SQL Serverзҙўеј•зҡ„зӨәдҫӢеҲҶжһҗ
е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢSQL Serverзҙўеј•зҡ„зӨәдҫӢеҲҶжһҗпјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳдёҚжҖҺд№ҲдәҶи§ЈпјҢеӣ жӯӨеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©жҲ‘们дёҖиө·еҺ»дәҶи§ЈдёҖдёӢеҗ§пјҒ
еүҚиЁҖ
жӯӨж–ҮжҳҜжҲ‘д№ӢеүҚзҡ„笔记ж•ҙзҗҶиҖҢжқҘпјҢд»Ҙзҙўеј•дёәе…ҘеҸЈиҝӣиЎҢжҺўи®Ёзӣёе…іж•°жҚ®еә“зҹҘиҜҶпјҲеҸҲеҒҡдәҶдҝ®ж”№д»Ҙи®©дәәжӣҙеҘҪж¶ҲеҢ–пјүгҖӮSQL ServerжҺҘи§ҰдёҚд№…зҡ„жңӢеҸӢеҸҜд»ҘеҸӘзңӢд»ҘдёӢи“қиүІеӯ—дҪ“еӯ—пјҢз®ҖеҚ•жңүз”ЁиҠӮзңҒж—¶й—ҙпјӣеҰӮжһңжҳҜж•°жҚ®еә“еҹәзЎҖдёҚй”ҷзҡ„жңӢеҸӢпјҢеҸҜд»Ҙе…ЁзңӢпјҢж¬ўиҝҺжҺўи®ЁгҖӮ
зҙўеј•зҡ„жҰӮеҝө
зҙўеј•зҡ„з”ЁйҖ”пјҡжҲ‘们еҜ№ж•°жҚ®жҹҘиҜўеҸҠеӨ„зҗҶйҖҹеәҰе·ІжҲҗдёәиЎЎйҮҸеә”з”Ёзі»з»ҹжҲҗиҙҘзҡ„ж ҮеҮҶпјҢиҖҢйҮҮз”Ёзҙўеј•жқҘеҠ еҝ«ж•°жҚ®еӨ„зҗҶйҖҹеәҰйҖҡеёёжҳҜжңҖжҷ®йҒҚйҮҮз”Ёзҡ„дјҳеҢ–ж–№жі•гҖӮ
зҙўеј•жҳҜд»Җд№Ҳпјҡж•°жҚ®еә“дёӯзҡ„зҙўеј•зұ»дјјдәҺдёҖжң¬д№Ұзҡ„зӣ®еҪ•пјҢеңЁдёҖжң¬д№ҰдёӯдҪҝз”Ёзӣ®еҪ•еҸҜд»Ҙеҝ«йҖҹжүҫеҲ°дҪ жғіиҰҒзҡ„дҝЎжҒҜпјҢиҖҢдёҚйңҖиҰҒиҜ»е®Ңе…Ёд№ҰгҖӮеңЁж•°жҚ®еә“дёӯпјҢж•°жҚ®еә“зЁӢеәҸдҪҝз”Ёзҙўеј•еҸҜд»ҘйҮҚе•ҠеҲ°иЎЁдёӯзҡ„ж•°жҚ®пјҢиҖҢдёҚеҝ…жү«жҸҸж•ҙдёӘиЎЁгҖӮд№Ұдёӯзҡ„зӣ®еҪ•жҳҜдёҖдёӘеӯ—иҜҚд»ҘеҸҠеҗ„еӯ—иҜҚжүҖеңЁзҡ„йЎөз ҒеҲ—иЎЁпјҢж•°жҚ®еә“дёӯзҡ„зҙўеј•жҳҜиЎЁдёӯзҡ„еҖјд»ҘеҸҠеҗ„еҖјеӯҳеӮЁдҪҚзҪ®зҡ„еҲ—иЎЁгҖӮ
зҙўеј•зҡ„еҲ©ејҠпјҡжҹҘиҜўжү§иЎҢзҡ„еӨ§йғЁеҲҶејҖй”ҖжҳҜI/OпјҢдҪҝз”Ёзҙўеј•жҸҗй«ҳжҖ§иғҪзҡ„дёҖдёӘдё»иҰҒзӣ®ж ҮжҳҜйҒҝе…Қе…ЁиЎЁжү«жҸҸпјҢеӣ дёәе…ЁиЎЁжү«жҸҸйңҖиҰҒд»ҺзЈҒзӣҳдёҠиҜ»еҸ–иЎЁзҡ„жҜҸдёҖдёӘж•°жҚ®йЎөпјҢеҰӮжһңжңүзҙўеј•жҢҮеҗ‘ж•°жҚ®еҖјпјҢеҲҷжҹҘиҜўеҸӘйңҖиҰҒиҜ»е°‘ж•°ж¬Ўзҡ„зЈҒзӣҳе°ұиЎҢе•ҰгҖӮжүҖд»ҘеҗҲзҗҶзҡ„дҪҝз”Ёзҙўеј•иғҪеҠ йҖҹж•°жҚ®зҡ„жҹҘиҜўгҖӮдҪҶжҳҜзҙўеј•е№¶дёҚжҖ»жҳҜжҸҗй«ҳзі»з»ҹзҡ„жҖ§иғҪпјҢеёҰзҙўеј•зҡ„иЎЁйңҖиҰҒеңЁж•°жҚ®еә“дёӯеҚ з”ЁжӣҙеӨҡзҡ„еӯҳеӮЁз©әй—ҙпјҢеҗҢж ·з”ЁжқҘеўһеҲ ж•°жҚ®зҡ„е‘Ҫд»ӨиҝҗиЎҢж—¶й—ҙд»ҘеҸҠз»ҙжҠӨзҙўеј•жүҖйңҖзҡ„еӨ„зҗҶж—¶й—ҙдјҡжӣҙй•ҝгҖӮжүҖд»ҘжҲ‘们иҰҒеҗҲзҗҶдҪҝз”Ёзҙўеј•пјҢеҸҠж—¶жӣҙж–°еҺ»йҷӨж¬Ўдјҳзҙўеј•гҖӮ
1.иҒҡйӣҶзҙўеј•е’ҢйқһиҒҡйӣҶзҙўеј•
зҙўеј•еҲҶдёәиҒҡйӣҶзҙўеј•е’ҢйқһиҒҡйӣҶзҙўеј•
1.1 иҒҡйӣҶзҙўеј•
иЎЁзҡ„ж•°жҚ®жҳҜеӯҳеӮЁеңЁж•°жҚ®йЎөдёӯпјҲж•°жҚ®йЎөзҡ„PageTypeж Үи®°дёә1пјүпјҢSqlServerдёҖйЎөжҳҜ8kпјҢеӯҳж»ЎдёҖйЎөе°ұејҖиҫҹдёӢдёҖйЎөеӯҳеӮЁгҖӮеҰӮжһңиЎЁжңүиҒҡйӣҶзҙўеј•пјҢйӮЈд№ҲдёҖ笔дёҖ笔зү©зҗҶж•°жҚ®е°ұжҳҜжҢүиҒҡйӣҶзҙўеј•еӯ—ж®өзҡ„еӨ§е°ҸеҚҮ/йҷҚжҺ’еәҸеӯҳеӮЁеңЁйЎөдёӯгҖӮеҪ“еҜ№иҒҡйӣҶзҙўеј•еӯ—ж®өжӣҙж–°жҲ–дёӯй—ҙжҸ’е…Ҙ/еҲ йҷӨж•°жҚ®ж—¶пјҢйғҪдјҡеҜјиҮҙиЎЁж•°жҚ®з§»еҠЁпјҲйҖ жҲҗжҖ§иғҪдёҖе®ҡеҪұе“ҚпјүпјҢеӣ дёәе®ғиҰҒдҝқжҢҒеҚҮ/йҷҚжҺ’еәҸгҖӮ
жіЁж„ҸпјҢдё»й”®еҸӘжҳҜй»ҳи®ӨжҳҜиҒҡйӣҶзҙўеј•пјҢе®ғд№ҹеҸҜд»Ҙи®ҫзҪ®дёәйқһиҒҡйӣҶзҙўеј•пјҢд№ҹеҸҜд»ҘеңЁйқһдё»й”®еӯ—ж®өдёҠи®ҫзҪ®дёәиҒҡйӣҶзҙўеј•пјҢе…ЁиЎЁеҸӘиғҪжңүдёҖдёӘиҒҡйӣҶзҙўеј•гҖӮ
дёҖдёӘдјҳз§Җзҡ„иҒҡйӣҶзҙўеј•еӯ—ж®өдёҖиҲ¬еҢ…еҗ«д»ҘдёӢ4дёӘзү№жҖ§пјҡ
(A).иҮӘеўһй•ҝ
жҖ»жҳҜеңЁжң«е°ҫеўһеҠ и®°еҪ•пјҢеҮҸе°‘еҲҶйЎөе’Ңзҙўеј•зўҺзүҮгҖӮ
(B).дёҚиў«жӣҙж”№
еҮҸе°‘ж•°жҚ®з§»еҠЁгҖӮ
(C).е”ҜдёҖжҖ§
е”ҜдёҖжҖ§жҳҜд»»дҪ•зҙўеј•жңҖзҗҶжғізҡ„зү№жҖ§пјҢеҸҜд»ҘжҳҺзЎ®зҙўеј•й”®еҖјеңЁжҺ’еәҸдёӯзҡ„дҪҚзҪ®гҖӮ
жӣҙйҮҚиҰҒзҡ„жҳҜпјҢзҙўеј•й”®жҢҮе”ҜдёҖзҡ„иҜқпјҢе®ғеңЁжҜҸжқЎи®°еҪ•йҮҢжүҚеҸҜд»ҘжӯЈзЎ®жҢҮеҗ‘жәҗж•°жҚ®иЎҢRIDгҖӮеҰӮжһңиҒҡйӣҶзҙўеј•й”®еҖјдёҚе”ҜдёҖпјҢSqlServerе°ұйңҖиҰҒеҶ…йғЁз”ҹжҲҗuniquifier еҲ—з»„еҗҲеҪ“дҪңиҒҡйӣҶй”®дҝқиҜҒвҖңй”®еҖјвҖқе”ҜдёҖжҖ§пјӣеҰӮжһңйқһиҒҡйӣҶзҙўеј•й”®еҖјдёҚе”ҜдёҖпјҢе°ұдјҡеўһеҠ RIDеҲ—пјҲиҒҡйӣҶзҙўеј•й”®жҲ–иҖ…е ҶиЎЁдёӯзҡ„иЎҢжҢҮй’ҲпјүдҝқиҜҒвҖңй”®еҖјвҖқе”ҜдёҖжҖ§гҖӮ
