建以及基本的服务质量是必修的功课,而如何对复杂和繁多的基础平台,甚至包括上面运行的 Ops 系统、业务系统,其稳定性的各项指标都是衡量 Infra 是否称职的非常重要的标准。
单纯离散的指标本身是没有实际意义的,只有将离散的指标通过某种方式进行存储,并支持对终端用户友好的查询以及聚合,才会真正的有意义。因此,一个性能足够的,分布式的,用户友好且方便下面 DevOps 团队进行部署的 TSDB ( Time Series Database )就成了一个不可缺少的系统。
常见的 TSDB 包括 InfluxDB , OpenTSDB , Prometheus 等,其中,开源版本的 InfluxDB 虽然优秀,但并不支持集群部署,且 TICK Stack 本身对数据清洗的灵活性支持并不太好,直接使用开源版本,会有统计信息被收集并上报;而 OpenTSDB 由于基于 HBase ,在部署时成本过高,且本身并不是一套完整的监控系统,而基于 Prometheus 与 TiKV 进行开发的话,整个系统可在保持最简洁的同时,也有非常丰富的生态支持。
因此,基于实际情况,融云最终选择 TiPrometheus 作为 Infra 部的监控平台存储方案。
项目简介:
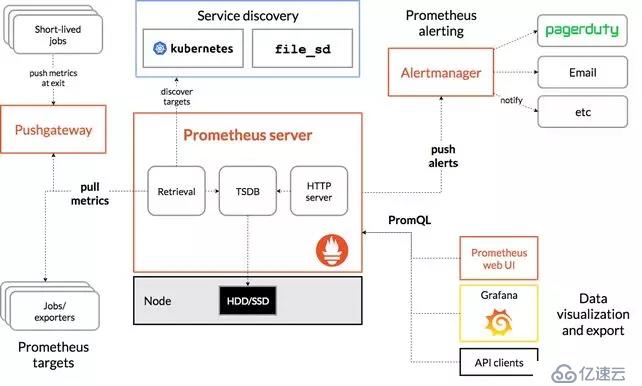
上图为 Prometheus 的官方系统架构图,而实现 TiPrometheus ,用到了上图中没有体现到的一个 Prometheus 的功能:Remote Storage ,如其名所示,其主要功能是给 Prometheus 提供了远程写的能力,这个功能对于查询是透明的,主要用于长存储。而我们当时的 TiPrometheus 实现了基于 TiKV 以及 PD 实现的 Prometheus 的 Remote Storage 。
核心实现
Prometheus 记录的数据结构分为两部分 Label 及 Samples 。 Label 记录了一些特征信息,Samples 包含了指标数据和 Timestamp 。
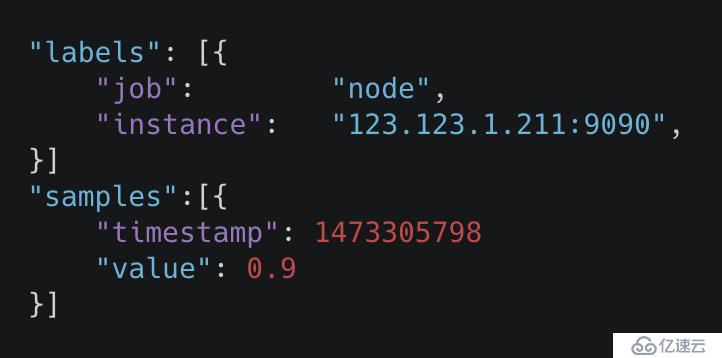
Label 和时间范围结合,可以查询到需要的 Value 。
为了查询这些记录,需要构建两种索引 Label Index 和 Time Index ,并以特殊的 Key 存储 Value 。
l Label Index
每对 Label 为会以 index:label:<name>#<latency> 为 key ,labelID 为 Value 存入。新的记录会 "," 分割追加到 Value 后面。这是一种搜索中常用的倒排索引。
l Time Index
每个 Sample 项会以 index:timeseries:<labelID>:<splitTime> 为 Key,Timestamp 为 Value ,SplitTime 为时间切片的起始点。追加的 Timestamp 同样以","分割。
l Doc 存储
我们将每一条 Samples 记录以 timeseries:doc:<labelID>:<timestamp> 为 Key 存入 TiKV ,其中 LabelID 是 Label 全文的散列值。
下面做一个梳理:
写入过程
生成 labelID
构建 time index,index:timeseries:<labelID>:<splitTime>"ts,ts"
写入时序数据 timeseries:doc:<labelID>:<timestamp> "value"
查询过程
根据倒排索引查出 labelID 的集合,多对 Label 的查询会对 labelID 集合求交集。
根据 labelID 和时间范围内的时间分片查询包含的 Timestamp 。
Why TiPrometheus
该项目最初源于参加 PingCAP 组织的 Hackathon ,当时希望与参与者一起完成大家脑海里的想法,其实最重要的事情就是,做出来的东西并不是为了单纯的 Demo ,而是要做一个在实际工作中应用于生产环境的实际能力,且能解决生产中的问题。
刚开始还有过各种奇思妙想,包括在 TiSpark 上做一套 ML ,Hadoop over TiKV 等,不过这些想法实现起来都有些过于硬核,对于只有两天工作时间就需要完成的项目来说,可能性太小;或者说,如果希望实现 Demo ,所需 Hack 的点过多。而 GEO 全文检索在融云现有的生产上,以及现有的系统中,也并没有需要去填补的大坑,因此,也就没有什么必要去在这方面花费力气去解决一个并不存在的问题。
由于 IM 服务是一种计算密集型的服务,且服务质量是融云的核心竞争力;而目前存储资源呈现出零散分布的节点,且每个节点的存储资源使用率并不高,为了最大化利用现有的闲置资源,融云最终设计并实现了这套 TiPrometheus 系统。
Result
打通了 TiKV 与 Prometheus ,为基于 K , V 存储的时序数据库设计提供了一个可行的思路。
为 Prometheus 的长存储提供了一套实用的解决方案。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



