这篇文章将为大家详细讲解有关Node Stream中运行机制的示例分析,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
你可以把流理解成一种传输的能力。通过流,可以以平缓的方式,无副作用的将数据传输到目的地。在Node中,Node Stream创建的流都是专用于String和Buffer上的,一般情况下使用Buffer。Stream表示的是一种传输能力,Buffer是传输内容的载体 (可以这样理解,Stream:外卖小哥哥, Buffer:你的外卖)。创建流的时候将ObjectMode设置true ,Stream同样可以传输任意类型的JS对象(除了null,null在流中有特殊用途)。
现在有个需求,我们要向客户端传输一个大文件。如果采用下面的方式
const fs = require('fs');
const server = require('http').createServer();
server.on('request', (req, res) => {
fs.readFile('./big.file', (err, data) => {
if (err) throw err;
res.end(data);
});
});
server.listen(8000);每次接收一个请求,就要把这个大文件读入内存,然后再传输给客户端。通过这种方式可能会产生以下三种后果:
内存耗尽
拖慢其他进程
增加垃圾回收器的负载
所以这种方式在传输大文件的情况下,不是一个好的方案。并发量一大,几百个请求过来很容易就将内存耗尽。
如果采用流呢?
const fs = require('fs');
const server = require('http').createServer();
server.on('request', (req, res) => {
const src = fs.createReadStream('./big.file');
src.pipe(res);
});
server.listen(8000);采用这种方式,不会占用太多内存,读取一点就传输一点,整个过程平缓进行,非常优雅。如果想在传输的过程中,想对文件进行处理,比如压缩、加密等等,也很好扩展(后面会具体介绍)。
流在Node中无处不在。从下图中可以看出:

Stream分为四大类:
Readable(可读流)
Writable (可写流)
Duplex (双工流)
Transform (转换流)
可读流中的数据,在以下两种模式下都能产生数据。
Flowing Mode
Non-Flowing Mode
两种模式下,触发的方式以及消耗的方式不一样。
Flowing Mode:数据会源源不断地生产出来,形成“流动”现象。监听流的data事件便可进入该模式。
Non-Flowing Mode下:需要显示地调用read()方法,才能获取数据。
两种模式可以互相转换
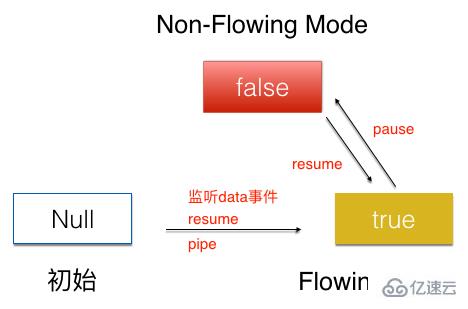
流的初始状态是Null,通过监听data事件,或者pipe方法,调用resume方法,将流转为Flowing Mode状态。Flowing Mode状态下调用pause方法,将流置为Non-Flowing Mode状态。Non-Flowing Mode状态下调用resume方法,同样可以将流置为Flowing Mode状态。
下面详细介绍下两种模式下,Readable流的运行机制。
在Flowing Mode状态下,创建的myReadable读流,直接监听data事件,数据就源源不断的流出来进行消费了。
myReadable.on('data',function(chunk){
consume(chunk);//消费流
})一旦监听data事件之后,Readable内部的流程如下图所示
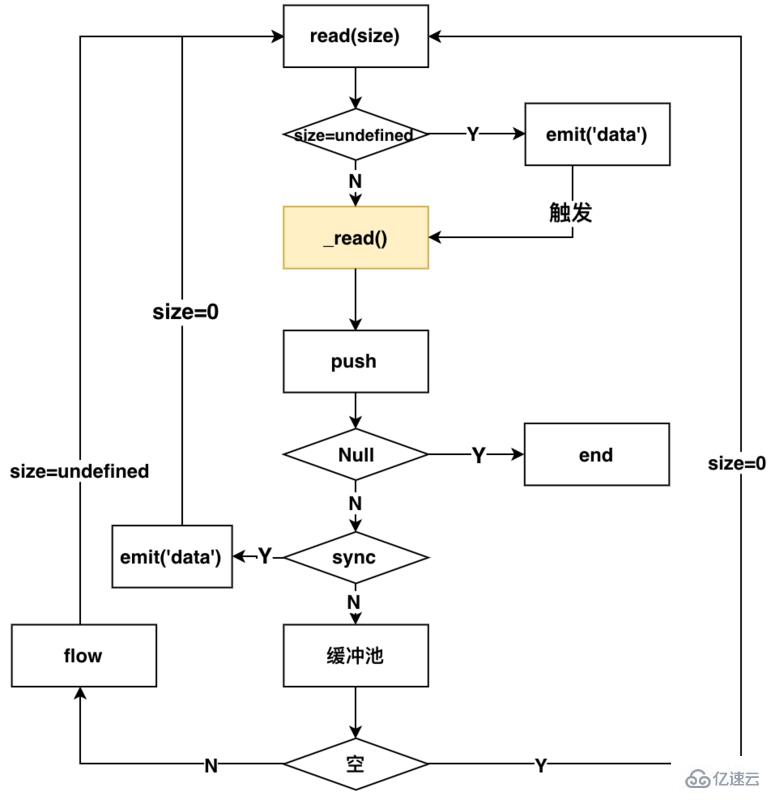
核心的方法是流内部的read方法,它在参数n为不同值时,分别触发不同的操作。下面描述中的hightwatermark表示的是流内部的缓冲池的大小。
n=undefined(消费数据,并触发一次可读流)
n=0(触发一次可读流,但是不会消费)
n>hightwatermark(修改hightwatermark的值)
n<buffer的总数据数(直接返回n个字节的数据)
n>buffer (可以返回null,也可以返回buffer所有的数据(当时最后一次读取))
图中黄色标识的_read(),是用户实现流所需要自己实现的方法,这个方法就是实际读取流的方式(可以这样理解,外卖平台给你提供外卖的能力,那_read()方法就相当于你下单点外卖)。后面会详细介绍如何实现_read方法。
