下文主要给大家带来Mysql中索引、事物及存储引擎的详细介绍,希望Mysql中索引、事物及存储引擎的详细介绍这些内容能够带给大家实际用处,这也是我编辑这篇文章的主要目的。好了,废话不多说,大家直接看下文吧。
一、索引:
(1)数据库索引:
1、在数据库中,索引使数据程序无须对整个表进行扫描,就可以在其中找到所需数据;
2、数据库中的索引是某个表中一列或者若干列值的集合,以及物理标识这些值的数据页的逻辑指针清单。
(2)索引的作用:
1、数据库能够大大加快查询速率;
2、降低数据库的 IO 成本,并且索引还可以降低数据库的排序成本;
3、通过创建唯一性索引保证数据表数据的唯一性;
4、加快表与表之间的连接;
5、分组和排序的时候,可以大大减少分组和排序时间
(3)索引分类:
1、普通索引 :最基本的索引类型,而且没有唯一性之类的限制;
2、唯一性索引 :与普通索引基本相似,区别在于,索引列的所有值都只能出现一次,即必须唯一;
3、主键 :主键是一种唯一性索引,必须指定为 “ primary key ” ;
4、全文索引 :mysql 从3.23.23版本开始支持全文索引和全文检索,在mysql 中,全文索引的索引类型为 fulltext ,全文索引可以在 varchar 或者 text 类型的列上创建;
5、单列索引与多列索引:索引可以是单列上创建的索引,也可以是在多列上创建的索引。
(4)创建索引的原则依据:
表的主键、外键必须有索引;
数据量超过 300 行的表应该有索引;
经常与其他表进行连接的表,在连接字段上应该建立索引;
唯一性太差的字段不适合建立索引;
更新太频繁的字段不适合创建索引;
经常出现在 where 子句中的字段,特别是大表的字段,应该建立索引;
索引应该建立在选择性高的字段上;
索引应该建立在小字段上,对于大的文本字段甚至超长字段,不要建立索引。
(5)创建索引的办法:
1、创建普通索引:

例如,我们针对下面这张表,给年龄这列创建一个索引:
