目录:
(一)了解通配符和正则的作用
(二)通配符的使用
(三)正则表达式的使用
(四)扩展正则表达式的使用
(一)了解通配符和正则的作用
(1.1)在我们日常的工作中,我们都会使用到通配符或者正则表达式。通配符是一种特殊语句,主要有星号(*)和问号(?),用来模糊搜索文件。当查找文件夹时,可以使用它来代替一个或多个真正字符;当不知道真正字符或者懒得输入完整名字时,常常使用通配符代替一个或多个真正的字符。正则表达式是计算机科学的一个概念,正则表达式通常被用来检索、替换那些符合某个模式的文本,正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
(1.2)不管是通配符还是正则表达式,其功能都是实现模糊匹配,用来匹配某一类东西,并不是匹配具体的某一个值。通配符一般用于shell中,正则表达式一般用于其他语言。
(二)通配符的使用
(2.1)首先第一个是“[]”中括号[list],匹配的是list中的任意单一字符。例如a[xyz]b,a与b之间必须也只能有一个字符,但只能是x或y或z,如:axb,ayb,azb
(2.2)第二个是“[c1-c2]”,用来表示字符的范围,匹配c1-c2的任意单一字符,如[0-9]或[a-z]。例如“a[0-9]b”表示的是0到9之间必须也只能有一个字符,如:a0b、a1b、a2b、a3b、a4b、a5b、a6b、a7b、a8b、a9b
注意:如果我们需要匹配的是单个字母,且不分大小写,则我们可以使用“[a-zA-Z]”来进行表示。
(2.3)第三个是“[!c1-c2]或[^c1-c2]”,匹配的是不在c1-c2的任意字符。例如a[!0-9]b,a[^0-9]b表示a与b之间只有一个字符,并且不是数字0-9之间的字符,符合要求的有:acb、adb
(2.4)示例:我们在vms002主机上创建一个rh224目录,然后在rh224目录中创建相关的文件:11111、a111、a_111、a22、lwang、lWang、rh224。接着我们查询第一个字符时a到z之间的,第二个字符是非数字的,后面的字符都是任意的。
# mkdir rh224
# touch 11111 a111 a_111 a22 lwang lWang rh224
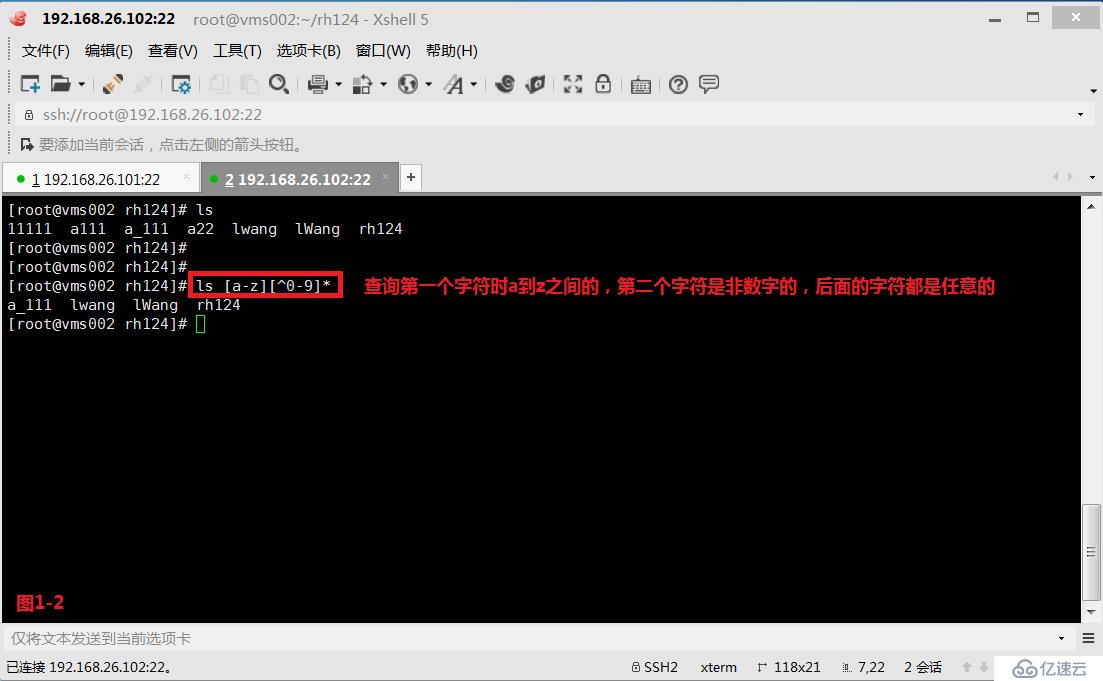
# ls [a-z][^0-9]*---查询第一个字符时a到z之间的,第二个字符是非数字的,后面的字符都是任意的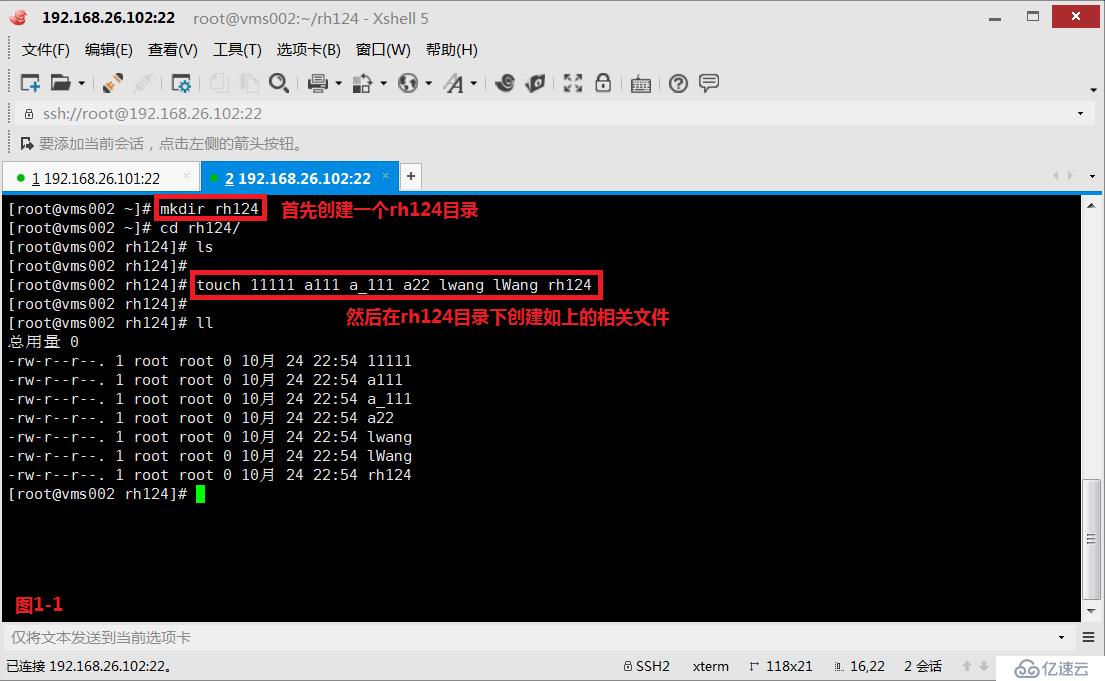
(2.5)示例:接着我们的需求是在rh224目录下找到格式为第一个字符是a到z之间,第二个字符是a或者“-”或者z三个字符中的任意一个,后面的字符是任意的。这样我们就可以符合要求的文件名a-1
# touch a-1
# ls [a-z][a-z]*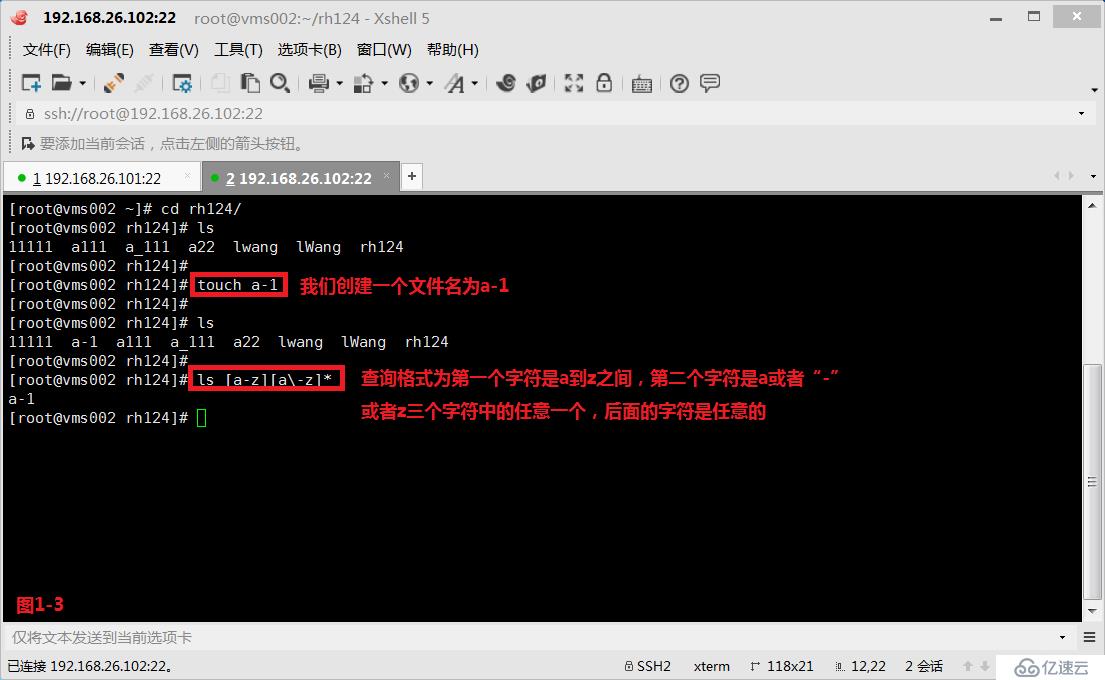
(2.6)第四个是精确指定字符的大小写“[[:upper:]]”、“[[:lower:]]”,由于我们使用[a-z]的时候可能会匹配出a到z和A到Z之间的字符,大小写并不能精确匹配,所以我们可以使用“[[:upper:]]”表示纯大写的字符,我们可以使用“[[:lower:]]”表示纯小写的字符。
