对于每种资源,检查:
1、 Utilization 使用率
2、 Saturation 饱和度
3、 Errors 错误
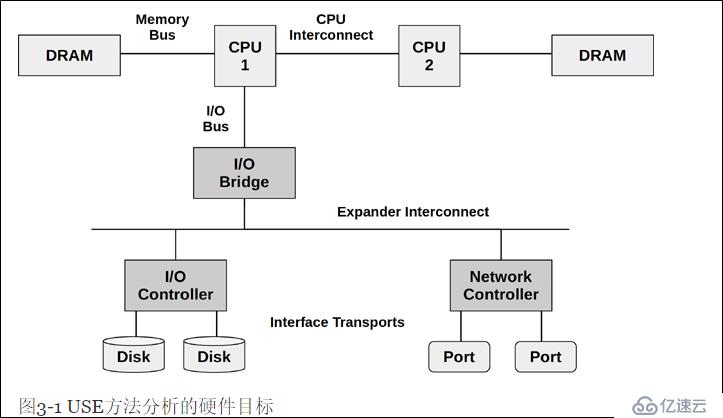
这个内容来自性能分析大神和Netflix性能工程团队
1、 uptime
2、 dmesg | tail
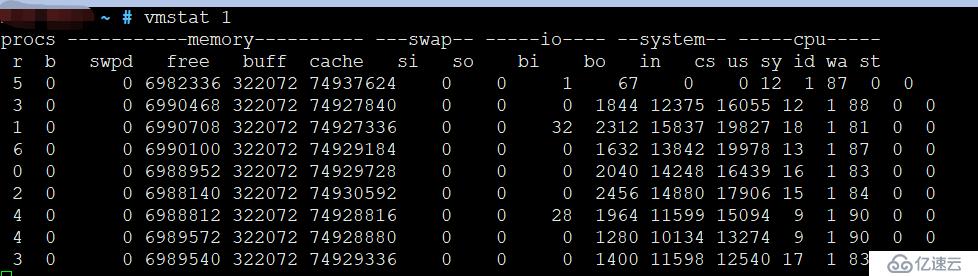
3、 vmstat 1
4、 mpstat -P ALL 1
5、 pidstat 1
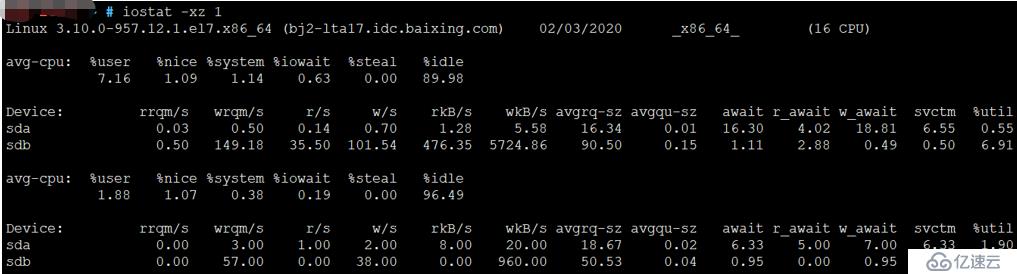
6、 iostat -xz 1
7、 free -m
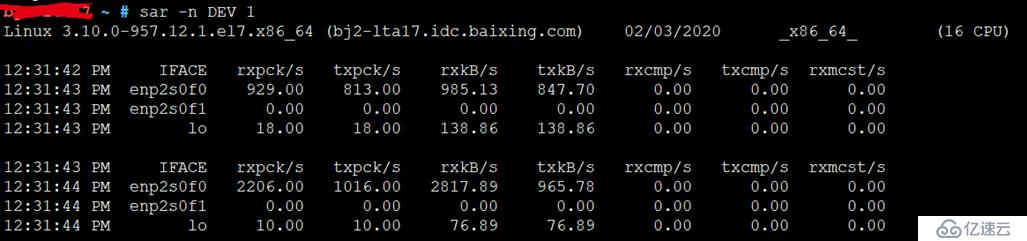
8、 sar -n DEV 1
9、 sar -n TCP,ETCP 1
10、 top
uptime
这是查看平均负载的快速方法,该平均负载指示要运行的任务(进程)的数量。在Linux系统上,这些数字包括要在CPU上运行的进程以及在不可中断I / O(通常是磁盘I / O)中阻塞的进程。这给出了资源负载(或需求)的高级概念,然后可以使用其他工具进一步探索。
首次响应问题时,可以检查平均负载,以查看问题是否仍然存在。在容错环境中,遇到性能问题的服务器可能会在您登录查看时自动从服务中删除。15分钟的平均负载过高,而1分钟的平均负载过低,则表明您登录得太迟而无法发现问题。
dmesg | tail
[1880957.563150] perl invoked oom-killer: gfp_mask=0x280da, order=0, oom_score_adj=0[...][1880957.563400] Out of memory: Kill process 18694 (perl) score 246 or sacrifice child[1880957.563408] Killed process 18694 (perl) total-vm:1972392kB, anon-rss:1953348kB,file-rss:0kB[2320864.954447] TCP: Possible SYN flooding on port 7001. Dropping request. CheckSNMP counters.
这将显示过去的10条系统消息(如果有的话),查找可能导致性能问题的错误。
上面的示例包括OOM killer和TCP SYN flooding造成的连接丢弃情况。TCP消息甚至指向您进行下一个分析区域:SNMP计数器。
vmstat 1
这是起源于BSD的虚拟内存统计工具,它还显示其他系统指标。
请注意,第一行数字是自启动以来的摘要(内存计数器除外)。
mpstat -P ALL 1
$ mpstat -P ALL 1[...]03:16:41 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle03:16:42 AM all 14.27 0.00 0.75 0.44 0.00 0.00 0.06 0.00 0.00 84.4803:16:42 AM 0 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.0003:16:42 AM 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.0003:16:42 AM 2 8.08 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 91.9203:16:42 AM 3 10.00 0.00 1.00 0.00 0.00 0.00 1.00 0.00 0.00 88.0003:16:42 AM 4 1.01 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 98.9903:16:42 AM 5 5.10 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 94.9003:16:42 AM 6 11.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 89.0003:16:42 AM 7 10.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 90.00[...]此命令显示按CPU时间划分成状态的时间。
输出显示了一个问题:CPU 0达到了100%的用户时间,这是单线程瓶颈的证据。
还需要注意到是否有iowait很高的情况出现。以及可以通过syscall和kernel tracing以及CPU分析来探索的%sys时间。
pidstat 1
pidstat(1)显示每个进程的CPU使用率。top(1)是用于此目的的流行工具;但是,pidstat(1)默认提供滚动输出,以便可以看到随时间的变化。
$ pidstat 1Linux 4.13.0-19-generic (...) 08/04/2018 _x86_64_ (16 CPU)03:20:47 AM UID PID %usr %system %guest %CPU CPU Command03:20:48 AM 0 1307 0.00 0.98 0.00 0.98 8 irqbalance03:20:48 AM 33 12178 4.90 0.00 0.00 4.90 4 java03:20:48 AM 33 12569 476.47 24.51 0.00 500.98 0 java03:20:48 AM 0 130249 0.98 0.98 0.00 1.96 1 pidstat03:20:48 AM UID PID %usr %system %guest %CPU CPU Command03:20:49 AM 33 12178 4.00 0.00 0.00 4.00 4 java03:20:49 AM 33 12569 331.00 21.00 0.00 352.00 0 java03:20:49 AM 0 129906 1.00 0.00 0.00 1.00 8 sshd03:20:49 AM 0 130249 1.00 1.00 0.00 2.00 1 pidstat03:20:49 AM UID PID %usr %system %guest %CPU CPU Command03:20:50 AM 33 12178 4.00 0.00 0.00 4.00 4 java03:20:50 AM 113 12356 1.00 0.00 0.00 1.00 11 snmp-pass03:20:50 AM 33 12569 210.00 13.00 0.00 223.00 0 java03:20:50 AM 0 130249 1.00 0.00 0.00 1.00 1 pidstat[...]此输出表明Java进程每秒消耗的CPU数量是变化的。注意这些百分比是所有CPU的总和,所以500%等于五个CPU的100%。
iostat -xz 1
此工具显示存储设备I / O指标。每个磁盘设备的输出列都在此处用换行符表示,因此很难读取。
free -m
推荐使用 -w 参数, 显示的更详细
sar -n DEV 1
sar工具具有用于不同度量标准组的多种模式。
在这里,我使用它来查看网络设备指标。检查接口吞吐量rxkB/s和txkB/s,以查看是否已达到任何限制。
图上可以看到 enp2s0f0的received接收到的流量在 985和 2817kb/s , sended 发出的流量在 847.7和965.78kb/s的样子。
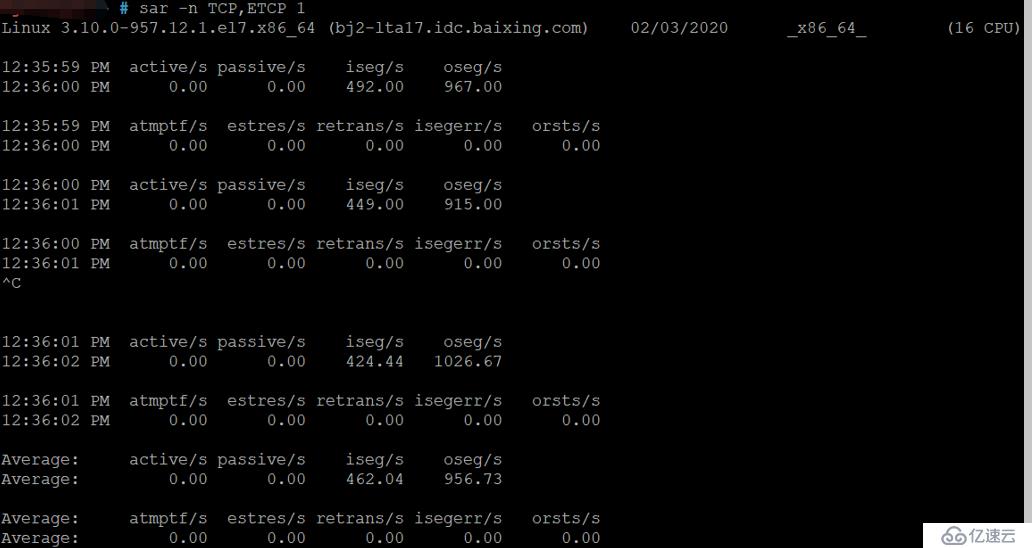
sar -n TCP,ETCP 1
现在,我们使用sar(1)查看TCP指标和TCP错误。要检查的列:
active/s: 每秒本地启动的TCP连接数(例如,通过connect()) ,主动对外发起连接(可以理解为client模式)
passive/s: 每秒远程启动的TCP连接数(例如,通过accept()) ,被动接收外部连接请求(可以理解为server模式)
retrans/s: 每秒TCP重传的次数
主动和被动连接计数对于表征工作负载很有用。重新传输是网络或远程主机问题的迹象。
top
top命令,可以具备uptime的功能。此外还能按照cpu或者内存使用率排序、搜索指定进程。 总体而言,top命令具备很强大的process、cpu、mem瓶颈分析功能。这里不过多介绍。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