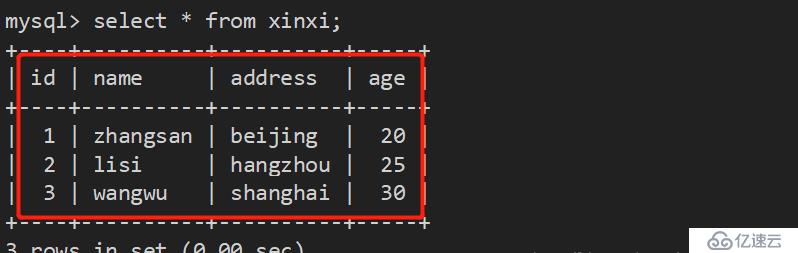


2、创建唯一性索引:



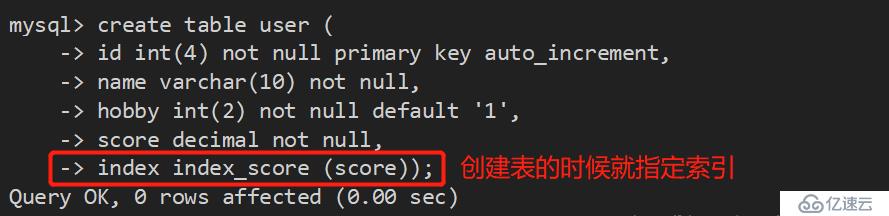
3、创建主键索引:

4、创建全文索引:
create fulltext index 索引名称 on 表名(列的列表);
5、创建组合索引:
create index 索引名称 on 表名 (列的列表1,列的列表2.....);
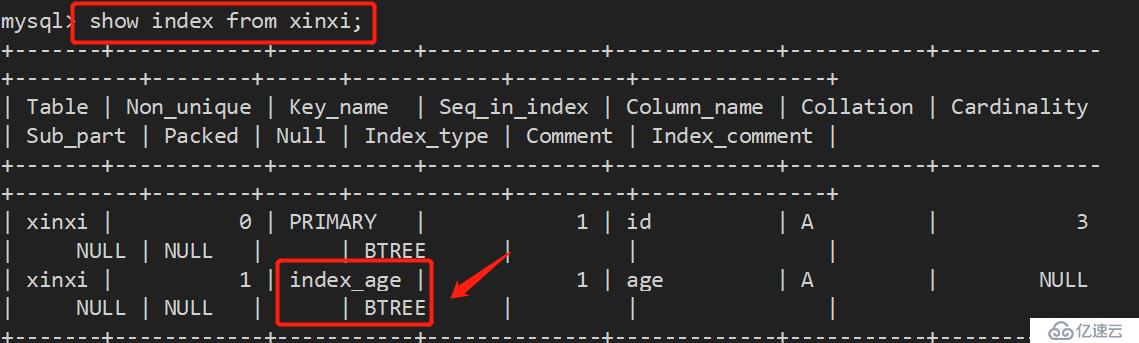
6、查看索引:
show index from tablename; show keys from tablename;
二、事务:
(1)事务概念:
简单的说就是把所有的命令作为一个整体一起提交或者撤销,要么一起都执行,要么一起都不执行。
(2)事务的四大特性:
1、原子性:所有元素都必须作为一个整体提交或回滚,任何元素失败,则整个事务都失败;
例如,我们平时下载软件等,如果中途遇到故障等导致安装失败,就会退回到安装软件前的状态。
2、一致性:事务开始之前,数据处于统一、一致的状态;事务完成之后,再次回到一致转态。
3、隔离性:所有并发事务彼此独立,互不相干、影响。
4、持久性:一旦事务被提交,就会被永久地保留在数据库中。
(3)事务的操作:
默认情况下,mysql 的事务都是自动提交的,当 sql 语句提交时事务便自动提交;
手动对事务进行控制的办法(事务处理命令控制或者使用 set命令控制):
1、事务处理命令控制事务:
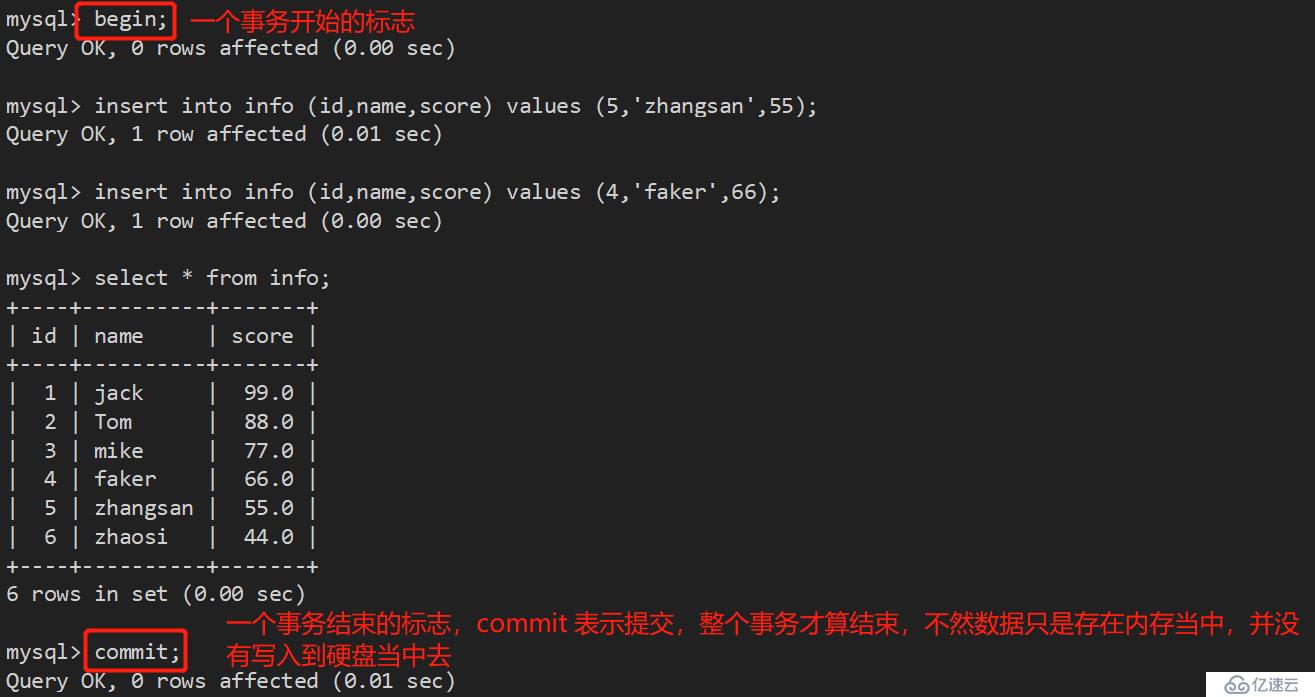
begin :开始一个事务;
commit :提交一个事务;
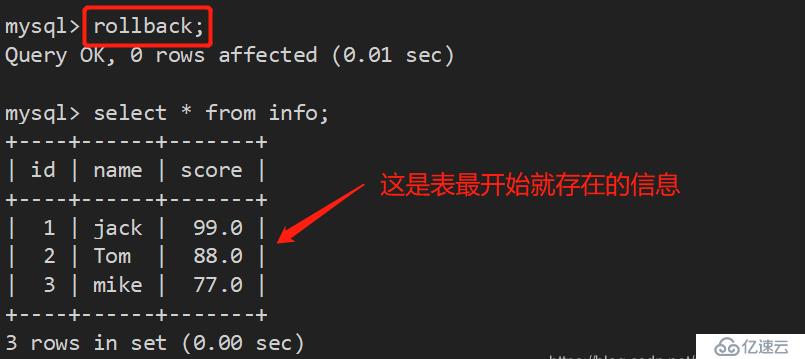
rollback :回滚一个事务;
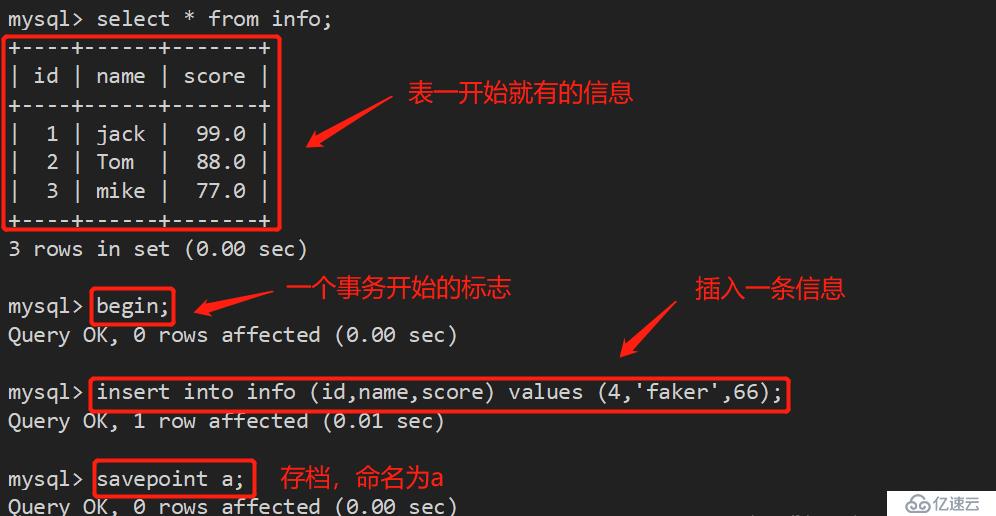