以上的流程可以描述为:监听data方法,Readable内部就会调用read方法,来进行触发读流操作,通过判断是同步还是异步读取,来决定读取的数据是否放入缓冲区。如果为异步的,那么就要调用flow方法,来继续触发read方法,来读取流,同时根据size参数判定是否emit('data')来消费流,循环读取。如果是同步的,那就emit('data')来消费流,同时继续触发read方法,来读取流。一旦push方法传入的是null,整个流就结束了。
从使用者的角度来看,在这种模式下,你可以通过下面的方式来使用流
const fs = require('./fs');
const readFile = fs.createReadStream('./big.file');
const writeFile = fs.createWriteStream('./writeFile.js');
readFile.on('data',function(chunk){
writeFile1.write(chunk);
})相对于Flowing mode,Non-Flowing Mode要相对简单很多。
消费该模式下的流,需要使用下面的方式
myReadable.on(‘readable’,function(){
const chunk = myReadable.read()
consume(chunk);//消费流
})在Non-Flowing Mode下,Readable内部的流程如下图:
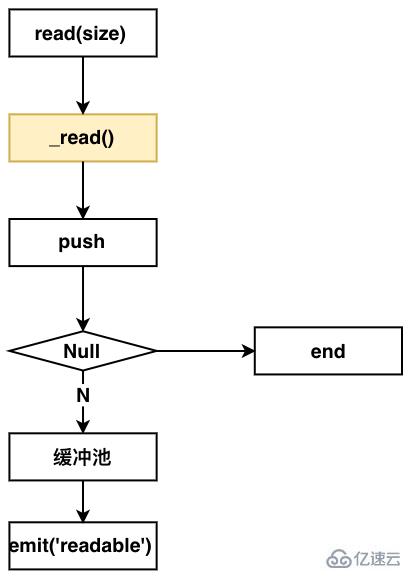
从这个图上看出,你要实现该模式的读流,同样要实现一个_read方法。
整个流程如下:监听readable方法,Readable内部就会调用read方法。调用用户实现的_read方法,来push数据到缓冲池,然后发送emit readable事件,通知用户端消费。
从使用者的角度来看,你可以通过下面的方式来使用该模式下的流
const fs = require('fs');
const readFile = fs.createReadStream('./big.file');
const writeFile = fs.createWriteStream('./writeFile.js');
readFile.on('readable',function(chunk) {
while (null !== (chunk = myReadable.read())) {
writeFile.write(chunk);
}
});相对于读流,写流的机制就更容易理解了。
写流使用下面的方式进行数据写入
myWrite.write(chunk);调用write后,内部Writable的流程如下图所示
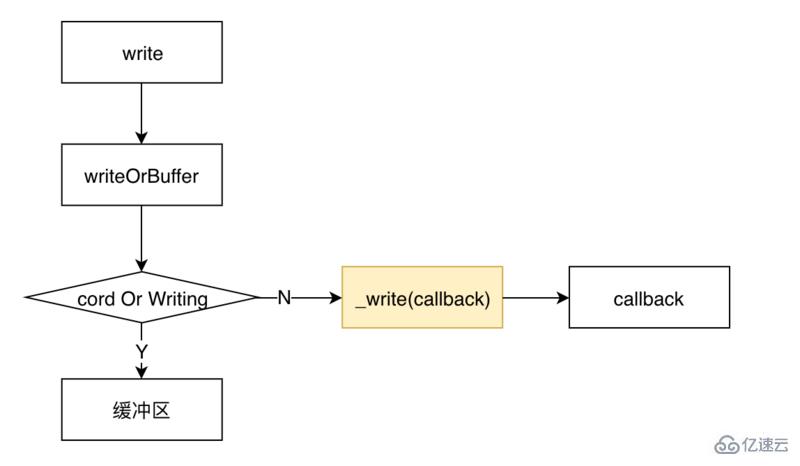
类似于读流,实现一个写流,同样需要用户实现一个_write方法。
整个流程是这样的:调用write之后,会首先判定是否要写入缓冲区。如果不需要,那就调用用户实现的_write方法,将流写入到相应的地方,_write会调用一个writeable内部的一个回调函数。
从使用者的角度来看,使用一个写流,采用下面的代码所示的方式。
const fs = require('fs');
const readFile = fs.createReadStream('./big.file');
const writeFile = fs.createWriteStream('./writeFile.js');
readFile.on('data',function(chunk) {
writeFile.write(chunk);
})可以看到,使用写流是非常简单的。
我们先讲解一下如何实现一个读流和写流,再来看Duplex和Transform是什么,因为了解了如何实现一个读流和写流,再来理解Duplex和Transform就非常简单了。
实现自定义的Readable,只需要实现一个_read方法即可,需要在_read方法中调用push方法来实现数据的生产。如下面的代码所示:
const Readable = require('stream').Readable;
class MyReadable extends Readable {
constructor(dataSource, options) {
super(options);
this.dataSource = dataSource;
}
_read() {
const data = this.dataSource.makeData();
setTimeout(()=>{
this.push(data);
});
}
}
// 模拟资源池
const dataSource = {
data: new Array(10).fill('-'),
makeData() {
if (!dataSource.data.length) return null;
return dataSource.data.pop();
}
};
const myReadable = new MyReadable(dataSource,);
myReadable.on('readable', () => {
let chunk;
while (null !== (chunk = myReadable.read())) {
console.log(chunk);
}
});实现自定义的writable,只需要实现一个_write方法即可。在_write中消费chunk写入到相应地方,并且调用callback回调。如下面代码所示:
const Writable = require('stream').Writable;
class Mywritable extends Writable{
constuctor(options){
super(options);
}
_write(chunk,endcoding,callback){
console.log(chunk);
callback && callback();
}
}
const myWritable = new Mywritable();双工流:简单理解,就是讲一个Readable流和一个Writable流绑定到一起,它既可以用来做读流,又可以用来做写流。
实现一个Duplex流,你需要同时实现_read和_write方法。
有一点需要注意的是:它所包含的 Readable流和Writable流是完全独立,互不影响的两个流,两个流使用的不是同一个缓冲区。通过下面的代码可以验证
// 模拟资源池1
const dataSource1 = {
data: new Array(10).fill('a'),
makeData() {
if (!dataSource1.data.length) return null;
return dataSource1.data.pop();
}
};
// 模拟资源池2
const dataSource2 = {
data: new Array(10).fill('b'),
makeData() {
if (!dataSource2.data.length) return null;
return dataSource2.data.pop();
}
};
const Readable = require('stream').Readable;
class MyReadable extends Readable {
constructor(dataSource, options) {
super(options);
this.dataSource = dataSource;
}
_read() {
const data = this.dataSource.makeData();
setTimeout(()=>{
this.push(data);
})
}
}
const Writable = require('stream').Writable;
class MyWritable extends Writable{
constructor(options){
super(options);
}
_write(chunk, encoding, callback) {
console.log(chunk.toString());
callback && callback();
}
}
const Duplex = require('stream').Duplex;
class MyDuplex extends Duplex{
constructor(dataSource,options) {
super(options);
this.dataSource = dataSource;
}
_read() {
const data = this.dataSource.makeData();
setTimeout(()=>{
this.push(data);
})
}
_write(chunk, encoding, callback) {
console.log(chunk.toString());
callback && callback();
}
}
const myWritable = new MyWritable();
const myReadable = new MyReadable(dataSource1);
const myDuplex = new MyDuplex(dataSource1);
myReadable.pipe(myDuplex).pipe(myWritable);打印的结果是
abababababababababab
从这个结果可以看出,myReadable.pipe(myDuplex),myDuplex充当的是写流,写入的内容是a;myDuplex.pipe(myWritable),myDuplex充当的是读流,往myWritable写的却是b;所以说它所包含的 Readable流和Writable流是完全独立的。