# ls [[:upper:]]*---查询所有纯大写字目开头的文件名
# ls [[:lower:]]*---查询所有纯小写字母开头的文件名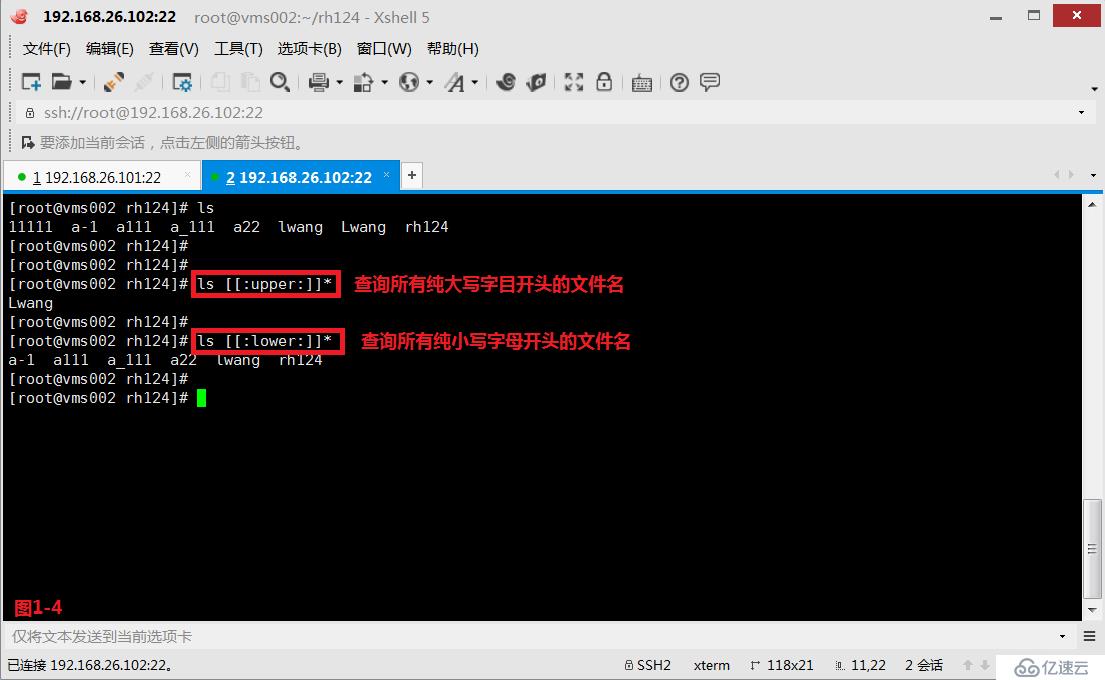
(2.7)当然第四个精确指定字符中还是有其他表示特定字符的方式的:“[[:alpha:]]”表示的是只匹配字母,“[[:alnum:]]”表示的是匹配字母和数字,“[[:digit:]]”表示的是匹配纯数字。
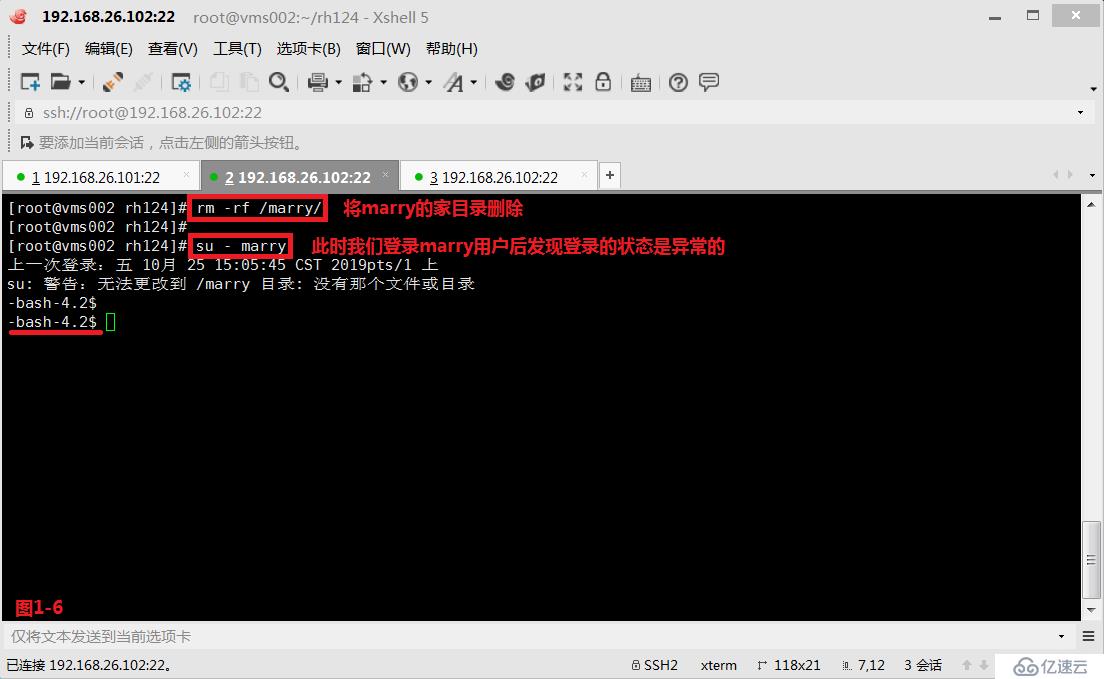
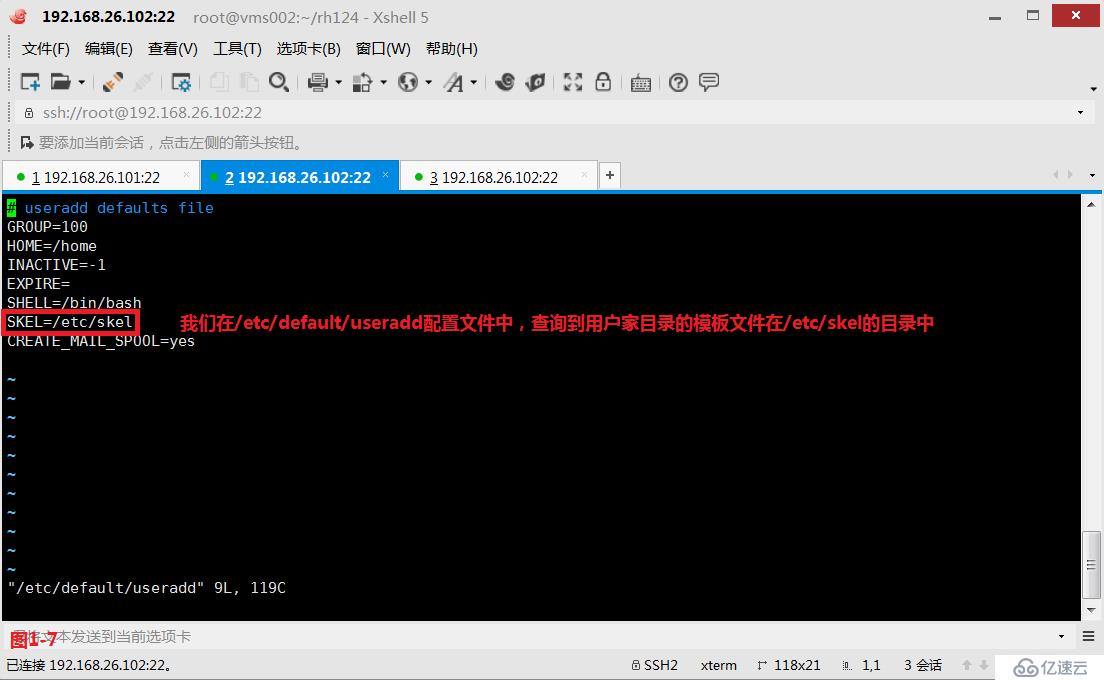
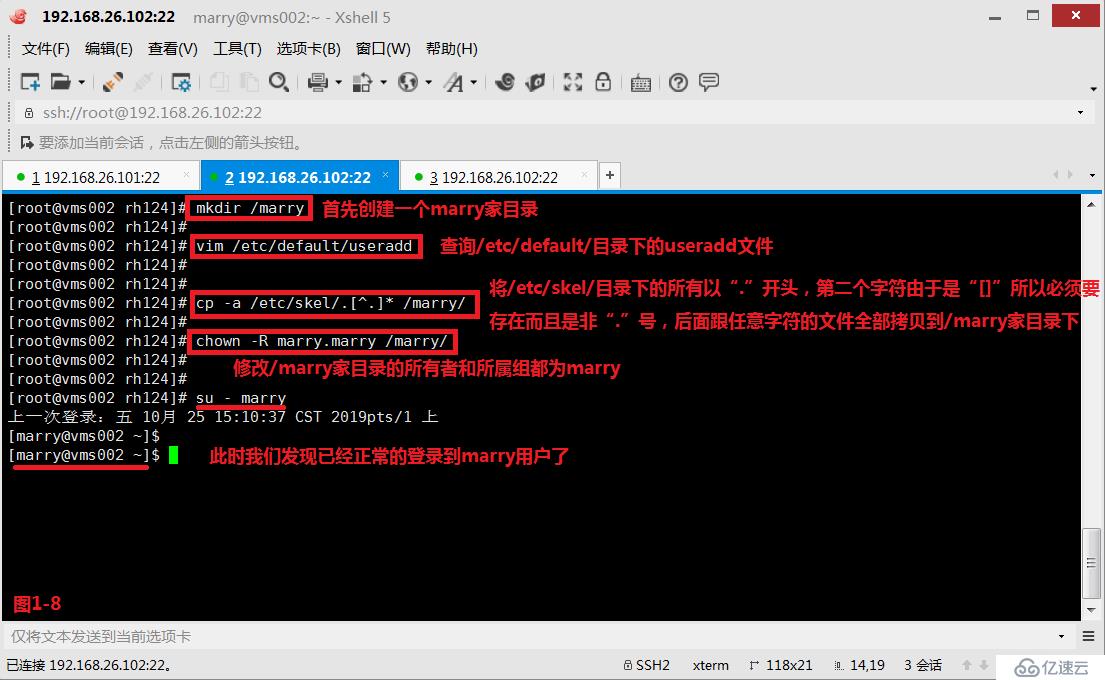
(2.8)示例:现在我们的系统中没有marry用户,我们首先创建一个marry用户,并且指定在根下创建marry的家目录(图1-5)。然后我们将marry家目录删除,此时我们切换到marry用户后发现由于没有家目录,所以切换后是异常的状态(图1-6),此时我们在/etc/default/useradd配置文件中,查询到用户家目录的模板文件在/etc/skel的目录中(图1-7),我们将/etc/skel中的所有模板文件都拷贝到marry家目录下,并修改了属主和属组的相关信息,此时便可以正常的进行marry用户的切换了(图1-8)。
# useradd -d /marry marry---创建一个marry用户,并且指定在根下创建marry的家目录
# rm -rf /marry/---删除marry的家目录
# vim /etc/default/useradd---查询/etc/default/目录下的useradd文件
# cp -a /etc/skel/.[^.]* /marry/---将/etc/skel/目录下的所有以“.”开头,第二个字符由于是“[]”所以必须要存在而且是非“.”号,后面跟任意字符的文件全部拷贝到/marry家目录下,skel表示骨架、框架(图1-8)
# chown -R marry.marry /marry/---修改/marry家目录的所有者和所属组都为marry(图1-8)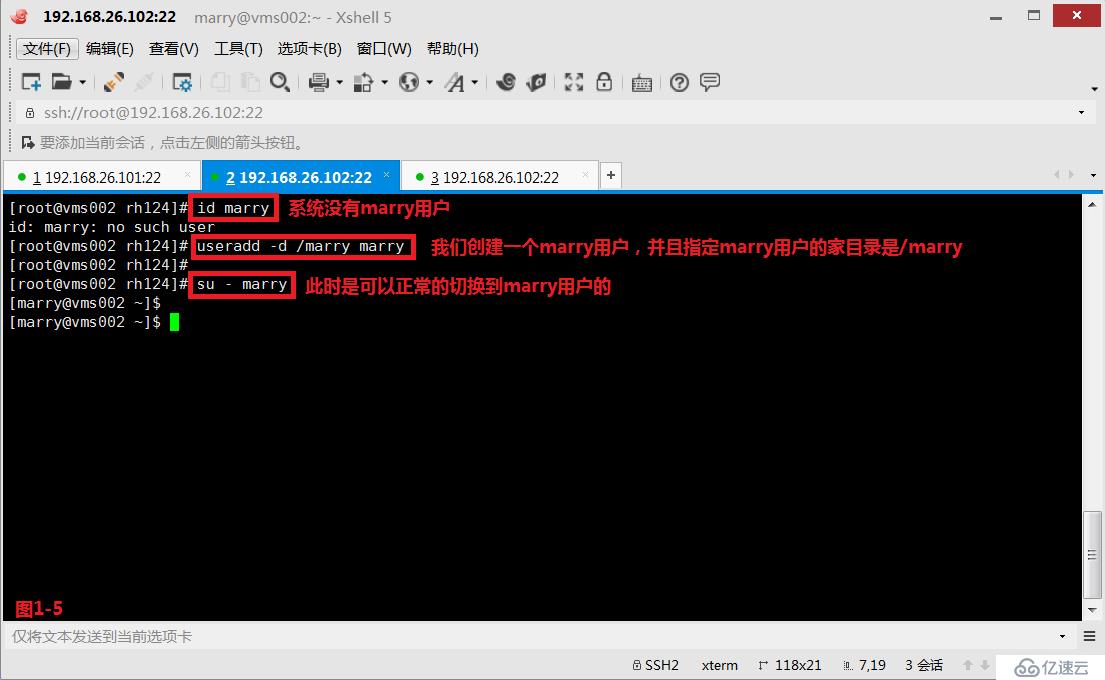
(2.9)第五个是“?”问号,匹配的是任意一个字符。例如在rh224目录中,我们查询“[a-z]????”,表示的是查询第一个字符是字母构成,后面会有四个任意的字符构成的文件名。
注意:“?”问号是不能匹配到表示隐藏文件的“.”点号的。即表示如果现在系统中有“.aa”文件,我们使用“???”是不能匹配出这个隐藏文件的,如果我们想要匹配出这类隐藏文件则应该开启全局通配符处理。
# ls [a-z]????---查询第一个字符是字母构成,后面会有四个任意的字符构成的文件名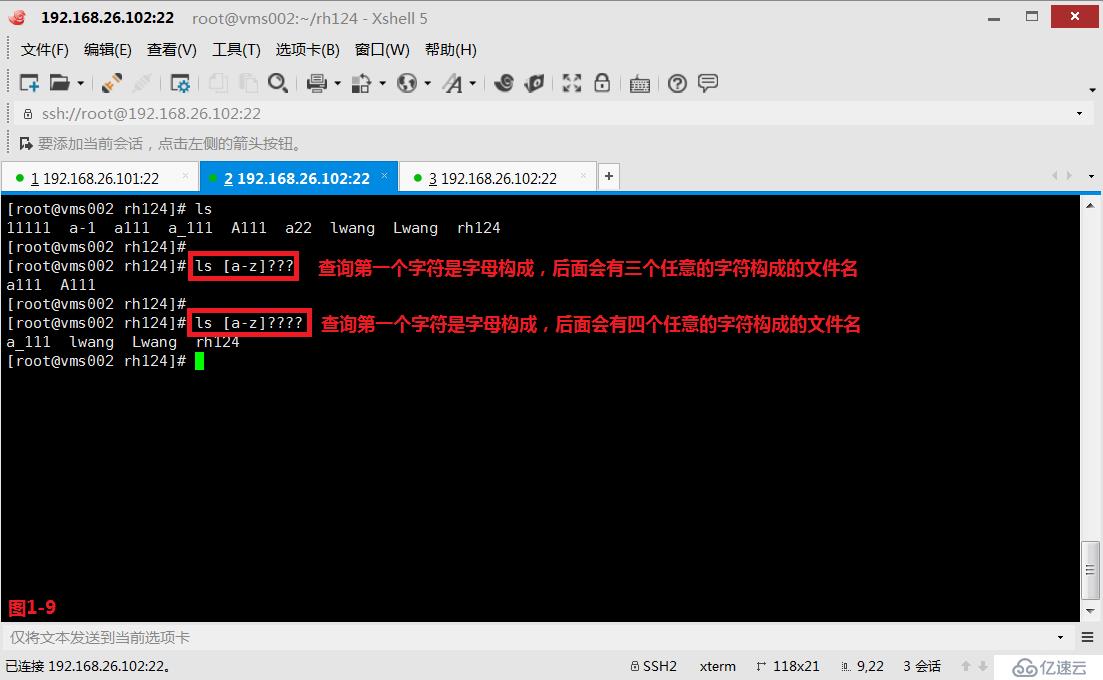
(2.10)第六个是“*”星号,表示匹配任意长度的任意字符。例如我们将所有文件名以a字母开头,且后面是任意字符的文件都删除掉
# touch aaa bb cc aa2---创建如下的四个文件
# rm -rf a*---将所有文件名以a字母开头,后面是任意字符的文件都删除掉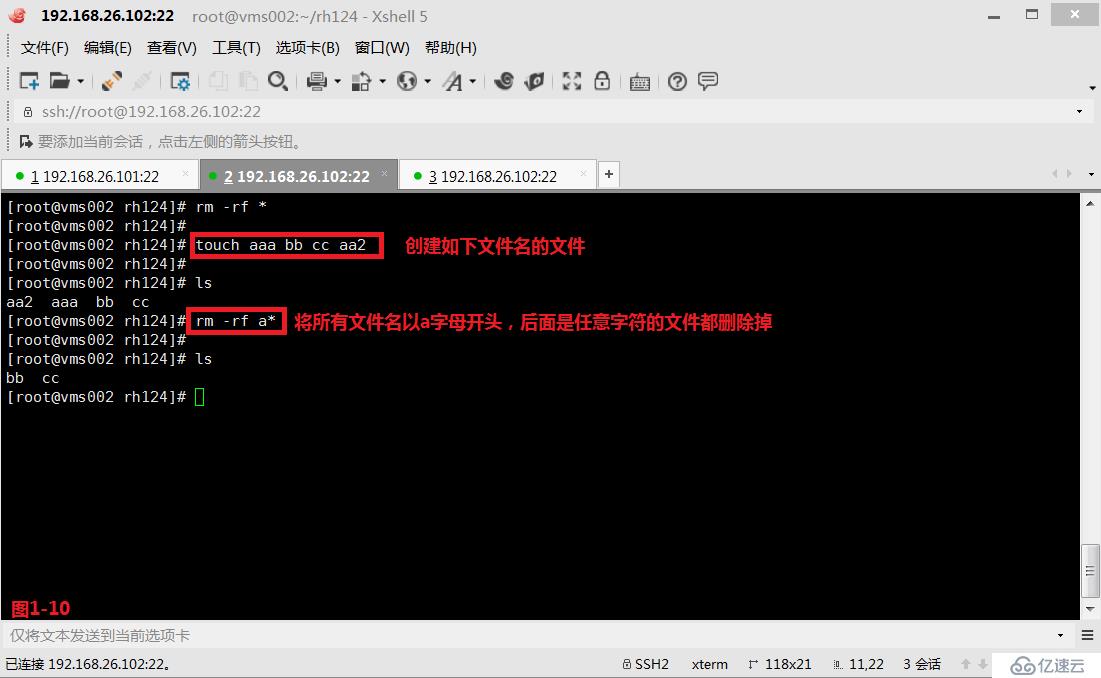
(2.11)第七个是“\”反斜线,表示转义符,有时候我们在当前系统中安装vsftp软件的时候我们可能会使用“# yum install vsftp*”进行安装,但是由于我们在执行系统命令的时候,首先是在shell进程中运行然后才到达YUM仓库中去进行相关的软件包查找工作。即我们在执行“vsftp*”的时候,shell会首先对“vsftp*”进行shell解析,查找当前目录中是否有符合“vsftp*”格式的文件,如果现在我们的当前目录中存在着一个文件vsftp123,则此时shell会将“vsftp*”解析成“vsftp123”,然后再到YUM仓库中去查找“vsftp123”的软件包进行安装,而这样的情况并不是我们所希望的。所以我们在shell中执行安装软件包的命令时,一般是建议使用转义符“# yum install vsftp\*”这样的格式进行安装是比较好的,这样就可以防止shell对我们所使用的通配符进行解析的情况产生。
# yum install vsftp\*---使用转义符对通配符进行转义,防止shell对通配符进行解析
# yum install 'vsftp*'---也可以使用单引号来进行转义,防止shell对通配符进行解析
(2.12)需要注意的是,我们在创建文件的时候,文件名是不可能包含“/”的,因为有“/”就是代表创建了一个目录。
# touch rh224/cc---此时“rh224/cc”并不是表示一个文件名,而是表示在rh224/目录下创建一个cc文件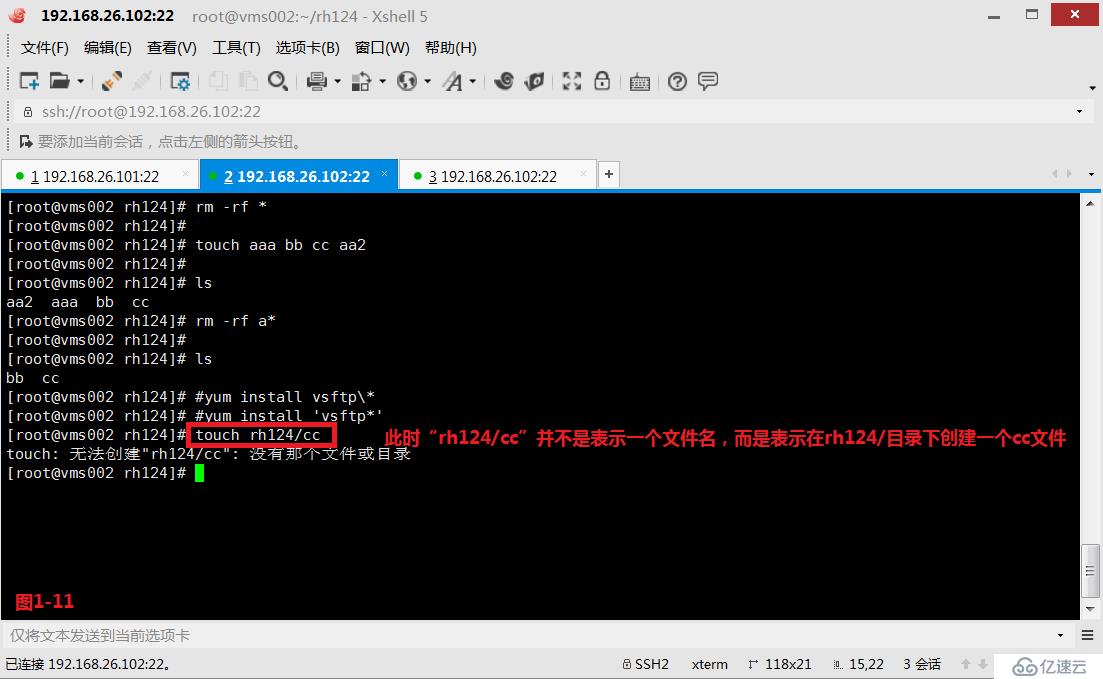
(三)正则表达式的使用
(3.1)正则表达式是用来匹配字符串的,针对文件内容的文本过滤工具,大都用到正则表达式,如vim、grep、awk、sed等。正则表达式和我们上面说的通配符实现的效果都是一样的,是为了实现查询信息的模糊匹配。
(3.2)第一个“^”表示开头,例如我们先将/etc/passwd文件拷贝到当前目录中,然后查询passwd文件中以root字符开头的行,此时可以使用“^”来进行标识。
# grep ^root passwd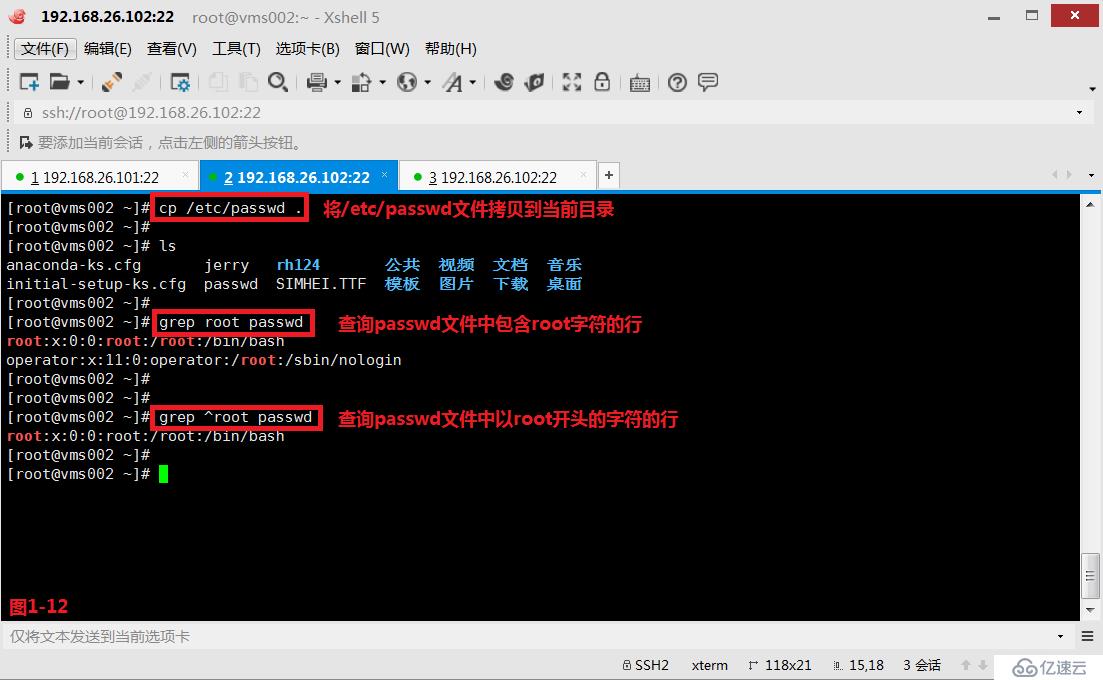
(3.3)第二个“$”表示行末,我们先将passwd文件中的相关行进行设计一下,然后查找每一行行末是“bash”字符的行。
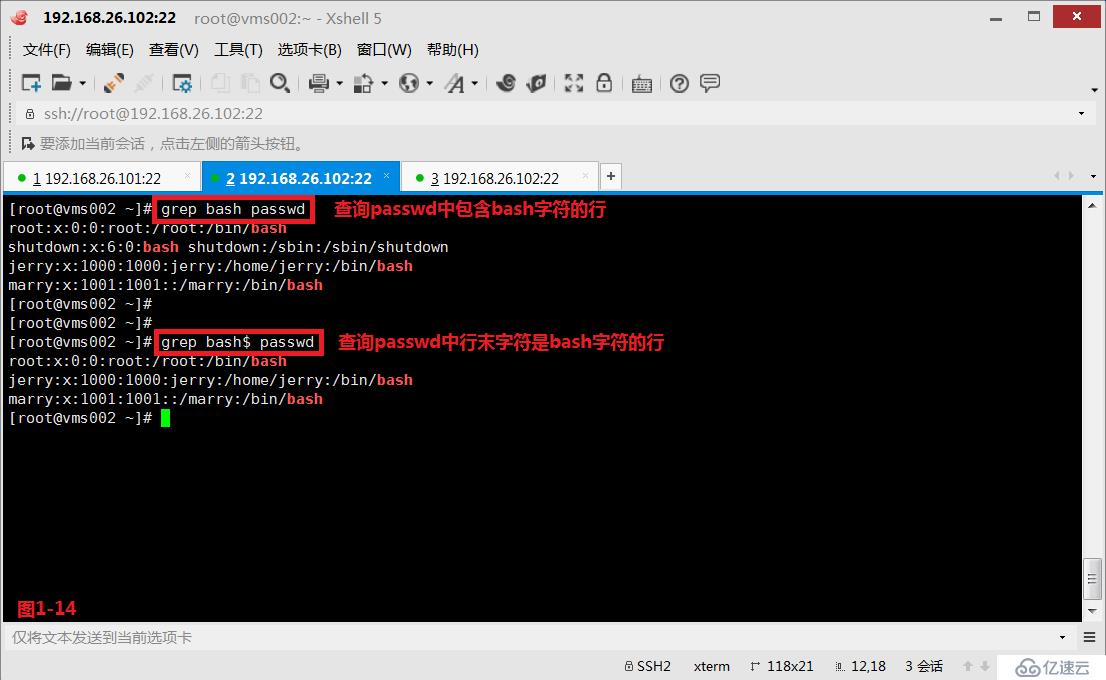
# grep bash$ passwd---查询行末字符是bash字符的所有行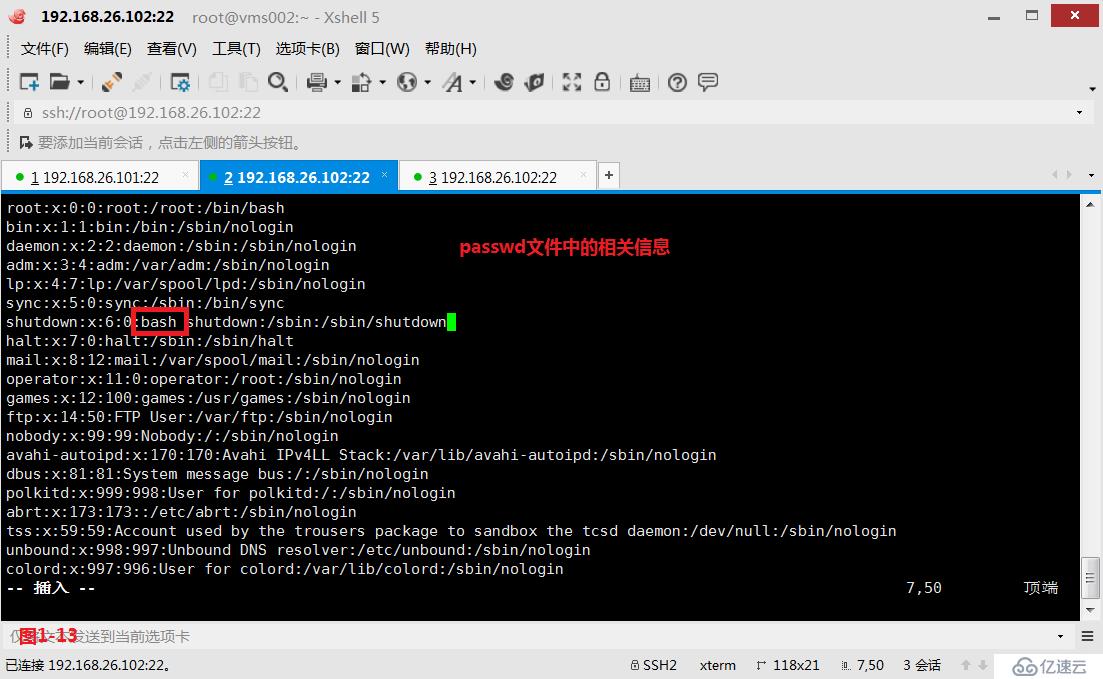
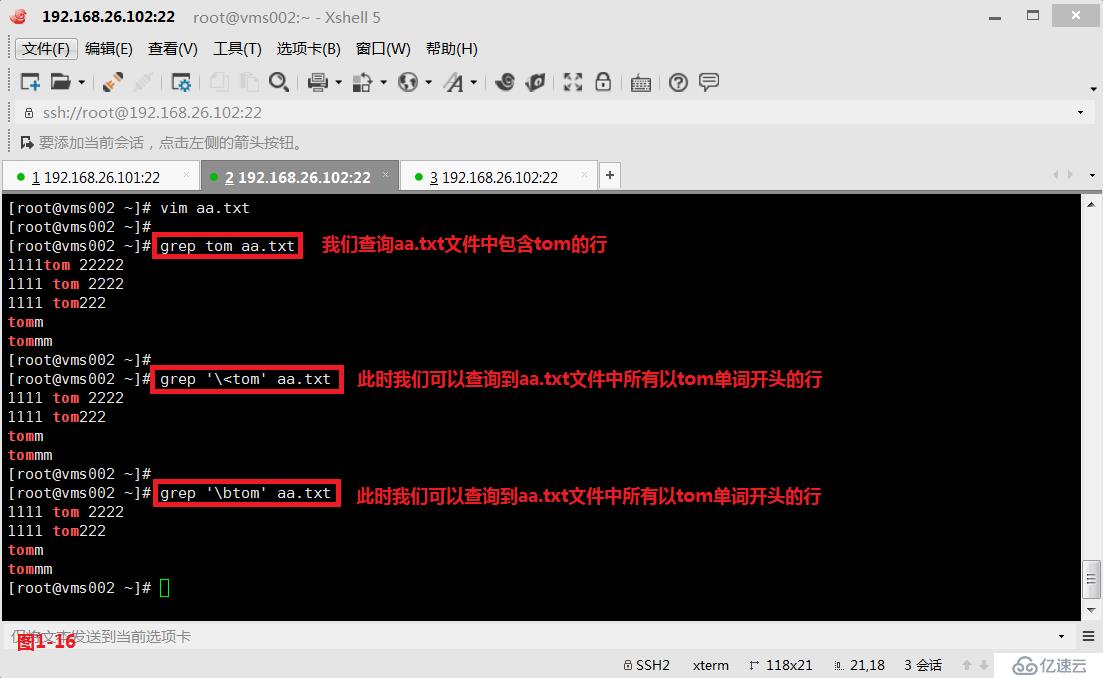
(3.4)第三个“\<”或者“\b”表示锚定的是单词的开头,我们先来创建一个aa.txt的文件,然后我们查询“\<tom”以tom字符开头的所有行。
