一条 SQL 在数据库中是如何执行的呢 ?相信很多人都会对这个问题比较感兴趣。但是,感兴趣归感兴趣,你得去追呀,还臆想着她主动到你怀里来 ?
一条 SQL 在数据库中的生命周期涵盖了 SQL 的词法解析、语法解析、权限检查、查询优化、SQL执行等一系列的步骤,是一个相当复杂的过程,不亚于你追她的艰苦历程,不是只言片语就说的完的。但是,大家先别紧张,上面说的那些了,今天一个也不讲,气不气 ?
今天和大家一起来看一下 SQL 生命周期中比较有意思的一个环节
给定一条 SQL,如何提取其中的 where 条件 ?
where 条件中的每个子条件,在 SQL 执行的过程中有分别起着什么样的作用 ?
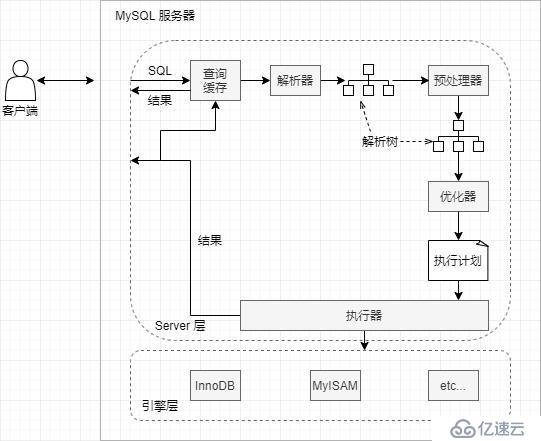
这是 MySQL 数据库中 SQL 的执行流程,其他数据库应该类似
关系型数据库中,数据组织涉及到两个最基本的结构:表与索引。表中存储的是完整数据记录,分为堆表和聚簇索引表;堆表中所有的记录无序存储,聚簇索引表中所有的记录则是按照记录主键进行排序存储。索引中存储的是完整记录的一个子集,用于加速记录的查询速度,索引的组织形式,一般均为B+树结构
MySQL 的 InnoDB 采用的是聚簇索引表,数据记录和索引是一起存储的,类似如下
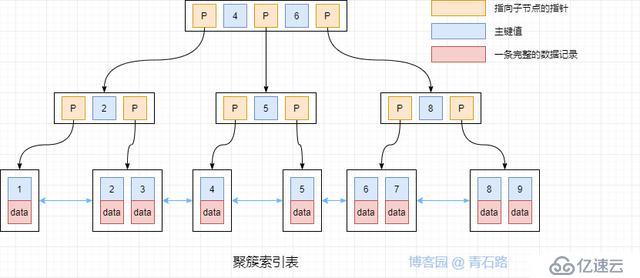
InnoDB 二级索引(非聚簇索引)的结构与聚集索引的结构基本相同,只是叶子节点有些许差别,二级索引的叶子节点存的是索引值 + 主键值,而聚簇索引的叶子节点存的是索引值 + 完整的数据记录,所以通过二级索引查找的过程是先找到该索引值对应的聚集索引的值,然后再通过该聚簇索引值到聚簇索引树上查找对应的完整数据记录,这个过程称为回表!当然也有不需要回表的情况,这里就不展开了
Oracle、DB2、PostgreSQL,MySQL 的 MyISAM 引擎,采用的是堆表形式来存储数据,索引和数据是分开存储的,类似如下
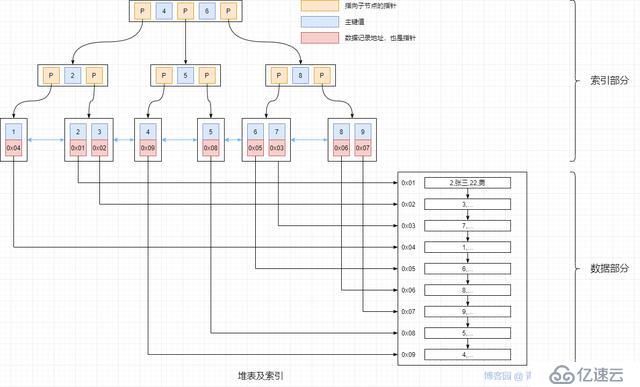
堆表结构中的聚簇索引和二级索引基本就没什么区别了,可以简单的认为聚簇索引的结构和二级索引中的唯一索引的结构是一样的
其实表结构采用何种形式并不重要,因为下面讲的内容在任何表结构中均适用
建表 tbl_test 并初始化数据
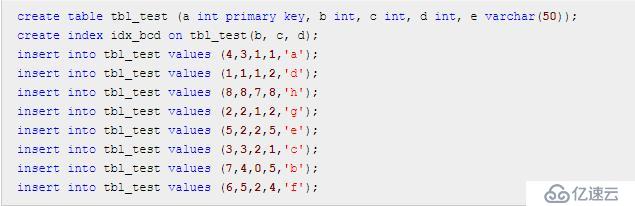
假设数据数据结构是堆表形式,那么 idx_bcd 索引的结构图大致如下(聚簇索引不一样,类比一下应该可以画出来,我就偷个懒不画了)
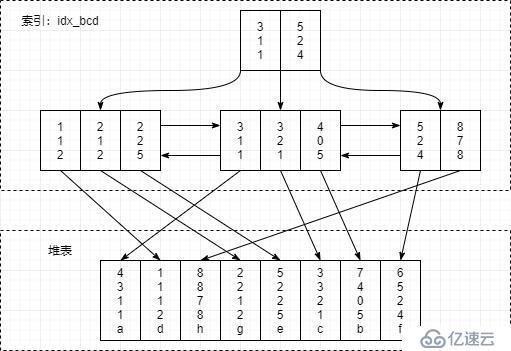
组合索引 idx_bcd 上有 b,c,d 三个字段,不包括 a,e 字段,它是先按照 b 字段排序,b 字段相同,则按照 c 字段排序,以此类推
针对上表,我们分析下 SQL:select * from tbl_test where b >= 2 and b < 7 and c > 0 and d != 2 and e != 'a'; 此 SQL 中 WHERE 条件用到了 b,c,d,e 四个字段,而索引 idx_bcd 刚好是建立在 b,c,d 三个字段上,那么走 idx_bcd 索引进行条件过滤应该能提高查询效率,既然走 idx_bcd 索引进行条件过滤,那么我们来思考下以下几个关键问题
1、上述 SQL,覆盖了 idx_bcd 索引的哪个范围 ?
起始点由 b >= 2,c > 0 决定,所以 2,1,2 是第一个需要检查的索引项
终止点由 b < 7 决定,所以 8,7,8 是第一个不需要检查的索引项, 8,7,8 后面的也无需检索
2、范围确定后,SQL 中还有哪些条件可以使用 idx_bcd 索引来过滤 ?
