这篇文章给大家分享的是有关Tensorflow分布式并行策略的示例分析的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
tensorFlow中主要包括了三种不同的并行策略,其分别是数据并行、模型并行、模型计算流水线并行,具体参考Tenssorflow白皮书,在接下来分别简单介绍三种并行策略的原理。
数据并行
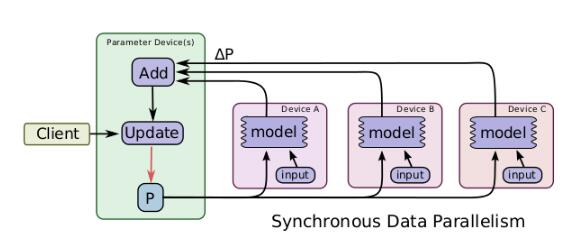
一个简单的加速训练的技术是并行地计算梯度,然后更新相应的参数。数据并行又可以根据其更新参数的方式分为同步数据并行和异步数据并行,同步的数据并行方式如图所示,tensorflow图有着很多的部分图模型计算副本,单一的客户端线程驱动整个训练图,来自不同的设备的数据需要进行同步更新。这种方式在实现时,主要的限制就是每一次更新都是同步的,其整体计算时间取决于性能最差的那个设备。
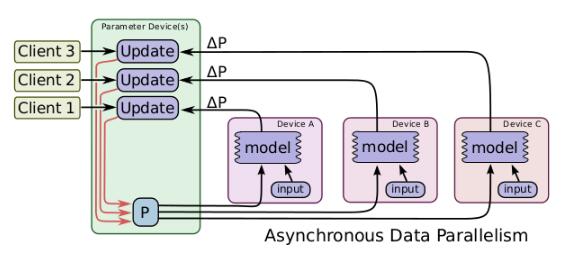
数据并行还有异步的实现方式,如图所示,与同步方式不同的是,在处理来自不同设备的数据更新时进行异步更新,不同设备之间互不影响,对于每一个图副本都有一个单独的客户端线程与其对应。在这样的实现方式下,即使有部分设备性能特别差甚至中途退出训练,对训练结果和训练效率都不会造成太大影响。但是由于设备间互不影响,所以在更新参数时可能其他设备已经更好的更新过了,所以会造成参数的抖动,但是整体的趋势是向着最好的结果进行的。所以说这种方式更适用于数据量大,更新次数多的情况。
模型并行
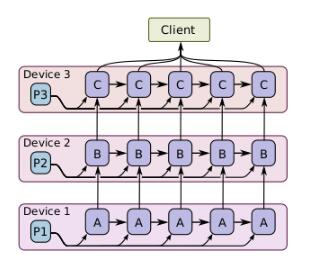
一个模型并行训练的例子如图所示,其针对的训练对象是同一批样本数据,但是将不同的模型计算部分分布在不同的计算设备上同时执行。
模型计算流水线并行
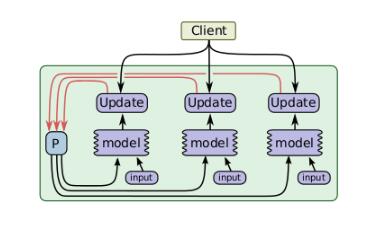
此并行方式主要针对在同一个设备中并发实现模型的计算,如图是其并发计算步骤,可以发现它实际上与异步数据并行有些相似,但是唯一不同的是此方式的并行发生在同一个设备上,而不是在不同的设备之间。并且在计算一批简单的样例时,允许进行“填充间隙”,这可以充分利用空闲的设备资源。
感谢各位的阅读!关于“Tensorflow分布式并行策略的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



