1.爬取页面效果图
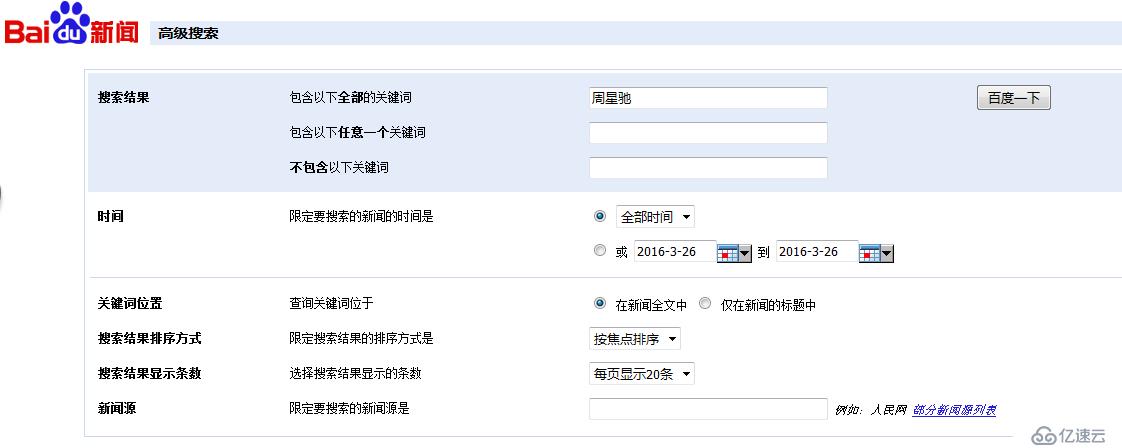
点击"百度一下"按钮前页面
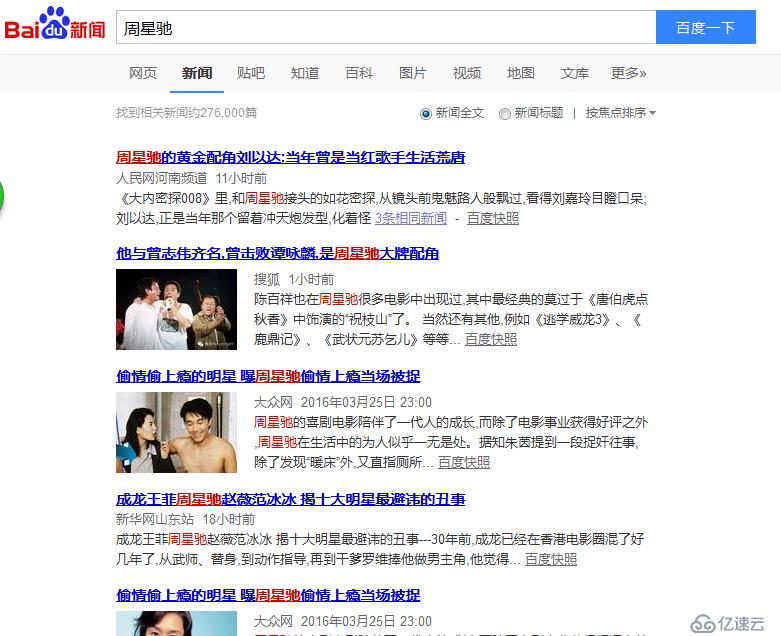
点击"百度一下"按钮后页面
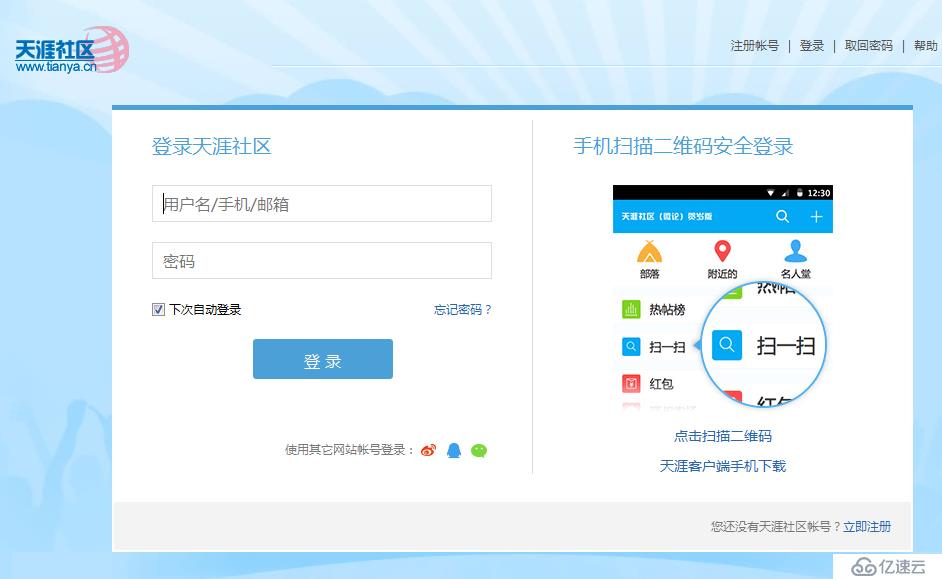
天涯社区登录页面
登录进去之后个人主页
二、具体实现代码
HtmlUnit(底层也是采用httpclient)和jsoup API
package com.yuanhai.test;
import java.io.IOException;
import java.net.MalformedURLException;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.safety.Whitelist;
import org.jsoup.select.Elements;
import org.junit.Assert;
import org.junit.Test;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.DefaultCredentialsProvider;
import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
import com.gargoylesoftware.htmlunit.html.HtmlButton;
import com.gargoylesoftware.htmlunit.html.HtmlDivision;
import com.gargoylesoftware.htmlunit.html.HtmlForm;
import com.gargoylesoftware.htmlunit.html.HtmlInput;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlSubmitInput;
import com.gargoylesoftware.htmlunit.html.HtmlTextInput;
//参考博文
//1.http://blog.csdn.net/zstu_cc/article/details/39250903
//2.http://blog.csdn.net/cslie/article/details/48735261
public class HtmlUnitAndJsoup {
/*
* 首先说说HtmlUnit相对于HttpClient的最明显的一个好处,
* 是HtmlUnit不仅保存了这个网页对象,更难能可贵的是它还存有这个网页的所有基本操作甚至事件。
* 现在很多网站使用大量ajax,普通爬虫无法获取js生成的内容。
*/
/*
* 依赖的jar包 commons-lang3-3.1.jar htmlunit-2.13.jar htmlunit-core-js-2.13.jar
* httpclient-4.3.1.jar httpcore-4.3.jar httpmime-4.3.1.jar sac-1.3.jar
* xml-apis-1.4.01.jar commons-collections-3.2.1.jar commons-io-2.4.jar