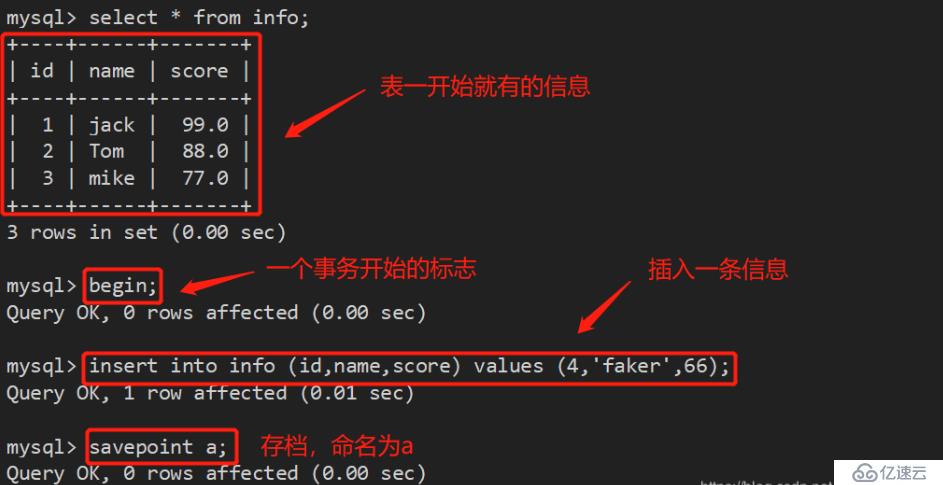
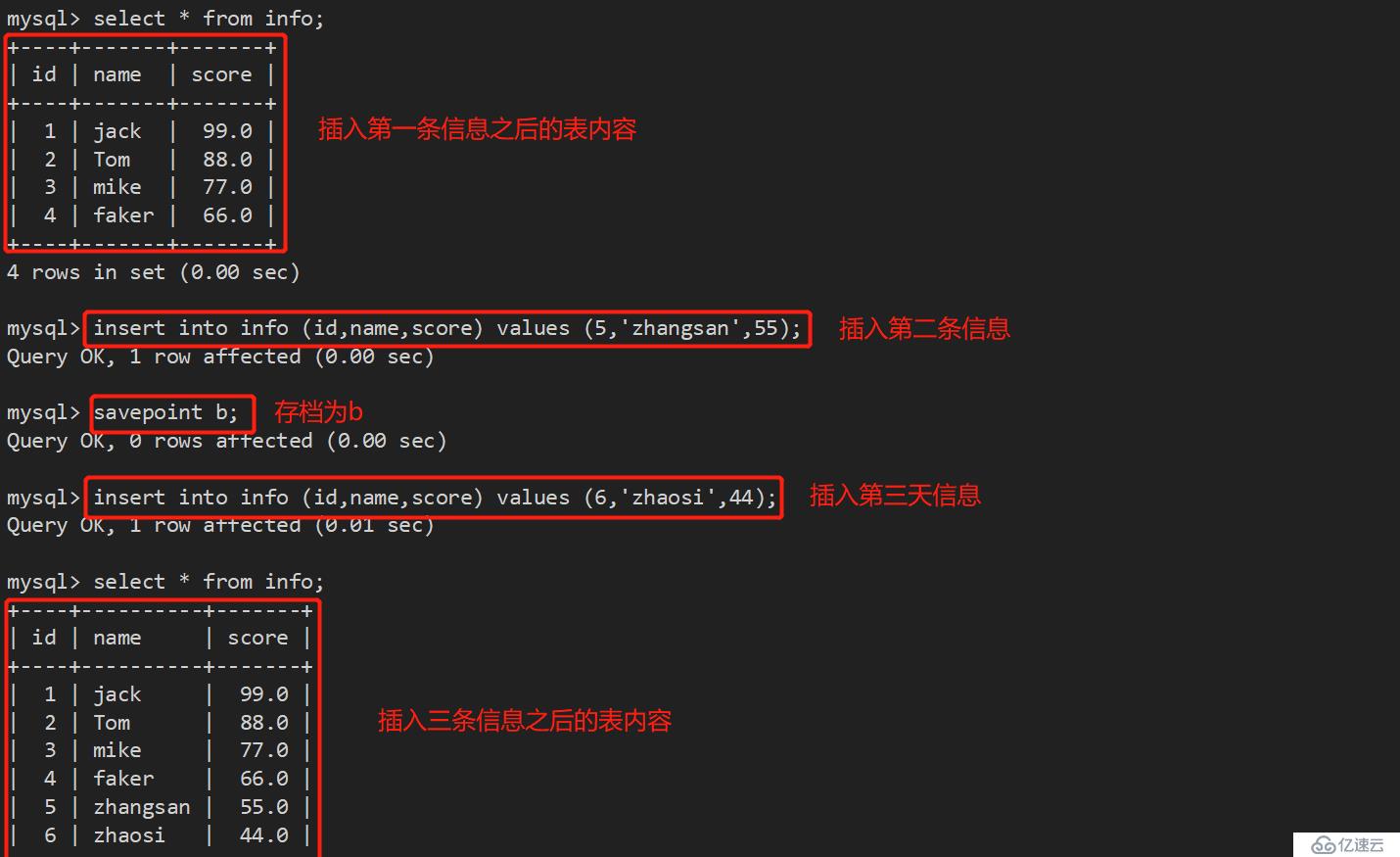
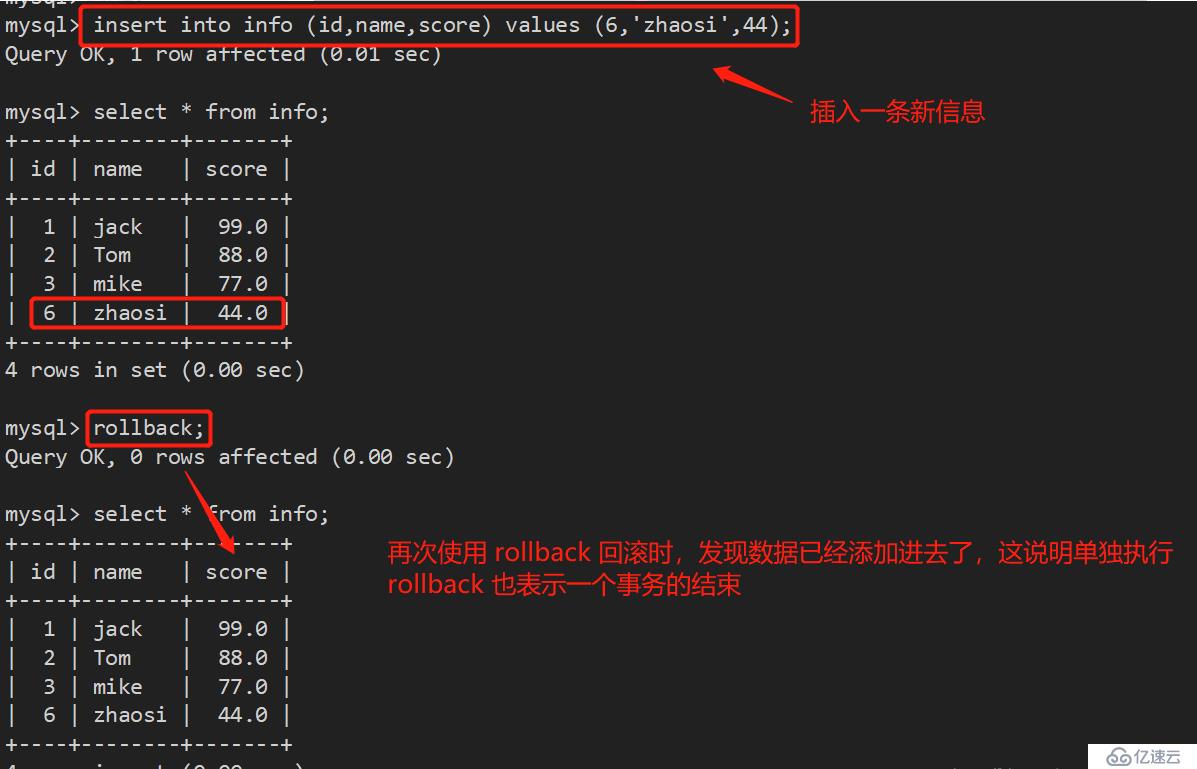
接下来,我们开始做回滚操作,想回到哪个节点,就回到那个存档点即可:
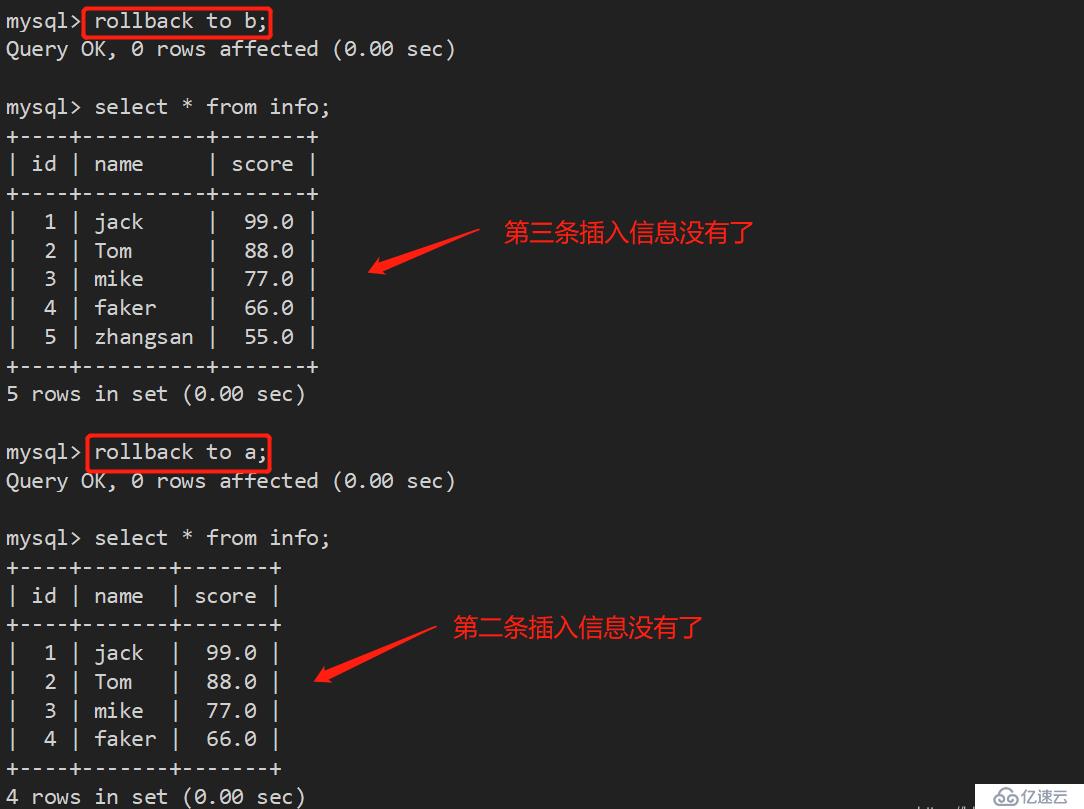
要想回滚到最初状态,直接使用 rollback 命令:
2、使用 set 命令进行控制:
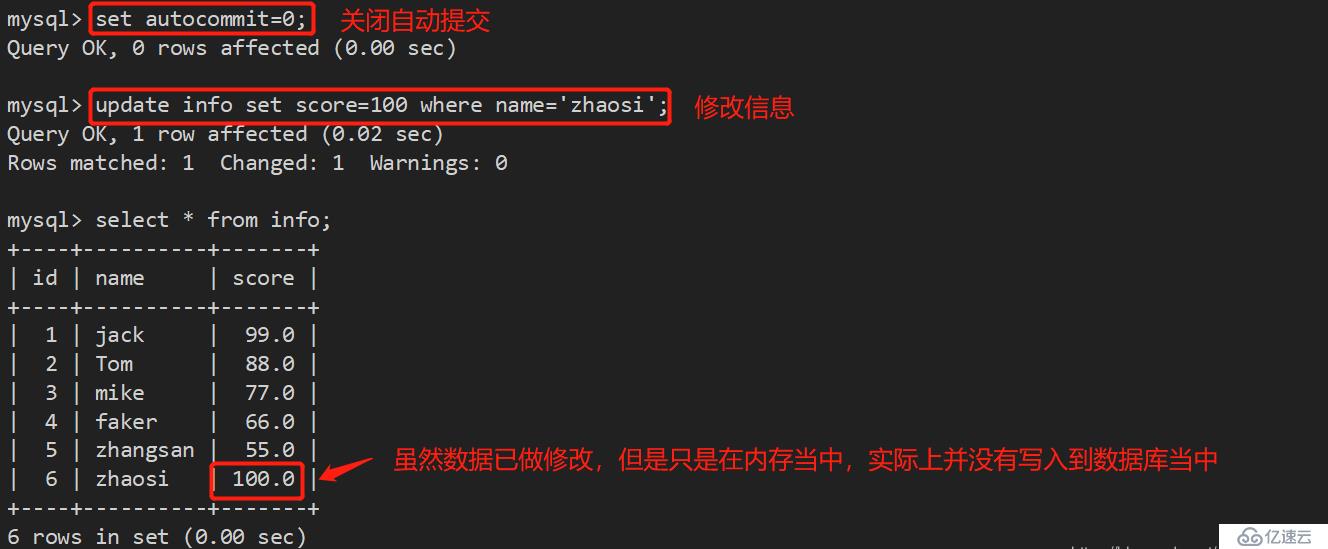
set autocommit=0 :禁止自动提交;
set autocommit=1 :开启自动提交;

三、存储引擎:
(1)存储引擎概念:
mysql 中的数据用各种不同的技术存储在文件中,每一种技术都使用不同的存储机制、索引技巧、锁定水平并最终提供不同的功能和能力,这些不同的技术以及配套功能在 mysql 中称为存储引擎。