жҖқиҖғпјҲеҸҜз•ҘиҝҮпјүпјҡзҙўеј•вҖңй”®еҖјвҖқеңЁйқһеҸ¶еӯҗиҠӮзӮ№д№ҹжңүдҝқиҜҒе”ҜдёҖжҖ§пјҢеҺҹеӣ еә”иҜҘжҳҜдёәдәҶжҳҺзЎ®зҙўеј•и®°еҪ•еңЁйқһеҸ¶еӯҗиҠӮзӮ№дёӯзҡ„дҪҚзҪ®гҖӮжҜ”еҰӮжңүдёӘйқһиҒҡйӣҶзҙўеј•еӯ—ж®өName2пјҢиЎЁдёӯжңүеҫҲеӨҡName2='a'зҡ„и®°еҪ•пјҢеҜјиҮҙName2='a'еңЁйқһеҸ¶еӯҗиҠӮзӮ№дёҠжңүеӨҡжқЎзҙўеј•и®°еҪ•пјҲиҠӮзӮ№пјүпјҢиҝҷж—¶еҖҷеҶҚinsertдёҖ笔Name2=вҖҳa'зҡ„и®°еҪ•ж—¶пјҢе°ұеҸҜд»Ҙж №жҚ®йқһеҸ¶еӯҗиҠӮзӮ№зҡ„RIDе’Ңж–°еўһи®°еҪ•зҡ„RIDеҫҲеҝ«зЎ®е®ҡиҰҒinsertеҲ°е“ӘдёӘзҙўеј•и®°еҪ•пјҲиҠӮзӮ№пјүдёҠпјҢеҰӮжһңжІЎжңүйқһеҸ¶еӯҗиҠӮзӮ№зҡ„RIDпјҢйӮЈеҫ—йҒҚеҺҶеҲ°жүҖжңүName2='a'зҡ„еҸ¶еӯҗиҠӮзӮ№жүҚиғҪзЎ®е®ҡдҪҚзҪ®гҖӮеҸҰеӨ–пјҢеҪ“жҲ‘们select * from Table1 where Name2<='a'ж—¶пјҢиҝ”еӣһзҡ„ж•°жҚ®жҳҜжҢүйқһиҒҡйӣҶзҙўеј•Name2е’ҢRIDжҺ’еәҸзҡ„пјҢеҫҲеҘҪзҗҶи§Јиҝ”еӣһзҡ„ж•°жҚ®е°ұжҳҜжҢүиҝҷиҫ№зҙўеј•еӯҳеӮЁзҡ„йЎәеәҸжҺ’еәҸзҡ„гҖӮиҝҷжҳҜиҝҷжқЎsqlжҹҘиҜўж—¶жңүз”ЁеҲ°Name2зҙўеј•зҡ„з»“жһңпјҢеҰӮжһңж•°жҚ®еә“жҹҘиҜўи®ЎеҲ’еӣ вҖңдёҙз•ҢзӮ№вҖқй—®йўҳйҖүжӢ©зӣҙжҺҘиЎЁж•°жҚ®жү«жҸҸпјҢйӮЈиҝ”еӣһзҡ„ж•°жҚ®й»ҳи®Өе°ұжҳҜжҢүиЎЁж•°жҚ®зҡ„йЎәеәҸжҺ’еәҸзҡ„гҖӮ
дёәдәҶвҖңй”®еҖјвҖқе”ҜдёҖжҖ§пјҢеҜ№дәҺиҒҡйӣҶзҙўеј•пјҢuniquifier еҲ—еҸӘеңЁзҙўеј•еҖјйҮҚеӨҚж—¶еўһеҠ гҖӮеҜ№дәҺйқһиҒҡйӣҶзҙўеј•пјҢеҰӮжһңеҲӣе»әзҙўеј•ж—¶жІЎе®ҡд№үе”ҜдёҖпјҢRIDдјҡеңЁжүҖжңүи®°еҪ•еўһеҠ пјҢе°ұз®—зҙўеј•еҖјжҳҜе”ҜдёҖзҡ„пјӣеҰӮжһңеҲӣе»әзҙўеј•ж—¶е®ҡд№үе”ҜдёҖпјҢRIDеҸӘеңЁеҸ¶еӯҗеұӮеўһеҠ пјҢз”ЁдәҺжҹҘжүҫжәҗж•°жҚ®иЎҢпјҢеҚід№ҰзӯҫжҹҘжүҫж“ҚдҪңгҖӮ
(D).еӯ—ж®өй•ҝеәҰе°Ҹ