* xercesImpl-2.11.0.jar xalan-2.7.1.jar cssparser-0.9.11.jar
* nekohtml-1.9.19.jar
*/
// 百度新闻高级搜索
@Test
public void HtmlUnitBaiduAdvanceSearch() {
try {
// 得到浏览器对象,直接New一个就能得到,现在就好比说你得到了一个浏览器了
WebClient webclient = new WebClient();
// 这里是配置一下不加载css和javaScript,配置起来很简单,是不是
webclient.getOptions().setCssEnabled(false);
webclient.getOptions().setJavaScriptEnabled(false);
// 做的第一件事,去拿到这个网页,只需要调用getPage这个方法即可
HtmlPage htmlpage = webclient
.getPage("http://news.baidu.com/advanced_news.html");
// 根据名字得到一个表单,查看上面这个网页的源代码可以发现表单的名字叫“f”
final HtmlForm form = htmlpage.getFormByName("f");
System.out.println(form);
// 同样道理,获取”百度一下“这个按钮
final HtmlSubmitInput button = form.getInputByValue("百度一下");
System.out.println(button);
// 得到搜索框
final HtmlTextInput textField = form.getInputByName("q1");
System.out.println(textField);
// 最近周星驰比较火呀,我这里设置一下在搜索框内填入”周星驰“
textField.setValueAttribute("周星驰");
// 输入好了,我们点一下这个按钮
final HtmlPage nextPage = button.click();
// 我把结果转成String
System.out.println(nextPage);
String result = nextPage.asXml();
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
// 测试天涯论坛登陆界面 HtmlUnit 页面JS的自动跳转(响应码是200,但是响应的页面就是一个JS)
// httpClient就麻烦了
@Test
public void TianyaTestByHtmlUnit() {
try {
WebClient webClient = new WebClient();
// The ScriptException is raised because you have a syntactical
// error in your javascript.
// Most browsers manage to interpret the JS even with some kind of
// errors
// but HtmlUnit is a bit inflexible in that sense.
