概述
本文主要介绍一种降维方法,PCA(Principal Component Analysis,主成分分析)。降维致力于解决三类问题。
1. 降维可以缓解维度灾难问题;
2. 降维可以在压缩数据的同时让信息损失最小化;
3. 理解几百个维度的数据结构很困难,两三个维度的数据通过可视化更容易理解。
PCA简介
在理解特征提取与处理时,涉及高维特征向量的问题往往容易陷入维度灾难。随着数据集维度的增加,算法学习需要的样本数量呈指数级增加。有些应用中,遇到这样的大数据是非常不利的,而且从大数据集中学习需要更多的内存和处理能力。另外,随着维度的增加,数据的稀疏性会越来越高。在高维向量空间中探索同样的数据集比在同样稀疏的数据集中探索更加困难。
主成分分析也称为卡尔胡宁-勒夫变换(Karhunen-Loeve Transform),是一种用于探索高维数据结构的技术。PCA通常用于高维数据集的探索与可视化。还可以用于数据压缩,数据预处理等。PCA可以把可能具有相关性的高维变量合成线性无关的低维变量,称为主成分( principal components)。新的低维数据集会尽可能的保留原始数据的变量。
PCA将数据投射到一个低维子空间实现降维。例如,二维数据集降维就是把点投射成一条线,数据集的每个样本都可以用一个值表示,不需要两个值。三维数据集可以降成二维,就是把变量映射成一个平面。一般情况下,nn维数据集可以通过映射降成kk维子空间,其中k≤nk≤n。
假如你是一本养花工具宣传册的摄影师,你正在拍摄一个水壶。水壶是三维的,但是照片是二维的,为了更全面的把水壶展示给客户,你需要从不同角度拍几张图片。下图是你从四个方向拍的照片:

第一张图里水壶的背面可以看到,但是看不到前面。第二张图是拍前面,可以看到壶嘴,这张图可以提供了第一张图缺失的信息,但是壶把看不到了。从第三张俯视图里无法看出壶的高度。第四张图是你真正想要的,水壶的高度,顶部,壶嘴和壶把都清晰可见。
PCA的设计理念与此类似,它可以将高维数据集映射到低维空间的同时,尽可能的保留更多变量。PCA旋转数据集与其主成分对齐,将最多的变量保留到第一主成分中。假设我们有下图所示的数据集:
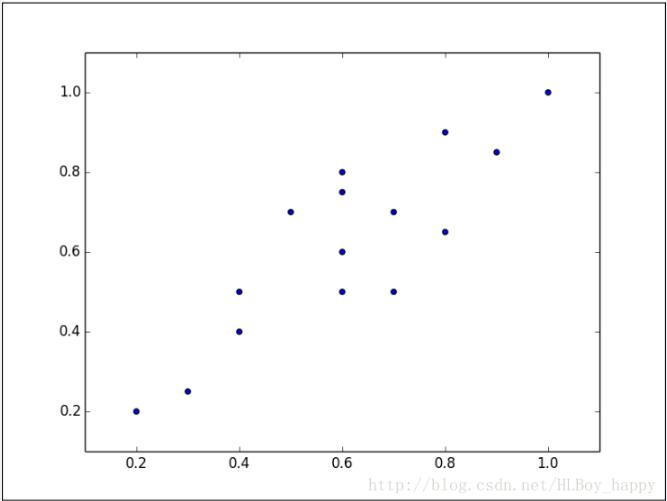
数据集看起来像一个从原点到右上角延伸的细长扁平的椭圆。要降低整个数据集的维度,我们必须把点映射成一条线。下图中的两条线都是数据集可以映射的,映射到哪条线样本变化最大?