иҒҡйӣҶзҙўеј•й”®й•ҝеәҰи¶Ҡе°ҸпјҢдёҖйЎөзҙўеј•йЎөе°ұеҸҜд»Ҙе®№зәіжӣҙеӨҡзҙўеј•и®°еҪ•пјҢиҝӣиҖҢеҮҸе°‘зҙўеј•Bж ‘з»“жһ„зҡ„ж·ұеәҰгҖӮдҫӢеҰӮпјҢдёҖдёӘзҷҫдёҮи®°еҪ•зҡ„иЎЁжңүдёҖдёӘintиҒҡйӣҶзҙўеј•пјҢеҸҜиғҪеҸӘйңҖиҰҒ3еұӮзҡ„Bж ‘з»“жһ„гҖӮеҰӮжһңжҠҠиҒҡйӣҶзҙўеј•е®ҡд№үеңЁжӣҙе®Ҫзҡ„еҲ—пјҲжҜ”еҰӮuniqueidentifierеҲ—йңҖиҰҒ16 еӯ—иҠӮпјүпјҢйӮЈд№Ҳзҙўеј•зҡ„ж·ұеәҰдјҡеўһеҠ еҲ°4еұӮгҖӮд»»дҪ•иҒҡйӣҶзҙўеј•жҹҘжүҫйңҖиҰҒ4дёӘI/Oж“ҚдҪңпјҲзЎ®еҲҮзҡ„иҜҙжҳҜ4дёӘйҖ»иҫ‘иҜ»пјүпјҢеҺҹе…ҲеҸӘиҰҒ3дёӘI/Oж“ҚдҪңгҖӮ
еҗҢж ·пјҢйқһиҒҡйӣҶзҙўеј•йҮҢдјҡеҢ…еҗ«иҒҡйӣҶзҙўеј•й”®еҖјпјҢиҒҡйӣҶзҙўеј•й”®й•ҝеәҰи¶Ҡе°ҸйқһиҒҡйӣҶзҙўеј•и®°еҪ•д№ҹе°ұи¶Ҡе°ҸпјҢдёҖйЎөзҙўеј•йЎөе°ұеҸҜд»Ҙе®№зәіжӣҙеӨҡзҙўеј•и®°еҪ•гҖӮ
1.2 йқһиҒҡйӣҶзҙўеј•
д№ҹжҳҜеӯҳеӮЁеңЁйЎөдёӯпјҲPageTypeж Үи®°дёә2зҡ„йЎөпјҢеҸ«зҙўеј•йЎө)гҖӮжҜ”еҰӮиЎЁTе»әз«ӢдәҶдёҖдёӘйқһиҒҡйӣҶзҙўеј•Index_AпјҢйӮЈд№ҲиЎЁTжңү100жқЎж•°жҚ®зҡ„иҜқпјҢйӮЈд№Ҳзҙўеј•Index_Aд№ҹе°ұжңү100жқЎж•°жҚ®пјҲеҮҶзЎ®зҡ„иҜҙжҳҜ100жқЎеҸ¶еӯҗиҠӮзӮ№ж•°жҚ®пјҢзҙўеј•жҳҜBж ‘з»“жһ„пјҢеҰӮжһңж ‘зҡ„й«ҳеәҰеӨ§дәҺ0пјҢйӮЈд№Ҳе°ұжңүж №иҠӮзӮ№йЎөжҲ–дёӯй—ҙиҠӮзӮ№йЎөж•°жҚ®пјҢиҝҷж—¶зҙўеј•ж•°жҚ®е°ұи¶…иҝҮ100жқЎпјүпјҢеҰӮжһңиЎЁTиҝҳжңүйқһиҒҡйӣҶзҙўеј•Index_BпјҢйӮЈд№ҲIndex_Bд№ҹжҳҜиҮіе°‘100жқЎж•°жҚ®пјҢжүҖд»Ҙзҙўеј•е»әи¶ҠеӨҡејҖй”Җи¶ҠеӨ§гҖӮ
жӣҙж–°зҙўеј•еӯ—ж®өгҖҒжҸ’е…ҘдёҖжқЎж•°жҚ®гҖҒеҲ йҷӨдёҖжқЎж•°жҚ®йғҪдјҡйҖ жҲҗзҙўеј•зҡ„з»ҙжҠӨд»ҺиҖҢйҖ жҲҗжҖ§иғҪзҡ„дёҖе®ҡеҪұе“ҚгҖӮеңЁдёҚеҗҢжғ…еҶөдёӢпјҢжҖ§иғҪеҪұе“ҚжҳҜдёҚеҗҢзҡ„гҖӮжҜ”еҰӮеҪ“дҪ жңүдёҖдёӘиҒҡйӣҶзҙўеј•пјҢжҸ’е…Ҙзҡ„ж•°жҚ®еҸҲйғҪжҳҜеңЁжң«е°ҫпјҢиҝҷж ·еҮ д№ҺжҳҜдёҚдјҡйҖ жҲҗж•°жҚ®з§»еҠЁпјҢеҪұе“Қиҫғе°ҸпјӣеҰӮжһңжҸ’е…Ҙзҡ„ж•°жҚ®еңЁдёӯй—ҙдҪҚзҪ®пјҢдёҖиҲ¬дјҡеҜјиҮҙж•°жҚ®з§»еҠЁпјҢиҖҢдё”еҸҜиғҪдә§з”ҹеҲҶйЎөе’ҢйЎөзўҺзүҮпјҢеҪұе“Қе°ұдјҡзЁҚеӨ§дёҖзӮ№пјҲеҰӮжһңжҸ’е…ҘеҲ°зҡ„дёӯй—ҙйЎөжңүи¶іеӨҹзҡ„еү©дҪҷз©әй—ҙе®№зәіжҸ’е…Ҙзҡ„ж•°жҚ®пјҢиҖҢдё”дҪҚзҪ®жҳҜеңЁйЎөжң«пјҢд№ҹжҳҜдёҚдјҡйҖ жҲҗж•°жҚ®з§»еҠЁпјү
2.зҙўеј•зҡ„з»“жһ„
йғҪиҜҙSqlServerзҡ„зҙўеј•жҳҜBж ‘з»“жһ„пјҲиҝҷиҫ№еҒҮе®ҡдҪ еҜ№Bж ‘з»“жһ„жңүдёҖе®ҡдәҶи§ЈпјүпјҢйӮЈе®ғеҲ°еә•й•ҝд»Җд№ҲдёӘжЁЎж ·е‘ўпјҢеҸҜд»Ҙз”ЁSqlиҜӯеҸҘжқҘжҹҘзңӢе®ғзҡ„йҖ»иҫ‘е‘ҲзҺ°гҖӮ
ж–°е»әжҹҘиҜўжү§иЎҢиҜӯжі•пјҡ DBCC IND(Test,OrderBo,-1) --е…¶дёӯTestеә“зҡ„OrderBoиЎЁжңү1дёҮ笔数жҚ®пјҢжңүиҒҡйӣҶзҙўеј•Idдё»й”®еӯ—ж®ө
пјҲдёҚеҰЁиҮӘе·ұеҠЁжүӢе»әдёӘиЎЁпјҢжңүиҒҡйӣҶзҙўеј•еӯ—ж®өпјҢжҸ’е…Ҙ1дёҮиЎЁж•°жҚ®пјҢ然еҗҺжү§иЎҢиҝҷдёӘиҜӯжі•зңӢзңӢпјҢдјҡ收иҺ·еҫҲеӨҡпјҢзҷҫй—»дёҚеҰӮдёҖи§Ғпјү
жү§иЎҢз»“жһңпјҡ
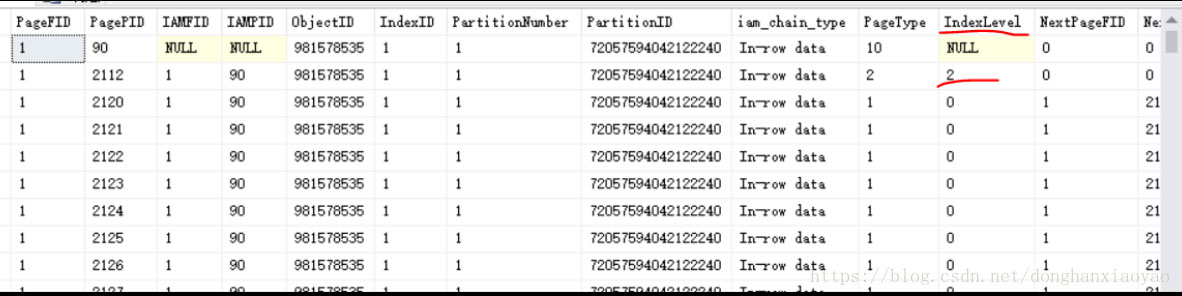
еҰӮдёҠеӣҫпјҢзңӢеҲ°дёҖдёӘIndexLevel=2зҡ„зҙўеј•йЎө2112пјҲиҝҷиҫ№е®ғе°ұжҳҜBж ‘зҡ„ж №иҠӮзӮ№пјҢIndexLevelжңҖеӨ§зҡ„е°ұжҳҜж №иҠӮзӮ№пјҢеҫҖдёӢе°ұжҳҜеӯҗзә§гҖҒеӯҗеӯҗзә§...еҸӘжңүдёҖдёӘж №йЎөдҪңдёәBж ‘з»“жһ„зҡ„и®ҝй—®е…ҘеҸЈзӮ№пјүпјҢиҜҙжҳҺдёҖе®ҡиҝҳжңүIndexLevel=1зҡ„зҙўеј•йЎөе’ҢIndexLevel=0зҡ„еҸ¶еӯҗйЎөгҖӮз”ұдәҺиҝҷиҫ№жҳҜиҒҡйӣҶзҙўеј•пјҢеӣ жӯӨеҪ“IndexLevel=0зҡ„еҸ¶еӯҗйЎөе°ұжҳҜж•°жҚ®йЎөпјҢеӯҳеӮЁзҡ„жҳҜдёҖ笔дёҖ笔зҡ„зү©зҗҶж•°жҚ®гҖӮеҰӮдёҠеӣҫд№ҹеҸҜд»ҘзңӢеҲ°пјҢIndexLevel=0зҡ„иЎҢзҡ„PageTypeзӯүдәҺ1пјҢе°ұжҳҜд»ЈиЎЁж•°жҚ®йЎөпјҢдёҠйқў1.1з« иҠӮи®ІеҲ°иҒҡйӣҶзҙўеј•ж—¶пјҢд№ҹжңүжҸҗеҲ°PageType=1пјӣиҖҢеҰӮжһңжҳҜйқһиҒҡйӣҶзҙўеј•пјҢIndexLevel=0зҡ„еҸ¶еӯҗйЎөпјҢPageTypeжҳҜзӯүдәҺ 2пјҢд»Қ然жҳҜзҙўеј•йЎөгҖӮ
еҗҢж ·пјҢжҲ‘们用Sqlе‘Ҫд»ӨDBCC PAGEзңӢдёҖзңӢ
-- DBCC TRACEON(3604,-1)
DBCC PAGE(Test,1,2112,3)
--ж №иҠӮзӮ№2112пјҢеҸҜд»ҘжҹҘеҮәе®ғзҡ„дёӨдёӘеӯҗиҠӮзӮ№2280е’Ң2448пјҢ然еҗҺеҜ№иҝҷдёӨдёӘеӯҗиҠӮзӮ№еҶҚдҪңDBCC PAGEжҹҘиҜў
DBCC PAGE(Test,1,2280,3)
DBCC PAGE(Test,1,2448,3)
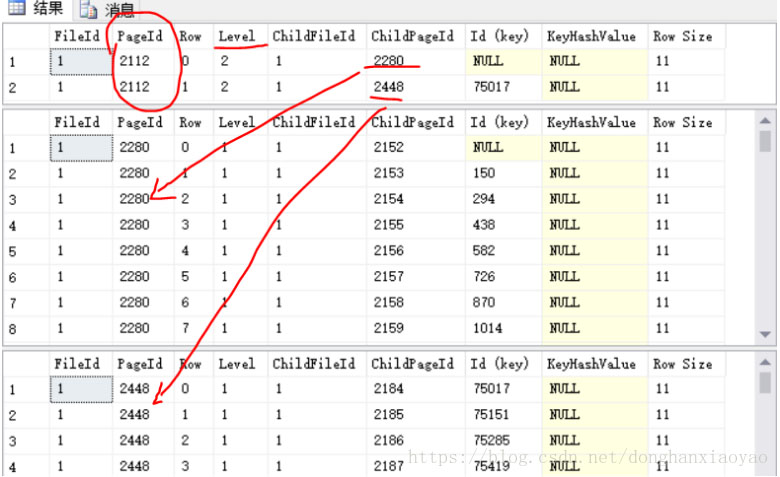
еҰӮдёҠеӣҫпјҢIndexLevel=2зҡ„2112йЎөжңүдёӨдёӘIndexLevel=1зҡ„еӯҗиҠӮзӮ№2280е’Ң2448пјҢеӯҗиҠӮзӮ№дёӢеҸҲжңүеӯҗиҠӮзӮ№пјҢжҜҸдёӘиҠӮзӮ№иҙҹиҙЈдёҚеҗҢзҡ„зҙўеј•й”®еҖјзҡ„еҢәй—ҙпјҲеҚідёҠеӣҫзҡ„вҖңId(key)вҖқж ҸдҪҚпјҢ第дёҖиЎҢеҖјжҳҜNullпјҢиЎЁзӨәжңҖе°ҸеҖјжҲ–еҖ’еәҸж—¶зҡ„жңҖеӨ§еҖјпјүгҖӮиҝҷж ·зҡ„еұӮзә§е…ізі»жҳҜдёҚжҳҜе°ұжҳҜдёҖжЈөBж ‘з»“жһ„пјҢе…¶дёӯIndexLevelе…¶е®һе°ұжҳҜBж ‘з»“жһ„дёӯзҡ„й«ҳеәҰHeightгҖӮ
SqlServerеңЁзҙўеј•дёӯжҹҘжүҫжҹҗдёҖ笔记еҪ•ж—¶пјҢжҳҜд»Һж №иҠӮзӮ№еҫҖдёӢжүҫеҲ°еҸ¶еӯҗиҠӮзӮ№пјҢеӣ дёәжүҖжңүж•°жҚ®ең°еқҖйғҪжңүеӯҳеңЁеҸ¶еӯҗиҠӮзӮ№пјҢиҝҷе…¶е®һжҳҜB+ж ‘зҡ„зү№зӮ№д№ӢдёҖпјҲBж ‘зү№зӮ№жҳҜеҰӮжһңжҹҘжүҫзҡ„еҖјеңЁйқһеҸ¶еӯҗиҠӮзӮ№е°ұжүҫеҲ°пјҢеҲҷе°ұиғҪзӣҙжҺҘиҝ”еӣһпјҢжҳҫ然SqlServerдёҚжҳҜиҝҷд№ҲеҒҡпјҢиҰҒйӘҢиҜҒиҝҷдёҖзӮ№дҪ еҸҜд»Ҙset statistics io onжҠҠз»ҹи®ЎејҖиө·жқҘпјҢ然еҗҺselectзңӢдёӢйҖ»иҫ‘иҜ»зҡ„ж¬Ўж•°пјүгҖӮ
既然дёҖе®ҡдјҡжүҫеҲ°еҸ¶еӯҗиҠӮзӮ№пјҢйӮЈд№Ҳзҙўеј•еҢ…еҗ«еҲ—еҸӘиҰҒеңЁеҸ¶еӯҗиҠӮзӮ№и®°еҪ•е°ұеҸҜд»ҘдәҶпјҢеҚійқһеҸ¶еӯҗиҠӮзӮ№жІЎжңүи®°еҪ•еҢ…еҗ«еҲ—пјҢвҖңзҙўеј•еҢ…еҗ«еҲ—вҖқи§ҒдёӢж–Ү第3з« иҠӮгҖӮ
B+ж ‘иҝҷдёӘзү№зӮ№пјҲжүҖжңүж•°жҚ®ең°еқҖйғҪжңүеӯҳеңЁеҸ¶еӯҗиҠӮзӮ№пјүд№ҹеҲ©дәҺbetween value1 and value2 еҢәй—ҙжҹҘиҜўпјҢеҸӘиҰҒжүҫеҲ°value1е’Ңvalue2пјҲеңЁеҸ¶еӯҗиҠӮзӮ№пјүпјҢ然еҗҺжҠҠдёӯй—ҙдёІиө·жқҘе°ұжҳҜиҰҒзҡ„з»“жһңдәҶгҖӮ
SqlServerзҙўеј•з»“жһ„жӣҙеғҸжҳҜB+ж ‘пјҢжңҖз»ҲжҳҜBж ‘е’ҢB+ж ‘зҡ„ж··еҗҲзүҲпјҢж•°жҚ®з»“жһ„йғҪжҳҜдәәе®ҡзҡ„пјҢдёҚдёҖе®ҡе°ұжҳҜзәҜзІ№зҡ„Bж ‘жҲ–иҖ…еҚ•зәҜзҡ„B+ж ‘гҖӮ
3.зҙўеј•еҢ…еҗ«еҲ—е’Ңд№ҰзӯҫжҹҘжүҫ
и°ҲеҲ°зҙўеј•пјҢиҝҷиҫ№еҶҚи®ІдёҖдёӘSqlServer2005ејҖе§ӢеўһеҠ зҡ„вҖңзҙўеј•еҢ…еҗ«еҲ—вҖқеҠҹиғҪпјҢеҫҲе®һз”ЁгҖӮ
жҜ”еҰӮпјҢеңЁеӨ§жҠҘиЎЁжҹҘиҜўж•°жҚ®ж—¶пјҢwhereжқЎд»¶з”ЁеҲ°зҙўеј•еӯ—ж®өName2пјҢдҪҶжҳҜиҰҒselectзҡ„еӯ—ж®өжҳҜName1пјҢиҝҷж—¶еҖҷеҸҜд»ҘдҪҝз”ЁвҖңзҙўеј•еҢ…еҗ«еҲ—вҖқжҠҠName1еҢ…еҗ«еңЁзҙўеј•еӯ—ж®өName2дёӯпјҢеӨ§еӨ§жҸҗй«ҳжҹҘиҜўжҖ§иғҪгҖӮ
иҜӯжі•пјҡ Create [UNIQUE] Nonclustered/Clustered Index IndexName On dbo.Table1(Name2) Include(Name1);
жҺҘдёӢжқҘеҲҶжһҗдёәд»Җд№Ҳзҙўеј•еҢ…еҗ«еҲ—еҸҜд»ҘеӨ§еӨ§жҸҗй«ҳжҖ§иғҪгҖӮд»Қ然дҪҝз”ЁDBCC PAGEе‘Ҫд»ӨпјҢжҹҘзңӢдёҖдёӘйқһиҒҡйӣҶзҙўеј•е№¶жңүеҢ…еҗ«еҲ—зҡ„зҙўеј•ж•°жҚ®жғ…еҶөпјҡ
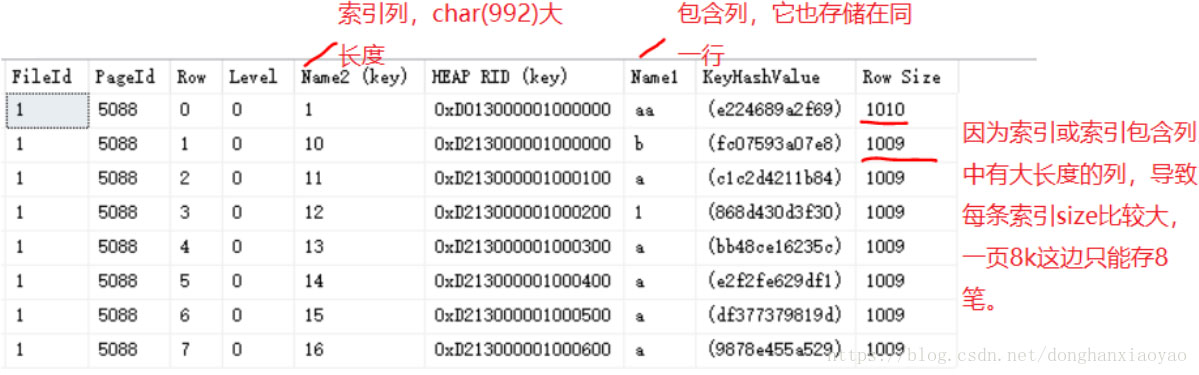
з”ұдёҠеӣҫеҸҜзҹҘпјҢеҢ…еҗ«еҲ—Name1д№ҹеӯҳеӮЁеңЁзҙўеј•ж•°жҚ®дёӯгҖӮеӣ жӯӨпјҢеҪ“ж•°жҚ®еә“з”Ёзҙўеј•еӯ—ж®өName2е®ҡдҪҚеҲ°иҰҒжҹҘжүҫзҡ„жҹҗдёҖиЎҢж—¶пјҢе°ұеҸҜд»ҘзӣҙжҺҘжҠҠName1зҡ„еҖјиҝ”еӣһдәҶпјҢиҖҢдёҚз”ЁеҶҚж №жҚ®RIDпјҲдёҠеӣҫжҳҜгҖҗHEAP RID(Key)гҖ‘еҲ—пјүе®ҡдҪҚеҲ°ж•°жҚ®йЎөдёӯеҺ»еҸ–еҖјпјҢеҚіеҮҸе°‘дәҶд№ҰзӯҫжҹҘжүҫгҖӮеҪ“жҹҘиҜўеҸӘиҝ”еӣһдёҖжқЎж•°жҚ®пјҢеҸӘжңүдёҖж¬Ўд№ҰзӯҫжҹҘжүҫж—¶еҪ“然没д»Җд№ҲпјҢеҰӮжһңжҹҘиҜўиҝ”еӣһзҡ„ж•°жҚ®еҫҲеӨ§пјҢжҜҸдёҖ笔йғҪиҰҒеҺ»ж•°жҚ®йЎөжүҫж•°жҚ®еҸ–еҮәжқҘпјҢ1000笔е°ұжҳҜ1000ж¬Ўд№ҰзӯҫжҹҘжүҫпјҢеҸҜжғіиҖҢзҹҘжҖ§иғҪж¶ҲиҖ—еҫҲеӨ§пјҢиҝҷж—¶еҖҷвҖңзҙўеј•еҢ…еҗ«еҲ—вҖқд»·еҖје°ұеӨ§еӨ§дҪ“зҺ°еҮәжқҘдәҶгҖӮ
е…ідәҺдёҖж¬Ўд№ҰзӯҫжҹҘжүҫпјҢиЎЁжңүиҒҡйӣҶзҙўеј•пјҲжҜ”еҰӮIdпјүж—¶е°ұжҳҜзұ»дјјжү§иЎҢдәҶдёҖж¬Ў select Name1 from Table1 where Id=1 пјҢеҲ©з”ЁиҒҡйӣҶзҙўеј•й”®IdжҹҘжүҫпјҲжҹҘжүҫж–№ејҸе°ұжҳҜзҙўеј•Idзҡ„Bж ‘з»“жһ„жҹҘжүҫпјүпјҢиҖҢеҰӮжһңиЎЁжІЎжңүиҒҡйӣҶзҙўеј•пјҢеҲҷжҳҜж №жҚ®ж•°жҚ®иЎҢжҢҮй’ҲпјҲз”ұвҖңж–Ү件еҸ·2byteпјҡйЎөеҸ·4byteпјҡж§ҪеҸ·2byteвҖқз»„жҲҗпјүжҹҘжүҫгҖӮиҒҡйӣҶзҙўеј•й”®е’ҢиЎҢжҢҮй’ҲдёҖиҲ¬з»ҹз§°дёәRIDпјҲRow IDпјүжҢҮй’ҲгҖӮд»ҺиҝҷйҮҢжҲ‘们еҸҜд»ҘжғіеҲ°пјҢеҰӮжһңдҪ зҡ„иЎЁжІЎжңүеҫҲеҘҪзҡ„иҒҡйӣҶзҙўеј•еӯ—ж®өпјҢе»әи®®иҮӘеўһй•ҝзҡ„Idеӯ—ж®өеҒҡиҒҡйӣҶзҙўеј•дё»й”®пјҲеҶ—дҪҷеҮәIdеӯ—ж®өд№ҹиЎҢпјүпјҢе®ғз¬ҰеҗҲиҮӘеўһй•ҝгҖҒдёҚиў«жӣҙж”№гҖҒе”ҜдёҖжҖ§гҖҒй•ҝеәҰе°Ҹзҡ„зү№жҖ§пјҢжҳҜиҒҡйӣҶзҙўеј•зҡ„еҫҲеҘҪйҖүжӢ©гҖӮ
иҮӘеўһй•ҝIdз»қеӨ§йғЁеҲҶжғ…еҶөдёӢжҳҜйҖӮз”Ёзҡ„пјҢзү№ж®Ҡзҡ„жғ…еҶөзңӢе…·дҪ“йңҖжұӮиҖҢе®ҡеҗ§гҖӮиҝҳжңүиҮӘеўһй•ҝIdиҰҒиҖғиҷ‘дёҖдёӘзјәйҷ·пјҢеҪ“еҜ№иЎЁеӨ§ж•°жҚ®йҮҸзҡ„并еҸ‘insertи®°еҪ•ж—¶пјҢеҸҜд»ҘжғіиұЎжҜҸдёӘзәҝзЁӢйғҪжҳҜиҰҒinsertеҲ°жң«е°ҫйӮЈдёӘйЎөпјҢе°ұдјҡеҸ‘з”ҹз«һдәүе’Ңзӯүеҫ…гҖӮи§ЈеҶіиҝҷз§Қжғ…еҶөдҪ еҸҜд»Ҙз”Ёuniqueidentifierзұ»еһӢеӯ—ж®өпјҲ16еӯ—иҠӮпјҢжҲ‘жҳҜдёҚе»әи®®дҪҝз”ЁпјүжҲ–иҖ…е“ҲеёҢеҲҶеҢәпјҲе°ұжҳҜдёҖдёӘиЎЁеҲҶжҲҗеӨҡдёӘиЎЁпјҢеӨ§ж•°жҚ®еӨ„зҗҶдёӯеҲҶеә“еҲҶиЎЁжҳҜжӯЈеёёзҡ„пјүзӯүгҖӮдҪҶжҳҜжҲ‘е»әи®®е…ҲдјҳеҢ–дҪ зҡ„insertж•ҲзҺҮпјҲinsertжҖ§иғҪжң¬иә«жҳҜеҫҲеҝ«зҡ„пјүпјҢжөӢиҜ•жҜҸ秒并еҸ‘insertж•°жҳҜеҗҰж»Ўи¶із”ҹдә§зҺҜеўғпјҢд»Ҙдҝқз•ҷз®ҖеҚ•зЁіе®ҡй«ҳж•Ҳзҡ„иҮӘеўһй•ҝIdдҪңжі•гҖӮ
иҮӘеўһй•ҝIdдёҚдёҖе®ҡе°ұжҳҜз”Ёж•°жҚ®еә“жҸҗдҫӣзҡ„иҮӘеўһй•ҝпјҢдҪ д№ҹеҸҜд»ҘиҮӘе·ұеҶҷз®—жі•з”ҹжҲҗдёҖдёӘ并еҸ‘жғ…еҶөдёӢд№ҹиғҪе”ҜдёҖзҡ„IdпјҲиҝҷж—¶еҖҷдёҖиҲ¬й•ҝеәҰжҳҜbitintпјҢ8еӯ—иҠӮж•ҙеҪўпјүпјҢиҝҷз§Қжғ…еҶөйҖӮеҗҲеңәжҷҜжҳҜеҲҶеёғејҸж•°жҚ®еә“дёӯдё»д»ҺеӨҚеҲ¶ж—¶Idж ҸдҪҚжҳҜиҰҒжұӮдёҖе®ҡдёҚиғҪеҮәй”ҷзҡ„жғ…еҶөпјҲдё»д»ҺеӨҚеҲ¶зҡ„дёҖиҲ¬жЁЎејҸдёӢпјҢдё»еә“зҡ„IdжҳҜжҢүдё»еә“еўһй•ҝпјҢд»Һеә“Idд№ҹжҳҜжҢүд»Һеә“иҮӘе·ұзҡ„еўһй•ҝпјҢеҰӮжһңйҒҮеҲ°жӯ»й”ҒзӯүеҺҹеӣ еҜјиҮҙдё»д»ҺеӨҚеҲ¶дёҚеҗҢжӯҘж—¶пјҢйӮЈд»Һеә“зҡ„Idе°ұе’Ңдё»еә“зҡ„IdиҮӘеўһй•ҝе°ұеҜ№дёҚдёҠеҸ·дәҶпјүгҖӮеҰӮжһңиҮӘеўһй•ҝIdжҳҜеҶ—дҪҷеҮәзҡ„дё»й”®пјҢйӮЈдё»д»Һеә“IdеҜ№дёҚдёҠеҸ·д№ҹе°ұж— еҪұе“ҚгҖӮ
еҸҰеӨ–пјҢдёҠеӣҫжңҖеҗҺдёҖеҲ—гҖҗRow SizeгҖ‘иҝҳе‘ҠиҜүжҲ‘们пјҢзҙўеј•еҲ—жҲ–зҙўеј•еҢ…еҗ«еҲ—зҡ„sizeдёҚиҰҒеӨӘй•ҝпјҢеҗҰеҲҷдёҖйЎөе®№дёҚдәҶеҮ 笔记еҪ•пјҢиҝҷж ·еӨ§еӨ§еўһеҠ дәҶзҙўеј•йЎөж•°йҮҸпјҢиҖҢдё”зҙўеј•ж•°жҚ®жүҖеҚ зҡ„з©әй—ҙд№ҹеӨ§еӨ§еўһеҠ дәҶгҖӮ
д»ҘдёҠжҳҜвҖңSQL Serverзҙўеј•зҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ





