我们知道JSON字符串是目前流行的数据交换格式,在pyhton中我们通过json模块,将常用的数据类型转化为json字符串。但是,json支持转化的数据类型是有限的。
比如,我们通过ORM从数据库查询出的结果,试图通过json序列化:
from .models import UserInfo def index(request): user_list = UserInfo.objects.all() import json return HttpResponse(json.dumps(user_list)) # TypeError: Object of type 'QuerySet' is not JSON serializable
报错,QuerySet不是JSON能序列化的对象。那么有什么办法可以解决呢?
注意,如果是通过values查询,如UserInfo.objects.values("name"),查询出来的结果虽然也是QuerySet对象,但是其结构是这样的:<QuerySet [{'name': 'egon'}, {'name': 'sb'}]>, 类似于列表套字典的结构。对于这种情况,我们可以通过list()方法将QuerySet 对象转化为列表,这样就可以直接用json.dumps()进行序列化了。
方法一:serializers
def index(request):
user_list = UserInfo.objects.all()
from django.core import serializers
user_list_json = serializers.serialize("json", user_list)
return HttpResponse(user_list_json)
将返回的结果放到bejson校验结果如下:
[
{
"model": "app01.userinfo",
"pk": 1,
"fields": {
"name": "egon",
"pwd": "123"
}
},
{
"model": "app01.userinfo",
"pk": 2,
"fields": {
"name": "sb",
"pwd": "123"
}
}
]
注:pk代表主键(可以是默认的id主键字段,也可以是用户自定义的主键字段)
观察序列化结果,发现这种方式将服务端数据库的表名都暴露了;另外serializers不支持连表序列化,只能拿到另一张表的id。下面我们我们用一种新的方式。
方法二:自定义JSON处理器
查看json.dumps源码,发现序列化时,用到了一个参数cls = JSONEncoder,我们可以继承它,自定义一个类,重写它的default方法,来处理我们需要的数据类型。比如自定义对时间对象进行转化:
import json
from datetime import date
from datetime import datetime
class JsonCustomEncoder(json.JSONEncoder):
def default(self, field):
if isinstance(field, datetime):
return field.strftime('%Y-%m-%d %H:%M:%S')
elif isinstance(field, date):
return field.strftime('%Y-%m-%d')
else:
return json.JSONEncoder.default(self, field)
下面我们试着序列化一个datetime对象:
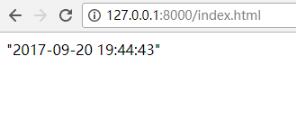
def index(request): now = datetime.now() import json return HttpResponse(json.dumps(now, cls=JsonCustomEncoder))
再次访问http://127.0.0.1:8000/index.html:
补充知识:Django ORM对象Json序列化问题
碰到了一个问题:在使用json.dumps()序列化Django ORM的Queryset对象,传递给前端的时候,程序报错:
Object of type 'QuerySet' is not JSON serializable
在python 中,常用的json 的序列化是从simplejson 基础上改变而来。这个json 包主要提供了dump,load 来实现dict 与 字符串之间的序列化与反序列化,这很方便的可以完成,但现在的问题是,这个json包不能序列化 django 的models 里面的对象的实例。
经过一番度娘搜索,发现有如下解决方案:
使用django.core自带的serializers模块:
#django ORM的 Queryset对象默认无法被直接json.dumps()序列化,django.core提供的serializers模块提供将其序列化成str类型
#的功能,serializers处理后,再次json.dumps传给前端,前端需要经过两次json.Parse()处理,才能得到原对象类型,但是格式发
#生了变化,需要按新的方式取索引.例如:obj['pk']取主键,obj['fields']["caption"]取obj的caption字段
由QuerySet:[<Business: Business object>]
变为了:
[{"model": "cmdb.business", "pk": 1, "fields": {"caption": "develop"}}]
这样前端就可以正常获取数据了,只不过此字段需要两次json.Parse()处理。
至于使用models.Host.objects.get(id=xx)的方式获取到单个对象,而非Queryset对象,serializers默认也无法处理的问题,可以自定义json方法来实现dumps序列化
json默认只支持python原生的list、tuple、dict数据类型对象的序列化,若需要扩展其他类型对象的序列化功能,可以这样修改:
import json as default_json
from json.encoder import JSONEncoder
class BaseResponse(object):
def __init__(self):
self.status = True
self.message = None
self.data = None
self.error = None
o=BaseResponse()
class JsonCustomEncoder(JSONEncoder):
def default(self, o):
if isinstance(o, BaseResponse):
return o.__dict__
return JSONEncoder.default(self, o)
o1=json.dumps(o,cls=JsonCustomEncoder)
>>> print(o1)
{"message": null, "error": null, "data": null, "status": true}
>>> print(type(o1))
<class 'str'>
#在序列化时指定cls参数,cls=自定义的序列化类,在自定义序列化类的default方法中判断,如果是指定的类的实例的话,则将该类转换成dict格式返回,若指定类的实例,则使用json模块默认的序列化方法。最终得到的return值为str类型。
以上这篇Django 再谈一谈json序列化就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