// 加载的页面有js语法错误会抛出异常
webClient.getOptions().setJavaScriptEnabled(true); // 启用JS解释器,默认为true
webClient.getOptions().setCssEnabled(false); // 禁用css支持
// 设置Ajax异步处理控制器即启用Ajax支持
webClient
.setAjaxController(new NicelyResynchronizingAjaxController());
// 当出现Http error时,程序不抛异常继续执行
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
// 防止js语法错误抛出异常
webClient.getOptions().setThrowExceptionOnScriptError(false); // js运行错误时,是否抛出异常
// 拿到这个网页
HtmlPage page = webClient
.getPage("http://passport.tianya.cn/login.jsp");
// 填入用户名和密码
HtmlInput username = (HtmlInput) page.getElementById("userName");
username.type("yourAccount");
HtmlInput password = (HtmlInput) page.getElementById("password");
password.type("yourPassword");
// 提交
HtmlButton submit = (HtmlButton) page.getElementById("loginBtn");
HtmlPage nextPage = submit.click();
System.out.println(nextPage.asXml());
} catch (Exception e) {
e.printStackTrace();
}
}
// jsoup解析文档
@Test
public void jsoupParse() {
try {
/** HtmlUnit请求web页面 */
// 模拟chorme浏览器,其他浏览器请修改BrowserVersion.后面
WebClient wc = new WebClient(BrowserVersion.CHROME);
wc.getOptions().setJavaScriptEnabled(true); // 启用JS解释器,默认为true
wc.getOptions().setCssEnabled(false); // 禁用css支持
wc.getOptions().setThrowExceptionOnScriptError(false); // js运行错误时,是否抛出异常
wc.getOptions().setTimeout(10000); // 设置连接超时时间 ,这里是10S。如果为0,则无限期等待
HtmlPage page = wc.getPage("http://passport.tianya.cn/login.jsp");
String pageXml = page.asXml(); // 以xml的形式获取响应文本
// text只会获取里面的文本,网页html标签和script脚本会被去掉
String pageText = page.asText();
System.out.println(pageText);
// 方法一,通过get方法获取
HtmlButton submit = (HtmlButton) page.getElementById("loginBtn");
// 方法二,通过XPath获取,XPath通常用于无法通过Id搜索,或者需要更为复杂的搜索时
HtmlDivision div = (HtmlDivision) page.getByXPath("//div").get(0);
// 网络爬虫中主要目的就是获取页面中所有的链接
java.util.List<HtmlAnchor> achList = page.getAnchors();
for (HtmlAnchor ach : achList) {
System.out.println(ach.getHrefAttribute());
}
System.out.println("-------jsoup部分------");
// 服务器端进行校验并清除有害的HTML代码,防止富文本提交有害代码
Jsoup.clean(pageXml, Whitelist.basic());
/** jsoup解析文档 */
// 把String转化成document格式
Document doc = Jsoup.parse(pageXml);
Element loginBtn = doc.select("#loginBtn").get(0);
System.out.println(loginBtn.text());
Assert.assertTrue(loginBtn.text().contains("登录"));
} catch (Exception e) {
e.printStackTrace();
}
}
// htmlunit设置代理上网
@Test
public void proxy() {
String proxyHost = "192.168.0.1";
int port = 80;
WebClient webClient = new WebClient(BrowserVersion.CHROME, proxyHost,
port);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
DefaultCredentialsProvider credentialsProvider = (DefaultCredentialsProvider) webClient
.getCredentialsProvider();
String username = "account";
String password = "password";
credentialsProvider.addCredentials(username, password);
}
// jsoup请求并解析
@Test
public void jsoupCrawl() throws IOException {
String url = "http://passport.tianya.cn/login.jsp";
Connection con = Jsoup.connect(url);// 获取请求连接
// 浏览器可接受的MIME类型。
con.header("Accept",
"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
con.header("Accept-Encoding", "gzip, deflate");
con.header("Accept-Language", "zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3");
con.header("Connection", "keep-alive");
con.header("Host", url);
con.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:26.0) Gecko/20100101 Firefox/26.0");
Document doc = con.get();
Elements loginBtn = doc.select("#loginBtn");
System.out.println(loginBtn.text());// 获取节点中的文本,类似于js中的方法
}
}httpclient模拟post请求登录
package com.yuanhai.test;
import java.io.IOException;
import java.security.cert.CertificateException;
import java.security.cert.X509Certificate;
import java.util.ArrayList;
import java.util.List;
import javax.net.ssl.SSLContext;
import org.apache.http.Consts;
import org.apache.http.Header;
import org.apache.http.HttpResponse;
import org.apache.http.NameValuePair;
