1. 工具产生的背景
导航对人们的生活起着越来越重要的作用,由于公司一直在做导航产品,所以为了从深度上保证产品的质量(已经通过大量的case从广度上来保证产品质量),做为Routing的测试负责人,我对导航算法进行了深入的研究。
在做Map Data的Regression时,我们是基于导航对底层的数据进行测试,而MapData是经过Tools Team 转换的,所以原始数据的改动、Tools的改动都会引起导航的变化,而这两层对从上层测试的我们来说都是blackbox。测试时,用自动化工具找出difference很容易,但check起来相当困难,因为我们不光需要知道路线变了,而且需要知道它是怎么变的,否则你不知道你的模型是不断优化的。当时一天也就check十几条路线变化的case,对于五六千条case的一轮Regression,测试工作量是呈指数增长的,已经不是增加一两个人就能解决问题的。
导航,本身就是机器学习的过程,所以用传统的功能测试抽取case覆盖各个feature的方法在这种情况下不是完全适用:一是因为一条规划的路线会涉及到几百、甚至上万条link,每条link又有多个影响因子,如果有一个或几个因子变化,都可能引起导航路径的变化,更何况是这么多个可变因子,而且以前设计的覆盖Feature的case,可能会因为数据变了就cover不到了;二是因为机器学习本身就是通过大量的数据,对原型不断进行训练、不断优化的过程,所以减少case进行测试,很可能会使模型陷入局部最优。所以作为数学系的我,认为机器学习的原型用机器学习的方法测试才是最好的解决方案,于是想到了神经网络。
在这个时期饱受折磨的不光是我们team的QA,ToolsTeam的dev也被要求用我们的Regression工具check case,要知道他们对导航的逻辑不了解,check起来难度多大(即使知道导航变了,但为什么变,你得知道)。这使我深刻意识到自动化工具的思想,比自动化工具的开发要重要得多,Tools Team的lead曾经说过一句话:只要你有想法,我们就能把工具做出来。所以经过大概两周的折磨,在凌晨四点的睡梦中终于有了solution,而不是idea,当时那叫一个兴奋啊JJ
第二天,跟mgr讨论了之后,他同意了我的solution,于是找到ToolsTeam的一个牛人,仅用了几天时间,就把工具生成出来了。
2. 人工神经网络ANN (Artificial Neural Network)
主要类型:
· 前向神经网络
· 反馈网络
· 自组织网络
· 相互结合型网络
为了使模型相对简单、准确,我们采用三层前向神经网络(即含一个隐含层)
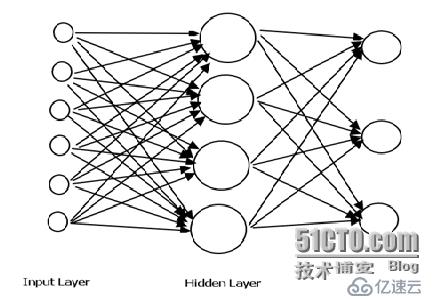
3. 实现的思想
· 抽取difference
采用第三方工具(diff.exe)将新旧地图的difference进行对比(类似Beyond Compare的功能)并且输出。
· 使用神经网络模型
输入层:diff.exe的output。
隐含层:内部处理逻辑
输出层:分类的结果和变化的cost
输入层到隐含层的权重:w(ih)
隐含层到输出层的权重:w(ho)
· 实现分类
根据feature 进行分类,通过config.xml手动配置来定义分类的优先级:
· 计算从输入层到隐含层的权重w(ih)
将priority 转换成 [0, 1]之间的数(当时就卡在了这个转换过程上,想到了神经网络,但就是不知道怎么将现有的输入和期望的输出转换成数学模型):
F1 = (1/2)^1
F2= (1/2)^2
F3 =(1/2)^3
F4 = (1/2)^4
F5 =(1/2)^5
F6 = (1/2)^6
F7=(1/2)^7
…
Notes:
1) Fn: 代表第n个feature
2) 根据等比数列1/2^n 给每个分类因素定义权重,这样做的目的是为了使每个weight最后加起来的值无限接近但<1,即使所有的expectedresult 全变化了,最大值不会超过1
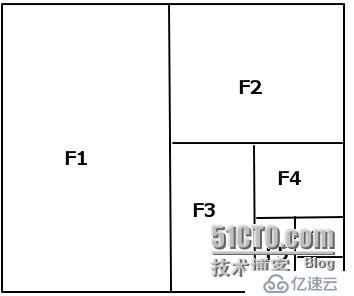
3)分类的顺序可以根据每次的改动调整
4)Config.xml的格式可修改为:
<priority>
<pr name="F1"value=1/>
<pr name="F2"value=2/>
<pr name="F3" value=3/>
<pr name="F4"value=4/>
<prname="F5"value=5/>
<pr name="F6" value=6/>
<pr name="F7" value=7/>
…
<pr name="Fn" value=0/>
</priority>
因此每个分类的weight=(1/2)^value
(对于不需要check的difference,不用计算,value设为0)
4. 定义隐含层到输出层的权重w(ho):
对于每个feature,可能不止一处发生变化,根据经验,设置可能变化的最大个数(config.xml里配置,可手动修改)
Config.xml可定义为
<hidden_output>
<f1weight="1/5"/>
<f3 weight="1/10"/>
<f4weight ="1/3"/>
<f5weight="1/10"/>
…
</hidden_output >
· 由于之前把主要的精力放到了check路线变化的case上,既慢又发现不了什么问题,后来经过经验和简单利用了下统计的原理,证明了引起长路径的变化的主要因子是路的等级和速度(通常这两个因子会引起一些列link都变),所以根据路线变化的段数计算cost,而非长路径导航。
· 这里比较麻烦的地方是Maneuver,因为每个Maneuver的提示(左转、右转、上高速等等)还有另外一整套逻辑,是分类工具比较复杂的地方。
· 权重的计算思想为:通过对Tools调研,知道Tools对哪些属性进行了处理(因为Tools的复杂度较高,了解详细的逻辑cost非常大,所以只是通过代码复杂度和逻辑复杂度知道个大概的情况)。根据line by line的读导航的 code,知道Maneuver的产生条件,并计算出Tools处理过的属性占每个maneuver的cost;根据Tools的代码复杂度和逻辑复杂度(复杂度越高,bug可能越多)以及客户(Customer bug is very important)报的bug类型,计算出每类maneuver的cost, 根据这两个cost,计算出Tools的影响和客户发现的bug占每个maneuver的cost;最后进行归一化处理。即:从导航的逻辑、客户、Tools的改动,以及最后的表现形式上计算cost。
· config.xml可定义为:
<all_maneuvers>
<amname="NC." weight=0.XX/>
<amname="CO." weight=0.XX/>
<amname="KP." weight=0.XX/>
<amname="KP.L" weight=0.XX/>
…
</all_maneuvers>
5. 计算从输入层到输出层的cost:
· F1: cost = w(ih)(F1)*(1/2+n*w(ho)(F1))=(1/2)^1*(1/2+1/2*n*1/5)
· F2: cost = w(ih)(F2)*(1/2+each w(ho)(F2))=(1/2)^2*(1/2+ 1/2*each maneuver weightfrom hidden layer to output layer)
· F3: cost = w(ih)(F3)*(1/2+n*w(ho)(F3))=(1/2)^3*(1/2+1/2*n*1/10)
· F4: cost = w(ih)( F4)*(1/2+n*w(ho)( F4))=(1/2)^4*(1/2+1/2*n*1/3)
· Fm: cost = w(ih)( Fm)*(1/2+n*w(ho)( Fm))=(1/2)^9*(1/2+1/2*n*1/30)
(n 代表每类feature的变化数量)
Notes:
1) 由此可见,F1的取值范围应该是[1/4, 1/2],F2的取值范围是[1/8, 1/4], F3的取值范围是[1/16, 1/8], …
2) 由于一条case里,可能既含有F1的,又含有F2, 所以F1的权重应该在[1/4,1],同理类推F2分类里权重的总和应该在[1/8, 1/2],,…(在已经正确分类的基础上,即使F2的cost比F1的大,也不会影响case的选取)
6. 用聚类分析方法根据最终的cost大小抽取指定数量的case。
7. 优点:
1. 在不减少Test Scope的情况下,可以合理的抽取case;在有限的时间内,check变化最大的case。
2. 通过了解Tools的改动,手动配置测试范围和优先级,来保证产品质量。
3. 由于人工check结果时会把difference里的所有变化全check,所以此工具也是在模拟人的操作。
8. 缺点:
1.由于Case的output是基于Maneuver的,而非Routing,所以计算时存在分类错误,但考虑到改动开发的code cost比较高,只能根据现有的结果和经验进行优化。
2.神经网络本身可能陷入局部最优,所以即使权重调整再大,期望结果也可能会很小。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