上面我们已经确认了范围 2,1,2 ~ 8,7,8 ,那么在这个范围内的每一个索引项是不是都满足 WHERE 条件了 ? 很显然不是, 4,0,5 不满足 c > 0 , 2,1,2 不满足 d != 2 ;所以 c,d 列的 where 条件可以通过索引 idx_bcd 来过滤
3、当 idx_bcd 索引物尽其用后,还有哪些条件是无法通过 idx_bcd 索引过滤的 ?
这个很明显, e != 'a' 无法在索引 idx_bcd 上进行过滤,因为索引并未包含 e 列;e 列只在堆表上存在,所以需要将已经满足索引查询条件的记录回表,取出对应的完整数据记录,然后看该数据记录中 e 列值是否满足 e != 'a' 条件
有些小伙伴可能觉得上述 WHERE 条件的抽取具有特殊性,不具普遍性,那么我们抽象出一套放置于所有 SQL 语句皆准的 WHERE 查询条件的提取规则:Index Key (First Key & Last Key),Index Filter,Table Filter,我们们往下仔细看
用于确定 SQL 查询在索引中的连续范围(起始点 + 终止点)的查询条件,被称之为Index Key;由于一个范围,至少包含一个起始条件与一个终止条件,因此 Index Key 也被拆分为 Index First Key 和 Index Last Key,分别用于定位索引查找的起始点以终止点
Index First Key
用于确定索引查询范围的起始点;提取规则:从索引的第一个键值开始,检查其在 where 条件中是否存在,若存在并且条件是 =、>=,则将对应的条件加入Index First Key之中,继续读取索引的下一个键值,使用同样的提取规则;若存在并且条件是 >,则将对应的条件加入 Index First Key 中,同时终止 Index First Key 的提取;若不存在,同样终止 Index First Key 的提取
针对 SQL:select * from tbl_test where b >= 2 and b < 7 and c > 0 and d != 2 and e != 'a',应用这个提取规则,提取出来的 Index First Key 为 b >= 2, c > 0 ,由于 c 的条件为 >,提取结束
Index Last Key
用于确定索引查询范围的终止点,与 Index First Key 正好相反;提取规则:从索引的第一个键值开始,检查其在 where 条件中是否存在,若存在并且条件是 =、<=,则将对应条件加入到 Index Last Key 中,继续提取索引的下一个键值,使用同样的提取规则;若存在并且条件是 < ,则将条件加入到 Index Last Key 中,同时终止提取;若不存在,同样终止Index Last Key的提取
针对 SQL:select * from tbl_test where b >= 2 and b < 7 and c > 0 and d != 2 and e != 'a',应用这个提取规则,提取出来的 Index Last Key为 b < 7 ,由于是 < 符号,提取结束
在完成 Index Key 的提取之后,我们根据 where 条件固定了索引的查询范围,那么是不是在范围内的每一个索引项都满足 WHERE 条件了 ? 很明显 4,0,5 , 2,1,2 均属于范围中,但是又均不满足SQL 的查询条件
所以 Index Filter 用于索引范围确定后,确定 SQL 中还有哪些条件可以使用索引来过滤;提取规则:从索引列的第一列开始,检查其在 where 条件中是否存在,若存在并且 where 条件仅为 =,则跳过第一列继续检查索引下一列,下一索引列采取与索引第一列同样的提取规则;若 where 条件为 >=、>、<、<= 其中的几种,则跳过索引第一列,将其余 where 条件中索引相关列全部加入到 Index Filter 之中;若索引第一列的 where 条件包含 =、>=、>、<、<= 之外的条件,则将此条件以及其余 where 条件中索引相关列全部加入到 Index Filter 之中;若第一列不包含查询条件,则将所有索引相关条件均加入到 Index Filter之中
针对 SQL:select * from tbl_test where b >= 2 and b < 7 and c > 0 and d != 2 and e != 'a',应用这个提取规则,提取出来的 Index Filter 为 c > 0 and d != 2 ,因为索引第一列只包含 >=、< 两个条件,因此第一列跳过,将余下的 c、d 两列加入到 Index Filter 中,提取结束
这个就比较简单了,where 中不能被索引过滤的条件都归为此中;提取规则:所有不属于索引列的查询条件,均归为 Table Filter 之中
针对 SQL:select * from tbl_test where b >= 2 and b < 7 and c > 0 and d != 2 and e != 'a',应用这个提取规则,那么 Table Filter 就为 e != 'a'
是不是有点感觉了 ? 相信此刻,大家对 where 条件的提取基本清楚了,但怎么应用了 ?
SQL 语句中的 where 条件,最终都会被提取到 Index Key (First Key & Last Key),Index Filter 与 Table Filter 之中,那么 where 条件的应用,其实就是 Index Key (First Key & Last Key),Index Filter 与Table Filter 的应用
Index First Key,只是用来定位索引的起始点,因此只在索引第一次Search Path(沿着索引B+树的根节点一直遍历,到索引正确的叶节点位置)时使用,只会判断一次
Index Last Key,用来定位索引的终止点,因此对于起始点之后读到的每一条索引记录,均需要判断是否满足 Index Last Key,若不满足,则当前查询结束
Index Filter,用于过滤索引范围中不满足条件的索引项,因此对于索引范围中的每一条索引项,均需要与 Index Filter 进行匹对,若不满足 Index Filter 则直接丢弃,继续读取索引下一条记录
Table Filter,用于过滤不能被索引过滤的条件,此时的索引项已经满足了 Index First Key 与 Index Last Key 构成的范围,并且满足 Index Filter 的条件,但是索引项无法过滤 Table Filter 中的条件,所以回表读取完整的数据记录,判断完整记录是否满足 Table Filter 中的查询条件,若不满足,跳过当前记录,继续读取索引项的下一条索引项,若满足,则返回记录,此记录满足了 where 的所有条件,可以返回给客户端
1、SQL 语句中的 where 条件,最终都会被提取到 Index Key (First Key & Last Key),Index Filter 与 Table Filter ,提取规则需要大家好好体会下
2、数据库中 where 条件的过滤是 one by one(一条一条)的方式进行的,联表查询其实也是 one by one 的方式进行的;虽然我们在开发中感觉到不是 one by one,那其实是数据库驱动做了处理
3、Index Key 的提取,需要考虑到间隙锁,避免幻读问题,有兴趣的小伙伴可以去琢磨下
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



