жӯЈеҲҷиЎЁиҫҫејҸжҳҜд»Җд№Ҳ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚжӯЈеҲҷиЎЁиҫҫејҸжҳҜд»Җд№ҲпјҢж–Үдёӯд»Ӣз»Қзҡ„йқһеёёиҜҰз»ҶпјҢе…·жңүдёҖе®ҡзҡ„еҸӮиҖғд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们дёҖе®ҡиҰҒзңӢе®ҢпјҒ
жӯЈеҲҷиЎЁиҫҫејҸеҲ°еә•жҳҜд»Җд№ҲдёңиҘҝпјҹдёӢйқўдәҝйҖҹдә‘е°ұеёҰжӮЁи®ӨиҜҶдёҖдёӢжӯЈеҲҷиЎЁиҫҫејҸгҖӮ
еңЁзј–еҶҷеӨ„зҗҶеӯ—з¬ҰдёІзҡ„зЁӢеәҸжҲ–зҪ‘йЎөж—¶пјҢз»ҸеёёдјҡжңүжҹҘжүҫз¬ҰеҗҲжҹҗдәӣеӨҚжқӮ规еҲҷзҡ„еӯ—з¬ҰдёІзҡ„йңҖиҰҒгҖӮжӯЈеҲҷиЎЁиҫҫејҸе°ұжҳҜз”ЁдәҺжҸҸиҝ°иҝҷдәӣ规еҲҷзҡ„е·Ҙе…·гҖӮжҚўеҸҘиҜқиҜҙпјҢжӯЈеҲҷиЎЁиҫҫејҸе°ұжҳҜи®°еҪ•ж–Үжң¬и§„еҲҷзҡ„д»Јз ҒгҖӮ
еҫҲеҸҜиғҪдҪ дҪҝз”ЁиҝҮWindows/DosдёӢз”ЁдәҺж–Ү件жҹҘжүҫзҡ„йҖҡй…Қз¬Ұ(wildcard)пјҢд№ҹе°ұжҳҜ*е’Ң?гҖӮеҰӮжһңдҪ жғіжҹҘжүҫжҹҗдёӘзӣ®еҪ•дёӢзҡ„жүҖжңүзҡ„Wordж–ҮжЎЈзҡ„иҜқпјҢдҪ дјҡжҗңзҙў*.docгҖӮеңЁиҝҷйҮҢпјҢ*дјҡиў«и§ЈйҮҠжҲҗд»»ж„Ҹзҡ„еӯ—з¬ҰдёІгҖӮе’ҢйҖҡй…Қз¬Ұзұ»дјјпјҢжӯЈеҲҷиЎЁиҫҫејҸд№ҹжҳҜз”ЁжқҘиҝӣиЎҢж–Үжң¬еҢ№й…Қзҡ„е·Ҙе…·пјҢеҸӘдёҚиҝҮжҜ”иө·йҖҡй…Қз¬ҰпјҢе®ғиғҪжӣҙзІҫзЎ®ең°жҸҸиҝ°дҪ зҡ„йңҖжұӮвҖ”вҖ”еҪ“然пјҢд»Јд»·е°ұжҳҜжӣҙеӨҚжқӮвҖ”вҖ”жҜ”еҰӮдҪ еҸҜд»Ҙзј–еҶҷдёҖдёӘжӯЈеҲҷиЎЁиҫҫејҸпјҢз”ЁжқҘжҹҘжүҫжүҖжңүд»Ҙ0ејҖеӨҙпјҢеҗҺйқўи·ҹзқҖ2-3дёӘж•°еӯ—пјҢ然еҗҺжҳҜдёҖдёӘиҝһеӯ—еҸ·вҖң-вҖқпјҢжңҖеҗҺжҳҜ7жҲ–8дҪҚж•°еӯ—зҡ„еӯ—з¬ҰдёІгҖӮ
е…Ҙй—Ё
еӯҰд№ жӯЈеҲҷиЎЁиҫҫејҸзҡ„жңҖеҘҪж–№жі•жҳҜд»ҺдҫӢеӯҗејҖе§ӢпјҢзҗҶи§ЈдҫӢеӯҗд№ӢеҗҺеҶҚиҮӘе·ұеҜ№дҫӢеӯҗиҝӣиЎҢдҝ®ж”№пјҢе®һйӘҢгҖӮдёӢйқўз»ҷеҮәдәҶдёҚе°‘з®ҖеҚ•зҡ„дҫӢеӯҗпјҢ并еҜ№е®ғ们дҪңдәҶиҜҰз»Ҷзҡ„иҜҙжҳҺгҖӮ
еҒҮи®ҫдҪ еңЁдёҖзҜҮиӢұж–Үе°ҸиҜҙйҮҢжҹҘжүҫhiпјҢдҪ еҸҜд»ҘдҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸhiгҖӮ
иҝҷеҮ д№ҺжҳҜжңҖз®ҖеҚ•зҡ„жӯЈеҲҷиЎЁиҫҫејҸдәҶпјҢе®ғеҸҜд»ҘзІҫзЎ®еҢ№й…Қиҝҷж ·зҡ„еӯ—з¬ҰдёІпјҡз”ұдёӨдёӘеӯ—з¬Ұз»„жҲҗпјҢеүҚдёҖдёӘеӯ—з¬ҰжҳҜh,еҗҺдёҖдёӘжҳҜiгҖӮйҖҡеёёпјҢеӨ„зҗҶжӯЈеҲҷиЎЁиҫҫејҸзҡ„е·Ҙе…·дјҡжҸҗдҫӣдёҖдёӘеҝҪз•ҘеӨ§е°ҸеҶҷзҡ„йҖүйЎ№пјҢеҰӮжһңйҖүдёӯдәҶиҝҷдёӘйҖүйЎ№пјҢе®ғеҸҜд»ҘеҢ№й…Қhi,HI,Hi,hIиҝҷеӣӣз§Қжғ…еҶөдёӯзҡ„д»»ж„ҸдёҖз§ҚгҖӮ
дёҚе№ёзҡ„жҳҜпјҢеҫҲеӨҡеҚ•иҜҚйҮҢеҢ…еҗ«hiиҝҷдёӨдёӘиҝһз»ӯзҡ„еӯ—з¬ҰпјҢжҜ”еҰӮhim,history,highзӯүзӯүгҖӮз”ЁhiжқҘжҹҘжүҫзҡ„иҜқпјҢиҝҷйҮҢиҫ№зҡ„hiд№ҹдјҡиў«жүҫеҮәжқҘгҖӮеҰӮжһңиҰҒзІҫзЎ®ең°жҹҘжүҫhiиҝҷдёӘеҚ•иҜҚзҡ„иҜқпјҢжҲ‘们еә”иҜҘдҪҝз”Ё\bhi\bгҖӮ
\bжҳҜжӯЈеҲҷиЎЁиҫҫејҸ规е®ҡзҡ„дёҖдёӘзү№ж®Ҡд»Јз ҒпјҲеҘҪеҗ§пјҢжҹҗдәӣдәәеҸ«е®ғе…ғеӯ—з¬ҰпјҢmetacharacterпјүпјҢд»ЈиЎЁзқҖеҚ•иҜҚзҡ„ејҖеӨҙжҲ–з»“е°ҫпјҢд№ҹе°ұжҳҜеҚ•иҜҚзҡ„еҲҶз•ҢеӨ„гҖӮиҷҪ然йҖҡеёёиӢұж–Үзҡ„еҚ•иҜҚжҳҜз”ұз©әж јпјҢж ҮзӮ№з¬ҰеҸ·жҲ–иҖ…жҚўиЎҢжқҘеҲҶйҡ”зҡ„пјҢдҪҶжҳҜ\b并дёҚеҢ№й…ҚиҝҷдәӣеҚ•иҜҚеҲҶйҡ”еӯ—з¬Ұдёӯзҡ„д»»дҪ•дёҖдёӘпјҢе®ғеҸӘеҢ№й…ҚдёҖдёӘдҪҚзҪ®гҖӮ
еҒҮеҰӮдҪ иҰҒжүҫзҡ„жҳҜhiеҗҺйқўдёҚиҝңеӨ„и·ҹзқҖдёҖдёӘLucyпјҢдҪ еә”иҜҘз”Ё\bhi\b.*\bLucy\bгҖӮ