理解了Duplex,就更好理解Transform了。Transform是一个转换流,它既有读的功能又有写的功能,但是它和Duplex不同的是,它的读流和写流共用同一个缓冲区;也就是说,通过它读入什么,那它就能写入什么。
实现一个Transform,你只需要实现一个_transform方法。比如最简单的Transform:PassThrough,其源代码如下所示
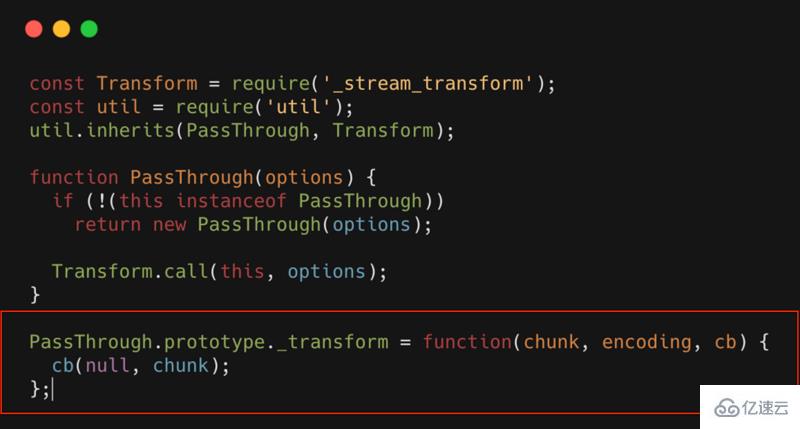
PassThrough就是一个Transform,但是这个转换流,什么也没做,相当于一个透明的转换流。可以看到_transform中什么都没有,只是简单的将数据进行回调。
如果我们在这个环节做些扩展,只需要在_transform中直接扩展就行了。比如我们可以对流进行压缩,加密,混淆等等操作。
最后介绍一个流中非常重要的一个概念:背压。要了解这个,我们首先来看下pipe和highWaterMaker是什么。
首先看下下面的代码
const fs = require('./fs');
const readFile = fs.createReadStream('./big.file');
const writeFile = fs.createWriteStream('./writeFile.js');
readFile.pipe(writeFile);上面的代码和下面是等价的
const fs = require('./fs');
const readFile = fs.createReadStream('./big.file');
const writeFile = fs.createWriteStream('./writeFile.js');
readFile.on('data',function(data){
var flag = ws.write(data);
if(!flag){ // 当前写流缓冲区已满,暂停读数据
readFile.pause();
}
})
writeFile.on('drain',function()){
readFile.resume();// 当前写流缓冲区已清空,重新开始读流
}
readFile.on('end',function(data){
writeFile.end();//将写流缓冲区的数据全部写入,并且关闭写入的文件
})pipe所做的操作就是相当于为写流和读流自动做了速度的匹配。
读写流速度不匹配的情况下,一般情况下不会造成什么问题,但是会造成内存增加。内存消耗增加,就有可能会带来一系列的问题。所以在使用的流的时候,强烈推荐使用pipe。
highWaterMaker说白了,就是定义缓冲区的大小。
默认16Kb(Readable最大8M)
可以自定义
背压的概念可以理解为:为了防止读写流速度不匹配而产生的一种调整机制;背压该调整机制的触发时机,受限于highWaterMaker设置的大小。
如上面的代码 var flag = ws.write(data);,一旦写流的缓冲区满了,那flag就会置为false,反向促进读流的速度调整。
主要有以下场景
文件操作(复制,压缩,解压,加密等)
下面的就很容易就实现了文件复制的功能。
const fs = require('fs');
const readFile = fs.createReadStream('big.file');
const writeFile = fs.createWriteStream('big_copy.file');
readFile.pipe(writeFile);那我们想在复制的过程中对文件进行压缩呢?
const fs = require('fs');
const readFile = fs.createReadStream('big.file');
const writeFile = fs.createWriteStream('big.gz');
const zlib = require('zlib');
readFile.pipe(zlib.createGzip()).pipe(writeFile);实现解压、加密也是类似的。
静态文件服务器
比如需要返回一个html,可以使用如下代码。
var http = require('http');
var fs = require('fs');
http.createServer(function(req,res){
fs.createReadStream('./a.html').pipe(res);
}).listen(8000);关于“Node Stream中运行机制的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



