CephFsзҡ„ж“ҚдҪңж–№жі•
иҝҷзҜҮж–Үз« дё»иҰҒдёәеӨ§е®¶иҜҰз»Ҷд»Ӣз»ҚдәҶCephFsзҡ„ж“ҚдҪңж–№жі•пјҢж–Үдёӯе…ідәҺCephFsзҡ„жһ¶жһ„д»ҘеҸҠCephFsзҡ„йғЁзҪІй…ҚзҪ®д»Ӣз»Қзҡ„йқһеёёиҜҰз»ҶпјҢйӣ¶еҹәзЎҖд№ҹиғҪеҸӮиҖғжӯӨж–Үз« пјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们еҸҜд»ҘеҸӮиҖғдёҖдёӢгҖӮ
дёҖгҖҒCephFsд»Ӣз»Қ
Ceph File System (CephFS) жҳҜдёҺ POSIX ж ҮеҮҶе…је®№зҡ„ж–Ү件系з»ҹ, иғҪеӨҹжҸҗдҫӣеҜ№ Ceph еӯҳеӮЁйӣҶзҫӨдёҠзҡ„ж–Ү件и®ҝй—®. Jewel зүҲжң¬ (10.2.0) жҳҜ第дёҖдёӘеҢ…еҗ«зЁіе®ҡ CephFS зҡ„ Ceph зүҲжң¬. CephFS йңҖиҰҒиҮіе°‘дёҖдёӘе…ғж•°жҚ®жңҚеҠЎеҷЁ (Metadata Server - MDS) daemon (ceph-mds) иҝҗиЎҢ, MDS daemon з®ЎзҗҶзқҖдёҺеӯҳеӮЁеңЁ CephFS дёҠзҡ„ж–Ү件зӣёе…ізҡ„е…ғж•°жҚ®, 并且еҚҸи°ғзқҖеҜ№ Ceph еӯҳеӮЁзі»з»ҹзҡ„и®ҝй—®гҖӮ
иҜҙеңЁеүҚйқўзҡ„иҜқпјҢcephfsе…¶е®һжҳҜдёәз”ЁжҲ·жҸҗдҫӣзҡ„дёҖдёӘж–Ү件系з»ҹпјҢжҠҠcephиҝҷдёӘиҪҜ件жҠҠйҮҢйқўзҡ„з©әй—ҙпјҢжЁЎжӢҹдёҖдёӘж–Ү件系з»ҹзҡ„ж јејҸжқҘжҸҗдҫӣжңҚеҠЎпјҢе®ғжңүposixж ҮеҮҶзҡ„ж–Ү件系з»ҹзҡ„жҺҘеҸЈиғҪеӨҹдёәcephйӣҶзҫӨеӯҳеӮЁж–Ү件пјҢиғҪеӨҹжҸҗдҫӣи®ҝй—®пјҢзӣ®еүҚеңЁеӨ§еӨҡж•°е…¬еҸёз”Ёcephfsд№ҹжҳҜжҜ”иҫғе°‘зҡ„пјҢд№ҹжҳҜз”ұдәҺжҖ§иғҪеҺҹеӣ пјҢдҪҶжҳҜд№ҹжңүдёҖдәӣеңәжҷҜд№ҹдјҡз”ЁеҲ°гҖӮ
еҜ№иұЎеӯҳеӮЁзҡ„жҲҗжң¬жҜ”иө·жҷ®йҖҡзҡ„ж–Ү件еӯҳеӮЁиҝҳжҳҜиҫғй«ҳпјҢйңҖиҰҒиҙӯд№°дё“й—Ёзҡ„еҜ№иұЎеӯҳеӮЁиҪҜ件д»ҘеҸҠеӨ§е®№йҮҸзЎ¬зӣҳгҖӮеҰӮжһңеҜ№ж•°жҚ®йҮҸиҰҒжұӮдёҚжҳҜжө·йҮҸпјҢеҸӘжҳҜдёәдәҶеҒҡж–Ү件е…ұдә«зҡ„ж—¶еҖҷпјҢзӣҙжҺҘз”Ёж–Ү件еӯҳеӮЁзҡ„еҪўејҸеҘҪдәҶпјҢжҖ§д»·жҜ”й«ҳгҖӮ
дәҢгҖҒCephFS жһ¶жһ„
еә•еұӮжҳҜж ёеҝғйӣҶзҫӨжүҖдҫқиө–зҡ„, еҢ…жӢ¬:
OSDs (ceph-osd): CephFS зҡ„ж•°жҚ®е’Ңе…ғж•°жҚ®е°ұеӯҳеӮЁеңЁ OSDs дёҠ
MDS (ceph-mds): Metadata Servers, з®ЎзҗҶзқҖ CephFS зҡ„е…ғж•°жҚ®
Mons (ceph-mon): Monitors з®ЎзҗҶзқҖйӣҶзҫӨ Map зҡ„дё»еүҜжң¬
еӣ дёәиҝҷдёӘmapйҮҢйқўз»ҙжҠӨзқҖеҫҲеӨҡж•°жҚ®зҡ„дҝЎжҒҜзҙўеј•пјҢжүҖжңүзҡ„ж•°жҚ®йғҪиҰҒд»ҺmonsдёӯmapйҮҢиҺ·еҸ–еҺ»osdйҮҢжүҫиҝҷдёӘж•°жҚ®пјҢе…¶е®һиҺ·еҸ–иҝҷдёӘж•°жҚ®зҡ„жөҒзЁӢеӨ§жҰӮйғҪжҳҜдёҖж ·зҡ„пјҢеҸӘдёҚиҝҮе®ғеӯҳеңЁзҡ„жҳҜдёҚеҗҢзҡ„еә“пјҢдёҚеҗҢзҡ„map
Ceph еӯҳеӮЁйӣҶзҫӨзҡ„еҚҸи®®еұӮжҳҜ Ceph еҺҹз”ҹзҡ„ librados еә“, дёҺж ёеҝғйӣҶзҫӨдәӨдә’.
CephFS еә“еұӮеҢ…жӢ¬ CephFS еә“ libcephfs, е·ҘдҪңеңЁ librados зҡ„йЎ¶еұӮ, д»ЈиЎЁзқҖ Cephж–Ү件系з»ҹ.жңҖдёҠеұӮжҳҜиғҪеӨҹи®ҝй—® Cephж–Ү件系з»ҹзҡ„дёӨзұ»е®ўжҲ·з«ҜпјҢз”ұдәҺжңүиҝҷдёӘlibcephfsиҝҷдёӘеә“пјҢcephfsжүҚиғҪеҜ№еӨ–жҸҗдҫӣжңҚеҠЎпјҢеӣ дёәеә•еұӮжҳҜдёҚиғҪжҸҗдҫӣжңҚеҠЎзҡ„пјҢйғҪеҫ—йҖҡиҝҮе®ғиҝҷдёӘ第дёүж–№зҡ„libеә“жүҚиғҪеҺ»жҸҗдҫӣи®ҝй—®пјҢ
е…ғж•°жҚ®пјҡж–Ү件зҡ„еҗҚеӯ—е’ҢеұһжҖ§дҝЎжҒҜеҸ«е…ғж•°жҚ®пјҢе’Ңж•°жҚ®жҳҜйҡ”зҰ»ејҖзҡ„
CephFsзҡ„ж•°жҚ®жҳҜжҖҺд№Ҳи®ҝй—®зҡ„пјҹ
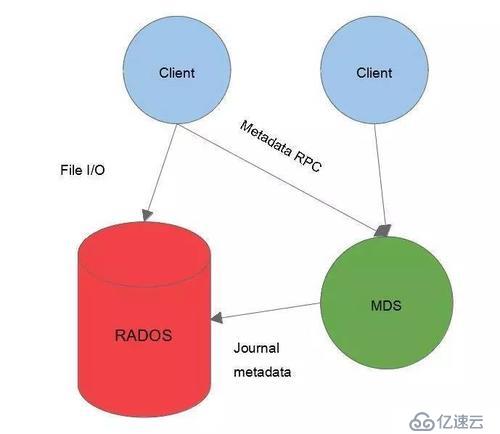
йҰ–е…Ҳе®ўжҲ·з«ҜйҖҡиҝҮRPCеҚҸи®®еҲ°иҫҫMDSпјҢд»ҺMDSиҺ·еҸ–еҲ°е…ғж•°жҚ®зҡ„дҝЎжҒҜпјҢе®ўжҲ·з«ҜдёҺRADOSиҺ·еҸ–ж–Ү件зҡ„дёҖдёӘIOж“ҚдҪңпјҢйӮЈд№ҲжңүдәҶиҝҷдёӨд»ҪдҝЎжҒҜпјҢз”ЁжҲ·е°ұиғҪеҫ—еҲ°дәҶжғіиҰҒзҡ„йӮЈд»Ҫж–Ү件пјҢMDSе’ҢRADOSд№Ӣй—ҙйҖҡиҝҮjournal metadate,иҝҷдёӘJournalжҳҜи®°еҪ•ж–Ү件еҶҷе…Ҙж—Ҙеҝ—зҡ„пјҢиҝҷдёӘд№ҹжҳҜеӯҳж”ҫеҲ°OSDеҪ“дёӯзҡ„пјҢMDSе’Ңradosд№Ӣй—ҙд№ҹжҳҜз”ұдәӨдә’зҡ„пјҢеӣ дёәжүҖжңүжңҖз»Ҳзҡ„ж•°жҚ®йғҪдјҡеӯҳеҲ°radosеҪ“дёӯ
 !
!
дёүгҖҒй…ҚзҪ® CephFS MDS
иҰҒдҪҝз”Ё CephFSпјҢ иҮіе°‘е°ұйңҖиҰҒдёҖдёӘ metadata server иҝӣзЁӢгҖӮеҸҜд»ҘжүӢеҠЁеҲӣе»әдёҖдёӘ MDSпјҢ д№ҹеҸҜд»ҘдҪҝз”Ё ceph-deploy жҲ–иҖ… ceph-ansible жқҘйғЁзҪІ MDSгҖӮ
зҷ»еҪ•еҲ°ceph-deployе·ҘдҪңзӣ®еҪ•жү§иЎҢ
hostnameжҢҮе®ҡcephйӣҶзҫӨзҡ„дё»жңәеҗҚ
#ceph-deploy mds create $hostname
еӣӣгҖҒйғЁзҪІCephж–Ү件系з»ҹ
йғЁзҪІдёҖдёӘ CephFS, жӯҘйӘӨеҰӮдёӢ:
еңЁдёҖдёӘ Mon иҠӮзӮ№дёҠеҲӣе»ә Cephж–Ү件系з»ҹ.
иӢҘдҪҝз”Ё CephX и®ӨиҜҒ,йңҖиҰҒеҲӣе»әдёҖдёӘи®ҝй—® CephFS зҡ„е®ўжҲ·з«Ҝ
жҢӮиҪҪ CephFS еҲ°дёҖдёӘдё“з”Ёзҡ„иҠӮзӮ№.
д»Ҙ kernel client еҪўејҸжҢӮиҪҪ CephFS
д»Ҙ FUSE client еҪўејҸжҢӮиҪҪ CephFS
1гҖҒеҲӣе»әдёҖдёӘ Ceph ж–Ү件系з»ҹ
1гҖҒйҰ–е…ҲиҰҒеҲӣе»әдёӨдёӘpoolпјҢдёҖдёӘжҳҜcephfs-dataпјҢдёҖдёӘжҳҜcephfs-metadateпјҢеҲҶеҲ«еӯҳеӮЁж–Ү件数жҚ®е’Ңж–Ү件е…ғж•°жҚ®пјҢиҝҷдёӘpgд№ҹеҸҜд»Ҙи®ҫзҪ®е°ҸдёҖзӮ№пјҢиҝҷдёӘж №жҚ®OSDеҺ»й…ҚзҪ®
#ceph osd pool create cephfs-data 256 256
#ceph osd pool create cephfs-metadata 64 64
жҹҘзңӢе·Із»ҸеҲӣе»әжҲҗеҠҹ
[root@cephnode01 my-cluster]# ceph osd lspools
1 .rgw.root
2 default.rgw.control
3 default.rgw.meta
4 default.rgw.log
5 rbd
6 cephfs-data
7 cephfs-metadata
е…ідәҺcephзҡ„ж—Ҙеҝ—пјҢеҸҜд»ҘеңЁ/var/log/cephдёӢеҸҜд»ҘжҹҘзңӢеҲ°зӣёе…ідҝЎжҒҜ
[root@cephnode01 my-cluster]# tail -f /var/log/ceph/ceph
ceph.audit.log ceph.log ceph-mgr.cephnode01.log ceph-osd.0.log
ceph-client.rgw.cephnode01.log ceph-mds.cephnode01.log ceph-mon.cephnode01.log ceph-volume.log
жіЁпјҡдёҖиҲ¬ metadata pool еҸҜд»Ҙд»ҺзӣёеҜ№иҫғе°‘зҡ„ PGs еҗҜеҠЁ, д№ӢеҗҺеҸҜд»Ҙж №жҚ®йңҖиҰҒеўһеҠ PGs. еӣ дёә metadata pool еӯҳеӮЁзқҖ CephFSж–Ү件зҡ„е…ғж•°жҚ®, дёәдәҶдҝқиҜҒе®үе…Ё, жңҖеҘҪжңүиҫғеӨҡзҡ„еүҜжң¬ж•°. дёәдәҶиғҪжңүиҫғдҪҺзҡ„延иҝҹ, еҸҜд»ҘиҖғиҷ‘е°Ҷ metadata еӯҳеӮЁеңЁ SSDs дёҠ.
2гҖҒеҲӣе»әдёҖдёӘ CephFS, еҗҚеӯ—дёә cephfs:йңҖиҰҒжҢҮе®ҡдёӨдёӘеҲӣе»әзҡ„poolзҡ„еҗҚеӯ—
#ceph fs new cephfs cephfs-metadata cephfs-data
new fs with metadata pool 7 and data pool 6
3гҖҒйӘҢиҜҒиҮіе°‘жңүдёҖдёӘ MDS е·Із»Ҹиҝӣе…Ҙ Active зҠ¶жҖҒпјҢд№ҹе°ұжҳҜжҙ»и·ғ
еҸҰеӨ–еҸҜд»ҘзңӢеҲ°дёӨдёӘеӨҮз”Ёзҡ„жҳҜcephnode01,е’Ңcephnode03
#ceph fs status cephfs
cephfs - 0 clients
+------+--------+------------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------------+---------------+-------+-------+
| 0 | active | cephnode02 | Reqs: 0 /s | 10 | 13 |
+------+--------+------------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs-metadata | metadata | 1536k | 17.0G |
| cephfs-data | data | 0 | 17.0G |
+-----------------+----------+-------+-------+
+-------------+
| Standby MDS |
+-------------+
| cephnode01 |
| cephnode03 |
+-------------+
MDS version: ceph version 14.2.7 (3d58626ebeec02d8385a4cefb92c6cbc3a45bfe8) nautilus (stable)
4гҖҒеңЁ Monitor дёҠ, еҲӣе»әдёҖдёӘеҸ«client.cephfsзҡ„з”ЁжҲ·пјҢз”ЁдәҺи®ҝй—®CephFs
#ceph auth get-or-create client.cephfs mon 'allow r' mds 'allow rw' osd 'allow rw pool=cephfs-data, allow rw pool=cephfs-metadata'
иҝҷйҮҢдјҡз”ҹжҲҗдёҖдёӘkey,з”ЁжҲ·йңҖиҰҒжӢҝиҝҷдёӘkeyеҺ»и®ҝй—®
[client.cephfs]
key = AQA5IV5eNCwMGRAAy4dIZ8+ISfBcwZegFTYD6Q==
жҹҘзңӢжқғйҷҗеҲ—иЎЁпјҢжңүе“Әдәӣз”ЁжҲ·еҲӣе»әдәҶжқғйҷҗ
[root@cephnode01 my-cluster]# ceph auth list
client.cephfs
key: AQA5IV5eNCwMGRAAy4dIZ8+ISfBcwZegFTYD6Q==
caps: [mds] allow rw
caps: [mon] allow r
caps: [osd] allow rw pool=cephfs-data, allow rw pool=cephfs-metadata
client.rgw.cephnode01
key: AQBOAl5eGVL/HBAAYH93c4wPiBlD7YhuPY0u7Q==
caps: [mon] allow rw
caps: [osd] allow r
5гҖҒйӘҢиҜҒkeyжҳҜеҗҰз”ҹж•Ҳ
#ceph auth get client.cephfs
еҸҜд»ҘзңӢеҲ°иҝҷдёӘз”ЁжҲ·жҳҜжӢҘжңүи®ҝй—®cephfsзҡ„иҜ»еҶҷжқғйҷҗзҡ„
exported keyring for client.cephfs
[client.cephfs]
key = AQA5IV5eNCwMGRAAy4dIZ8+ISfBcwZegFTYD6Q==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rw pool=cephfs-data, allow rw pool=cephfs-metadata"
6гҖҒжЈҖжҹҘCephFsе’ҢmdsзҠ¶жҖҒ
#ceph -s жҹҘзңӢйӣҶзҫӨе·Із»ҸеўһеҠ mdsй…ҚзҪ®
cluster:
id: 75aade75-8a3a-47d5-ae44-ec3a84394033
health: HEALTH_OK
services:
mon: 3 daemons, quorum cephnode01,cephnode02,cephnode03 (age 2h)
mgr: cephnode01(active, since 2h), standbys: cephnode02, cephnode03
mds: cephfs:1 {0=cephnode02=up:active} 2 up:standby
osd: 3 osds: 3 up (since 2h), 3 in (since 2h)
rgw: 1 daemon active (cephnode01)
data:
pools: 7 pools, 96 pgs
objects: 263 objects, 29 MiB
usage: 3.1 GiB used, 54 GiB / 57 GiB avail
pgs: 96 active+clean
#ceph mds stat
иҝҷйҮҢжҳҫзӨә1дёӘжҳҜactiveзҠ¶жҖҒпјҢ2дёӘеӨҮз”ЁзҠ¶жҖҒ
cephfs:1 {0=cephnode02=up:active} 2 up:standby
#ceph fs ls
иҝҷйҮҢжңүдёӨдёӘpool
name: cephfs, metadata pool: cephfs-metadata, data pools: [cephfs-data ]
#ceph fs status
1.1 д»Ҙ kernel client еҪўејҸжҢӮиҪҪ CephFS
иҝҷйҮҢдҪҝз”Ёе…¶д»–зҡ„жңәеҷЁиҝӣиЎҢжҢӮиҪҪпјҢиҝҷйҮҢжҳҜжҳҜд»Ҙprometheusдё»жңәжҢӮиҪҪпјҢдёҚиҝҮиҝҷдёӘеңЁе“ӘжҢӮиҪҪйғҪеҸҜд»ҘпјҢkernelдё»иҰҒиҒ”зі»зі»з»ҹеҶ…ж ёпјҢе’Ңзі»з»ҹеҶ…ж ёиҝӣиЎҢеҒҡзӣёдә’пјҢз”Ёиҝҷз§Қж–№ејҸиҝӣиЎҢжҢӮиҪҪж–Ү件系з»ҹ
1гҖҒеҲӣе»әжҢӮиҪҪзӣ®еҪ• cephfs
#mkdir /cephfs
2гҖҒжҢӮиҪҪзӣ®еҪ•пјҢиҝҷйҮҢеҶҷйӣҶзҫӨcephиҠӮзӮ№зҡ„ең°еқҖпјҢеҗҺйқўи·ҹеҲӣе»әз”ЁжҲ·и®ҝй—®йӣҶзҫӨзҡ„key
#mount -t ceph 192.168.1.10:6789,192.168.1.11:6789,192.168.1.12:6789:/ /cephfs/ -o name=cephfs,secret=AQDHjeddHlktJhAAxDClZh9mvBxRea5EI2xD9w==
3гҖҒиҮӘеҠЁжҢӮиҪҪ
#echo "mon1:6789,mon2:6789,mon3:6789:/ /cephfs ceph name=cephfs,secretfile=/etc/ceph/cephfs.key,_netdev,noatime 0 0" | sudo tee -a /etc/fstab
4гҖҒйӘҢиҜҒжҳҜеҗҰжҢӮиҪҪжҲҗеҠҹ
#stat -f /cephfs
ж–Ү件пјҡ"/cephfs"
IDпјҡ4f32eedbe607030e ж–Ү件еҗҚй•ҝеәҰпјҡ255 зұ»еһӢпјҡceph
еқ—еӨ§е°Ҹпјҡ4194304 еҹәжң¬еқ—еӨ§е°Ҹпјҡ4194304
еқ—пјҡжҖ»и®Ўпјҡ4357 з©әй—Іпјҡ4357 еҸҜз”Ёпјҡ4357
Inodes: жҖ»и®Ўпјҡ0 з©әй—Іпјҡ-1
1.2 д»Ҙ FUSE client еҪўејҸжҢӮиҪҪ CephFS
1гҖҒе®үиЈ…ceph-commonпјҢе®үиЈ…еҘҪеҸҜд»ҘдҪҝз”Ёrbd,cephзӣёе…іе‘Ҫд»Ө
иҝҷйҮҢиҝҳжҳҜдҪҝз”ЁжҲ‘们зҡ„еҶ…зҪ‘yumжәҗжқҘе®үиЈ…иҝҷдәӣдҫқиө–еҢ…
yum -y install epel-release
yum install -y ceph-common
2гҖҒе®үиЈ…ceph-fuseпјҢcephзҡ„е®ўжҲ·з«Ҝе·Ҙе…·пјҢд№ҹе°ұжҳҜз”Ёcephзҡ„ж–№ејҸжҠҠиҝҷдёӘж–Ү件系з»ҹжҢӮдёҠ
yum install -y ceph-fuse
3гҖҒе°ҶйӣҶзҫӨзҡ„ceph.confжӢ·иҙқеҲ°е®ўжҲ·з«Ҝ
scp root@192.168.1.10:/etc/ceph/ceph.conf /etc/ceph/
chmod 644 /etc/ceph/ceph.conf
4гҖҒдҪҝз”Ё ceph-fuse жҢӮиҪҪ CephFS
еҰӮжһңжҳҜеңЁе…¶д»–дё»жңәжҢӮиҪҪзҡ„иҜқпјҢйңҖиҰҒиҝҷдёӘдҪҝз”Ёcephfsзҡ„key,иҝҷдёӘжҳҜеҲҡжүҚжҲ‘们еҲӣе»әеҘҪзҡ„
зӣҙжҺҘжӢҝиҝҷеҸ°жңҚеҠЎеҷЁдёҠз”Ёе°ұеҸҜд»Ҙ
[root@prometheus ~]# more /etc/ceph/ceph.client.cephfs.keyring
exported keyring for client.cephfs
[client.cephfs]
key = AQA5IV5eNCwMGRAAy4dIZ8+ISfBcwZegFTYD6Q==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rw pool=cephfs-data, allow rw pool=cephfs-metadata"
#ceph-fuse --keyring /etc/ceph/ceph.client.cephfs.keyring --name client.cephfs -m 192.168.1.10:6789,192.168.1.11:6789,192.168.1.12:6789 /cephfs/
5гҖҒйӘҢиҜҒ CephFS е·Із»ҸжҲҗеҠҹжҢӮиҪҪ
#df -h
ceph-fuse 18G 0 18G 0% /cephfs
#stat -f /cephfs
ж–Ү件пјҡ"/cephfs/"
IDпјҡ0 ж–Ү件еҗҚй•ҝеәҰпјҡ255 зұ»еһӢпјҡfuseblk
еқ—еӨ§е°Ҹпјҡ4194304 еҹәжң¬еқ—еӨ§е°Ҹпјҡ4194304
еқ—пјҡжҖ»и®Ўпјҡ4357 з©әй—Іпјҡ4357 еҸҜз”Ёпјҡ4357
Inodes: жҖ»и®Ўпјҡ1 з©әй—Іпјҡ0
6гҖҒиҮӘеҠЁжҢӮиҪҪ
#echo "none /cephfs fuse.ceph ceph.id=cephfs[,ceph.conf=/etc/ceph/ceph.conf],_netdev,defaults 0 0"| sudo tee -a /etc/fstab
жҲ–
#echo "id=cephfs,conf=/etc/ceph/ceph.conf /mnt/ceph3 fuse.ceph _netdev,defaults 0 0"| sudo tee -a /etc/fstab
7гҖҒеҚёиҪҪ
#fusermount -u /cephfs
дә”гҖҒMDSдё»еӨҮдёҺдё»дё»еҲҮжҚў
1гҖҒй…ҚзҪ®дё»дё»жЁЎејҸ
еҪ“cephfsзҡ„жҖ§иғҪеҮәзҺ°еңЁMDSдёҠж—¶пјҢе°ұеә”иҜҘй…ҚзҪ®еӨҡдёӘжҙ»еҠЁзҡ„MDSгҖӮйҖҡеёёжҳҜеӨҡдёӘе®ўжҲ·жңәеә”з”ЁзЁӢеәҸ并иЎҢзҡ„жү§иЎҢеӨ§йҮҸе…ғж•°жҚ®ж“ҚдҪңпјҢ并且е®ғ们еҲҶеҲ«жңүиҮӘе·ұеҚ•зӢ¬зҡ„е·ҘдҪңзӣ®еҪ•гҖӮиҝҷз§Қжғ…еҶөдёӢеҫҲйҖӮеҗҲдҪҝз”ЁеӨҡдё»MDSжЁЎејҸгҖӮ
й…ҚзҪ®MDSеӨҡдё»жЁЎејҸ
жҜҸдёӘcephfsж–Ү件系з»ҹйғҪжңүдёҖдёӘmax_mdsи®ҫзҪ®пјҢеҸҜд»ҘзҗҶи§Јдёәе®ғе°ҶжҺ§еҲ¶еҲӣе»әеӨҡе°‘дёӘдё»MDSгҖӮжіЁж„ҸеҸӘжңүеҪ“е®һйҷ…зҡ„MDSдёӘж•°еӨ§дәҺжҲ–зӯүдәҺmax_mdsи®ҫзҪ®зҡ„еҖјж—¶пјҢmdx_mdsи®ҫзҪ®жүҚдјҡз”ҹж•ҲгҖӮдҫӢеҰӮпјҢеҰӮжһңеҸӘжңүдёҖдёӘMDSе®ҲжҠӨиҝӣзЁӢеңЁиҝҗиЎҢпјҢ并且max_mdsиў«и®ҫзҪ®дёәдёӨдёӘпјҢеҲҷдёҚдјҡеҲӣе»ә第дәҢдёӘдё»MDSгҖӮ
ж·»еҠ и®ҫзҪ®max_mds 2пјҢд№ҹе°ұжҳҜжҲҗ2дёӘactivity,1дёӘstandbyпјҢз§°дёәдё»дё»еӨҮжЁЎејҸ
#ceph fs set cephfs max_mds 2
[root@cephnode01 ceph]# ceph fs status
cephfs - 1 clients
+------+--------+------------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------------+---------------+-------+-------+
| 0 | active | cephnode02 | Reqs: 0 /s | 11 | 14 |
| 1 | active | cephnode01 | Reqs: 0 /s | 10 | 13 |
+------+--------+------------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs-metadata | metadata | 2688k | 16.8G |
| cephfs-data | data | 521M | 16.8G |
+-----------------+----------+-------+-------+
+-------------+
| Standby MDS |
+-------------+
| cephnode03 |
+-------------+
д№ҹе°ұжҳҜеҪ“дҪ cephfsз”Ёзҡ„еӨҡзҡ„иҜқпјҢж•°жҚ®йҮҸеӨ§зҡ„иҜқпјҢе°ұдјҡеҮәзҺ°жҖ§иғҪзҡ„й—®йўҳпјҢд№ҹе°ұжҳҜеҪ“й…ҚзҪ®еӨҡдёӘavtiveзҡ„mdsзҡ„ж—¶еҖҷдјҡйҒҮеҲ°зі»з»ҹ瓶йўҲпјҢиҝҷдёӘж—¶еҖҷе°ұйңҖиҰҒй…ҚзҪ®дё»дё»жЁЎејҸпјҢжҠҠиҝҷдёӘж•°жҚ®еҒҡдёҖдёӘзұ»дјјзҡ„иҙҹиҪҪеқҮиЎЎпјҢеӨҡдё»зҡ„иҜқд№ҹе°ұжҳҜиҝҷдәӣдё»дјҡеҗҢж—¶жҸҗдҫӣжңҚеҠЎ
# 1.3гҖҒй…ҚзҪ®еӨҮз”ЁMDS
еҚідҪҝжңүеӨҡдёӘжҙ»еҠЁзҡ„MDSпјҢеҰӮжһңе…¶дёӯдёҖдёӘMDSеҮәзҺ°ж•…йҡңпјҢд»Қ然йңҖиҰҒеӨҮз”Ёе®ҲжҠӨиҝӣзЁӢжқҘжҺҘз®ЎгҖӮеӣ жӯӨпјҢеҜ№дәҺй«ҳеҸҜз”ЁжҖ§зі»з»ҹпјҢе®һйҷ…й…ҚзҪ®max_mdsж—¶пјҢжңҖеҘҪжҜ”зі»з»ҹдёӯMDSзҡ„жҖ»ж•°е°‘дёҖдёӘгҖӮ
дҪҶеҰӮжһңдҪ зЎ®дҝЎдҪ зҡ„MDSдёҚдјҡеҮәзҺ°ж•…йҡңпјҢеҸҜд»ҘйҖҡиҝҮд»ҘдёӢи®ҫзҪ®жқҘйҖҡзҹҘcephдёҚйңҖиҰҒеӨҮз”ЁMDSпјҢеҗҰеҲҷдјҡеҮәзҺ°insufficient standby daemons availableе‘ҠиӯҰдҝЎжҒҜпјҡ
#ceph fs set <fs> standby_count_wanted 0
2гҖҒиҝҳеҺҹеҚ•дё»MDS
2.1гҖҒи®ҫзҪ®max_mds
иҰҒжҳҜиҝҳеҺҹзҡ„иҜқпјҢзӣҙжҺҘи®ҫзҪ®дёәmax_mds 1д№ҹе°ұжҳҜдёҖдёӘactivityдёӨдёӘstandby
#ceph fs set max_mds 1
[root@cephnode01 ceph]# ceph fs status
cephfs - 1 clients
======
+------+--------+------------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------------+---------------+-------+-------+
| 0 | active | cephnode02 | Reqs: 0 /s | 11 | 14 |
+------+--------+------------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs-metadata | metadata | 2688k | 16.8G |
| cephfs-data | data | 521M | 16.8G |
+-----------------+----------+-------+-------+
+-------------+
| Standby MDS |
+-------------+
| cephnode03 |
| cephnode01 |
+-------------+
еҰӮжһңжғіеңЁе®ўжҲ·з«ҜеҺ»жү§иЎҢзӣёе…ізҡ„cephе‘Ҫд»Өзҡ„иҜқпјҢйңҖиҰҒе®үиЈ…ceph-commonд»ҘеҸҠceph-fuseе®ўжҲ·з«Ҝе·Ҙе…·е°ҶиҝҷдёӘceph.client.admin.keyringд»ҘеҸҠceph.confж–Ү件жӢ·еҲ°зӣёеә”зҡ„е®ўжҲ·з«Ҝд№ҹеҸҜд»Ҙжү§иЎҢcephе‘Ҫд»ӨдәҶ
[root@cephnode01 ceph]# scp ceph.client.admin.keyring root@192.168.1.14:/etc/ceph
root@192.168.1.14's password:
ceph.client.admin.keyring
[root@prometheus ceph]# ceph -s
cluster:
id: 75aade75-8a3a-47d5-ae44-ec3a84394033
health: HEALTH_OK
services:
mon: 3 daemons, quorum cephnode01,cephnode02,cephnode03 (age 4h)
mgr: cephnode01(active, since 4h), standbys: cephnode02, cephnode03
mds: cephfs:2 {0=cephnode02=up:active,1=cephnode03=up:active} 1 up:standby
osd: 3 osds: 3 up (since 4h), 3 in (since 4h)
rgw: 1 daemon active (cephnode01)
data:
pools: 7 pools, 96 pgs
objects: 345 objects, 203 MiB
usage: 3.6 GiB used, 53 GiB / 57 GiB avail
pgs: 96 active+clean
д»ҘдёҠе°ұжҳҜCephFsзҡ„иҜҰз»ҶеҶ…е®№дәҶпјҢзңӢе®Ңд№ӢеҗҺжҳҜеҗҰжңүжүҖ收иҺ·е‘ўпјҹеҰӮжһңжғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№жҲ–иҖ…жғізҹҘйҒ“е…·дҪ“зҡ„йғЁзҪІе’Ңй…ҚзҪ®жӯҘйӘӨпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®ҜпјҒ