иҝҷйҮҢпјҢ.жҳҜеҸҰдёҖдёӘе…ғеӯ—з¬ҰпјҢеҢ№й…ҚйҷӨдәҶжҚўиЎҢз¬Ұд»ҘеӨ–зҡ„д»»ж„Ҹеӯ—з¬ҰгҖӮ*еҗҢж ·жҳҜе…ғеӯ—з¬ҰпјҢдёҚиҝҮе®ғд»ЈиЎЁзҡ„дёҚжҳҜеӯ—з¬ҰпјҢд№ҹдёҚжҳҜдҪҚзҪ®пјҢиҖҢжҳҜж•°йҮҸвҖ”вҖ”е®ғжҢҮе®ҡ*еүҚиҫ№зҡ„еҶ…е®№еҸҜд»Ҙиҝһз»ӯйҮҚеӨҚдҪҝз”Ёд»»ж„Ҹж¬Ўд»ҘдҪҝж•ҙдёӘиЎЁиҫҫејҸеҫ—еҲ°еҢ№й…ҚгҖӮеӣ жӯӨпјҢ.*иҝһеңЁдёҖиө·е°ұж„Ҹе‘ізқҖд»»ж„Ҹж•°йҮҸзҡ„дёҚеҢ…еҗ«жҚўиЎҢзҡ„еӯ—з¬ҰгҖӮзҺ°еңЁ\bhi\b.*\bLucy\bзҡ„ж„ҸжҖқе°ұеҫҲжҳҺжҳҫдәҶпјҡе…ҲжҳҜдёҖдёӘеҚ•иҜҚhi,然еҗҺжҳҜд»»ж„ҸдёӘд»»ж„Ҹеӯ—з¬Ұ(дҪҶдёҚиғҪжҳҜжҚўиЎҢ)пјҢжңҖеҗҺжҳҜLucyиҝҷдёӘеҚ•иҜҚгҖӮ
еҰӮжһңеҗҢж—¶дҪҝз”Ёе…¶е®ғе…ғеӯ—з¬ҰпјҢжҲ‘们е°ұиғҪжһ„йҖ еҮәеҠҹиғҪжӣҙејәеӨ§зҡ„жӯЈеҲҷиЎЁиҫҫејҸгҖӮжҜ”еҰӮдёӢйқўиҝҷдёӘдҫӢеӯҗпјҡ
0\d\d-\d\d\d\d\d\d\d\dеҢ№й…Қиҝҷж ·зҡ„еӯ—з¬ҰдёІпјҡд»Ҙ0ејҖеӨҙпјҢ然еҗҺжҳҜдёӨдёӘж•°еӯ—пјҢ然еҗҺжҳҜдёҖдёӘиҝһеӯ—еҸ·вҖң-вҖқпјҢжңҖеҗҺжҳҜ8дёӘж•°еӯ—(д№ҹе°ұжҳҜдёӯеӣҪзҡ„з”өиҜқеҸ·з ҒгҖӮеҪ“然пјҢиҝҷдёӘдҫӢеӯҗеҸӘиғҪеҢ№й…ҚеҢәеҸ·дёә3дҪҚзҡ„жғ…еҪў)гҖӮ
иҝҷйҮҢзҡ„\dжҳҜдёӘж–°зҡ„е…ғеӯ—з¬ҰпјҢеҢ№й…ҚдёҖдҪҚж•°еӯ—(0пјҢжҲ–1пјҢжҲ–2пјҢжҲ–вҖҰвҖҰ)гҖӮ-дёҚжҳҜе…ғеӯ—з¬ҰпјҢеҸӘеҢ№й…Қе®ғжң¬иә«вҖ”вҖ”иҝһеӯ—з¬Ұ(жҲ–иҖ…еҮҸеҸ·пјҢжҲ–иҖ…дёӯжЁӘзәҝпјҢжҲ–иҖ…йҡҸдҪ жҖҺд№Ҳз§°е‘је®ғ)гҖӮ
дёәдәҶйҒҝе…ҚйӮЈд№ҲеӨҡзғҰдәәзҡ„йҮҚеӨҚпјҢжҲ‘们д№ҹеҸҜд»Ҙиҝҷж ·еҶҷиҝҷдёӘиЎЁиҫҫејҸпјҡ0\d{2}-\d{8}гҖӮиҝҷйҮҢ\dеҗҺйқўзҡ„{2}({8})зҡ„ж„ҸжҖқжҳҜеүҚйқў\dеҝ…йЎ»иҝһз»ӯйҮҚеӨҚеҢ№й…Қ2ж¬Ў(8ж¬Ў)гҖӮ
жөӢиҜ•жӯЈеҲҷиЎЁиҫҫејҸ
еҰӮжһңдҪ дёҚи§үеҫ—жӯЈеҲҷиЎЁиҫҫејҸеҫҲйҡҫиҜ»еҶҷзҡ„иҜқпјҢиҰҒд№ҲдҪ жҳҜдёҖдёӘеӨ©жүҚпјҢиҰҒд№ҲпјҢдҪ дёҚжҳҜең°зҗғдәәгҖӮжӯЈеҲҷиЎЁиҫҫејҸзҡ„иҜӯжі•еҫҲд»ӨдәәеӨҙз–јпјҢеҚідҪҝеҜ№з»ҸеёёдҪҝз”Ёе®ғзҡ„дәәжқҘиҜҙд№ҹжҳҜеҰӮжӯӨгҖӮз”ұдәҺйҡҫдәҺиҜ»еҶҷпјҢе®№жҳ“еҮәй”ҷпјҢжүҖд»ҘжүҫдёҖз§Қе·Ҙе…·еҜ№жӯЈеҲҷиЎЁиҫҫејҸиҝӣиЎҢжөӢиҜ•жҳҜеҫҲжңүеҝ…иҰҒзҡ„гҖӮ
дёҚеҗҢзҡ„зҺҜеўғдёӢжӯЈеҲҷиЎЁиҫҫејҸзҡ„дёҖдәӣз»ҶиҠӮжҳҜдёҚзӣёеҗҢзҡ„пјҢжң¬ж•ҷзЁӢд»Ӣз»Қзҡ„жҳҜеҫ®иҪҜ .Net Framework 4.5 дёӢжӯЈеҲҷиЎЁиҫҫејҸзҡ„иЎҢдёәпјҢжүҖд»ҘпјҢжҲ‘еҗ‘дҪ жҺЁиҚҗжҲ‘зј–еҶҷзҡ„.NetдёӢзҡ„е·Ҙе…· RegesterгҖӮиҜ·еҸӮиҖғиҜҘйЎөйқўзҡ„иҜҙжҳҺжқҘе®үиЈ…е’ҢиҝҗиЎҢиҜҘиҪҜ件гҖӮ
дёӢйқўжҳҜRegesterиҝҗиЎҢж—¶зҡ„жҲӘеӣҫпјҡ
е…ғеӯ—з¬Ұ
зҺ°еңЁдҪ е·Із»ҸзҹҘйҒ“еҮ дёӘеҫҲжңүз”Ёзҡ„е…ғеӯ—з¬ҰдәҶпјҢеҰӮ\b,.,*пјҢиҝҳжңү\d.жӯЈеҲҷиЎЁиҫҫејҸйҮҢиҝҳжңүжӣҙеӨҡзҡ„е…ғеӯ—з¬ҰпјҢжҜ”еҰӮ\sеҢ№й…Қд»»ж„Ҹзҡ„з©әзҷҪз¬ҰпјҢеҢ…жӢ¬з©әж јпјҢеҲ¶иЎЁз¬Ұ(Tab)пјҢжҚўиЎҢз¬ҰпјҢдёӯж–Үе…Ёи§’з©әж јзӯүгҖӮ\wеҢ№й…Қеӯ—жҜҚжҲ–ж•°еӯ—жҲ–дёӢеҲ’зәҝжҲ–жұүеӯ—зӯүгҖӮ
дёӢйқўжқҘзңӢзңӢжӣҙеӨҡзҡ„дҫӢеӯҗпјҡ
\ba\w*\bеҢ№й…Қд»Ҙеӯ—жҜҚaејҖеӨҙзҡ„еҚ•иҜҚвҖ”вҖ”е…ҲжҳҜжҹҗдёӘеҚ•иҜҚејҖе§ӢеӨ„(\b)пјҢ然еҗҺжҳҜеӯ—жҜҚa,然еҗҺжҳҜд»»ж„Ҹж•°йҮҸзҡ„еӯ—жҜҚжҲ–ж•°еӯ—(\w*)пјҢжңҖеҗҺжҳҜеҚ•иҜҚз»“жқҹеӨ„(\b)гҖӮ
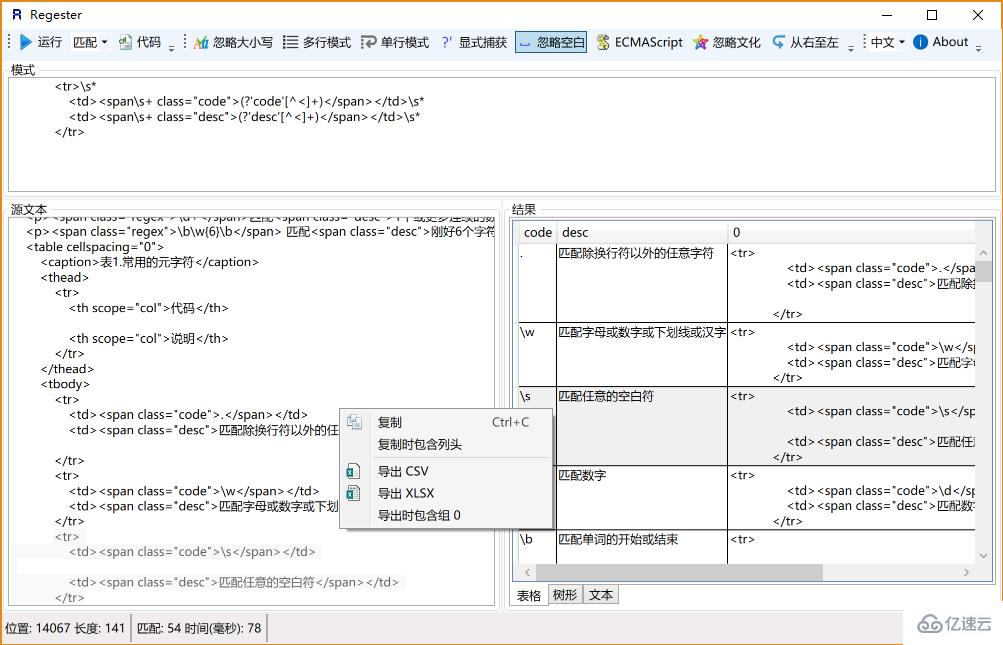
\d+еҢ№й…Қ1дёӘжҲ–жӣҙеӨҡиҝһз»ӯзҡ„ж•°еӯ—гҖӮиҝҷйҮҢзҡ„+жҳҜе’Ң*зұ»дјјзҡ„е…ғеӯ—з¬ҰпјҢдёҚеҗҢзҡ„жҳҜ*еҢ№й…ҚйҮҚеӨҚд»»ж„Ҹж¬Ў(еҸҜиғҪжҳҜ0ж¬Ў)пјҢиҖҢ+еҲҷеҢ№й…ҚйҮҚеӨҚ1ж¬ЎжҲ–жӣҙеӨҡж¬ЎгҖӮ
\b\w{6}\b еҢ№й…ҚеҲҡеҘҪ6дёӘеӯ—з¬Ұзҡ„еҚ•иҜҚгҖӮ