存储引擎就是 mysql 将数据存储在文件系统中的存储方式或者存储格式;
目前 Mysql 常用的两种存储引擎:
MyISAM (轻量级)
InnoDB
mysql 存储引擎是 mysql 数据库云服务器中的组件,负责为数据库执行实际的数据 I/O 操作;
使用特殊存储引擎的主要优点之一在于,仅需提供特殊应用的特性,数据库中的数据开销较小,具有更有效和更高的数据库性能;
mysql 系统中,存储引擎处于文件系统之上,在数据保存到数据文件之前会传输到到存储引擎,之后按照各个存储引擎的存储格式进行存储。
1、MyISAM 介绍:
是5.5版本之前的默认存储引擎,前身是 ISAM;
①.特点:
ISAM 执行读取操作的速度很快,
不占用大量的内存和存储资源;
但是不支持事务处理;
不能够容错;
MyISAM在磁盘.上存储的文件;
②.数据存储位置:
表定义文件;
表数据存储文件;
表索引文件;
.frm文件存储表定义
数据文件的扩展名为.MYD (MYData)
索引文件的扩展名是.MYI (MYIndex)
③.MyISAM适用的生产场景举例:
公司业务不需要事务的支持;
数据修改相对较少的业务;
一般单方面读取数据比较多的业务,或单方面写入数据比较多的业务;
对数据业务一致性要求不是非常高的业务云服务器硬件资源相对比较差。
2、InnoDB
①.特点:
支持4个事务隔离级别;
具有非常高效的缓存特性:能缓存索引,也能缓存数据;
支持分区、表空间,类似oracle数据库;
表与主键以簇的方式存储;
行级锁定,但是全表扫描仍然会是表级锁定读写阻塞与事务隔离级别相关;
适用于对硬件资源要求还是比较高的场合。
②.适用的生产场景:
业务需要事务的支持;
业务数据更新较为频繁的场景;
业务数据一致性要求较高;
件设备内存较大,利用Innodb较好的缓存能力来提高内存利用率,减少磁盘I0的压力;
(2)企业选择存储引擎依据 :