# grep '\<tom' aa.txt---查询以tom字符开头的所有行
# grep '\btom' aa.txt---查询以tom字符开头的所有行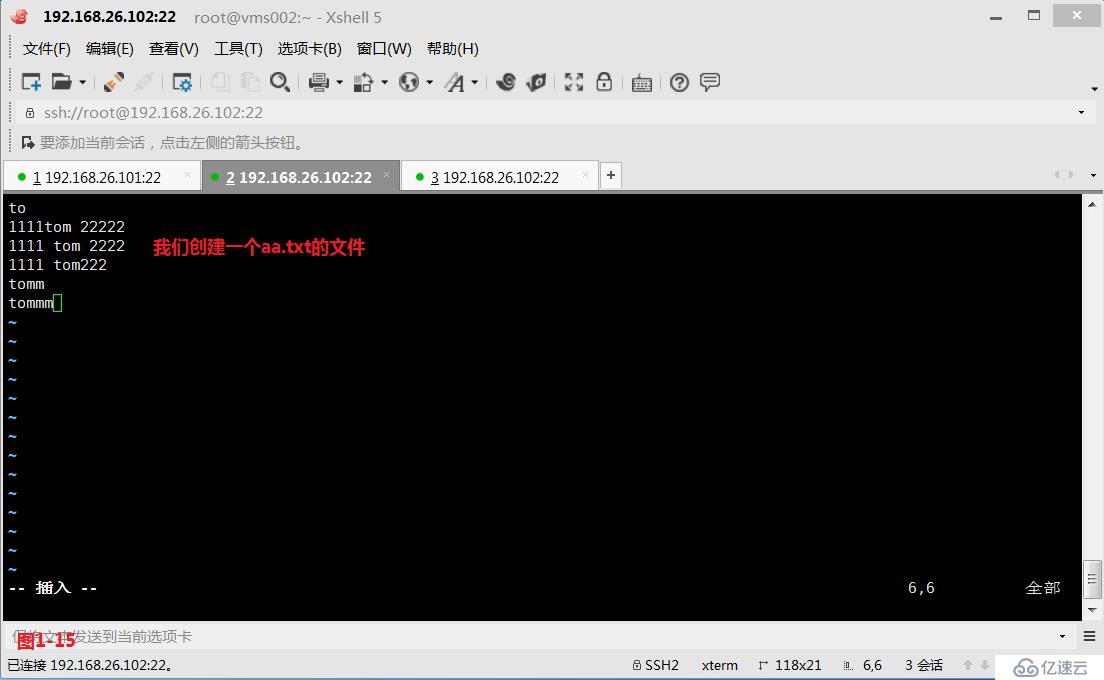
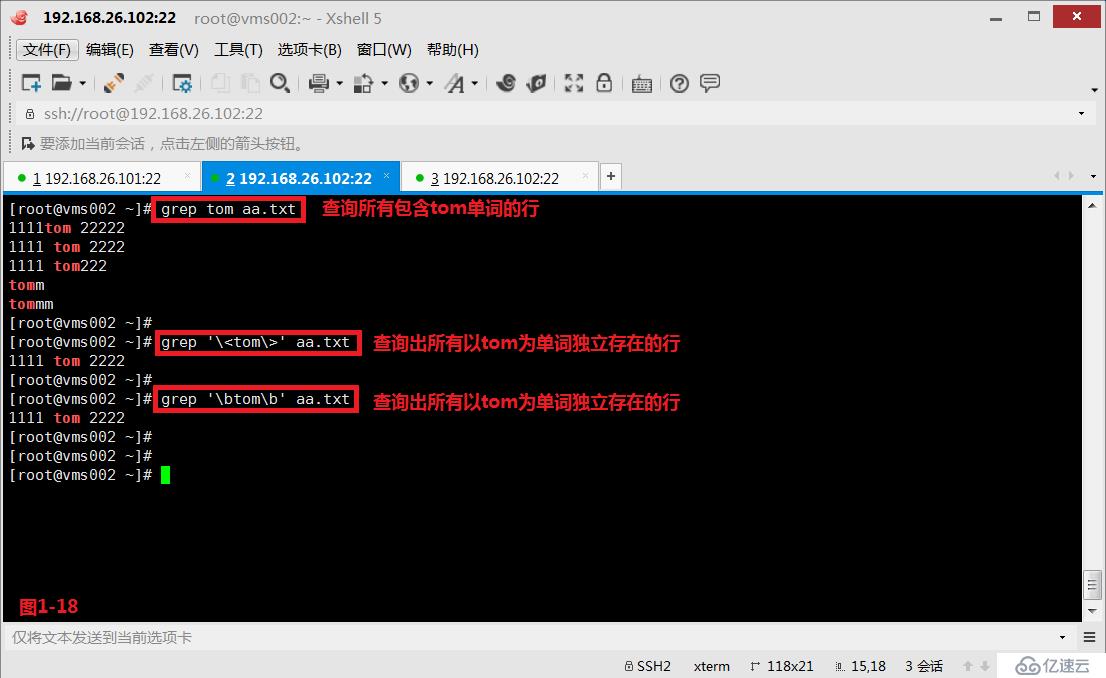
(3.5)第四个“\>”或者“\b”表示锚定的是单词的末尾,在aa.txt文件中,我们查询“tom\>”以tom字符结束的所有行(图1-17)。如果我们希望查询出所有以tom为单词独立存在的行时,我们可以同时使用“\<”和“\>”符号(图1-18)。
# grep 'tom\>' aa.txt---查询“tom\>”以tom字符结束的所有行
# grep 'tom\b' aa.txt---查询“tom\b”以tom字符结束的所有行
# grep '\<tom\>' aa.txt---查询出所有以tom为单词独立存在的行
# grep '\btom\b' aa.txt ---查询出所有以tom为单词独立存在的行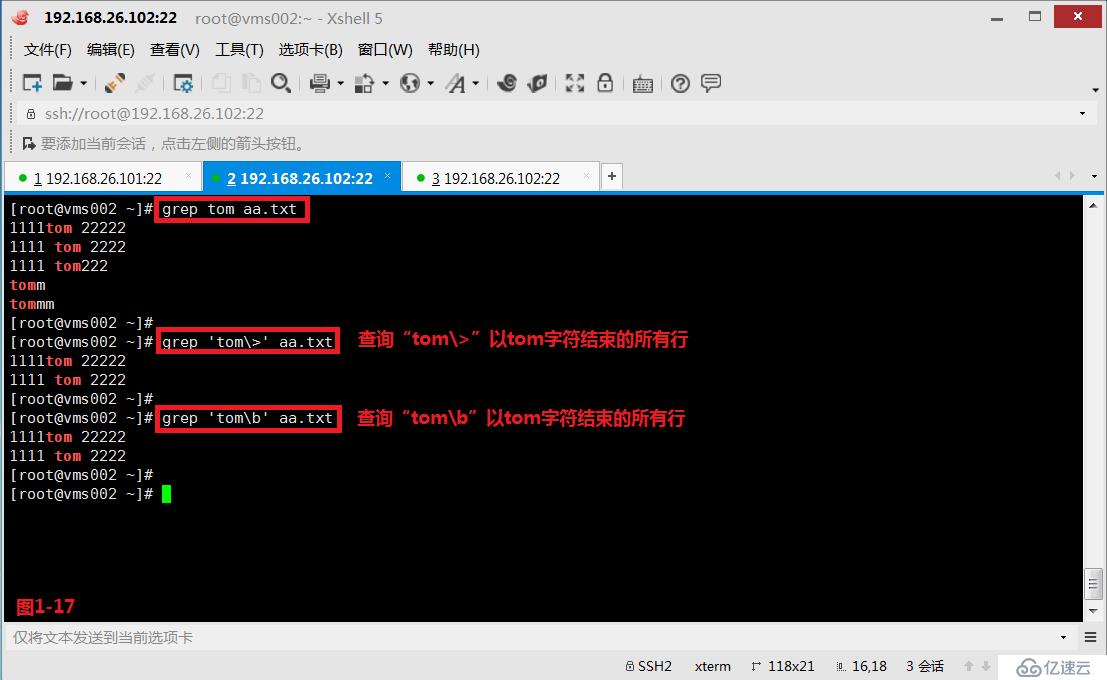
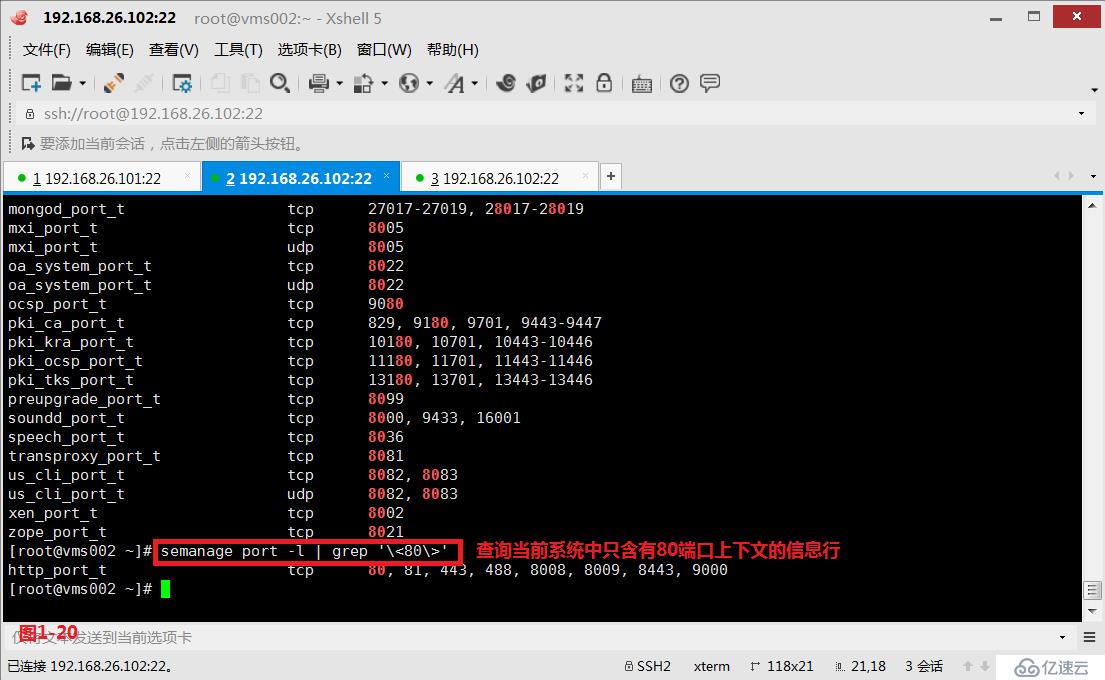
(3.6)示例:现在我们希望查询SELinux中对端口设置的上下文信息,如果需要过滤具体的端口号的信息,则可以使用“\<\>”来指定独立的单词信息,例如过滤出只包含80端口上下文的行,如果我们只是使用“grep 80”过滤出的信息是不正确的(图1-19),我们应该使用“grep '\<80\>'”才是正确的(图1-20)。
# semanage port -l | grep 80---查询当前系统中所有包含80端口上下文的信息
# semanage port -l | grep '\<80\>'---查询当前系统中只含有80端口上下文的信息行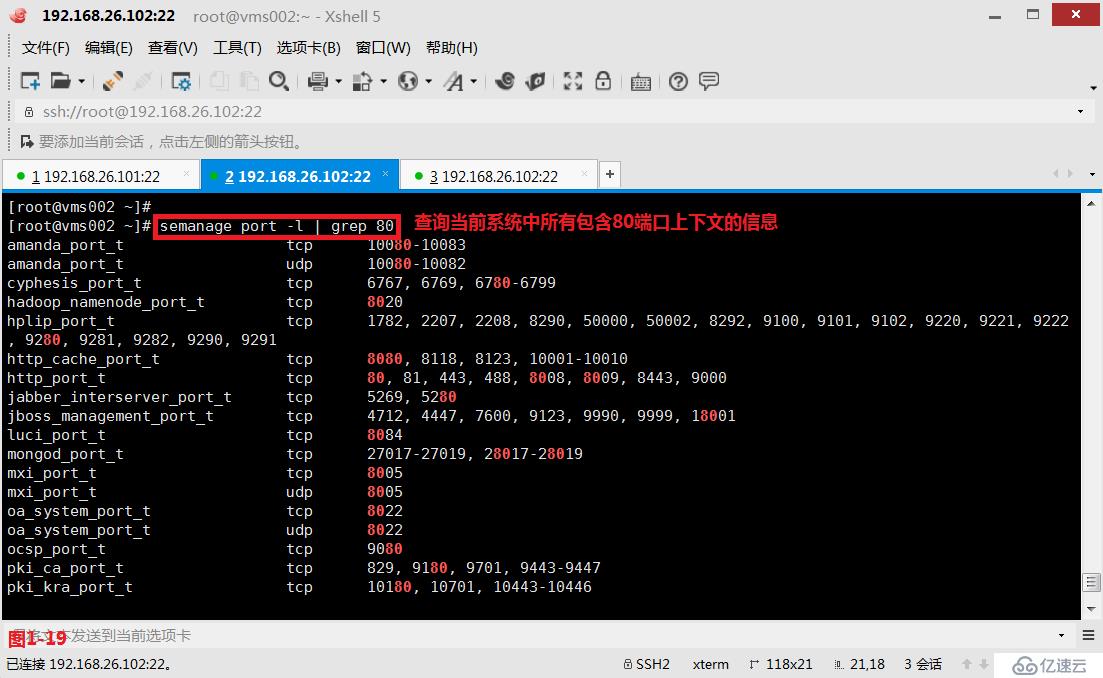
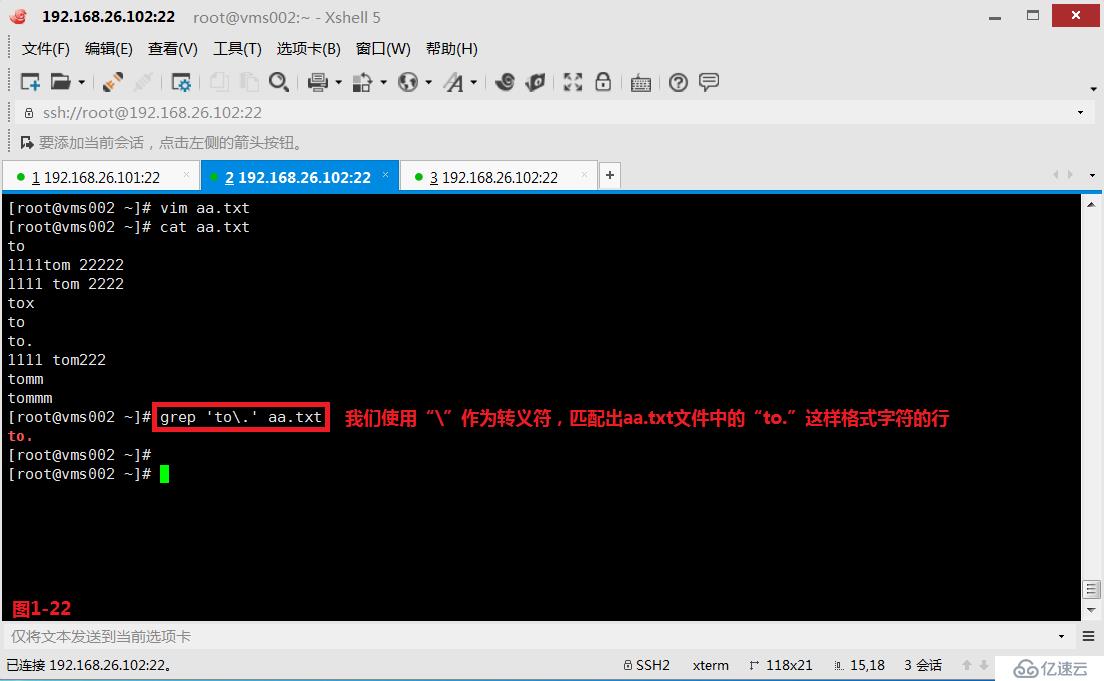
(3.7)第五个“.”表示单个任意字符,和通配符中的“?”问号的意义一致。例如我们想要匹配出aa.txt文件中to单词后跟任意一个字符的所有符合要求的行(图1-21)。如果我们希望“.”符号没有模糊查询的意思,就代表它本身的字符的意思,则我们可以使用“\”作为转义符,这样就可以直接查询出包含“to.”字样的行(图1-22)。
# grep 'to.' aa.txt---查询出所有符合to单词后还会跟一个任意字符的行
# grep 'to\.' aa.txt---使用转义符,直接查询包含“to.”字符的行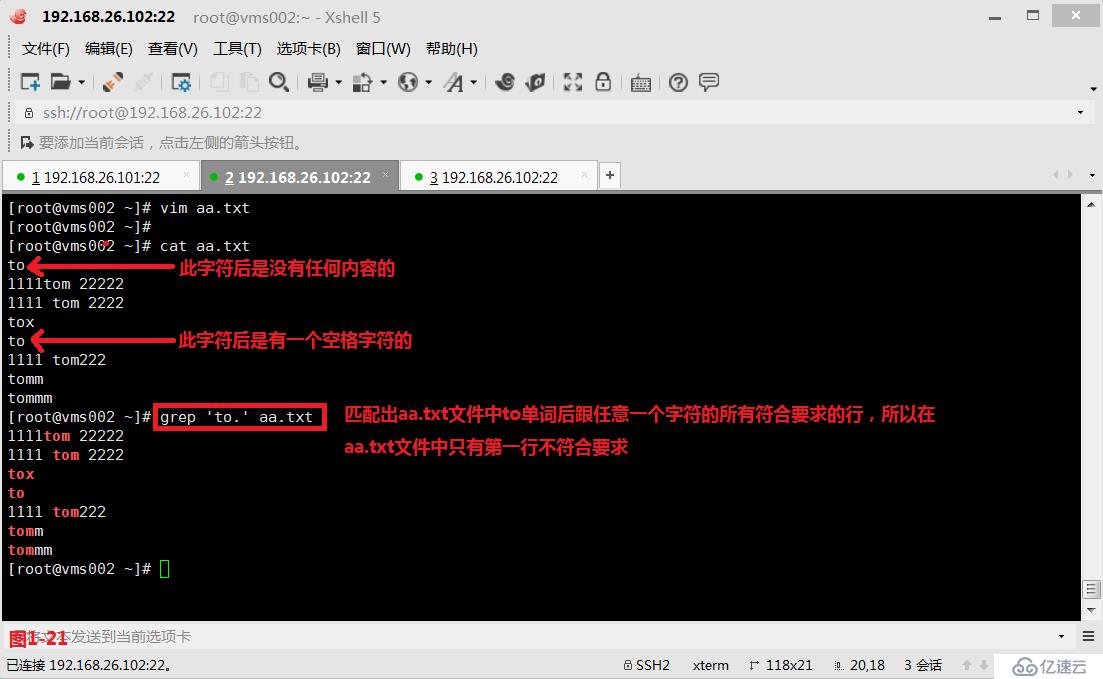
(3.8)第六个“[]”,表示的是匹配指定范围内的任意单个字符。
(3.9)第七个“[^]”,表示的是匹配指定范围外的任意单个字符。
(3.10)分组概念
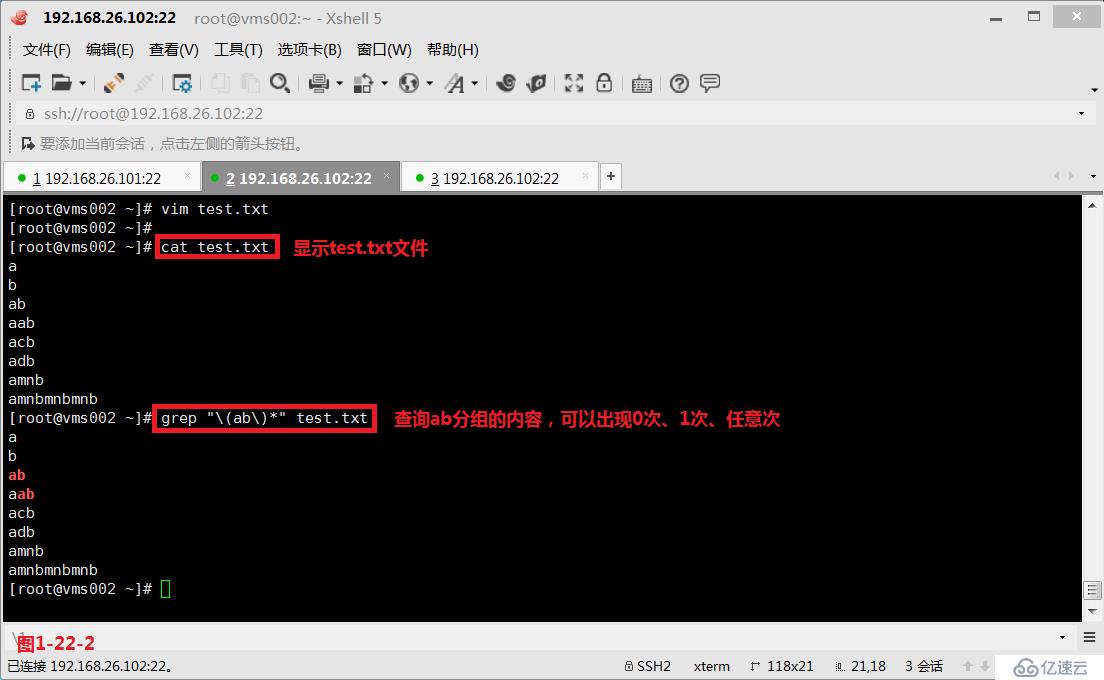
