PythonеҰӮдҪ•еӨ„зҗҶPDFдёҺCDF
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іPythonеҰӮдҪ•еӨ„зҗҶPDFдёҺCDFзҡ„еҶ…е®№гҖӮе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢдёҖиө·и·ҹйҡҸе°Ҹзј–иҝҮжқҘзңӢзңӢеҗ§гҖӮ
еңЁжӢҝеҲ°ж•°жҚ®еҗҺпјҢжңҖйңҖиҰҒеҒҡзҡ„е·ҘдҪңд№ӢдёҖе°ұжҳҜжҹҘзңӢдёҖдёӢиҮӘе·ұзҡ„ж•°жҚ®еҲҶеёғжғ…еҶөгҖӮиҖҢй’ҲеҜ№ж•°жҚ®зҡ„еҲҶеёғпјҢеҸҲеҢ…жӢ¬pdfе’ҢcdfдёӨзұ»гҖӮ
дёӢйқўд»Ӣз»ҚдҪҝз”Ёpythonз”ҹжҲҗpdfзҡ„ж–№жі•пјҡ
дҪҝз”Ёmatplotlibзҡ„з”»еӣҫжҺҘеҸЈhist()пјҢзӣҙжҺҘз”»еҮәpdfеҲҶеёғпјӣ
дҪҝз”Ёnumpyзҡ„ж•°жҚ®еӨ„зҗҶеҮҪж•°histogram()пјҢеҸҜд»Ҙз”ҹжҲҗpdfеҲҶеёғж•°жҚ®пјҢж–№дҫҝиҝӣиЎҢеҗҺз»ӯзҡ„ж•°жҚ®еӨ„зҗҶпјҢжҜ”еҰӮиҝӣдёҖжӯҘз”ҹжҲҗcdfпјӣ
дҪҝз”Ёseabornзҡ„distplot()пјҢеҘҪеӨ„жҳҜеҸҜд»ҘиҝӣиЎҢpdfеҲҶеёғзҡ„жӢҹеҗҲпјҢжҹҘзңӢиҮӘе·ұж•°жҚ®зҡ„еҲҶеёғзұ»еһӢпјӣ
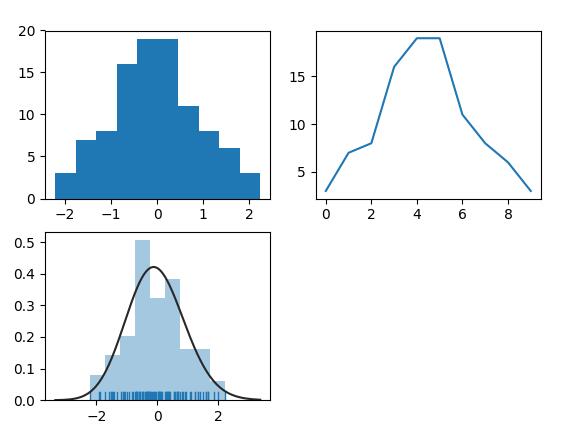
дёҠеӣҫжүҖзӨәдёәйҮҮз”Ё3з§Қз®—жі•з”ҹжҲҗзҡ„pdfеӣҫгҖӮдёӢйқўжҳҜжәҗд»Јз ҒгҖӮ
from scipy import stats
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
arr = np.random.normal(size=100)
# plot histogram
plt.subplot(221)
plt.hist(arr)
# obtain histogram data
plt.subplot(222)
hist, bin_edges = np.histogram(arr)
plt.plot(hist)
# fit histogram curve
plt.subplot(223)
sns.distplot(arr, kde=False, fit=stats.gamma, rug=True)
plt.show()
дёӢйқўд»Ӣз»ҚдҪҝз”Ёpythonз”ҹжҲҗcdfзҡ„ж–№жі•пјҡ
дҪҝз”Ёnumpyзҡ„ж•°жҚ®еӨ„зҗҶеҮҪж•°histogram()пјҢз”ҹжҲҗpdfеҲҶеёғж•°жҚ®пјҢиҝӣдёҖжӯҘз”ҹжҲҗcdfпјӣ
дҪҝз”Ёseabornзҡ„cumfreq()пјҢзӣҙжҺҘз”»еҮәcdfпјӣ
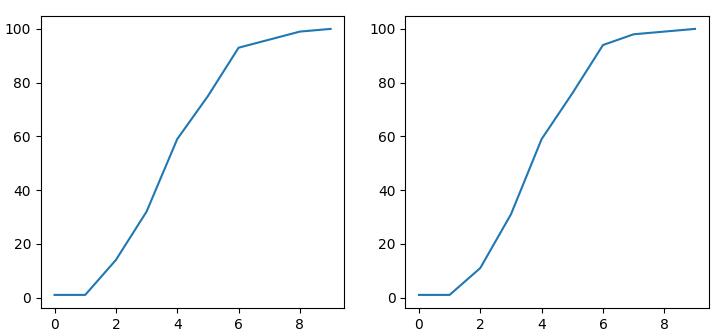
дёҠеӣҫжүҖзӨәдёәйҮҮз”Ё2з§Қз®—жі•з”ҹжҲҗзҡ„cdfеӣҫгҖӮдёӢйқўжҳҜжәҗд»Јз ҒгҖӮ
from scipy import stats
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
arr = np.random.normal(size=100)
plt.subplot(121)
hist, bin_edges = np.histogram(arr)
cdf = np.cumsum(hist)
plt.plot(cdf)
plt.subplot(122)
cdf = stats.cumfreq(arr)
plt.plot(cdf[0])
plt.show()
еңЁжӣҙеӨҡж—¶еҖҷпјҢйңҖиҰҒжҠҠpdfе’Ңcdfж”ҫеңЁдёҖиө·пјҢеҸҜд»ҘжӣҙеҘҪзҡ„жҳҫзӨәж•°жҚ®еҲҶеёғгҖӮиҝҷдёӘе®һзҺ°йңҖиҰҒжҠҠpdfе’ҢcdfеҲҶеҲ«иҝӣиЎҢеҪ’дёҖеҢ–гҖӮ
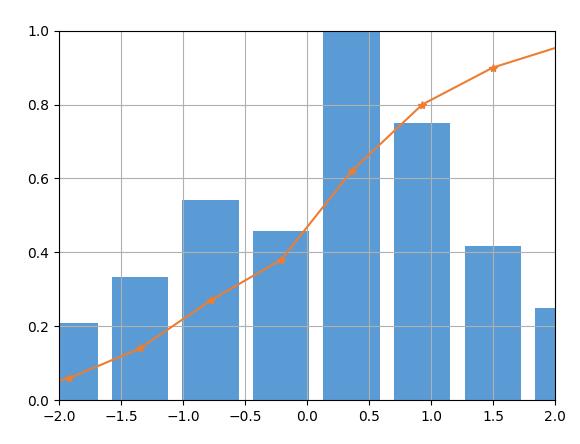
дёҠеӣҫжүҖзӨәдёәеҪ’дёҖеҢ–зҡ„pdfе’ҢcdfгҖӮдёӢйқўжҳҜжәҗд»Јз ҒгҖӮ
from scipy import stats
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
arr = np.random.normal(size=100)
hist, bin_edges = np.histogram(arr)
width = (bin_edges[1] - bin_edges[0]) * 0.8
plt.bar(bin_edges[1:], hist/max(hist), width=width, color='#5B9BD5')
cdf = np.cumsum(hist/sum(hist))
plt.plot(bin_edges[1:], cdf, '-*', color='#ED7D31')
plt.xlim([-2, 2])
plt.ylim([0, 1])
plt.grid()
plt.show()
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒе…ідәҺвҖңPythonеҰӮдҪ•еӨ„зҗҶPDFдёҺCDFвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢи®©еӨ§е®¶еҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°еҗ§пјҒ