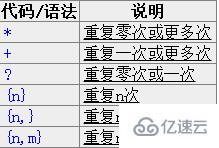
е…ғеӯ—з¬Ұ^пјҲе’Ңж•°еӯ—6еңЁеҗҢдёҖдёӘй”®дҪҚдёҠзҡ„з¬ҰеҸ·пјүе’Ң$йғҪеҢ№й…ҚдёҖдёӘдҪҚзҪ®пјҢиҝҷе’Ң\bжңүзӮ№зұ»дјјгҖӮ^еҢ№й…ҚдҪ иҰҒз”ЁжқҘжҹҘжүҫзҡ„еӯ—з¬ҰдёІзҡ„ејҖеӨҙпјҢ$еҢ№й…Қз»“е°ҫгҖӮиҝҷдёӨдёӘд»Јз ҒеңЁйӘҢиҜҒиҫ“е…Ҙзҡ„еҶ…е®№ж—¶йқһеёёжңүз”ЁпјҢжҜ”еҰӮдёҖдёӘзҪ‘з«ҷеҰӮжһңиҰҒжұӮдҪ еЎ«еҶҷзҡ„QQеҸ·еҝ…йЎ»дёә5дҪҚеҲ°12дҪҚж•°еӯ—ж—¶пјҢеҸҜд»ҘдҪҝз”Ёпјҡ^\d{5,12}$гҖӮ
иҝҷйҮҢзҡ„{5,12}е’ҢеүҚйқўд»Ӣз»ҚиҝҮзҡ„{2}жҳҜзұ»дјјзҡ„пјҢеҸӘдёҚиҝҮ{2}еҢ№й…ҚеҸӘиғҪдёҚеӨҡдёҚе°‘йҮҚеӨҚ2ж¬ЎпјҢ{5,12}еҲҷжҳҜйҮҚеӨҚзҡ„ж¬Ўж•°дёҚиғҪе°‘дәҺ5ж¬ЎпјҢдёҚиғҪеӨҡдәҺ12ж¬ЎпјҢеҗҰеҲҷйғҪдёҚеҢ№й…ҚгҖӮ
еӣ дёәдҪҝз”ЁдәҶ^е’Ң$пјҢжүҖд»Ҙиҫ“е…Ҙзҡ„ж•ҙдёӘеӯ—з¬ҰдёІйғҪиҰҒз”ЁжқҘе’Ң\d{5,12}жқҘеҢ№й…ҚпјҢд№ҹе°ұжҳҜиҜҙж•ҙдёӘиҫ“е…Ҙеҝ…йЎ»жҳҜ5еҲ°12дёӘж•°еӯ—пјҢеӣ жӯӨеҰӮжһңиҫ“е…Ҙзҡ„QQеҸ·иғҪеҢ№й…ҚиҝҷдёӘжӯЈеҲҷиЎЁиҫҫејҸзҡ„иҜқпјҢйӮЈе°ұз¬ҰеҗҲиҰҒжұӮдәҶгҖӮ
е’ҢеҝҪз•ҘеӨ§е°ҸеҶҷзҡ„йҖүйЎ№зұ»дјјпјҢжңүдәӣжӯЈеҲҷиЎЁиҫҫејҸеӨ„зҗҶе·Ҙе…·иҝҳжңүдёҖдёӘеӨ„зҗҶеӨҡиЎҢзҡ„йҖүйЎ№гҖӮеҰӮжһңйҖүдёӯдәҶиҝҷдёӘйҖүйЎ№пјҢ^е’Ң$зҡ„ж„Ҹд№үе°ұеҸҳжҲҗдәҶеҢ№й…ҚиЎҢзҡ„ејҖе§ӢеӨ„е’Ңз»“жқҹеӨ„гҖӮ
еӯ—з¬ҰиҪ¬д№ү
еҰӮжһңдҪ жғіжҹҘжүҫе…ғеӯ—з¬Ұжң¬иә«зҡ„иҜқпјҢжҜ”еҰӮдҪ жҹҘжүҫ.,жҲ–иҖ…*,е°ұеҮәзҺ°дәҶй—®йўҳпјҡдҪ жІЎеҠһжі•жҢҮе®ҡе®ғ们пјҢеӣ дёәе®ғ们дјҡиў«и§ЈйҮҠжҲҗеҲ«зҡ„ж„ҸжҖқгҖӮиҝҷж—¶дҪ е°ұеҫ—дҪҝз”Ё\жқҘеҸ–ж¶Ҳиҝҷдәӣеӯ—з¬Ұзҡ„зү№ж®Ҡж„Ҹд№үгҖӮеӣ жӯӨпјҢдҪ еә”иҜҘдҪҝз”Ё\.е’Ң\*гҖӮеҪ“然пјҢиҰҒжҹҘжүҫ\жң¬иә«пјҢдҪ д№ҹеҫ—з”Ё\\.
дҫӢеҰӮпјҡdeerchao\.netеҢ№й…Қdeerchao.netпјҢC:\\WindowsеҢ№й…ҚC:\WindowsгҖӮ
йҮҚеӨҚ
дҪ е·Із»ҸзңӢиҝҮдәҶеүҚйқўзҡ„*,+,{2},{5,12}иҝҷеҮ дёӘеҢ№й…ҚйҮҚеӨҚзҡ„ж–№ејҸдәҶгҖӮдёӢйқўжҳҜжӯЈеҲҷиЎЁиҫҫејҸдёӯжүҖжңүзҡ„йҷҗе®ҡз¬Ұ(жҢҮе®ҡж•°йҮҸзҡ„д»Јз ҒпјҢдҫӢеҰӮ*,{5,12}зӯү)пјҡ
дёӢйқўжҳҜдёҖдәӣдҪҝз”ЁйҮҚеӨҚзҡ„дҫӢеӯҗпјҡ
Windows\d+еҢ№й…ҚWindowsеҗҺйқўи·ҹ1дёӘжҲ–жӣҙеӨҡж•°еӯ—
^\w+еҢ№й…ҚдёҖиЎҢзҡ„第дёҖдёӘеҚ•иҜҚ(жҲ–ж•ҙдёӘеӯ—з¬ҰдёІзҡ„第дёҖдёӘеҚ•иҜҚпјҢе…·дҪ“еҢ№й…Қе“ӘдёӘж„ҸжҖқеҫ—зңӢйҖүйЎ№и®ҫзҪ®)
еӯ—з¬Ұзұ»
иҰҒжғіжҹҘжүҫж•°еӯ—пјҢеӯ—жҜҚжҲ–ж•°еӯ—пјҢз©әзҷҪжҳҜеҫҲз®ҖеҚ•зҡ„пјҢеӣ дёәе·Із»ҸжңүдәҶеҜ№еә”иҝҷдәӣеӯ—з¬ҰйӣҶеҗҲзҡ„е…ғеӯ—з¬ҰпјҢдҪҶжҳҜеҰӮжһңдҪ жғіеҢ№й…ҚжІЎжңүйў„е®ҡд№үе…ғеӯ—з¬Ұзҡ„еӯ—з¬ҰйӣҶеҗҲ(жҜ”еҰӮе…ғйҹіеӯ—жҜҚa,e,i,o,u),еә”иҜҘжҖҺд№ҲеҠһпјҹ
еҫҲз®ҖеҚ•пјҢдҪ еҸӘйңҖиҰҒеңЁж–№жӢ¬еҸ·йҮҢеҲ—еҮәе®ғ们е°ұиЎҢдәҶпјҢеғҸ[aeiou]е°ұеҢ№й…Қд»»дҪ•дёҖдёӘиӢұж–Үе…ғйҹіеӯ—жҜҚпјҢ[.?!]еҢ№й…Қж ҮзӮ№з¬ҰеҸ·(.жҲ–?жҲ–!)гҖӮ
жҲ‘们д№ҹеҸҜд»ҘиҪ»жқҫең°жҢҮе®ҡдёҖдёӘеӯ—з¬ҰиҢғеӣҙпјҢеғҸ[0-9]д»ЈиЎЁзҡ„еҗ«ж„ҸдёҺ\dе°ұжҳҜе®Ңе…ЁдёҖиҮҙзҡ„пјҡдёҖдҪҚж•°еӯ—пјӣеҗҢзҗҶ[a-z0-9A-Z_]д№ҹе®Ңе…ЁзӯүеҗҢдәҺ\wпјҲеҰӮжһңеҸӘиҖғиҷ‘иӢұж–Үзҡ„иҜқпјүгҖӮ
жҲ‘们еҜ№е®ғиҝӣиЎҢдёҖдәӣеҲҶжһҗеҗ§пјҡйҰ–е…ҲжҳҜдёҖдёӘиҪ¬д№үеӯ—з¬Ұ\(,е®ғиғҪеҮәзҺ°0ж¬ЎжҲ–1ж¬Ў(?),然еҗҺжҳҜдёҖдёӘ0пјҢеҗҺйқўи·ҹзқҖ2дёӘж•°еӯ—(\d{2})пјҢ然еҗҺжҳҜ)жҲ–-жҲ–з©әж јдёӯзҡ„дёҖдёӘпјҢе®ғеҮәзҺ°1ж¬ЎжҲ–дёҚеҮәзҺ°(?)пјҢжңҖеҗҺжҳҜ8дёӘж•°еӯ—(\d{8})гҖӮ
еҲҶжһқжқЎд»¶
дёҚе№ёзҡ„жҳҜпјҢеҲҡжүҚйӮЈдёӘиЎЁиҫҫејҸд№ҹиғҪеҢ№й…Қ010)12345678жҲ–(022-87654321иҝҷж ·зҡ„вҖңдёҚжӯЈзЎ®вҖқзҡ„ж јејҸгҖӮиҰҒи§ЈеҶіиҝҷдёӘй—®йўҳпјҢжҲ‘们йңҖиҰҒз”ЁеҲ°еҲҶжһқжқЎд»¶гҖӮжӯЈеҲҷиЎЁиҫҫејҸйҮҢзҡ„еҲҶжһқжқЎд»¶жҢҮзҡ„жҳҜжңүеҮ з§Қ规еҲҷпјҢеҰӮжһңж»Ўи¶іе…¶дёӯд»»ж„ҸдёҖз§Қ规еҲҷйғҪеә”иҜҘеҪ“жҲҗеҢ№й…ҚпјҢе…·дҪ“ж–№жі•жҳҜз”Ё|жҠҠдёҚеҗҢзҡ„规еҲҷеҲҶйҡ”ејҖгҖӮеҗ¬дёҚжҳҺзҷҪпјҹжІЎе…ізі»пјҢзңӢдҫӢеӯҗпјҡ
0\d{2}-\d{8}|0\d{3}-\d{7}иҝҷдёӘиЎЁиҫҫејҸиғҪеҢ№й…ҚдёӨз§Қд»Ҙиҝһеӯ—еҸ·еҲҶйҡ”зҡ„з”өиҜқеҸ·з ҒпјҡдёҖз§ҚжҳҜдёүдҪҚеҢәеҸ·пјҢ8дҪҚжң¬ең°еҸ·(еҰӮ010-12345678)пјҢдёҖз§ҚжҳҜ4дҪҚеҢәеҸ·пјҢ7дҪҚжң¬ең°еҸ·(0376-2233445)гҖӮ
\(0\d{2}\)[- ]?\d{8}|0\d{2}[- ]?\d{8}иҝҷдёӘиЎЁиҫҫејҸеҢ№й…Қ3дҪҚеҢәеҸ·зҡ„з”өиҜқеҸ·з ҒпјҢе…¶дёӯеҢәеҸ·еҸҜд»Ҙз”Ёе°ҸжӢ¬еҸ·жӢ¬иө·жқҘпјҢд№ҹеҸҜд»ҘдёҚз”ЁпјҢеҢәеҸ·дёҺжң¬ең°еҸ·й—ҙеҸҜд»Ҙз”Ёиҝһеӯ—еҸ·жҲ–з©әж јй—ҙйҡ”пјҢд№ҹеҸҜд»ҘжІЎжңүй—ҙйҡ”гҖӮдҪ еҸҜд»ҘиҜ•иҜ•з”ЁеҲҶжһқжқЎд»¶жҠҠиҝҷдёӘиЎЁиҫҫејҸжү©еұ•жҲҗд№ҹж”ҜжҢҒ4дҪҚеҢәеҸ·зҡ„гҖӮ
\d{5}-\d{4}|\d{5}иҝҷдёӘиЎЁиҫҫејҸз”ЁдәҺеҢ№й…ҚзҫҺеӣҪзҡ„йӮ®ж”ҝзј–з ҒгҖӮзҫҺеӣҪйӮ®зј–зҡ„规еҲҷжҳҜ5дҪҚж•°еӯ—пјҢжҲ–иҖ…з”Ёиҝһеӯ—еҸ·й—ҙйҡ”зҡ„9дҪҚж•°еӯ—гҖӮд№ӢжүҖд»ҘиҰҒз»ҷеҮәиҝҷдёӘдҫӢеӯҗжҳҜеӣ дёәе®ғиғҪиҜҙжҳҺдёҖдёӘй—®йўҳпјҡдҪҝз”ЁеҲҶжһқжқЎд»¶ж—¶пјҢиҰҒжіЁж„Ҹеҗ„дёӘжқЎд»¶зҡ„йЎәеәҸгҖӮеҰӮжһңдҪ жҠҠе®ғж”№жҲҗ\d{5}|\d{5}-\d{4}зҡ„иҜқпјҢйӮЈд№Ҳе°ұеҸӘдјҡеҢ№й…Қ5дҪҚзҡ„йӮ®зј–(д»ҘеҸҠ9дҪҚйӮ®зј–зҡ„еүҚ5дҪҚ)гҖӮеҺҹеӣ жҳҜеҢ№й…ҚеҲҶжһқжқЎд»¶ж—¶пјҢе°Ҷдјҡд»Һе·ҰеҲ°еҸіең°жөӢиҜ•жҜҸдёӘжқЎд»¶пјҢеҰӮжһңж»Ўи¶ідәҶжҹҗдёӘеҲҶжһқзҡ„иҜқпјҢе°ұдёҚдјҡеҺ»еҶҚз®Ўе…¶е®ғзҡ„жқЎд»¶дәҶгҖӮ
еҲҶз»„
жҲ‘们已з»ҸжҸҗеҲ°дәҶжҖҺд№ҲйҮҚеӨҚеҚ•дёӘеӯ—з¬ҰпјҲзӣҙжҺҘеңЁеӯ—з¬ҰеҗҺйқўеҠ дёҠйҷҗе®ҡз¬Ұе°ұиЎҢдәҶпјүпјӣдҪҶеҰӮжһңжғіиҰҒйҮҚеӨҚеӨҡдёӘеӯ—з¬ҰеҸҲиҜҘжҖҺд№ҲеҠһпјҹдҪ еҸҜд»Ҙз”Ёе°ҸжӢ¬еҸ·жқҘжҢҮе®ҡеӯҗиЎЁиҫҫејҸ(д№ҹеҸ«еҒҡеҲҶз»„)пјҢ然еҗҺдҪ е°ұеҸҜд»ҘжҢҮе®ҡиҝҷдёӘеӯҗиЎЁиҫҫејҸзҡ„йҮҚеӨҚж¬Ўж•°дәҶпјҢдҪ д№ҹеҸҜд»ҘеҜ№еӯҗиЎЁиҫҫејҸиҝӣиЎҢе…¶е®ғдёҖдәӣж“ҚдҪң(еҗҺйқўдјҡжңүд»Ӣз»Қ)гҖӮ
(\d{1,3}\.){3}\d{1,3}жҳҜдёҖдёӘз®ҖеҚ•зҡ„IPең°еқҖеҢ№й…ҚиЎЁиҫҫејҸгҖӮиҰҒзҗҶи§ЈиҝҷдёӘиЎЁиҫҫејҸпјҢиҜ·жҢүдёӢеҲ—йЎәеәҸеҲҶжһҗе®ғпјҡ\d{1,3}еҢ№й…Қ1еҲ°3дҪҚзҡ„ж•°еӯ—пјҢ(\d{1,3}\.){3}еҢ№й…ҚдёүдҪҚж•°еӯ—еҠ дёҠдёҖдёӘиӢұж–ҮеҸҘеҸ·(иҝҷдёӘж•ҙдҪ“д№ҹе°ұжҳҜиҝҷдёӘеҲҶз»„)йҮҚеӨҚ3ж¬ЎпјҢжңҖеҗҺеҶҚеҠ дёҠдёҖдёӘдёҖеҲ°дёүдҪҚзҡ„ж•°еӯ—(\d{1,3})гҖӮ
дёҚе№ёзҡ„жҳҜпјҢе®ғд№ҹе°ҶеҢ№й…Қ256.300.888.999иҝҷз§ҚдёҚеҸҜиғҪеӯҳеңЁзҡ„IPең°еқҖгҖӮеҰӮжһңиғҪдҪҝз”Ёз®—жңҜжҜ”иҫғзҡ„иҜқпјҢжҲ–и®ёиғҪз®ҖеҚ•ең°и§ЈеҶіиҝҷдёӘй—®йўҳпјҢдҪҶжҳҜжӯЈеҲҷиЎЁиҫҫејҸдёӯ并дёҚжҸҗдҫӣе…ідәҺж•°еӯҰзҡ„д»»дҪ•еҠҹиғҪпјҢжүҖд»ҘеҸӘиғҪдҪҝз”ЁеҶ—й•ҝзҡ„еҲҶз»„пјҢйҖүжӢ©пјҢеӯ—з¬Ұзұ»жқҘжҸҸиҝ°дёҖдёӘжӯЈзЎ®зҡ„IPең°еқҖпјҡ((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)гҖӮ
зҗҶи§ЈиҝҷдёӘиЎЁиҫҫејҸзҡ„е…ій”®жҳҜзҗҶи§Ј2[0-4]\d|25[0-5]|[01]?\d\d?пјҢиҝҷйҮҢжҲ‘е°ұдёҚз»ҶиҜҙдәҶпјҢдҪ иҮӘе·ұеә”иҜҘиғҪеҲҶжһҗеҫ—еҮәжқҘе®ғзҡ„ж„Ҹд№үгҖӮ
еҸҚд№ү
жңүж—¶йңҖиҰҒжҹҘжүҫдёҚеұһдәҺжҹҗдёӘиғҪз®ҖеҚ•е®ҡд№үзҡ„еӯ—з¬Ұзұ»зҡ„еӯ—з¬ҰгҖӮжҜ”еҰӮжғіжҹҘжүҫйҷӨдәҶж•°еӯ—д»ҘеӨ–пјҢе…¶е®ғд»»ж„Ҹеӯ—з¬ҰйғҪиЎҢзҡ„жғ…еҶөпјҢиҝҷж—¶йңҖиҰҒз”ЁеҲ°еҸҚд№үпјҡ

дҫӢеӯҗпјҡ\S+еҢ№й…ҚдёҚеҢ…еҗ«з©әзҷҪз¬Ұзҡ„еӯ—з¬ҰдёІгҖӮ
<a[^>]+>еҢ№й…Қз”Ёе°–жӢ¬еҸ·жӢ¬иө·жқҘзҡ„д»ҘaејҖеӨҙзҡ„еӯ—з¬ҰдёІгҖӮ
еҗҺеҗ‘еј•з”Ё
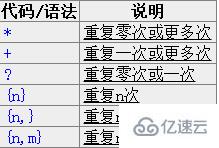
дҪҝз”Ёе°ҸжӢ¬еҸ·жҢҮе®ҡдёҖдёӘеӯҗиЎЁиҫҫејҸеҗҺпјҢеҢ№й…ҚиҝҷдёӘеӯҗиЎЁиҫҫејҸзҡ„ж–Үжң¬(д№ҹе°ұжҳҜжӯӨеҲҶз»„жҚ•иҺ·зҡ„еҶ…е®№)еҸҜд»ҘеңЁиЎЁиҫҫејҸжҲ–е…¶е®ғзЁӢеәҸдёӯдҪңиҝӣдёҖжӯҘзҡ„еӨ„зҗҶгҖӮй»ҳи®Өжғ…еҶөдёӢпјҢжҜҸдёӘеҲҶз»„дјҡиҮӘеҠЁжӢҘжңүдёҖдёӘз»„еҸ·пјҢ规еҲҷжҳҜпјҡд»Һе·Ұеҗ‘еҸіпјҢд»ҘеҲҶз»„зҡ„е·ҰжӢ¬еҸ·дёәж Үеҝ—пјҢ第дёҖдёӘеҮәзҺ°зҡ„еҲҶз»„зҡ„з»„еҸ·дёә1пјҢ第дәҢдёӘдёә2пјҢд»ҘжӯӨзұ»жҺЁгҖӮ
еҗҺеҗ‘еј•з”Ёз”ЁдәҺйҮҚеӨҚжҗңзҙўеүҚйқўжҹҗдёӘеҲҶз»„еҢ№й…Қзҡ„ж–Үжң¬гҖӮдҫӢеҰӮпјҢ\1д»ЈиЎЁеҲҶз»„1еҢ№й…Қзҡ„ж–Үжң¬гҖӮйҡҫд»ҘзҗҶи§ЈпјҹиҜ·зңӢзӨәдҫӢпјҡ
\b(\w+)\b\s+\1\bеҸҜд»Ҙз”ЁжқҘеҢ№й…ҚйҮҚеӨҚзҡ„еҚ•иҜҚпјҢеғҸgo go, жҲ–иҖ…kitty kittyгҖӮиҝҷдёӘиЎЁиҫҫејҸйҰ–е…ҲжҳҜдёҖдёӘеҚ•иҜҚпјҢд№ҹе°ұжҳҜеҚ•иҜҚејҖе§ӢеӨ„е’Ңз»“жқҹеӨ„д№Ӣй—ҙзҡ„еӨҡдәҺдёҖдёӘзҡ„еӯ—жҜҚжҲ–ж•°еӯ—(\b(\w+)\b)пјҢиҝҷдёӘеҚ•иҜҚдјҡиў«жҚ•иҺ·еҲ°зј–еҸ·дёә1зҡ„еҲҶз»„дёӯпјҢ然еҗҺжҳҜ1дёӘжҲ–еҮ дёӘз©әзҷҪз¬Ұ(\s+)пјҢжңҖеҗҺжҳҜеҲҶз»„1дёӯжҚ•иҺ·зҡ„еҶ…е®№пјҲд№ҹе°ұжҳҜеүҚйқўеҢ№й…Қзҡ„йӮЈдёӘеҚ•иҜҚпјү(\1)гҖӮ
дҪ д№ҹеҸҜд»ҘиҮӘе·ұжҢҮе®ҡеӯҗиЎЁиҫҫејҸзҡ„з»„еҗҚгҖӮиҰҒжҢҮе®ҡдёҖдёӘеӯҗиЎЁиҫҫејҸзҡ„з»„еҗҚпјҢиҜ·дҪҝз”Ёиҝҷж ·зҡ„иҜӯжі•пјҡ(?<Word>\w+)(жҲ–иҖ…жҠҠе°–жӢ¬еҸ·жҚўжҲҗ'д№ҹиЎҢпјҡ(?'Word'\w+)),иҝҷж ·е°ұжҠҠ\w+зҡ„з»„еҗҚжҢҮе®ҡдёәWordдәҶгҖӮиҰҒеҸҚеҗ‘еј•з”ЁиҝҷдёӘеҲҶз»„жҚ•иҺ·зҡ„еҶ…е®№пјҢдҪ еҸҜд»ҘдҪҝз”Ё\k<Word>,жүҖд»ҘдёҠдёҖдёӘдҫӢеӯҗд№ҹеҸҜд»ҘеҶҷжҲҗиҝҷж ·пјҡ\b(?<Word>\w+)\b\s+\k<Word>\bгҖӮ
дҪҝз”Ёе°ҸжӢ¬еҸ·зҡ„ж—¶еҖҷпјҢиҝҳжңүеҫҲеӨҡзү№е®ҡз”ЁйҖ”зҡ„иҜӯжі•гҖӮдёӢйқўеҲ—еҮәдәҶжңҖеёёз”Ёзҡ„дёҖдәӣпјҡ
йӣ¶е®Ҫж–ӯиЁҖ
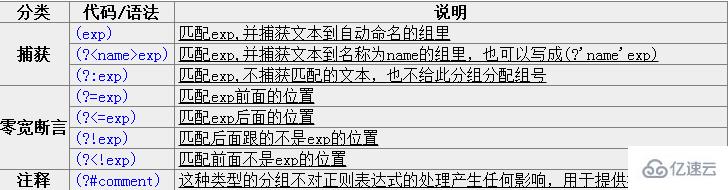
жҺҘдёӢжқҘзҡ„еӣӣдёӘз”ЁдәҺжҹҘжүҫеңЁжҹҗдәӣеҶ…е®№(дҪҶ并дёҚеҢ…жӢ¬иҝҷдәӣеҶ…е®№)д№ӢеүҚжҲ–д№ӢеҗҺзҡ„дёңиҘҝпјҢд№ҹе°ұжҳҜиҜҙе®ғ们еғҸ\b,^,$йӮЈж ·з”ЁдәҺжҢҮе®ҡдёҖдёӘдҪҚзҪ®пјҢиҝҷдёӘдҪҚзҪ®еә”иҜҘж»Ўи¶ідёҖе®ҡзҡ„жқЎд»¶(еҚіж–ӯиЁҖ)пјҢеӣ жӯӨе®ғ们д№ҹиў«з§°дёәйӣ¶е®Ҫж–ӯиЁҖгҖӮжңҖеҘҪиҝҳжҳҜжӢҝдҫӢеӯҗжқҘиҜҙжҳҺеҗ§пјҡ
(?=exp)д№ҹеҸ«йӣ¶е®ҪеәҰжӯЈйў„жөӢе…ҲиЎҢж–ӯиЁҖпјҢе®ғж–ӯиЁҖиҮӘиә«еҮәзҺ°зҡ„дҪҚзҪ®зҡ„еҗҺйқўиғҪеҢ№й…ҚиЎЁиҫҫејҸexpгҖӮжҜ”еҰӮ\b\w+(?=ing\b)пјҢеҢ№й…Қд»Ҙingз»“е°ҫзҡ„еҚ•иҜҚзҡ„еүҚйқўйғЁеҲҶ(йҷӨдәҶingд»ҘеӨ–зҡ„йғЁеҲҶ)пјҢеҰӮжҹҘжүҫI'm singing while you're dancing.ж—¶пјҢе®ғдјҡеҢ№й…Қsingе’ҢdancгҖӮ
(?<=exp)д№ҹеҸ«йӣ¶е®ҪеәҰжӯЈеӣһйЎҫеҗҺеҸ‘ж–ӯиЁҖпјҢе®ғж–ӯиЁҖиҮӘиә«еҮәзҺ°зҡ„дҪҚзҪ®зҡ„еүҚйқўиғҪеҢ№й…ҚиЎЁиҫҫејҸexpгҖӮжҜ”еҰӮ(?<=\bre)\w+\bдјҡеҢ№й…Қд»ҘreејҖеӨҙзҡ„еҚ•иҜҚзҡ„еҗҺеҚҠйғЁеҲҶ(йҷӨдәҶreд»ҘеӨ–зҡ„йғЁеҲҶ)пјҢдҫӢеҰӮеңЁжҹҘжүҫreading a bookж—¶пјҢе®ғеҢ№й…ҚadingгҖӮ
еҒҮеҰӮдҪ жғіиҰҒз»ҷдёҖдёӘеҫҲй•ҝзҡ„ж•°еӯ—дёӯжҜҸдёүдҪҚй—ҙеҠ дёҖдёӘйҖ—еҸ·(еҪ“然жҳҜд»ҺеҸіиҫ№еҠ иө·дәҶ)пјҢдҪ еҸҜд»Ҙиҝҷж ·жҹҘжүҫйңҖиҰҒеңЁеүҚйқўе’ҢйҮҢйқўж·»еҠ йҖ—еҸ·зҡ„йғЁеҲҶпјҡ((?<=\d)\d{3})+\bпјҢз”Ёе®ғеҜ№1234567890иҝӣиЎҢжҹҘжүҫж—¶з»“жһңжҳҜ234567890гҖӮ
дёӢйқўиҝҷдёӘдҫӢеӯҗеҗҢж—¶дҪҝз”ЁдәҶиҝҷдёӨз§Қж–ӯиЁҖпјҡ(?<=\s)\d+(?=\s)еҢ№й…Қд»Ҙз©әзҷҪз¬Ұй—ҙйҡ”зҡ„ж•°еӯ—(еҶҚж¬Ўејәи°ғпјҢдёҚеҢ…жӢ¬иҝҷдәӣз©әзҷҪз¬Ұ)гҖӮ
иҙҹеҗ‘йӣ¶е®Ҫж–ӯиЁҖ
еүҚйқўжҲ‘们жҸҗеҲ°иҝҮжҖҺд№ҲжҹҘжүҫдёҚжҳҜжҹҗдёӘеӯ—з¬ҰжҲ–дёҚеңЁжҹҗдёӘеӯ—з¬Ұзұ»йҮҢзҡ„еӯ—з¬Ұзҡ„ж–№жі•(еҸҚд№ү)гҖӮдҪҶжҳҜеҰӮжһңжҲ‘们еҸӘжҳҜжғіиҰҒзЎ®дҝқжҹҗдёӘеӯ—з¬ҰжІЎжңүеҮәзҺ°пјҢдҪҶ并дёҚжғіеҺ»еҢ№й…Қе®ғж—¶жҖҺд№ҲеҠһпјҹдҫӢеҰӮпјҢеҰӮжһңжҲ‘们жғіжҹҘжүҫиҝҷж ·зҡ„еҚ•иҜҚ--е®ғйҮҢйқўеҮәзҺ°дәҶеӯ—жҜҚq,дҪҶжҳҜqеҗҺйқўи·ҹзҡ„дёҚжҳҜеӯ—жҜҚu,жҲ‘们еҸҜд»Ҙе°қиҜ•иҝҷж ·пјҡ
\b\w*q[^u]\w*\bеҢ№й…ҚеҢ…еҗ«еҗҺйқўдёҚжҳҜеӯ—жҜҚuзҡ„еӯ—жҜҚqзҡ„еҚ•иҜҚгҖӮдҪҶжҳҜеҰӮжһңеӨҡеҒҡжөӢиҜ•(жҲ–иҖ…дҪ жҖқз»ҙи¶іеӨҹж•Ҹй”җпјҢзӣҙжҺҘе°ұи§ӮеҜҹеҮәжқҘдәҶ)пјҢдҪ дјҡеҸ‘зҺ°пјҢеҰӮжһңqеҮәзҺ°еңЁеҚ•иҜҚзҡ„з»“е°ҫзҡ„иҜқпјҢеғҸIraq,BenqпјҢиҝҷдёӘиЎЁиҫҫејҸе°ұдјҡеҮәй”ҷгҖӮиҝҷжҳҜеӣ дёә[^u]жҖ»иҰҒеҢ№й…ҚдёҖдёӘеӯ—з¬ҰпјҢжүҖд»ҘеҰӮжһңqжҳҜеҚ•иҜҚзҡ„жңҖеҗҺдёҖдёӘеӯ—з¬Ұзҡ„иҜқпјҢеҗҺйқўзҡ„[^u]е°ҶдјҡеҢ№й…ҚqеҗҺйқўзҡ„еҚ•иҜҚеҲҶйҡ”з¬Ұ(еҸҜиғҪжҳҜз©әж јпјҢжҲ–иҖ…жҳҜеҸҘеҸ·жҲ–е…¶е®ғзҡ„д»Җд№Ҳ)пјҢеҗҺйқўзҡ„\w*\bе°ҶдјҡеҢ№й…ҚдёӢдёҖдёӘеҚ•иҜҚпјҢдәҺжҳҜ\b\w*q[^u]\w*\bе°ұиғҪеҢ№й…Қж•ҙдёӘIraq fightingгҖӮиҙҹеҗ‘йӣ¶е®Ҫж–ӯиЁҖиғҪи§ЈеҶіиҝҷж ·зҡ„й—®йўҳпјҢеӣ дёәе®ғеҸӘеҢ№й…ҚдёҖдёӘдҪҚзҪ®пјҢ并дёҚж¶Ҳиҙ№д»»дҪ•еӯ—з¬ҰгҖӮзҺ°еңЁпјҢжҲ‘们еҸҜд»Ҙиҝҷж ·жқҘи§ЈеҶіиҝҷдёӘй—®йўҳпјҡ\b\w*q(?!u)\w*\bгҖӮ
йӣ¶е®ҪеәҰиҙҹйў„жөӢе…ҲиЎҢж–ӯиЁҖ(?!exp)пјҢж–ӯиЁҖжӯӨдҪҚзҪ®зҡ„еҗҺйқўдёҚиғҪеҢ№й…ҚиЎЁиҫҫејҸexpгҖӮдҫӢеҰӮпјҡ\d{3}(?!\d)еҢ№й…ҚдёүдҪҚж•°еӯ—пјҢиҖҢдё”иҝҷдёүдҪҚж•°еӯ—зҡ„еҗҺйқўдёҚиғҪжҳҜж•°еӯ—пјӣ\b((?!abc)\w)+\bеҢ№й…ҚдёҚеҢ…еҗ«иҝһз»ӯеӯ—з¬ҰдёІabcзҡ„еҚ•иҜҚгҖӮ
еҗҢзҗҶпјҢжҲ‘们еҸҜд»Ҙз”Ё(?<!exp),йӣ¶е®ҪеәҰиҙҹеӣһйЎҫеҗҺеҸ‘ж–ӯиЁҖжқҘж–ӯиЁҖжӯӨдҪҚзҪ®зҡ„еүҚйқўдёҚиғҪеҢ№й…ҚиЎЁиҫҫејҸexpпјҡ(?<![a-z])\d{7}еҢ№й…ҚеүҚйқўдёҚжҳҜе°ҸеҶҷеӯ—жҜҚзҡ„дёғдҪҚж•°еӯ—гҖӮ
дёҖдёӘжӣҙеӨҚжқӮзҡ„дҫӢеӯҗпјҡ(?<=<(\w+)>).*(?=<\/\1>)еҢ№й…ҚдёҚеҢ…еҗ«еұһжҖ§зҡ„з®ҖеҚ•HTMLж ҮзӯҫеҶ…йҮҢзҡ„еҶ…е®№гҖӮ(?<=<(\w+)>)жҢҮе®ҡдәҶиҝҷж ·зҡ„еүҚзјҖпјҡиў«е°–жӢ¬еҸ·жӢ¬иө·жқҘзҡ„еҚ•иҜҚ(жҜ”еҰӮеҸҜиғҪжҳҜ<b>)пјҢ然еҗҺжҳҜ.*(д»»ж„Ҹзҡ„еӯ—з¬ҰдёІ),жңҖеҗҺжҳҜдёҖдёӘеҗҺзјҖ(?=<\/\1>)гҖӮжіЁж„ҸеҗҺзјҖйҮҢзҡ„\/пјҢе®ғз”ЁеҲ°дәҶеүҚйқўжҸҗиҝҮзҡ„еӯ—з¬ҰиҪ¬д№үпјӣ\1еҲҷжҳҜдёҖдёӘеҸҚеҗ‘еј•з”ЁпјҢеј•з”Ёзҡ„жӯЈжҳҜжҚ•иҺ·зҡ„第дёҖз»„пјҢеүҚйқўзҡ„(\w+)еҢ№й…Қзҡ„еҶ…е®№пјҢиҝҷж ·еҰӮжһңеүҚзјҖе®һйҷ…дёҠжҳҜ<b>зҡ„иҜқпјҢеҗҺзјҖе°ұжҳҜ</b>дәҶгҖӮж•ҙдёӘиЎЁиҫҫејҸеҢ№й…Қзҡ„жҳҜ<b>е’Ң</b>д№Ӣй—ҙзҡ„еҶ…е®№(еҶҚж¬ЎжҸҗйҶ’пјҢдёҚеҢ…жӢ¬еүҚзјҖе’ҢеҗҺзјҖжң¬иә«)гҖӮ
жіЁйҮҠ
е°ҸжӢ¬еҸ·зҡ„еҸҰдёҖз§Қз”ЁйҖ”жҳҜйҖҡиҝҮиҜӯжі•(?#comment)жқҘеҢ…еҗ«жіЁйҮҠгҖӮдҫӢеҰӮпјҡ2[0-4]\d(?#200-249)|25[0-5](?#250-255)|[01]?\d\d?(?#0-199)гҖӮ
иҰҒеҢ…еҗ«жіЁйҮҠзҡ„иҜқпјҢжңҖеҘҪжҳҜеҗҜз”ЁвҖңеҝҪз•ҘжЁЎејҸйҮҢзҡ„з©әзҷҪз¬ҰвҖқйҖүйЎ№пјҢиҝҷж ·еңЁзј–еҶҷиЎЁиҫҫејҸж—¶иғҪд»»ж„Ҹзҡ„ж·»еҠ з©әж јпјҢTabпјҢжҚўиЎҢпјҢиҖҢе®һйҷ…дҪҝз”Ёж—¶иҝҷдәӣйғҪе°Ҷиў«еҝҪз•ҘгҖӮеҗҜз”ЁиҝҷдёӘйҖүйЎ№еҗҺпјҢеңЁ#еҗҺйқўеҲ°иҝҷдёҖиЎҢз»“жқҹзҡ„жүҖжңүж–Үжң¬йғҪе°Ҷиў«еҪ“жҲҗжіЁйҮҠеҝҪз•ҘжҺүгҖӮдҫӢеҰӮпјҢжҲ‘们еҸҜд»ҘеүҚйқўзҡ„дёҖдёӘиЎЁиҫҫејҸеҶҷжҲҗиҝҷж ·пјҡ
(?<= # ж–ӯиЁҖиҰҒеҢ№й…Қзҡ„ж–Үжң¬зҡ„еүҚзјҖ
<(\w+)> # жҹҘжүҫе°–жӢ¬еҸ·жӢ¬иө·жқҘзҡ„еӯ—жҜҚжҲ–ж•°еӯ—(еҚіHTML/XMLж Үзӯҫ)
) # еүҚзјҖз»“жқҹ
.* # еҢ№й…Қд»»ж„Ҹж–Үжң¬
(?= # ж–ӯиЁҖиҰҒеҢ№й…Қзҡ„ж–Үжң¬зҡ„еҗҺзјҖ
<\/\1> # жҹҘжүҫе°–жӢ¬еҸ·жӢ¬иө·жқҘзҡ„еҶ…е®№пјҡеүҚйқўжҳҜдёҖдёӘ"/"пјҢеҗҺйқўжҳҜе…ҲеүҚжҚ•иҺ·зҡ„ж Үзӯҫ
) # еҗҺзјҖз»“жқҹиҙӘе©ӘдёҺжҮ’жғ°
еҪ“жӯЈеҲҷиЎЁиҫҫејҸдёӯеҢ…еҗ«иғҪжҺҘеҸ—йҮҚеӨҚзҡ„йҷҗе®ҡз¬Ұж—¶пјҢйҖҡеёёзҡ„иЎҢдёәжҳҜпјҲеңЁдҪҝж•ҙдёӘиЎЁиҫҫејҸиғҪеҫ—еҲ°еҢ№й…Қзҡ„еүҚжҸҗдёӢпјүеҢ№й…Қе°ҪеҸҜиғҪеӨҡзҡ„еӯ—з¬ҰгҖӮд»ҘиҝҷдёӘиЎЁиҫҫејҸдёәдҫӢпјҡa.*bпјҢе®ғе°ҶдјҡеҢ№й…ҚжңҖй•ҝзҡ„д»ҘaејҖе§ӢпјҢд»Ҙbз»“жқҹзҡ„еӯ—з¬ҰдёІгҖӮеҰӮжһңз”Ёе®ғжқҘжҗңзҙўaababзҡ„иҜқпјҢе®ғдјҡеҢ№й…Қж•ҙдёӘеӯ—з¬ҰдёІaababгҖӮиҝҷиў«з§°дёәиҙӘе©ӘеҢ№й…ҚгҖӮ
жңүж—¶пјҢжҲ‘们жӣҙйңҖиҰҒжҮ’жғ°еҢ№й…ҚпјҢд№ҹе°ұжҳҜеҢ№й…Қе°ҪеҸҜиғҪе°‘зҡ„еӯ—з¬ҰгҖӮеүҚйқўз»ҷеҮәзҡ„йҷҗе®ҡз¬ҰйғҪеҸҜд»Ҙиў«иҪ¬еҢ–дёәжҮ’жғ°еҢ№й…ҚжЁЎејҸпјҢеҸӘиҰҒеңЁе®ғеҗҺйқўеҠ дёҠдёҖдёӘй—®еҸ·?гҖӮиҝҷж ·.*?е°ұж„Ҹе‘ізқҖеҢ№й…Қд»»ж„Ҹж•°йҮҸзҡ„йҮҚеӨҚпјҢдҪҶжҳҜеңЁиғҪдҪҝж•ҙдёӘеҢ№й…ҚжҲҗеҠҹзҡ„еүҚжҸҗдёӢдҪҝз”ЁжңҖе°‘зҡ„йҮҚеӨҚгҖӮзҺ°еңЁзңӢзңӢжҮ’жғ°зүҲзҡ„дҫӢеӯҗеҗ§пјҡ
a.*?bеҢ№й…ҚжңҖзҹӯзҡ„пјҢд»ҘaејҖе§ӢпјҢд»Ҙbз»“жқҹзҡ„еӯ—з¬ҰдёІгҖӮеҰӮжһңжҠҠе®ғеә”з”ЁдәҺaababзҡ„иҜқпјҢе®ғдјҡеҢ№й…ҚaabпјҲ第дёҖеҲ°з¬¬дёүдёӘеӯ—з¬Ұпјүе’ҢabпјҲ第еӣӣеҲ°з¬¬дә”дёӘеӯ—з¬ҰпјүгҖӮ

еӨ„зҗҶйҖүйЎ№
дёҠйқўд»Ӣз»ҚдәҶеҮ дёӘйҖүйЎ№еҰӮеҝҪз•ҘеӨ§е°ҸеҶҷпјҢеӨ„зҗҶеӨҡиЎҢзӯүпјҢиҝҷдәӣйҖүйЎ№иғҪз”ЁжқҘж”№еҸҳеӨ„зҗҶжӯЈеҲҷиЎЁиҫҫејҸзҡ„ж–№ејҸгҖӮдёӢйқўжҳҜ.Netдёӯеёёз”Ёзҡ„жӯЈеҲҷиЎЁиҫҫејҸйҖүйЎ№пјҡ

дёҖдёӘз»Ҹеёёиў«й—®еҲ°зҡ„й—®йўҳжҳҜпјҡжҳҜдёҚжҳҜеҸӘиғҪеҗҢж—¶дҪҝз”ЁеӨҡиЎҢжЁЎејҸе’ҢеҚ•иЎҢжЁЎејҸдёӯзҡ„дёҖз§Қпјҹзӯ”жЎҲжҳҜпјҡдёҚжҳҜгҖӮиҝҷдёӨдёӘйҖүйЎ№д№Ӣй—ҙжІЎжңүд»»дҪ•е…ізі»пјҢйҷӨдәҶе®ғ们зҡ„еҗҚеӯ—жҜ”иҫғзӣёдјјпјҲд»ҘиҮідәҺи®©дәәж„ҹеҲ°з–‘жғ‘пјүд»ҘеӨ–гҖӮ
е№іиЎЎз»„/йҖ’еҪ’еҢ№й…Қ
