数据导出不完全等于数据备份:
- 数据导出是指将数据库中的数据逆向成SQL语句进行导出,所以导出的是SQL文件。通常用作把数据从一个系统迁移到另一个系统,目的是屏蔽系统之间的差异性
- 数据备份是指将数据库中数据存储的相关文件进行拷贝,用于保存一个数据库的全部物理数据,所以备份后的数据与原本数据在细节及状态上都是完全一致的。不会像SQL那样在使用了一些函数的情况下,可能会在不同的时间点或不同的系统上产生不一样的结果
冷备份与热备份:
- 冷备份:在数据库已经关闭的情况下,对数据的备份称作冷备份
- 热备份:与冷备份相反,在数据库节点不停机的状态下进行的备份被称作热备份
冷备份的限制:
- 数据库必须停机备份,这对一些线上数据库是无法接受的
- 备份的数据文件非常占用存储空间,并且不支持增量备份
- 冷备份是备份所有的数据文件和日志文件,所以无法单独备份某个逻辑库和数据表
联机冷备份:
单节点的数据库在冷备份时需要停机,这就会对业务系统产生影响。为了解决这个问题,我们可以组建集群然后挑选集群中的一个节点进行停机冷备份。由于集群中还有其他节点在运行,所以不必担心影响正在运行的系统。等备份结束之后再启动该节点,这样就能解决停机备份带来的影响
热备份的限制:
- 数据库在热备份的时候会全局加读锁,备份期间节点只能读取数据不能写入数据
联机热备份:
同样的方式,为了避免全局加锁,我们可以挑选集群中的一个节点与其他节点解除数据同步关系后进行热备份。等待备份完成后,再去恢复与集群中其他节点的数据同步关系。这样在备份过程中就只有该节点会加读锁,其他节点不会受到影响
联机热备份与联机冷备份该如何选择:
建议选择联机热备份,因为热备份可以选择全量备份或增量备份。而冷备份只能选择全量备份,当后期数据量很大的时候,冷备份需要耗费很多的时间,并且由于是全量备份也需要占用更多的存储空间。热备份只有在第一次备份的时候需要选择全量备份,后续备份只需要增量备份新数据即可。 因此,热备份在存储空间的占用及备份耗费的时间上都优于冷备份
上一小节提到了数据备份是指将数据库中数据存储的相关文件进行拷贝,而这些文件有很多,所以让我们来简单认识下MySQL中与数据相关的文件。
首先是组成逻辑库的文件,在MySQL中一个逻辑库实际由多个文件组成,其结构如下: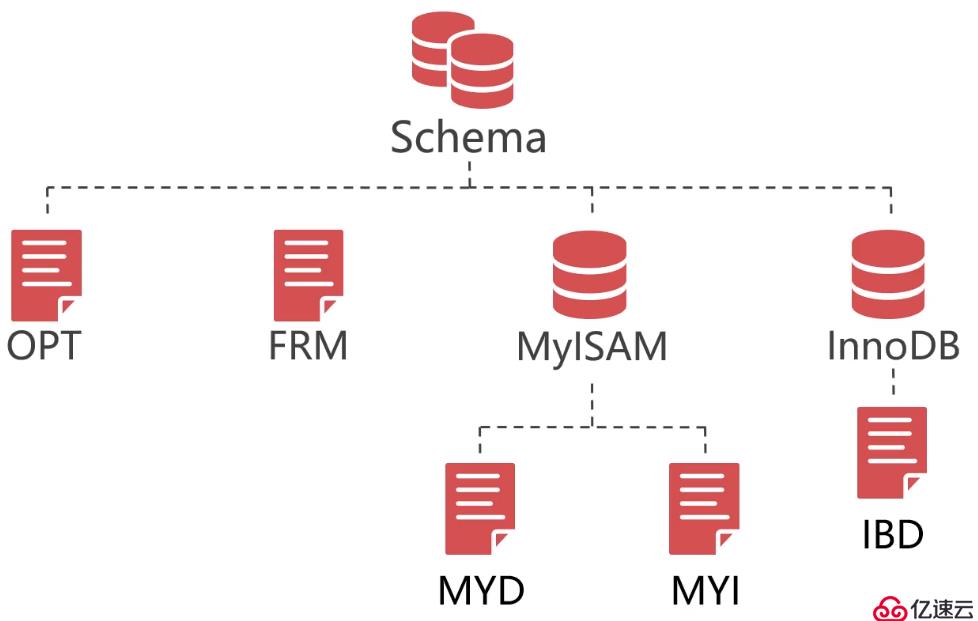
OPT文件:定义字符集和字符集的排序规则,该文件是一个文本文件FRM文件:这是数据表的定义文件,包含了数据表的结构信息。无论数据表使用的什么存储引擎,每一个数据表的定义文件一定是FRM文件ISL文件:该文件只有创建了表分区才会出现,它存储着表分区数据文件所在的路径MYD文件:MyISAM的数据文件MYI文件:MyISAM的索引文件IBD文件:InnoDB的索引及数据文件,该文件是一个二进制文件FRM文件在很多情况下都会被用到,例如数据库在执行SQL语句之前,先会审查SQL语句中用到的一些字段是否在FRM文件中定义了。或者数据库在优化SQL语句时,通过FRM文件判断where子句中的字段是否是主键列或索引列等。因为FRM文件经常会被使用,所以该文件是一个二进制文件
MySQL中的其他文件:
auto.cnf文件:该文件存储MySQL实例的UUID,即server-uuid,在集群中可以作为节点的唯一标识grastate.dat文件:该文件保存的是PXC的同步信息gvwstate.dat文件:该文件保存的是PXC集群中其他节点的信息.pem:该文件存储的是加解密用的证书和密钥信息.sock:套接字文件,用于本地连接MySQL.err:错误日志文件,MySQL所有错误信息都会保存在该文件中.pid:MySQL进程id文件ib_buffer_pool:InnoDB缓存文件ib_logfile:InnoDB事务日志(redo)ibdata:InnoDB共享表空间文件logbin:日志文件(binlog)index:日志索引文件ibtmp:临时表空间文件数据文件中的碎片是什么:
MySQL的数据文件一直存在着碎片化问题,MySQL之所以不会自动整理碎片缩减数据文件的体积,是因为这个整理过程是会锁表的。如果每删除一条数据就锁表整理碎片,那么势必会对数据表的读写造成很大的影响。不过MySQL在写入新数据时,会优先将其写入碎片空间,所以数据文件中的碎片空间对日常运行没有什么影响。
但是对于数据库备份这个场景来说,如果数据文件中存在着大量的碎片,就会导致实际有意义的数据没多少,而数据文件的体积又很大。这对备份来说就很占用存储空间和传输带宽,所以在进行备份之前,需要对数据文件的碎片进行一个整理,尽量缩减数据文件的体积。
MySQL中整理数据文件碎片的SQL语句如下:
alter table ${table_name} engine=InnoDB;需要注意的是,在执行该SQL之前,记得先将用于备份的数据库节点的binlog给关掉。避免binlog中记录了该SQL,导致在节点备份完成恢复到集群后,其他节点同步了该SQL出现整个集群锁表的情况。所以需要注释掉MySQL配置文件中的以下两个参数,在备份完成后再打开:
# log_bin
# log_slave_updates在前面介绍了一些前置知识后,本小节就逐步演示一下如何实践联机冷备份。我这里事先准备了一个由三个节点组成的PXC集群:
首先挑选集群中的任意一个节点作为备份节点,然后停止该节点:
[root@PXC-Node3 ~]# systemctl stop mysqld编辑配置文件,注释binlog相关参数:
[root@PXC-Node3 ~]# vim /etc/percona-xtradb-cluster.conf.d/mysqld.cnf
[mysqld]
...
#log-bin
#log_slave_updates然后注释PXC集群相关参数:
[root@PXC-Node3 ~]# vim /etc/percona-xtradb-cluster.conf.d/wsrep.cnf
[mysqld]
#wsrep_provider=/usr/lib64/galera3/libgalera_smm.so
#wsrep_cluster_address=gcomm://192.168.190.132,192.168.190.133,192.168.190.134
#wsrep_slave_threads=8
#wsrep_log_conflicts
#wsrep_cluster_name=pxc-cluster
#wsrep_node_name=pxc-node-03
#pxc_strict_mode=DISABLED
#wsrep_sst_method=xtrabackup-v2
#wsrep_node_address=192.168.190.134
#wsrep_sst_auth=admin:Abc_123456修改完毕后,启动MySQL服务,此时该节点就退出了PXC集群:
[root@PXC-Node3 ~]# systemctl start mysqld该节点的数据文件有1.1个G:
[root@PXC-Node3 ~]# du -h /var/lib/* |grep /var/lib/mysql$
1.1G /var/lib/mysql
[root@PXC-Node3 ~]# 本示例中是对test库进行备份,所以在进行备份之前,需要对test库下所有的表进行碎片整理。由于表比较多,我这里编写了一个简单的Java程序来实现:
import com.mysql.jdbc.Driver;
import java.sql.*;
import java.util.ArrayList;
/**
* 数据表碎片整理
*
* @author 01
* @date 2020-01-25
**/
public class CleanFragments {
public static void main(String[] args) throws SQLException {
DriverManager.registerDriver(new Driver());
String url = "jdbc:mysql://192.168.190.134:3306/test?useSSL=false";
String username = "admin";
String password = "Abc_123456";
try (Connection connection = DriverManager.getConnection(url, username, password);
PreparedStatement pst = connection.prepareStatement("show tables;")) {
ResultSet resultSet = pst.executeQuery();
ArrayList<String> tableNames = new ArrayList<>();
while (resultSet.next()) {
tableNames.add(resultSet.getString(1));
}
for (String tableName : tableNames) {
if ("t_range_1".equals(tableName)) {
continue;
}
System.out.println("整理 " + tableName + " 表碎片...");
pst.execute("alter table " + tableName + " engine=InnoDB;");
}
}
System.out.println("整理完毕...");
}
}碎片整理完成后,停止MySQL服务,因为冷备份需要停机:
[root@PXC-Node3 ~]# systemctl stop mysqld然后就可以开始备份了,其实备份的过程也很简单,没用到啥高大上的特殊技术,就是使用tar命令将MySQL数据目录打成一个压缩包即可。例如我这里的数据目录是/var/lib/mysql,所以执行的命令如下:
# 先进入到/var/lib/目录下
[root@PXC-Node3 ~]# cd /var/lib/
# 然后对数据目录进行打包,mysql.tar.gz是打包后的文件名,存放在/home目录下
[root@PXC-Node3 /var/lib]# tar -zcvf /home/mysql.tar.gz ./mysqldatadir参数定义的如果创建了表分区,并且将表分区映射到了其他目录上,那么就还需要对表分区进行打包。例如我这里有两个表分区,分别映射到了/mnt/p0/data/和/mnt/p1/data/目录,所以执行的命令如下:
[root@PXC-Node3 ~]# cd /mnt/
[root@PXC-Node3 /mnt]# tar -zcvf /home/p0.tar.gz ./p0/data/
[root@PXC-Node3 /mnt]# tar -zcvf /home/p1.tar.gz ./p1/data/到此备份完成后,恢复配置文件中所注释的配置项,然后重启节点让该节点重新加入到PXC集群中即可。由于没啥需要特殊说明的,所以这里就不演示了。
演示了如何冷备份后,接下来则演示如何将备份文件冷还原到其他的PXC节点上。首先将备份文件传输到需要还原的节点上,可以使用scp或rsync命令在Linux系统之间传输文件,如下示例:
[root@PXC-Node3 /home]# scp ./mysql.tar.gz 192.168.190.133:/home/mysql.tar.gz
[root@PXC-Node3 /home]# scp ./p0.tar.gz 192.168.190.133:/home/p0.tar.gz
[root@PXC-Node3 /home]# scp ./p1.tar.gz 192.168.190.133:/home/p1.tar.gz还原节点接收到的备份文件如下:
[root@PXC-Node2 ~]# cd /home/
[root@PXC-Node2 /home]# ls
mysql.tar.gz p0.tar.gz p1.tar.gz
[root@PXC-Node2 /home]#除此之外还需要进行一些准备工作,因为备份节点是存在表分区的,并且映射了相应的数据目录,若还原节点不存在则需要创建。如下示例:
[root@PXC-Node2 ~]# mkdir /mnt/p0/
[root@PXC-Node2 ~]# mkdir /mnt/p1/由于是冷还原,所以和冷备份一样也需要先停止还原节点:
[root@PXC-Node2 ~]# systemctl stop mysqld还原MySQL的数据目录,命令如下:
# 先备份原本的数据目录,以防万一
[root@PXC-Node2 ~]# mv /var/lib/mysql /var/lib/mysql-backup
# 将压缩文件解压到/var/lib/目录下
[root@PXC-Node2 /home]# tar -zxvf mysql.tar.gz -C /var/lib/然后是还原表分区数据目录:
[root@PXC-Node2 /home]# tar -zxvf p0.tar.gz -C /mnt/
[root@PXC-Node2 /home]# tar -zxvf p1.tar.gz -C /mnt/删除auto.cnf文件,不然uuid重复的话,该节点是无法启动的:
[root@PXC-Node2 ~]# rm -rf /var/lib/mysql/auto.cnf如果你是使用PXC集群中的首节点作为备份节点,那么就还需要将grastate.dat文件中的safe_to_bootstrap参数修改为0,普通节点则不需要。如下示例:
[root@PXC-Node2 ~]# vim /var/lib/mysql/grastate.dat
...
safe_to_bootstrap: 0到此就算是还原完成了,启动MySQL服务即可:
[root@PXC-Node2 ~]# systemctl start mysqld剩下就是自行验证下该节点的数据是否正确还原了,能否与集群中其他节点进行数据同步等。以及最后清理掉之前备份的旧数据目录:
[root@PXC-Node2 ~]# rm -rf /var/lib/mysql-backup冷备份的实际用途:
经过以上小节,现在我们已经了解了冷备份和冷还原,从本节开始我们来学习热备份。热备份是数据库运行的状态下备份数据,也是难度最大的备份。PXC集群常见的热备份有LVM和XtraBackup两种方案。
利用Linux的LVM技术来实现热备份,将MySQL的数据目录放到LVM逻辑卷上,然后通过LVM快照技术备份逻辑卷的内容。第一次备份是全量备份,之后的备份都是增量备份。在还原时,将快照中的数据目录恢复到ySQL的数据目录即可。
使用LVM这种技术不仅可以备份MySQL还可以备份MongoDB等其他数据库,但使用LVM做热备份方案也比较麻烦,因为需要手动创建逻辑卷、迁移数据目录、创建快照以及给数据库加锁等等,所以LVM并不是常用的热备份方案。
因为LVM的麻烦,所以人们都希望使用专业的工具去做热备份,这个工具就是XtraBackup。XtraBackup是由Percona开源的免费数据库热备份工具,它能对InnoDB数据库和XtraDB存储引擎的数据库非阻塞地备份。因为XtraBackup在备份过程中不会打断正在执行的事务,而事务日志中记录了哪些是备份前写入的数据哪些是备份后写入的数据,所以无需加锁。
另外,XtraBackup提供了对备份数据的压缩功能,可以节约备份文件占用的磁盘空间及网络带宽。但XtraBackup在备份使用MyISAM作为存储引擎的表时会加读锁,即表中的数据可读但不可写,不过这也不是问题,之前提到了可以使用联机热备份的方式来解决加读锁的问题。同样,XtraBackup支持全量备份和增量备份,因为XtraBackup的方便性,所以一般都是采用XtraBackup来做热备份方案。
系统中通常会同时存在全量备份和增量备份,以防其中一个备份出了问题,还有另一个备份可以使用。由于全量热备份比较耗时,所以一般不会经常执行,会间隔一段时间才执行一次。例如,每个月一号零点执行或每周一零点执行等。
在Linux中有一个crontab命令,可以在固定的间隔时间执行指定的系统指令或shell脚本。使用crontab命令结合shell脚本可以实现定时的全量热备份。
这里就举例演示一下,首先编写执行全量热备份的shell脚本如下:
[root@PXC-Node3 ~]# vim full-backup.sh
#!/bin/bash
time=`date "+%Y-%m-%d %H:%M:%S"`
echo '执行全量热备份 '$time
innobackupex --defaults-file=/etc/my.cnf --host=192.168.190.134 --user=admin --password=Abc_123456 --port=3306 --no-timestamp --stream=xbstream --encrypt=AES256 --encrypt-threads=10 --encrypt-chunk-size 512 --encrypt-key='1K!cNoq&RUfQsY&&LAczTjco' -> /home/backup/fullBackupOfMysql.xbstream赋予该脚本执行权限:
[root@PXC-Node3 ~]# chmod -R 777 full-backup.sh最后配置一下crontab即可,例如我这里定义每周一零点执行,这样就实现了定时全量热备份:
[root@PXC-Node3 ~]# crontab -e
# 每周一零点执行
0 0 * * 1 /root/full-backup.sh > /home/backup/full-backup.log 2>&1上面介绍了全量热备份后,我们来看下如何将XtraBackup备份的文件进行还原。在还原这块只能冷还原,不存在热还原,因为对一个正在运行中的数据库进行在线还原操作,而同时用户又在读写数据,这就有可能导致数据互相覆盖,使得数据库的数据发生错乱。
因此,还原这块就只能是冷还原,之前也介绍过冷还原,只不过使用XtraBackup进行冷还原会更加简单,没有还原冷备份时那么麻烦。
首先关闭MySQL服务:
[root@PXC-Node3 ~]# systemctl stop mysqld清空数据目录及表分区的数据目录:
[root@PXC-Node3 ~]# rm -rf /var/lib/mysql/*
[root@PXC-Node3 ~]# rm -rf /mnt/p0/data/*
[root@PXC-Node3 ~]# rm -rf /mnt/p1/data/*rm删除了,如果是实际的运行环境,建议先使用mv重命名需要删除的目录,最后还原完备份文件并验证没有问题后,再使用rm删除,以避免删库跑路的悲剧发生备份文件是经过压缩的,所以需要创建一个临时目录来存放解压后的文件:
[root@PXC-Node3 ~]# mkdir /home/backup/temp然后使用xbstream命令将备份文件解压至该目录下:
[root@PXC-Node3 ~]# xbstream -x < /home/backup/fullBackupOfMysql.xbstream -C /home/backup/temp/因为备份文件时进行了加密,所以解压后的文件都是加密的,需要解密备份文件:
[root@PXC-Node3 ~]# innobackupex --decrypt=AES256 --encrypt-key='1K!cNoq\&RUfQsY\&\&LAczTjco' /home/backup/temp&是特殊字符,所以需要使用\转义一下由于是热备份,所以事务日志中可能会存在一些未完成的事务,这就需要回滚没有提交的事务,以及同步已经提交的事务到数据文件。执行如下命令:
[root@PXC-Node3 ~]# innobackupex --apply-log /home/backup/temp完成以上步骤后,就可以使用以下命令对备份文件进行还原:
[root@PXC-Node3 ~]# innobackupex --defaults-file=/etc/my.cnf --copy-back /home/backup/temp接着给还原后的目录文件赋予mysql用户权限:
[root@PXC-Node3 ~]# chown -R mysql:mysql /var/lib/mysql/*到此为止就完成了冷还原,最后启动MySQL服务并自行验证下数据是否正常即可:
[root@PXC-Node3 ~]# systemctl start mysqld增量热备份必须以全量热备份为基础进行备份,所以在了解了XtraBackup的全量热备份和全量冷还原后,接下来就可以实践XtraBackup的增量热备份了。
注意事项:
之前演示冷还原的时候已经对全量备份的文件进行了解压缩和内容解密,所以这里以/home/backup/temp/备份目录为例,增量热备份命令如下:
[root@PXC-Node3 ~]# innobackupex --defaults-file=/etc/my.cnf --host=192.168.190.134 --user=admin --password=Abc_123456 --port=3306 --incremental-basedir=/home/backup/temp/ --incremental /home/backup/increment--incremental-basedir:指定全量备份文件所存储的目录,即基于哪个全量备份进行增量备份--incremental:指定采用增量备份/home/backup/increment:增量备份文件所存放的目录增量备份的文件目录如下:
[root@PXC-Node3 ~]# ls /home/backup/increment/
2020-01-26_17-02-21
[root@PXC-Node3 ~]# ls /home/backup/increment/2020-01-26_17-32-41/
backup-my.cnf ibdata1.delta mysql sys tpcc xtrabackup_checkpoints xtrabackup_logfile
ib_buffer_pool ibdata1.meta performance_schema test xtrabackup_binlog_info xtrabackup_info
[root@PXC-Node3 ~]# 可以使用du命令对比一下全量热备份与增量热备份的目录大小:
[root@PXC-Node3 ~]# du -sh /home/backup/temp/
1.6G /home/backup/temp/ # 全量热备份的目录大小
[root@PXC-Node3 ~]# du -sh /home/backup/increment/2020-01-26_17-32-41/
92M /home/backup/increment/2020-01-26_17-32-41/ # 增量热备份的目录大小
[root@PXC-Node3 ~]# 之后的第二次增量备份就可以不基于全量备份,而是基于第一次的增量备份,如下示例:
[root@PXC-Node3 ~]# innobackupex --defaults-file=/etc/my.cnf --user=admin --password=Abc_123456 --incremental-basedir=/home/backup/increment/2020-01-26_17-32-41/ --incremental /home/backup/increment如果增量备份时需要使用流式压缩和内容加密,则添加相关参数即可。如下示例:
[root@PXC-Node3 ~]# innobackupex --defaults-file=/etc/my.cnf --user=admin --password=Abc_123456 --incremental-basedir=/home/backup/increment/2020-01-26_17-32-41/ --incremental --stream=xbstream --encrypt=AES256 --encrypt-threads=10 --encrypt-chunk-size 512 --encrypt-key='1K!cNoq&RUfQsY&&LAczTjco' ./ > /home/backup/increment./表示将增量备份所有的内容都写到流式压缩文件里,压缩文件则存放在/home/backup/increment目录下通常我们会让增量热备份作为定时任务自动进行,从而避免人工定点去操作,以节省不必要的工作量。在全量热备份时介绍了使用Linux的crontab命令来实现shell脚本的定时执行,而一些主流的编程语言也都基本具备实现定时任务的框架或类库。
这里以Java为例,在Java的生态中,有Quartz和Spring框架可以实现定时任务,同样也是使用Cron表达式语法。但Java的Cron表达式可以精确到秒,这一点与Linux的Cron表达式有所不同。
由于Quartz稍微复杂些,为了简单起见这里就以Spring为例。首先创建一个Spring Boot工程,pom.xml中的依赖项如下:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>在引导类上添加@EnableScheduling注解,以开启定时调度功能:
@EnableScheduling
@SpringBootApplication
public class IncrementBackupApplication {
...
}在Linux上创建一个文件,用于记录每次增量热备份时基于哪个目录去备份。例如在第一次增量热备份时是基于全量热备份的目录进行备份的,而在这之后的增量热备份则是基于上一次增量热备份的目录进行备份:
[root@PXC-Node3 ~]# echo '/home/backup/temp/' > /home/backup/increment-backup.cnf然后编写实现定时执行增量热备份的Java类:
package com.example.incrementbackup.task;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.io.*;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
/**
* 增量热备份定时任务
*
* @author 01
* @date 2020-01-26
**/
@Slf4j
@Component
public class IncrementBackupTask {
/**
* 每分钟执行一次增量热备份
* 当然实际情况不会设置这么短的间隔时间
*/
@Scheduled(cron = "0 */1 * * * *")
public void backup() {
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd_HH_mm_ss");
String folderName = LocalDateTime.now().format(formatter);
String configPath = "/home/backup/increment-backup.cnf";
try (FileReader fileReader = new FileReader(configPath);
BufferedReader bufferedReader = new BufferedReader(fileReader)) {
String basedir = bufferedReader.readLine();
String cmd = getCmd(basedir, folderName);
log.info("开始进行增量热备份. 执行的命令:{}", cmd);
// 执行增量热备份命令
Process process = Runtime.getRuntime().exec(cmd);
// 等待命令执行完成
process.waitFor();
try (FileWriter fileWriter = new FileWriter(configPath);
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter)) {
// 更新下次增量备份所使用的basedir路径
bufferedWriter.write("/home/backup/increment/" + folderName);
log.info("增量热备份结束");
}
} catch (IOException | InterruptedException e) {
log.error("", e);
}
}
/**
* 拼装 innobackupex 命令参数
*/
private String getCmd(String basedir, String folderName) {
String cmd = "innobackupex --defaults-file=/etc/my.cnf " +
"--user=admin --password=Abc_123456 " +
"--incremental-basedir=%s --no-timestamp " +
"--incremental /home/backup/increment/%s";
return String.format(cmd, basedir, folderName);
}
}完成以上代码的编写后,使用maven将项目打成jar包,然后将该jar包上传到Linux中,通过java -jar命令执行。如下:
[root@PXC-Node3 ~]# java -jar increment-backup-0.0.1-SNAPSHOT.jar执行过程中输出的日志信息如下:
等待备份结束后,可以看到increment-backup.cnf文件的内容也更新了:
[root@PXC-Node3 ~]# cat /home/backup/increment-backup.cnf
/home/backup/increment/2020-01-26_21_06_00
[root@PXC-Node3 ~]# 生成的备份目录结构也是正常的:
[root@PXC-Node3 ~]# ls /home/backup/increment/2020-01-26_21_12_00
backup-my.cnf ibdata1.delta mysql sys tpcc xtrabackup_checkpoints xtrabackup_logfile
ib_buffer_pool ibdata1.meta performance_schema test xtrabackup_binlog_info xtrabackup_info
[root@PXC-Node3 ~]# 到此为止,我们就使用Java语言实现了定时增量热备份数据库。之所以介绍如何使用编程语言来实现,是因为实际企业应用中,可能会有一些较为复杂或个性化的需求,单纯使用shell脚本是无法实现的。例如要求备份完成后发送邮件或短信通知相关人员,又或者要求可以在UI上控制定时执行的间隔时间等等。这种需求都得使用编程语言去定制化开发才能实现。
经过以上小节可以得知增量热备份仅备份新数据,并且生成的备份目录体积也要比全量热备份生成的目录体积要小很多。那么XtraBackup要如何将增量备份的数据还原到数据库呢?其实也很简单,就是先将增量热备份的数据与全量热备份的数据合并,然后基于合并后的备份数据去还原即可。
增量热备份可以有很多个备份点,因为除第一次增量热备份外,其余的增量热备份都是基于上一次增量热备份进行的。所以在还原的时候也可以选择任意一个备份点去还原,但事务日志的处理步骤与全量冷还原不一样。
在之前演示全量冷还原的时候,有一个处理事务日志的步骤,同样增量冷还原也有这个步骤,但是有些差异。上面提到增量热备份是可以有多个备份点的,那么在还原某一个备份点时就需要处理该备份点及其之前备份点的事务日志,否则就会出现数据混乱的情况。如下图,有三个备份点: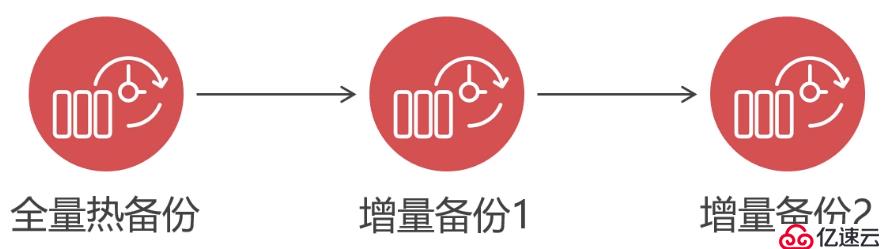
例如,当还原“增量备份1”时,需要先处理其前一个备份点的事务日志,即图中的“全量热备份”。接着再处理“增量备份1”这个备份点的事务日志,然后合并“增量备份1”的数据到“全量热备份”中。这样才能保证多个备份点合并到全量备份点后的数据是一致的,最后还原“全量热备份”中的数据即可。
再例如,要还原的是“增量备份2”,那么就得先处理“全量热备份”,然后处理“增量备份1”,接着处理“增量备份2”,按从前往后的顺序依次将这三个备份点的事务日志都给处理了后,才能合并备份点的数据到全量备份中,最后还原“全量热备份”中的数据。其余则以此类推......
接下来实操一下增量冷还原,这里有三个与上图对应的备份点目录:
/home/backup/temp/ # 全量热备份
/home/backup/increment/2020-01-27_10-11-24/ # 增量备份1
/home/backup/increment/2020-01-27_10-15-11/ # 增量备份2因为是冷还原,所以得先关闭MySQL服务:
[root@PXC-Node3 ~]# systemctl stop mysqld在本例中要还原的是“增量备份2”这个备份点的数据,按照之前的说明,首先处理全量备份点的事务日志,执行如下命令:
[root@PXC-Node3 ~]# innobackupex --apply-log --redo-only /home/backup/temp/--redo-only:指定不回滚未提交的事务,因为下个备份点的事务日志里可能会提交该备份点未提交的事务。如果回滚了就会导致下个备份点无法正常提交然后处理“增量备份1”的事务日志,并将"增量备份1"的数据合并到全量备份点上:
[root@PXC-Node3 ~]# innobackupex --apply-log --redo-only /home/backup/temp/ --incremental-dir=/home/backup/increment/2020-01-27_10-11-24/--incremental-dir:指定要合并到全量备份的增量备份目录接着处理“增量备份2”的事务日志,并将"增量备份2"的数据合并到全量备份点上。由于只还原到“增量备份2”这个备份点,所以就不需要加上--redo-only参数了,因为没有下个备份点了:
[root@PXC-Node3 ~]# innobackupex --apply-log /home/backup/temp/ --incremental-dir=/home/backup/increment/2020-01-27_10-15-11/与全量冷还原一样,也需清空数据目录及表分区的数据目录:
[root@PXC-Node3 ~]# rm -rf /var/lib/mysql/*
[root@PXC-Node3 ~]# rm -rf /mnt/p0/data/*
[root@PXC-Node3 ~]# rm -rf /mnt/p1/data/*完成以上步骤后,就可以使用如下命令完成备份文件的还原了:
[root@PXC-Node3 ~]# innobackupex --defaults-file=/etc/my.cnf --copy-back /home/backup/temp/ # 注意这里指定的是全量备份点的目录接着给还原后的目录文件赋予mysql用户权限:
[root@PXC-Node3 ~]# chown -R mysql:mysql /var/lib/mysql/*
[root@PXC-Node3 ~]# chown -R mysql:mysql /mnt/p0/data/*
[root@PXC-Node3 ~]# chown -R mysql:mysql /mnt/p1/data/*到此为止还原就完成了,最后启动MySQL服务并自行验证下数据是否正常即可:
[root@PXC-Node3 ~]# systemctl start mysqld亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