import org.apache.http.client.HttpClient;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.conn.ssl.SSLConnectionSocketFactory;
import org.apache.http.conn.ssl.SSLContextBuilder;
import org.apache.http.conn.ssl.TrustStrategy;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import com.steadystate.css.parser.ParseException;
/**
* @author
* @date
* @version
*
*/
public class TianyaTestByHttpClient {
/**
* 无法实现js页面的自动跳转,HtmlUnit可以
*/
public static void main(String[] args) throws Exception {
// 这是一个测试,也是为了让大家看的更清楚,请暂时抛开代码规范性,不要纠结于我多建了一个局部变量等
// 得到认证https的浏览器对象
HttpClient client = getSSLInsecureClient();
// 得到我们需要的post流
HttpPost post = getPost();
// 使用我们的浏览器去执行这个流,得到我们的结果
HttpResponse hr = client.execute(post);
// 在控制台输出我们想要的一些信息
showResponseInfo(hr);
}
private static void showResponseInfo(HttpResponse hr) throws ParseException, IOException {
System.out.println("响应状态行信息:" + hr.getStatusLine());
System.out.println("---------------------------------------------------------------");
System.out.println("响应头信息:");
Header[] allHeaders = hr.getAllHeaders();
for (int i = 0; i < allHeaders.length; i++) {
System.out.println(allHeaders[i].getName() + ":" + allHeaders[i].getValue());
}
System.out.println("---------------------------------------------------------------");
System.out.println("响应正文:");
System.out.println(EntityUtils.toString(hr.getEntity()));
/* <body>
<script>
location.href="http://passport.tianya.cn:80/online/loginSuccess.jsp?fowardurl=http%3A%2F%2Fwww.tianya.cn%2F110486326&userthird=®Orlogin=%E7%99%BB%E5%BD%95%E4%B8%AD......&t=1458895519504&k=06d41f547cd05fb5dea1590a60e1ec98&c=669767baea73097dde58423fac777138";
</script>
</body>*/
}
// 得到一个认证https链接的HttpClient对象(因为我们将要的天涯登录是Https的)
// 具体是如何工作的我们后面会提到的
private static HttpClient getSSLInsecureClient() throws Exception {
// 建立一个认证上下文,认可所有安全链接,当然,这是因为我们仅仅是测试,实际中认可所有安全链接是危险的
SSLContext sslContext = new SSLContextBuilder().loadTrustMaterial(null, new TrustStrategy() {
public boolean isTrusted(X509Certificate[] chain, String authType) throws CertificateException {
return true;
}
}).build();
SSLConnectionSocketFactory sslsf = new SSLConnectionSocketFactory(sslContext);
return HttpClients.custom().//
setSSLSocketFactory(sslsf)//
// .setProxy(new HttpHost("127.0.0.1", 8888))
.build();
}
// 获取我们需要的Post流,如果你是把我的代码复制过去,请记得更改为你的用户名和密码
private static HttpPost getPost() {
HttpPost post = new HttpPost("https://passport.tianya.cn/login");
// 首先我们初始化请求头
post.addHeader("Referer", "https://passport.tianya.cn/login.jsp");
post.addHeader("Host", "passport.tianya.cn");
post.addHeader("Origin", "http://passport.tianya.cn");
// 然后我们填入我们想要传递的表单参数(主要也就是传递我们的用户名和密码)
// 我们可以先建立一个List,之后通过post.setEntity方法传入即可
// 写在一起主要是为了大家看起来方便,大家在正式使用的当然是要分开处理,优化代码结构的
List<NameValuePair> paramsList = new ArrayList<NameValuePair>();
/*
* 添加我们要的参数,这些可以通过查看浏览器中的网络看到,如下面我的截图中看到的一样
* 不论你用的是firebug,httpWatch或者是谷歌自带的查看器也好,都能查看到(后面会推荐辅助工具来查看)
* 要把表单需要的参数都填齐,顺序不影响
*/
paramsList.add(new BasicNameValuePair("Submit", ""));
paramsList.add(new BasicNameValuePair("fowardURL", "http://www.tianya.cn"));
paramsList.add(new BasicNameValuePair("from", ""));
paramsList.add(new BasicNameValuePair("method", "name"));
paramsList.add(new BasicNameValuePair("returnURL", ""));
paramsList.add(new BasicNameValuePair("rmflag", "1"));
paramsList.add(new BasicNameValuePair("__sid", "1#1#1.0#a6c606d9-1efa-4e12-8ad5-3eefd12b8254"));
// 你可以申请一个天涯的账号 并在下两行代码中替换为你的用户名和密码
paramsList.add(new BasicNameValuePair("vwriter", "yourAccount"));// 替换为你的用户名
paramsList.add(new BasicNameValuePair("vpassword", "yourPassword"));// 你的密码
// 将这个参数list设置到post中
post.setEntity(new UrlEncodedFormEntity(paramsList, Consts.UTF_8));
return post;
}
}参考文章:
http://blog.csdn.net/zstu_cc/article/details/39250903
http://blog.csdn.net/cslie/article/details/48735261
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