жңүж—¶жҲ‘们йңҖиҰҒеҢ№й…ҚеғҸ( 100 * ( 50 + 15 ) )иҝҷж ·зҡ„еҸҜеөҢеҘ—зҡ„еұӮж¬ЎжҖ§з»“жһ„пјҢиҝҷж—¶з®ҖеҚ•ең°дҪҝз”Ё\(.+\)еҲҷеҸӘдјҡеҢ№й…ҚеҲ°жңҖе·Ұиҫ№зҡ„е·ҰжӢ¬еҸ·е’ҢжңҖеҸіиҫ№зҡ„еҸіжӢ¬еҸ·д№Ӣй—ҙзҡ„еҶ…е®№(иҝҷйҮҢжҲ‘们讨и®әзҡ„жҳҜиҙӘе©ӘжЁЎејҸпјҢжҮ’жғ°жЁЎејҸд№ҹжңүдёӢйқўзҡ„й—®йўҳ)гҖӮеҒҮеҰӮеҺҹжқҘзҡ„еӯ—з¬ҰдёІйҮҢзҡ„е·ҰжӢ¬еҸ·е’ҢеҸіжӢ¬еҸ·еҮәзҺ°зҡ„ж¬Ўж•°дёҚзӣёзӯүпјҢжҜ”еҰӮ( 5 / ( 3 + 2 ) ) )пјҢйӮЈжҲ‘们зҡ„еҢ№й…Қз»“жһңйҮҢдёӨиҖ…зҡ„дёӘж•°д№ҹдёҚдјҡзӣёзӯүгҖӮжңүжІЎжңүеҠһжі•еңЁиҝҷж ·зҡ„еӯ—з¬ҰдёІйҮҢеҢ№й…ҚеҲ°жңҖй•ҝзҡ„пјҢй…ҚеҜ№зҡ„жӢ¬еҸ·д№Ӣй—ҙзҡ„еҶ…е®№е‘ўпјҹ
дёәдәҶйҒҝе…Қ(е’Ң\(жҠҠдҪ зҡ„еӨ§и„‘еҪ»еә•жҗһзіҠж¶ӮпјҢжҲ‘们иҝҳжҳҜз”Ёе°–жӢ¬еҸ·д»ЈжӣҝеңҶжӢ¬еҸ·еҗ§гҖӮзҺ°еңЁжҲ‘们зҡ„й—®йўҳеҸҳжҲҗдәҶеҰӮдҪ•жҠҠxx <aa <bbb> <bbb> aa> yyиҝҷж ·зҡ„еӯ—з¬ҰдёІйҮҢпјҢжңҖй•ҝзҡ„й…ҚеҜ№зҡ„е°–жӢ¬еҸ·еҶ…зҡ„еҶ…е®№жҚ•иҺ·еҮәжқҘпјҹ
иҝҷйҮҢйңҖиҰҒз”ЁеҲ°д»ҘдёӢзҡ„иҜӯжі•жһ„йҖ пјҡ
(?'group') жҠҠжҚ•иҺ·зҡ„еҶ…е®№е‘ҪеҗҚдёәgroup,并еҺӢе…Ҙе Ҷж Ҳ(Stack)
(?'-group') д»Һе Ҷж ҲдёҠеј№еҮәжңҖеҗҺеҺӢе…Ҙе Ҷж Ҳзҡ„еҗҚдёәgroupзҡ„жҚ•иҺ·еҶ…е®№пјҢеҰӮжһңе Ҷж Ҳжң¬жқҘдёәз©әпјҢеҲҷжң¬еҲҶз»„зҡ„еҢ№й…ҚеӨұиҙҘ
(?(group)yes|no) еҰӮжһңе Ҷж ҲдёҠеӯҳеңЁд»ҘеҗҚдёәgroupзҡ„жҚ•иҺ·еҶ…е®№зҡ„иҜқпјҢ继з»ӯеҢ№й…ҚyesйғЁеҲҶзҡ„иЎЁиҫҫејҸпјҢеҗҰеҲҷ继з»ӯеҢ№й…ҚnoйғЁеҲҶ
(?!) йӣ¶е®Ҫиҙҹеҗ‘е…ҲиЎҢж–ӯиЁҖпјҢз”ұдәҺжІЎжңүеҗҺзјҖиЎЁиҫҫејҸпјҢиҜ•еӣҫеҢ№й…ҚжҖ»жҳҜеӨұиҙҘ
жҲ‘们йңҖиҰҒеҒҡзҡ„жҳҜжҜҸзў°еҲ°дәҶе·ҰжӢ¬еҸ·пјҢе°ұеңЁеҺӢе…ҘдёҖдёӘ"Open",жҜҸзў°еҲ°дёҖдёӘеҸіжӢ¬еҸ·пјҢе°ұеј№еҮәдёҖдёӘпјҢеҲ°дәҶжңҖеҗҺе°ұзңӢзңӢе Ҷж ҲжҳҜеҗҰдёәз©әпјҚпјҚеҰӮжһңдёҚдёәз©әйӮЈе°ұиҜҒжҳҺе·ҰжӢ¬еҸ·жҜ”еҸіжӢ¬еҸ·еӨҡпјҢйӮЈеҢ№й…Қе°ұеә”иҜҘеӨұиҙҘгҖӮжӯЈеҲҷиЎЁиҫҫејҸеј•ж“ҺдјҡиҝӣиЎҢеӣһжәҜ(ж”ҫејғжңҖеүҚйқўжҲ–жңҖеҗҺйқўзҡ„дёҖдәӣеӯ—з¬Ұ)пјҢе°ҪйҮҸдҪҝж•ҙдёӘиЎЁиҫҫејҸеҫ—еҲ°еҢ№й…ҚгҖӮ
< #жңҖеӨ–еұӮзҡ„е·ҰжӢ¬еҸ·
[^<>]* #жңҖеӨ–еұӮзҡ„е·ҰжӢ¬еҸ·еҗҺйқўзҡ„дёҚжҳҜжӢ¬еҸ·зҡ„еҶ…е®№
(
(
(?'Open'<) #зў°еҲ°дәҶе·ҰжӢ¬еҸ·пјҢеңЁй»‘жқҝдёҠеҶҷдёҖдёӘ"Open"
[^<>]* #еҢ№й…Қе·ҰжӢ¬еҸ·еҗҺйқўзҡ„дёҚжҳҜжӢ¬еҸ·зҡ„еҶ…е®№
)+
(
(?'-Open'>) #зў°еҲ°дәҶеҸіжӢ¬еҸ·пјҢж“ҰжҺүдёҖдёӘ"Open"
[^<>]* #еҢ№й…ҚеҸіжӢ¬еҸ·еҗҺйқўдёҚжҳҜжӢ¬еҸ·зҡ„еҶ…е®№
)+
)*
(?(Open)(?!)) #еңЁйҒҮеҲ°жңҖеӨ–еұӮзҡ„еҸіжӢ¬еҸ·еүҚйқўпјҢеҲӨж–ӯй»‘жқҝдёҠиҝҳжңүжІЎжңүжІЎж“ҰжҺүзҡ„"Open"пјӣеҰӮжһңиҝҳжңүпјҢеҲҷеҢ№й…ҚеӨұиҙҘ
> #жңҖеӨ–еұӮзҡ„еҸіжӢ¬еҸ·е№іиЎЎз»„зҡ„дёҖдёӘжңҖеёёи§Ғзҡ„еә”з”Ёе°ұжҳҜеҢ№й…ҚHTML,дёӢйқўиҝҷдёӘдҫӢеӯҗеҸҜд»ҘеҢ№й…ҚеөҢеҘ—зҡ„<div>ж Үзӯҫпјҡ<div[^>]*>[^<>]*(((?'Open'<div[^>]*>)[^<>]*)+((?'-Open'</div>)[^<>]*)+)*(?(Open)(?!))</div>.
дёҠиҫ№е·Із»ҸжҸҸиҝ°дәҶжһ„йҖ жӯЈеҲҷиЎЁиҫҫејҸзҡ„еӨ§йҮҸе…ғзҙ пјҢдҪҶжҳҜиҝҳжңүеҫҲеӨҡжІЎжңүжҸҗеҲ°зҡ„дёңиҘҝгҖӮдёӢйқўжҳҜдёҖдәӣжңӘжҸҗеҲ°зҡ„е…ғзҙ зҡ„еҲ—иЎЁпјҢеҢ…еҗ«иҜӯжі•е’Ңз®ҖеҚ•зҡ„иҜҙжҳҺгҖӮдҪ еҸҜд»ҘеңЁзҪ‘дёҠжүҫеҲ°жӣҙиҜҰз»Ҷзҡ„еҸӮиҖғиө„ж–ҷжқҘеӯҰд№ е®ғ们--еҪ“дҪ йңҖиҰҒз”ЁеҲ°е®ғ们зҡ„ж—¶еҖҷгҖӮеҰӮжһңдҪ е®үиЈ…дәҶMSDN Library,дҪ д№ҹеҸҜд»ҘеңЁйҮҢйқўжүҫеҲ°.netдёӢжӯЈеҲҷиЎЁиҫҫејҸиҜҰз»Ҷзҡ„ж–ҮжЎЈгҖӮ

д»ҘдёҠжҳҜвҖңжӯЈеҲҷиЎЁиҫҫејҸжҳҜд»Җд№ҲвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ