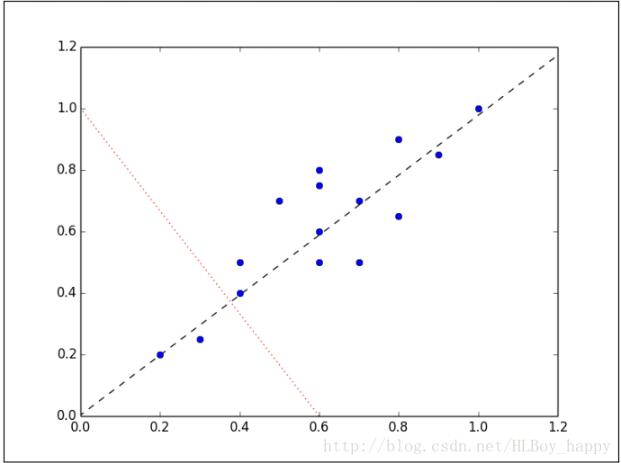
显然,样本映射到黑色虚线的变化比映射到红色点线的变化要大的多。实际上,这条黑色虚线就是第一主成分。第二主成分必须与第一主成分正交,也就是说第二主成分必须是在统计学上独立的,会出现在与第一主成分垂直的方向,如下图所示:
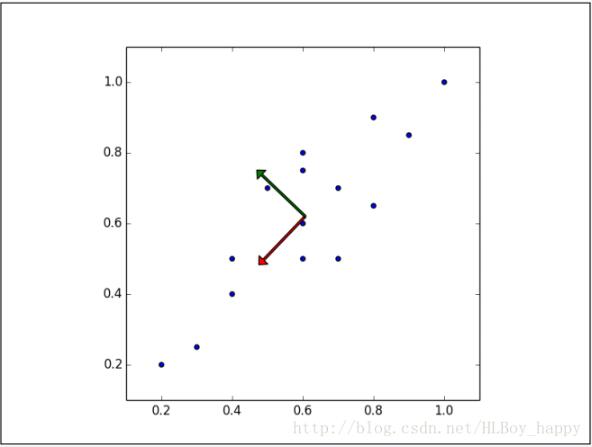
后面的每个主成分也会尽量多的保留剩下的变量,唯一的要求就是每一个主成分需要和前面的主成分正交。
现在假设数据集是三维的,散点图看起来像是沿着一个轴旋转的圆盘。
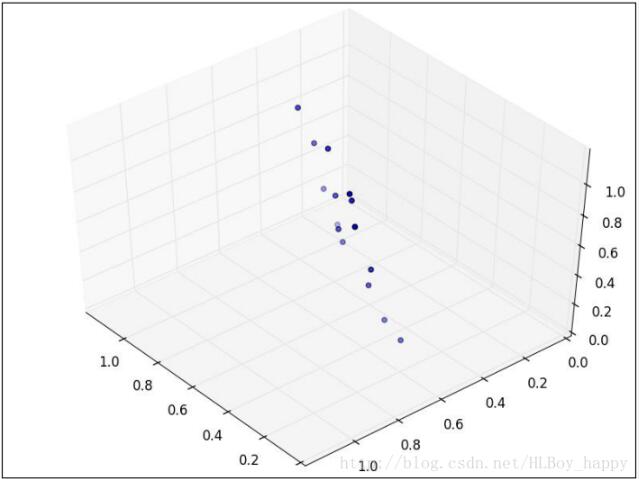
这些点可以通过旋转和变换使圆盘完全变成二维的。现在这些点看着像一个椭圆,第三维上基本没有变量,可以被忽略。
当数据集不同维度上的方差分布不均匀的时候,PCA最有用。(如果是一个球壳形数据集,PCA不能有效的发挥作用,因为各个方向上的方差都相等;没有丢失大量的信息维度一个都不能忽略)。
python实现PCA降维代码
# coding=utf-8
from sklearn.decomposition import PCA
from pandas.core.frame import DataFrame
import pandas as pd
import numpy as np
l=[]
with open('test.csv','r') as fd:
line= fd.readline()
while line:
if line =="":
continue
line = line.strip()
word = line.split(",")
l.append(word)
line= fd.readline()
data_l=DataFrame(l)
print (data_l)
dataMat = np.array(data_l)
pca_sk = PCA(n_components=2)
newMat = pca_sk.fit_transform(dataMat)
data1 = DataFrame(newMat)
data1.to_csv('test_PCA.csv',index=False,header=False)以上这篇python实现PCA降维的示例详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持亿速云。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