(3.10.1)第八个“\(\)”,表示的是分组。例如“\(ab\)*”表示ab单词可以出现0次、1次或任意次。我们创建一个test.txt文件(图1-22-1),然后我们使用“\(ab\)*”将符合条件的都筛选出来(图1-22-2)。
# grep "(ab)*" test.txt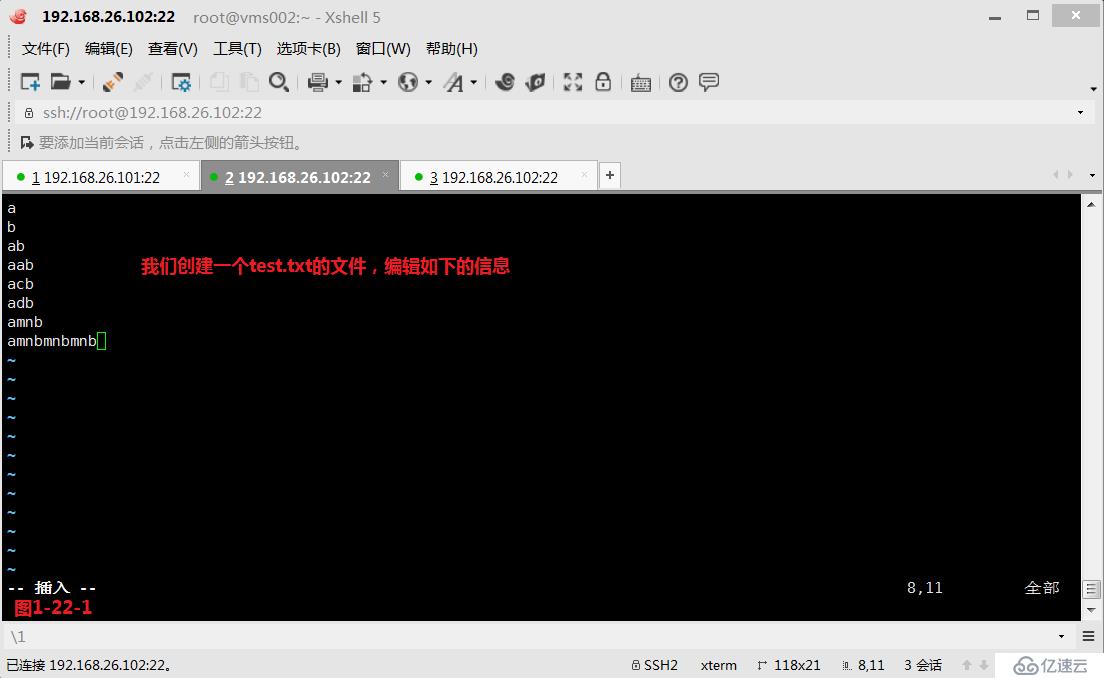
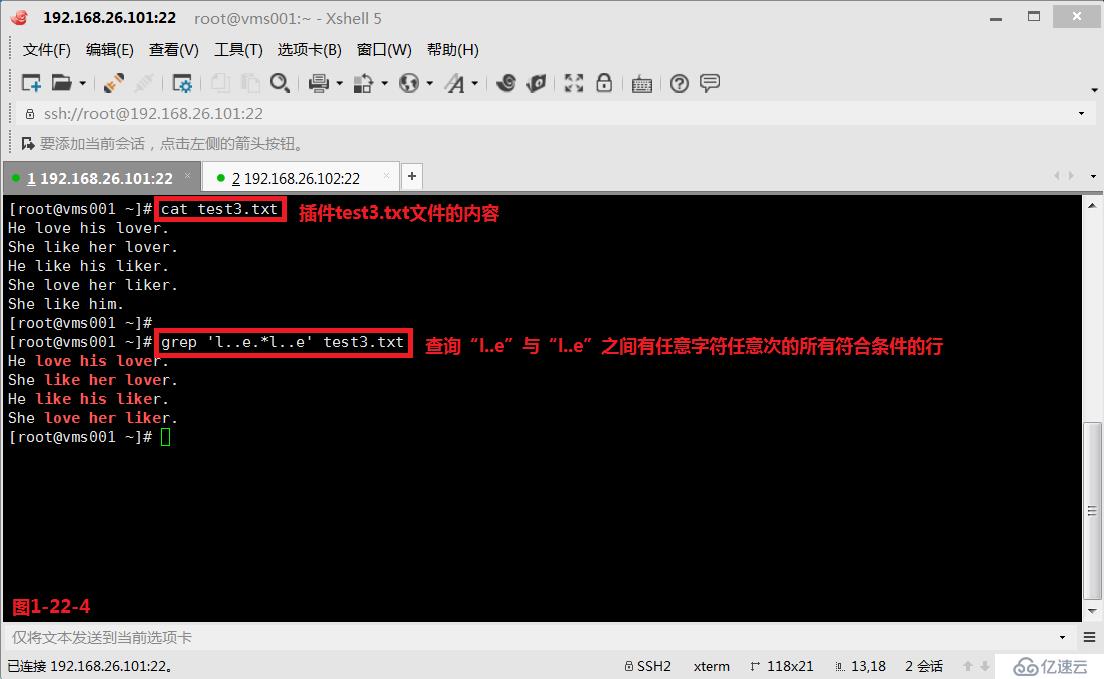
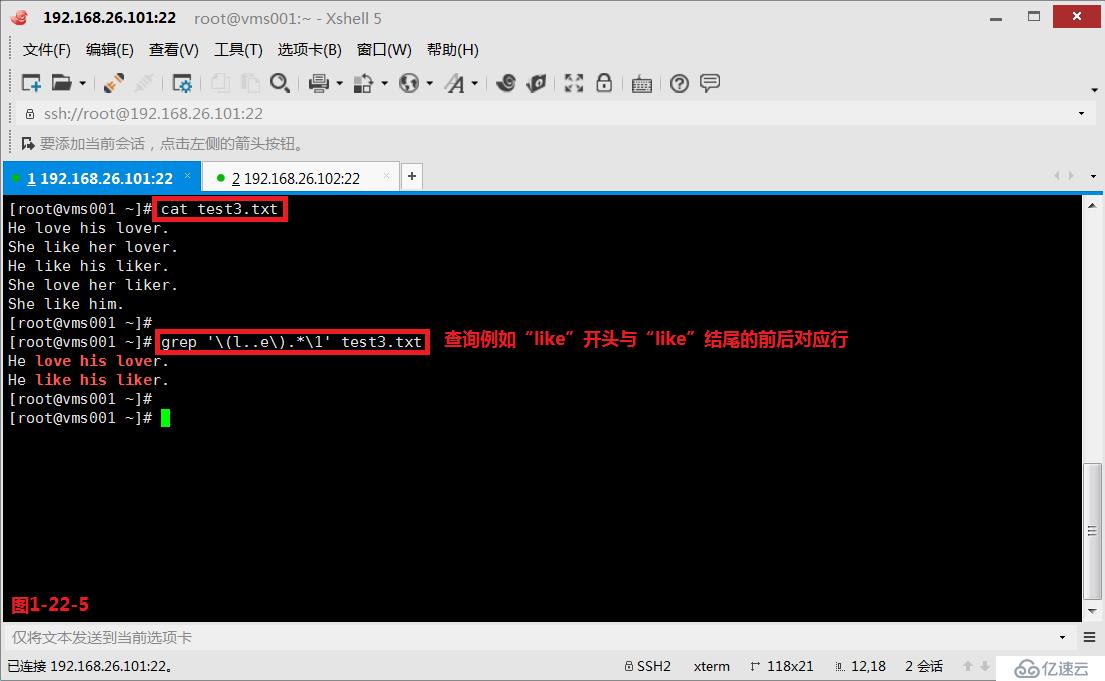
(3.10.2)我们创建一个文件test3.txt,然后编辑如下的内容,我们查询“l..e”与“l..e”之间有任意字符任意次的所有符合条件的行,此时我们发现test3.txt文件中的第1行至第4行的内容都被筛选出来了(图1-22-4)。此时我们如果希望出现的行中前后两个字符是完全一致的才符合要求并显示,即test3.txt文件中的第1行和第3行显示出来,此时我们需要使用后项引用的方式来完成要求(图1-22-5)。
分组:\(\)
后项引用:
\1:引用第一个左括号以及与之对应的右括号所包括的所有内容
\2:引用第二个左括号以及与之对应的右括号所包括的所有内容
\3:引用第三个左括号以及与之对应的右括号所包括的所有内容
# grep 'l..e.*l..e' test3.txt---查询“l..e”与“l..e”之间有任意字符任意次的所有符合条件的行
# grep '\(l..e\).*\1' test3.txt---查询例如“like”开头与“like”结尾的前后对应行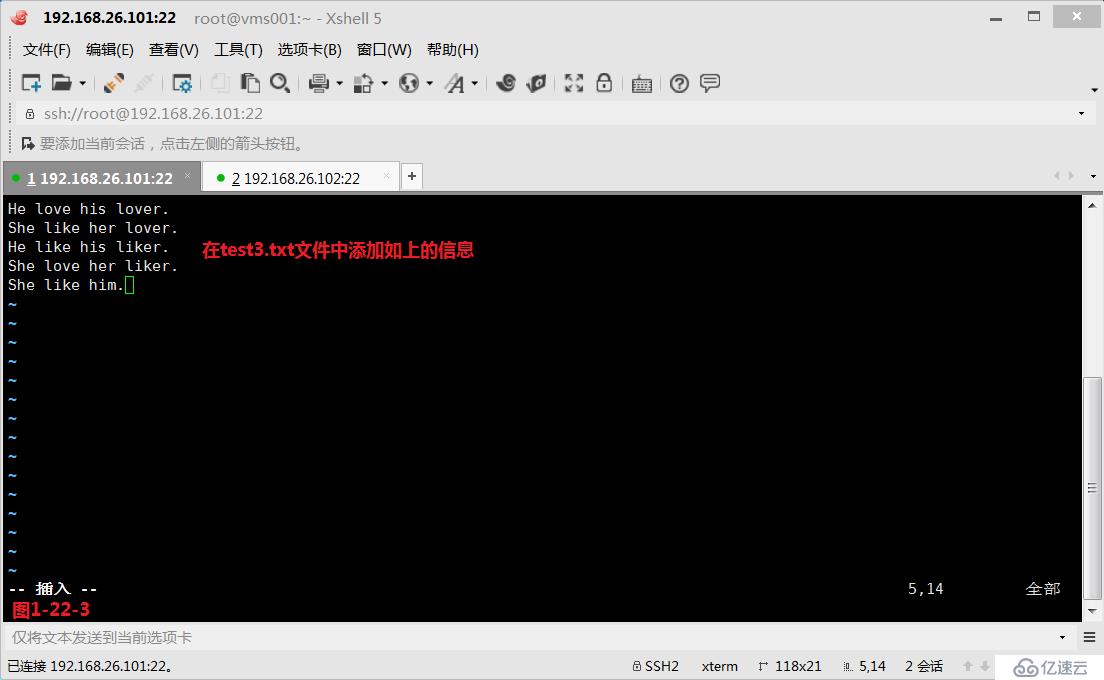
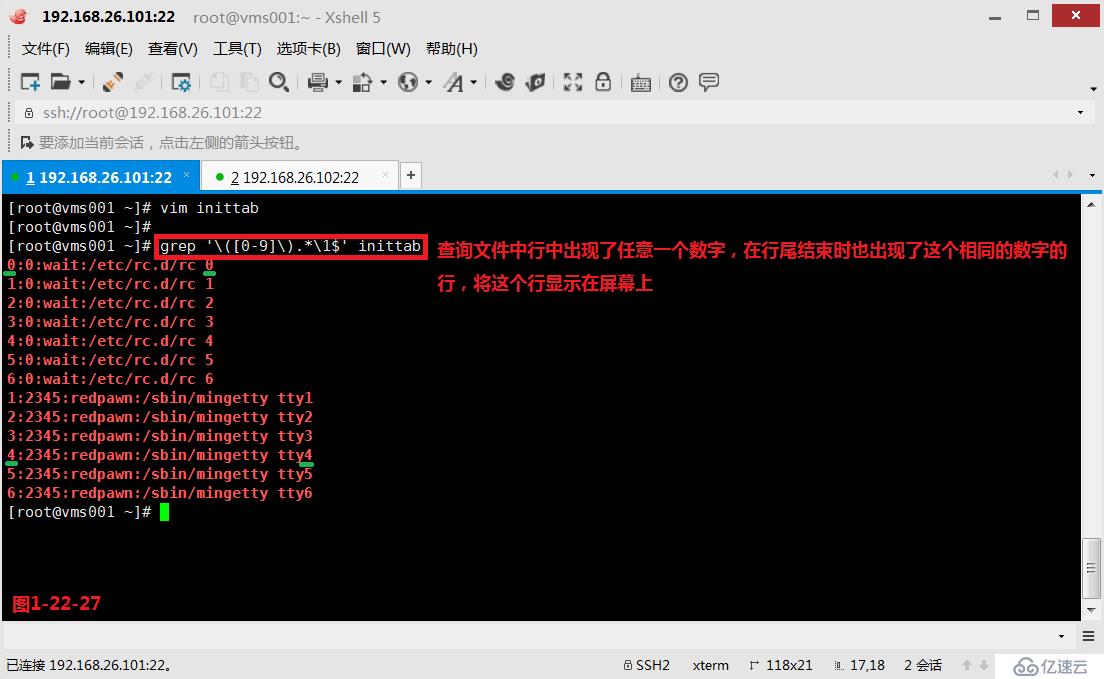
(3.10.3)示例:我们在当前目录下创建一个inittab的文件,然后我们查询文件中行中出现了任意一个数字,在行尾结束时也出现了这个相同的数字的行,将这个行显示在屏幕上。
# grep '\([0-9]\).*\1$' inittab---其中“\([0-9]\)”表示行中出现的任意一个数字,“\1$”表示在行尾结束时也出现了这个相同的数字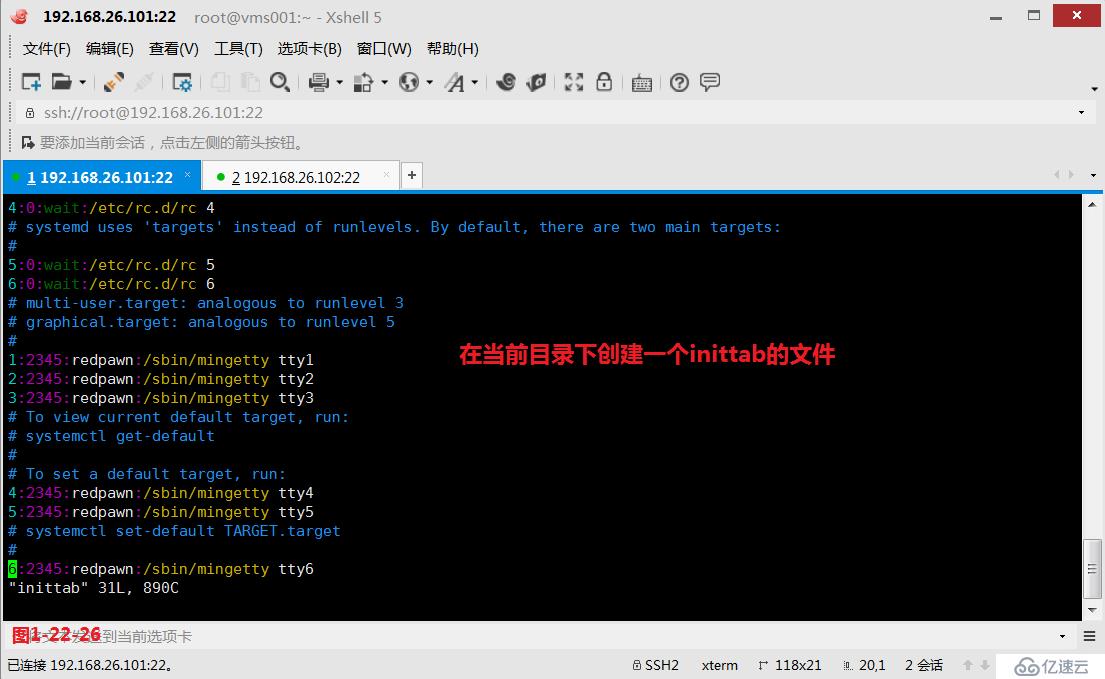
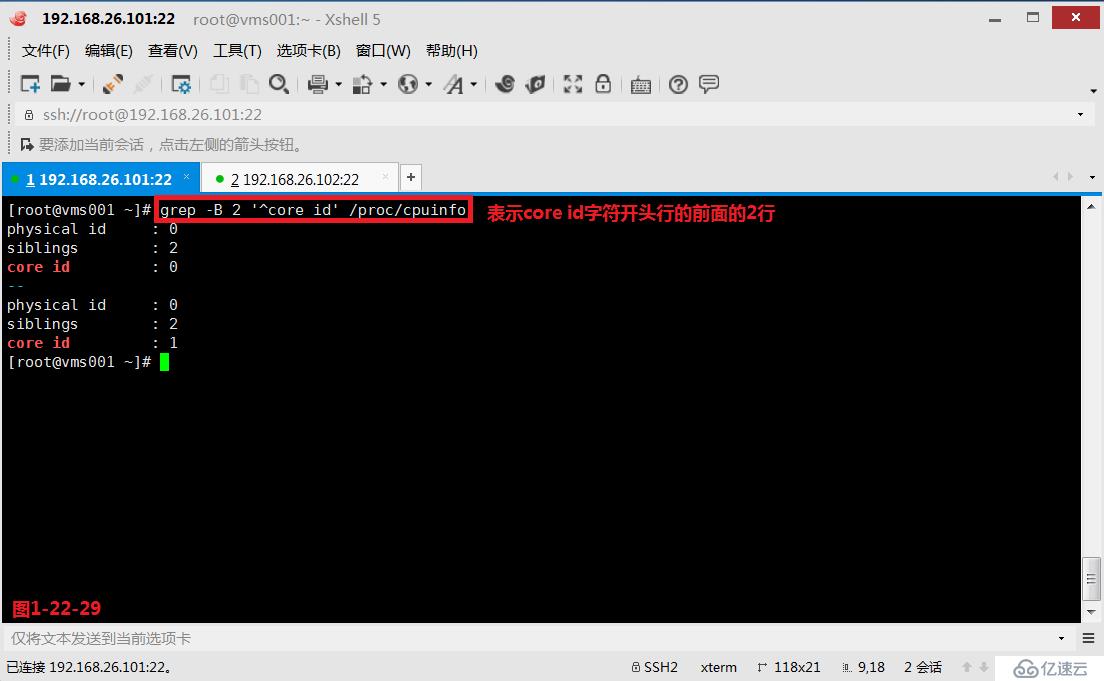
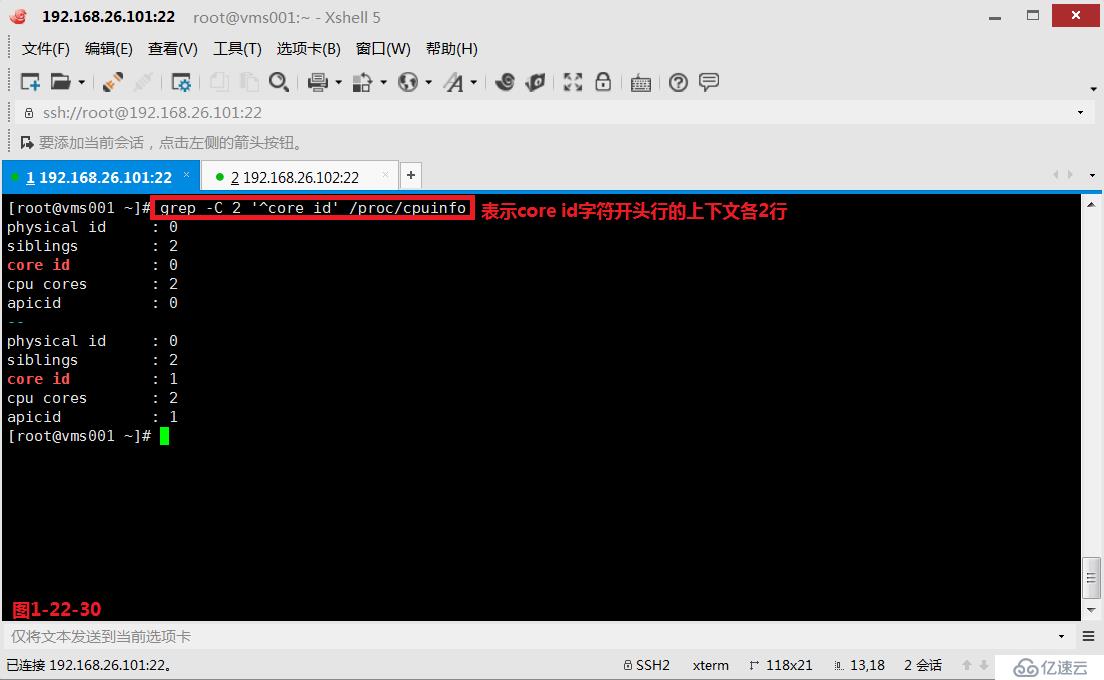
(3.11)我们在使用grep命令的时候可以使用“-A”、“-B”、“-C”参数,其中-A表示的是after后面,其中-B表示的是before前面,其中-C表示的是context上下文。
# grep -A 2 '^core id' /proc/cpuinfo---表示core id字符开头行的后面的2行
# grep -B 2 '^core id' /proc/cpuinfo---表示core id字符开头行的前面的2行
# grep -C 2 '^core id' /proc/cpuinfo---表示core id字符开头行的上下文各2行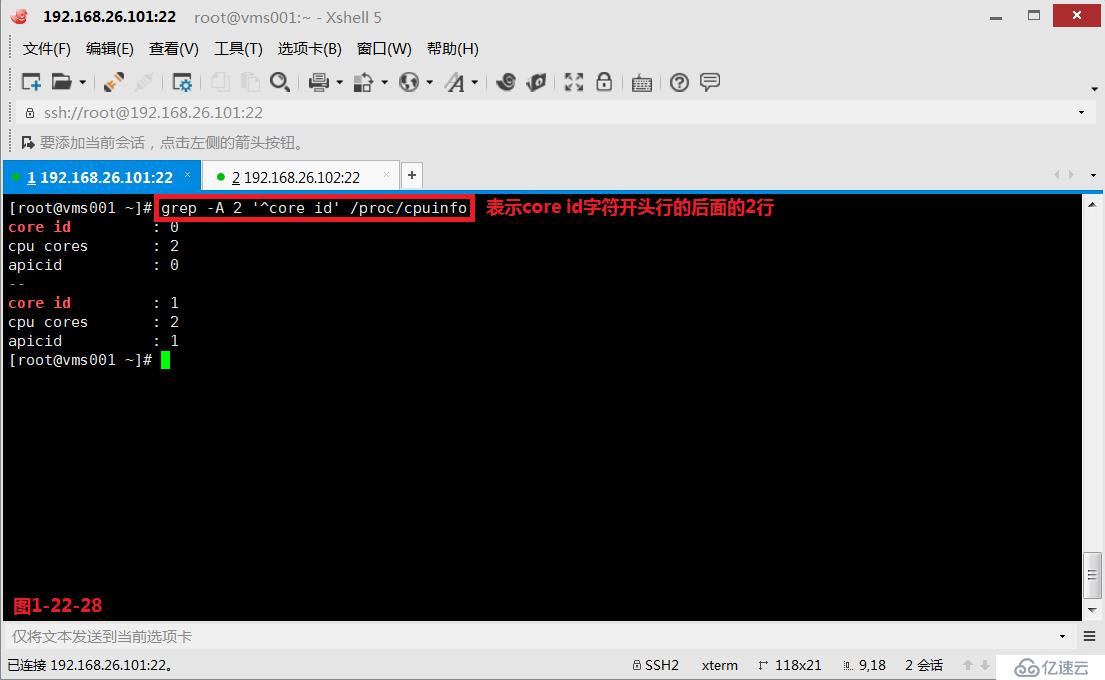
(四)扩展正则表达式的使用
(4.1)以上我们所使用的正则表达式在进行查询的时候可以配合grep命令进行使用“grep 表达式 file”。不过有些正则表达式grep命令并不支持,此时我们应该使用“grep -E 表达式 file”或者“egrep 表达式 file”启用扩展的正则表达式进行查询。有时候还有一些正则表达式是扩展的正则表达式也解决不了的,此时我们应该使用“grep -P 表达式 file”即调用perl语言中的正则表达式进行查询。分割线扩展正则表达式。
注意:egrep -o表示的是仅仅输出查询出的字符
(4.2)第一个“?”表示它前面出现的字符,出现0次或者1次。“to.?”表示的意思是to后会跟一个任意的字符,但是这样任意的字符可能出现0次,也可能出现1次,所以此时aa.txt 文件中包括“to”在内的所有行都是符合要求的。此时由于使用的“?”问号,所以我们需要使用扩展的正则表达式egrep进行匹配查询。
# egrep 'to.?' aa.txt---其中to后会跟一个任意的字符,但是这样任意的字符可能出现0次,也可能出现1次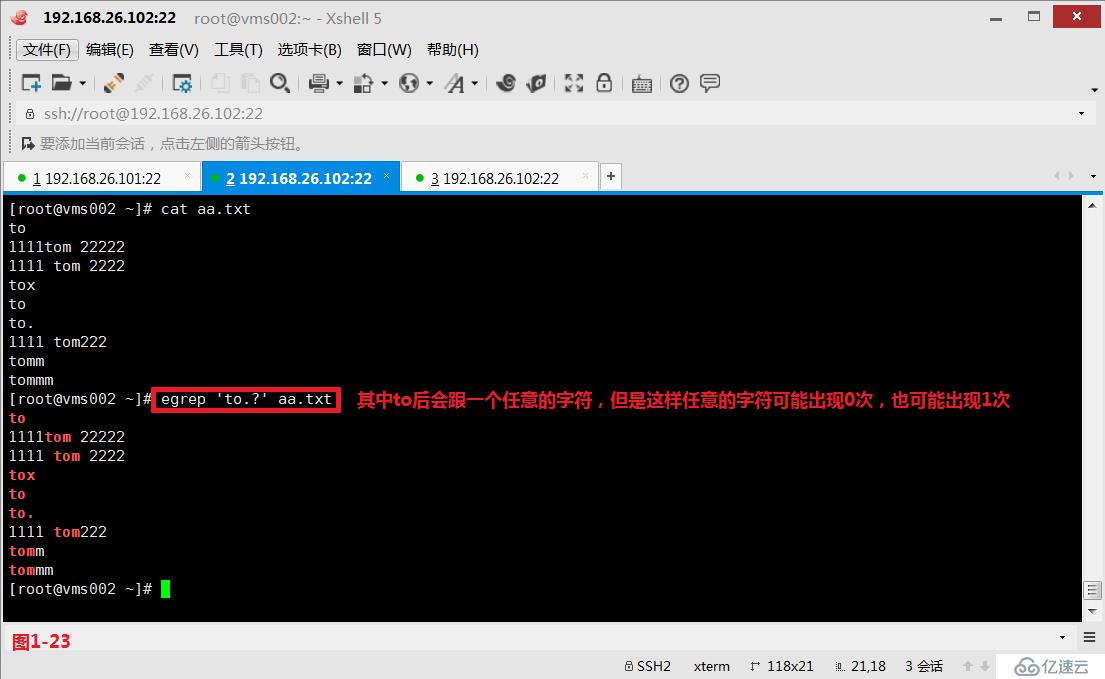
(4.3)第二个“+”表示它前面的字符出现1次或者多次。此时我们查询“to.+”表示的意思是在to单词后面有一个任意字符,同时这个任意字符出现可能是1次,也可能出现多次,所以在aa.txt文件中除了第一行不符合要求,其他的行都是符合要求的。同时我们需要使用扩展的正则表达式egrep进行匹配查询。
# egrep 'to.+' aa.txt---也称贪婪匹配,在to单词后面有一个任意字符,同时这个任意字符出现可能是1次,也可能出现多次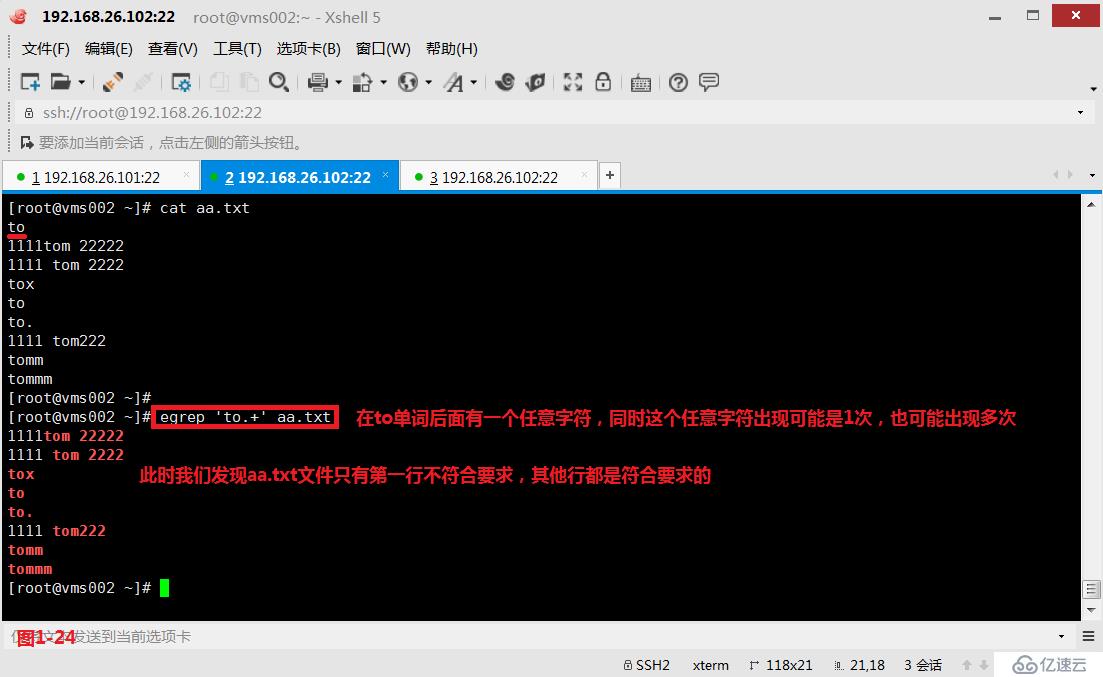
(4.4)第三个“*”表示它前面的字符出现任意次数。此时我们查询“to.*”表示匹配的是to单词后有一个任意字符,并且这个任意字符出现任意次,包括0次、1次、任意次。所以此时aa.txt文件中所有行都是符合匹配的要求的。同时我们需要使用扩展的正则表达式egrep进行匹配查询。
# egrep 'to.*' aa.txt---查询匹配to单词后有一个任意字符,并且这个任意字符出现任意次,包括0次、1次、任意次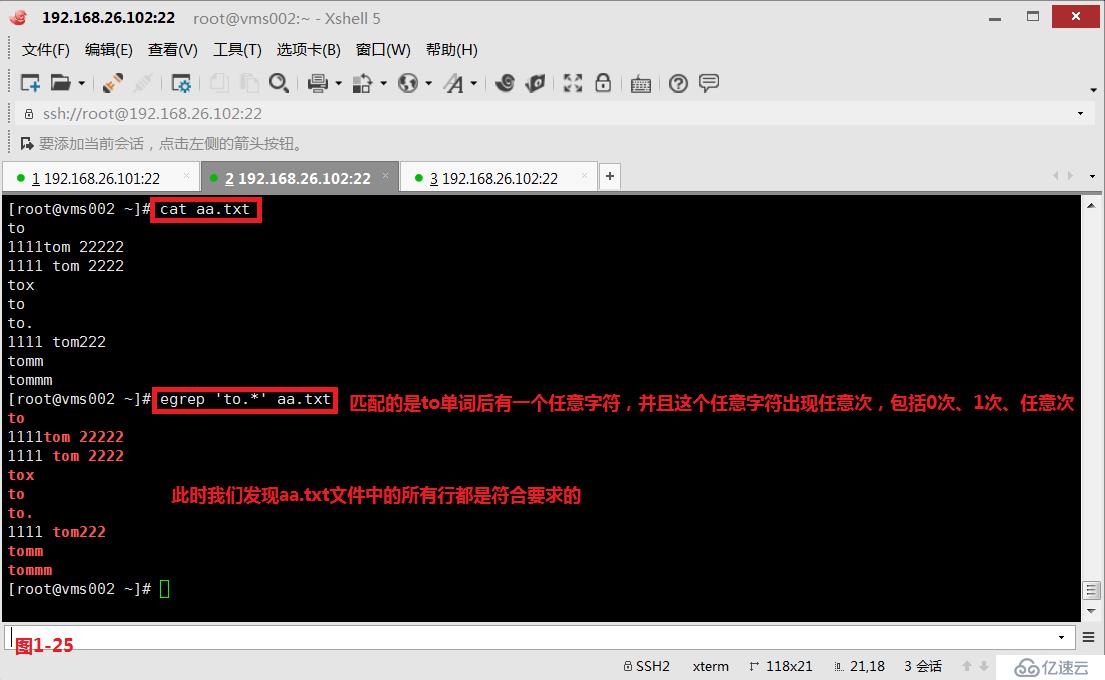
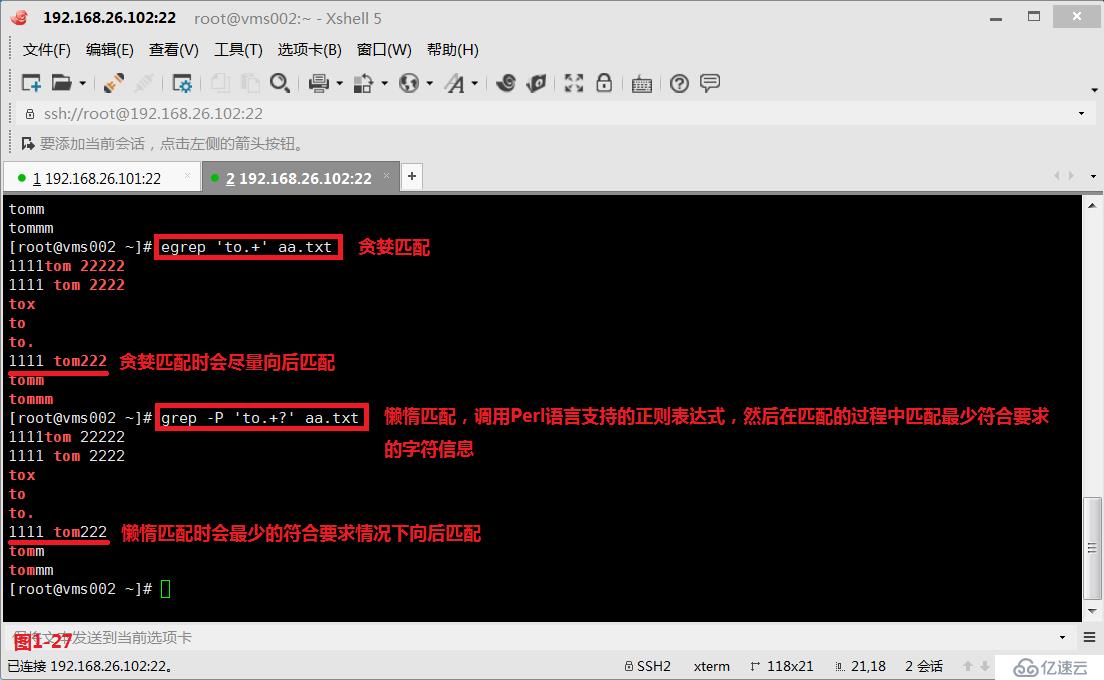
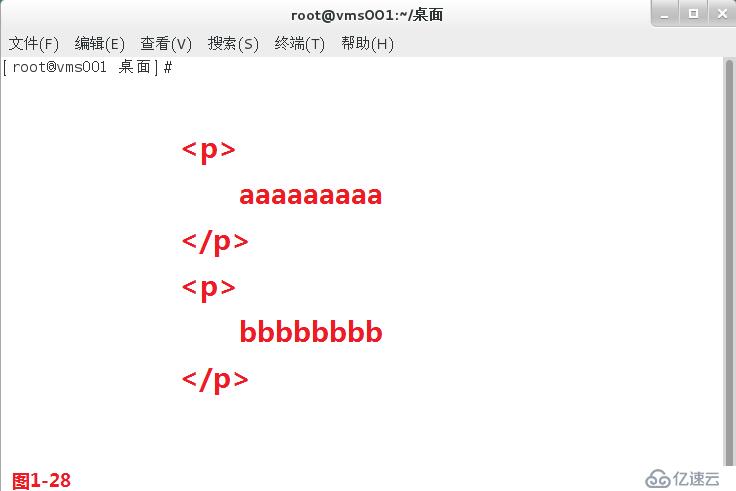
(4.5)在模式匹配的过程中我们有两个概念,第一个是贪婪匹配,第二个是懒惰匹配,默认是工作在贪婪模式中。其中贪婪匹配表示的是尽可能多的向后面进行匹配,例如“to.+”表示的是to单词后会有一个任意字符,并且这个任意的字符至少是1个,最多可以任意的个数,所以匹配的时候符合要求的行会尽可能的向后进行匹配,同时我们需要使用扩展的正则表达式egrep进行匹配查询(图1-26)。而懒惰匹配表示的是在符合要求的情况下尽可能少的向后进行匹配,例如“to.+?”表示的是to单词后会有一个任意字符,“+”表示并且这个任意字符至少匹配一个,最多可以匹配任意的个数,“?”表示前面的部分可以出现0次或者1次,所以此时就会按照最少符合要求的情况进行懒惰匹配,同时我们需要使用扩展的正则表达式“grep -P”进行匹配查询(图1-27)。以上的应用也是非常广泛的,有时候我们在网站进行信息抓取的时候我们希望从<p>标志位开始的抓取,到</p>标志位结束,此时如果我们使用贪婪匹配的模式进行抓取,那么我们抓取的信息便包含a和b两段内容,如果我们使用懒惰匹配的模式进行抓取,那么我们抓取的信息就只会包含a段的内容(图1-28)。
# egrep 'to.+' aa.txt---贪婪匹配,在to单词后面有一个任意字符,同时这个任意字符出现可能是1次,也可能出现多次,同(3.9)
# grep -P 'to.+?' aa.txt---懒惰匹配,调用Perl语言支持的正则表达式,然后在匹配的过程中匹配最少符合要求的字符信息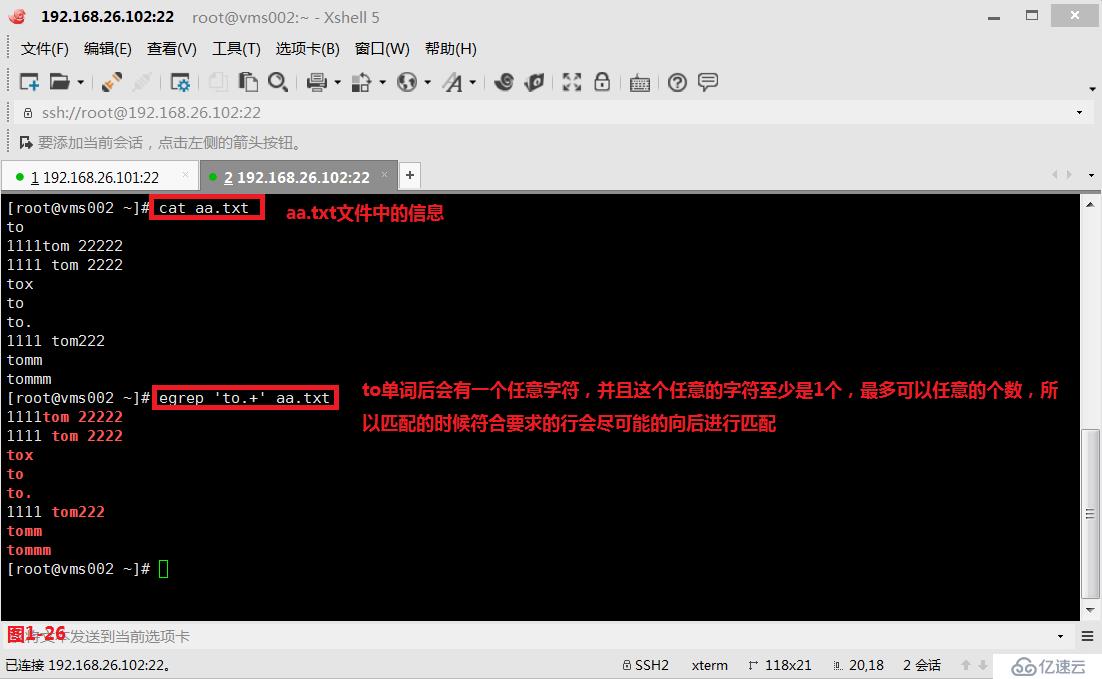
(4.6)第四个是在使用grep -P时的“{n,m}”,在使用常规grep时的“{n,m}”,表示的是匹配次数在n到m之间,包括边界;其中grep -P时的“{n}”或者常规grep时的“{n}”表示必须匹配n次;grep -P时的“{n,}”或者常规grep时的“{n,}”表示匹配n次及以上。
# grep -P 'tom{2}' aa.txt---查询m出现两次的所有符合字段
# grep -P 'tom{2,}' aa.txt---查询m出现次数在两次及两次以上的所有符合字段
# grep 'tom{2,}' aa.txt---查询m出现次数在两次及两次以上的所有符合字段,由于使用的是常规grep,所以需要用“{2,}”表示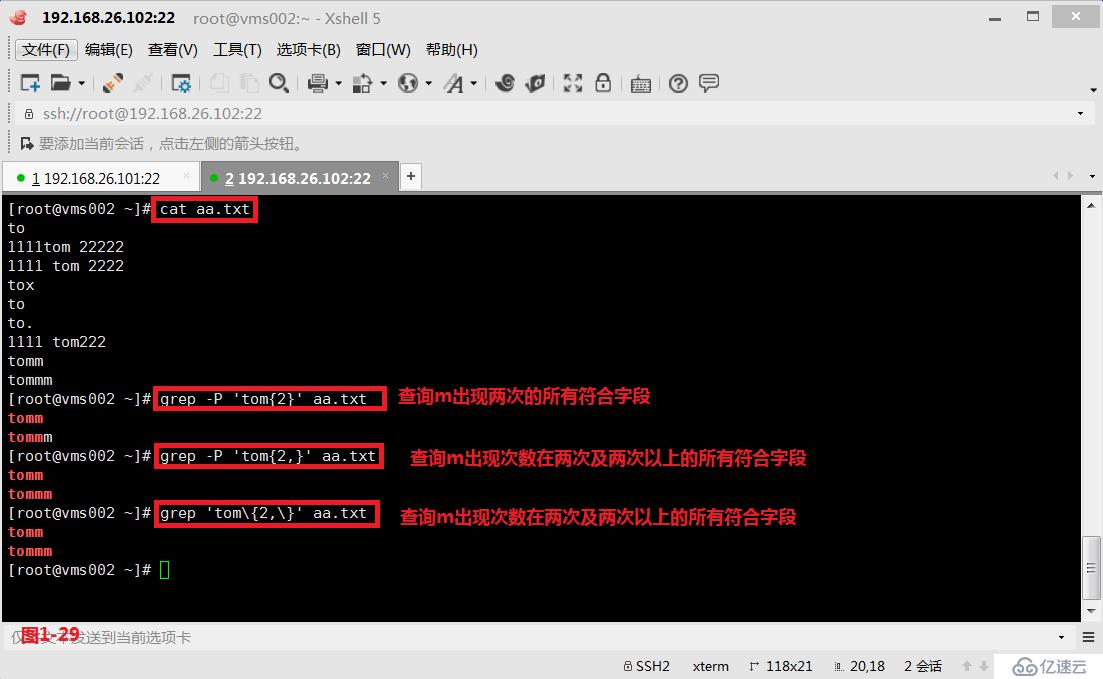
(4.7)第五个是可以使用指定的字符表示特定类型的一类字符。
[[:alpha:]]:表示所有字母
[[:alnum:]]:表示字母与数字字符
[[:ascii:]]:表示ASCII字符
[[:blank:]]:表示空格或制表符
[[:cntrl:]]:表示ASCII控制符
[[:digit:]]:表示数字
[[:graph:]]:表示可见字符,非控制、非空格字符
[[:lower:]]:表示小写字母
[[:print:]]:表示可打印字符
[[:punct:]]:表示标点符号字符
[[:space:]]:表示空白字符,包括垂直制表符
[[:upper:]]:表示大写字母
[[:xdigit:]]:十六进制数字
(4.8)查询实例
(4.8.1)示例:查询IP地址,目前在我们的/var/log/messages文件主要保存的是系统的日志信息,其中也会有包含IP地址的字符信息,我们的需求是将其中所有IP地址格式的信息全部过滤出来。由于我们知道IP地址的格式可以是192.168.26.101,也可以是1.1.1.1,所以此时我们可以使用“[0-9]{1,3}”表示IP地址的一段信息,使用“{3}”表示数字和点组成的信息重复3次,最后再加上一段数字,此时我们便可以得到这样一个表示IP地址格式的正则表达式:([0-9]{1,3}.){3}[0-9]{1,3}
# less /var/log/messages---查看包含系统日志的文件
# egrep '([0-9]{1,3}.){3}[0-9]{1,3}' /var/log/messages---查询出日志中所有包含IP地址的所有字符信息的行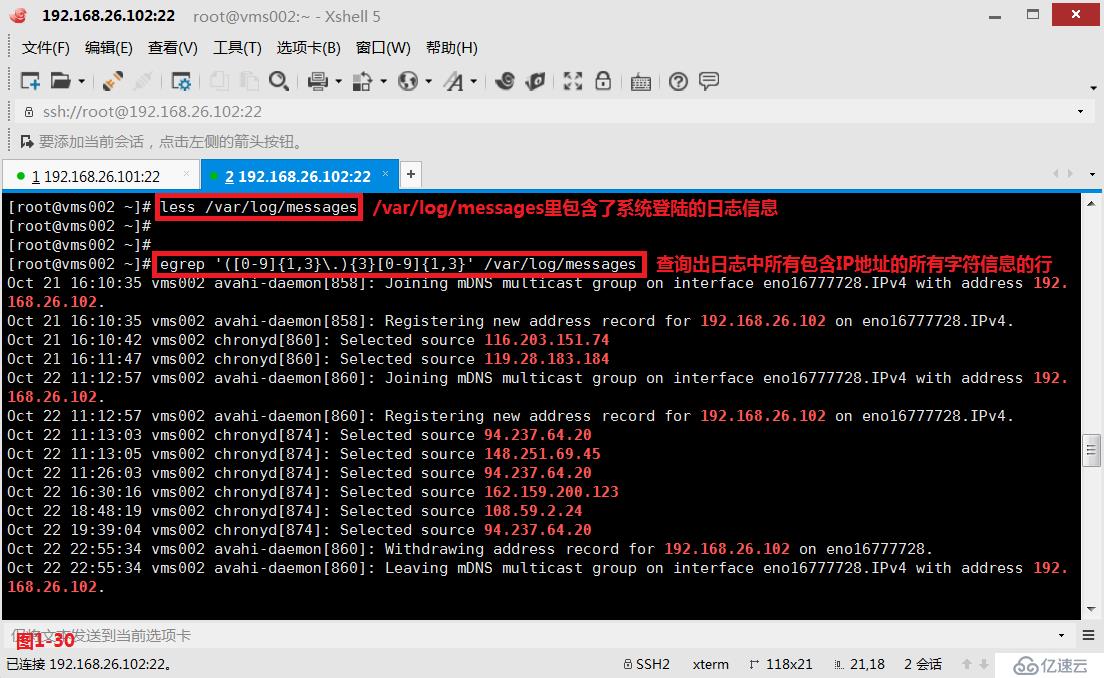
(4.8.2)示例:找出/boot/grub2/grub.cfg文件中1-255之间的数字。此时我们可以使用的正则表达式为:\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>
# egrep '\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>' /boot/grub2/grub.cfg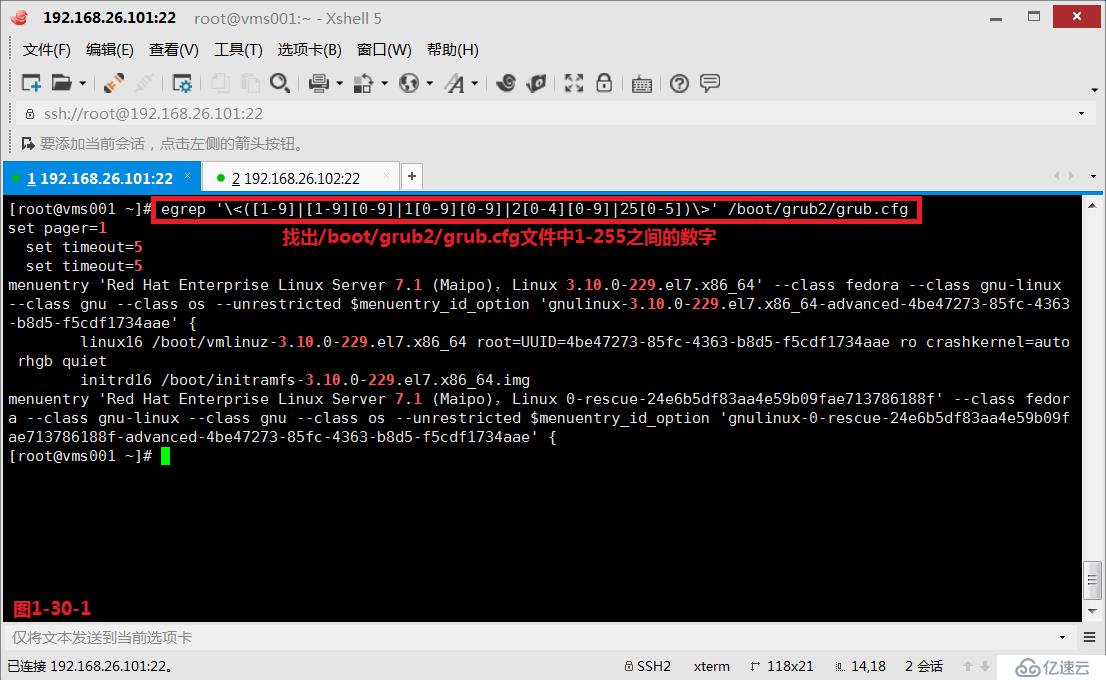
(4.8.3)示例:粗略查询所有符合IP地址格式要求的字符串,例如0.0.0.0至255.255.255.255这样的格式,此时我们可以按照如下的方式进行查询。
# ifconfig | egrep -o '\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>'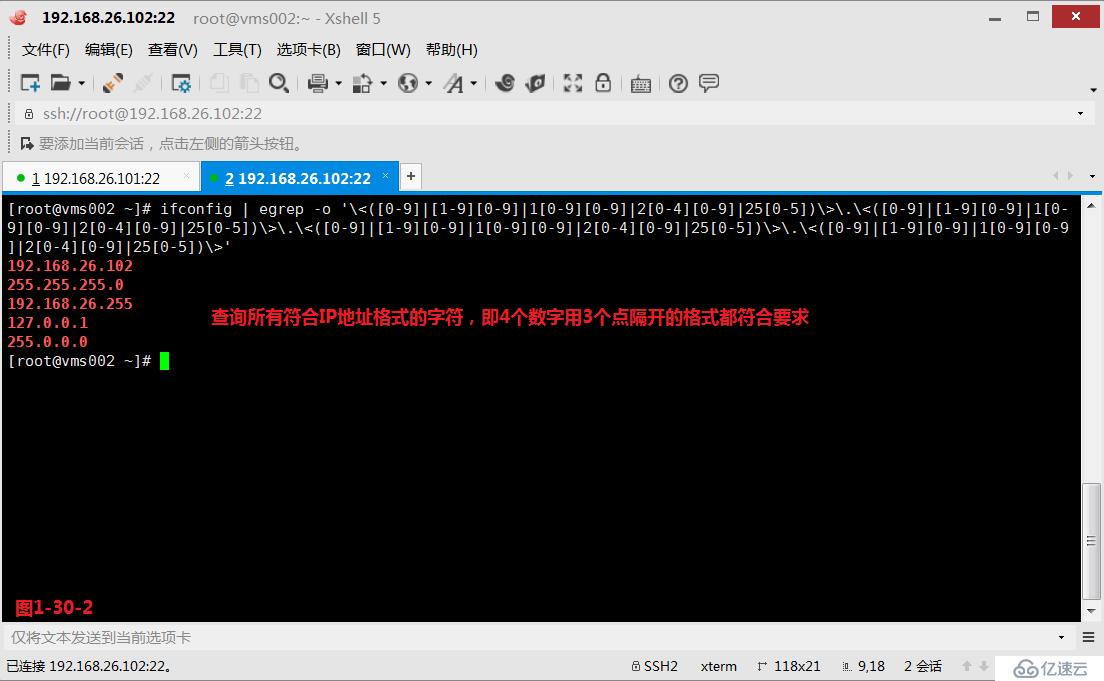
(4.8.4)示例:精确查询所有格式为IP地址,并且符合五类IP地址中A类、B类、C类IP地址的所有适合的字段。
A类:1-127
B类:128-191
C类:192-223
# ifconfig | egrep '\<([1-9]|[1-9][0-9]|1[0-9]{2}|2[01][0-9]|22[0-3])\>(\.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-4])\>){2}\.\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-4])\>'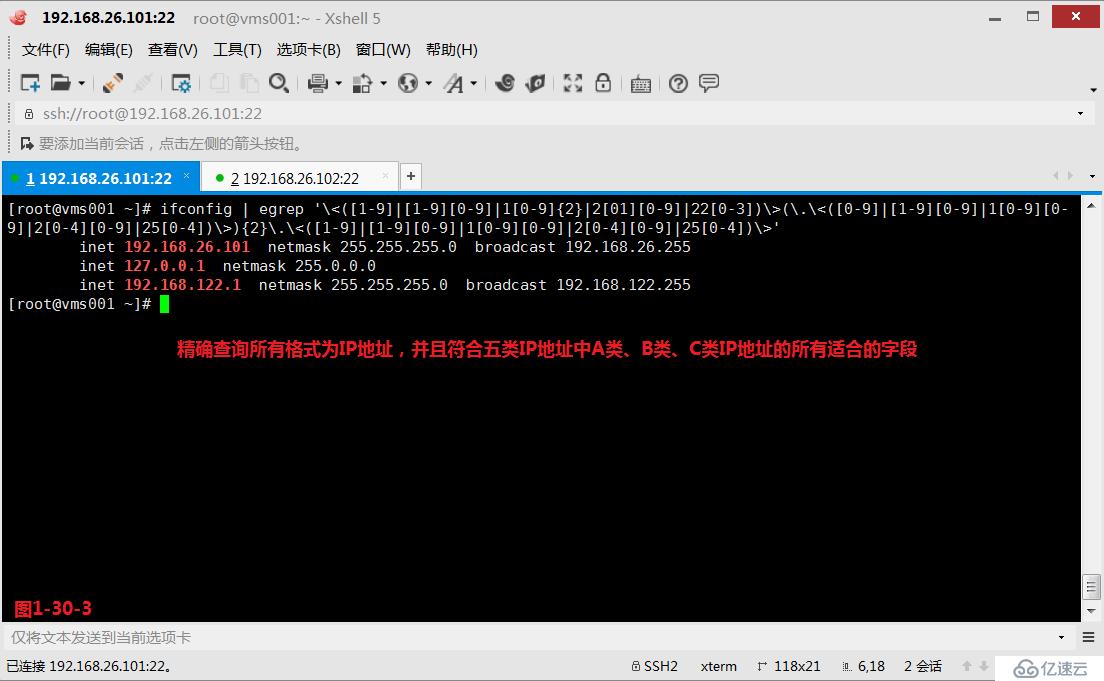
(4.9)一般我们在表示正则表达式中表达式的部分的时候是建议加上单引号将表达式引起来的。如果我们在系统中如果原先存在一个toz文件名的文件,此时我们对表达式不加单引号的情况下,首先会将查询的“to?”发送到shell中进行shell解析,此时sehll会对应“to?”在系统中查找并解析成“toz”,然后再将“toz”发送到egrep中进行解析,此时在aa.txt文件中是查询不出来任何信息的。所以一般是需要将表示正则表达式中表达式的部分的时候是建议加上单引号这样可以防止shell解析的情况发生。
# egrep 'to?' aa.txt---查询aa.txt中to单词后出现一个任意字符,这个任意字符出现0次或者1次
# egrep to\? aa.txt---和以上使用单引号的效果一致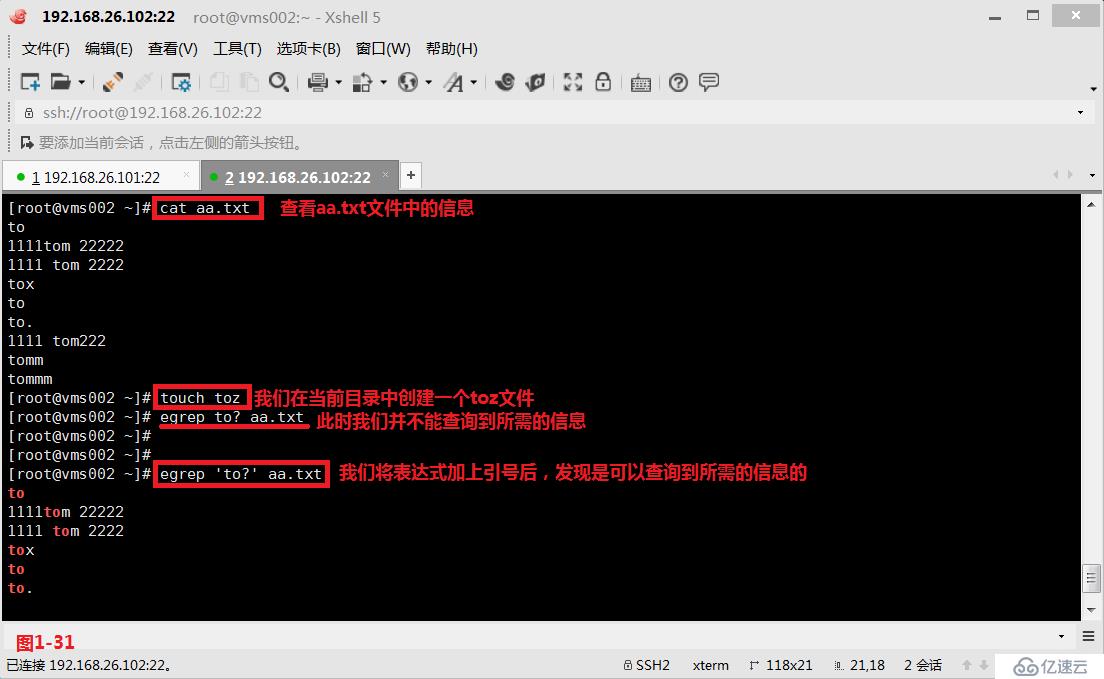
—————— 本文至此结束,感谢阅读 ——————
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