需要考虑每个存储引擎提供了哪些不同的核心功能及应用场景;
支持的字段和数据类型;
锁定类型(表锁定,行锁定);
(3)存储引擎相关命令:
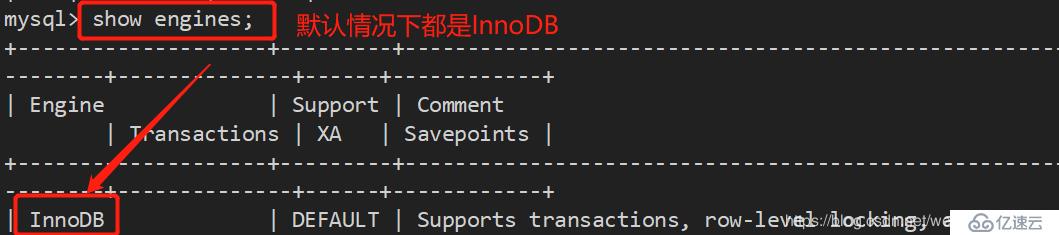
1、查看存储引擎的命令:
show engines //查看系统支持的存储引擎
2、查看表使用的存储引擎:
show table status from 库名 where name='表名'; show create table 表名;
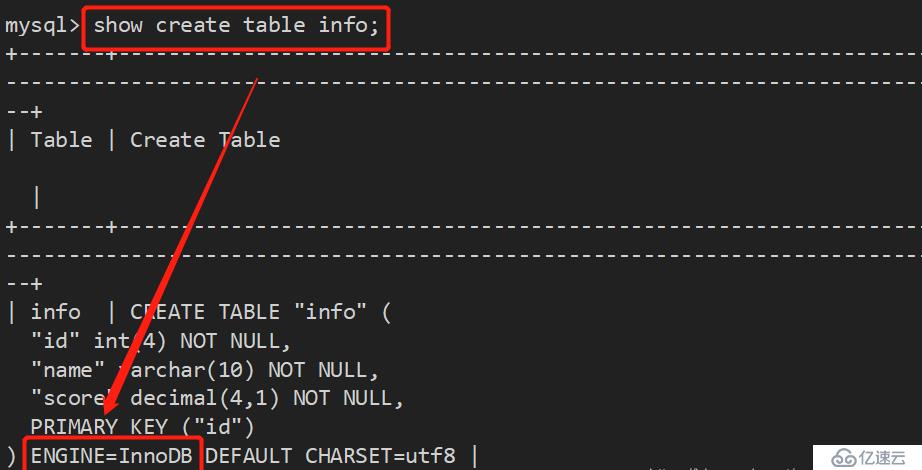
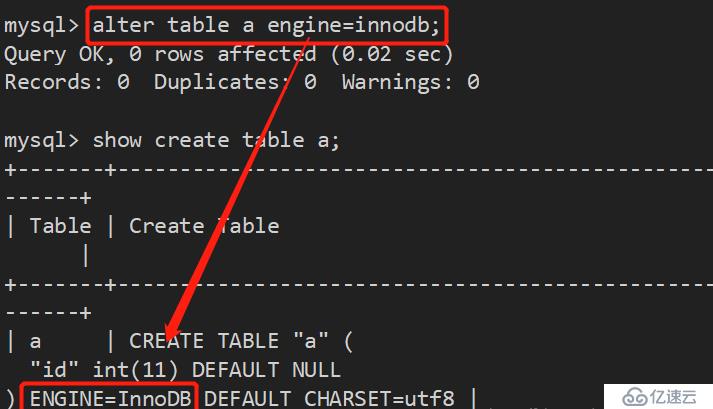
3、修改存储引擎:
方法一:使用 alter table 修改
alter table table_name engine=引擎;
方法二:修改 my.cnf 文件,指定默认存储引擎并重启服务
default-storage-engine=InnoDB

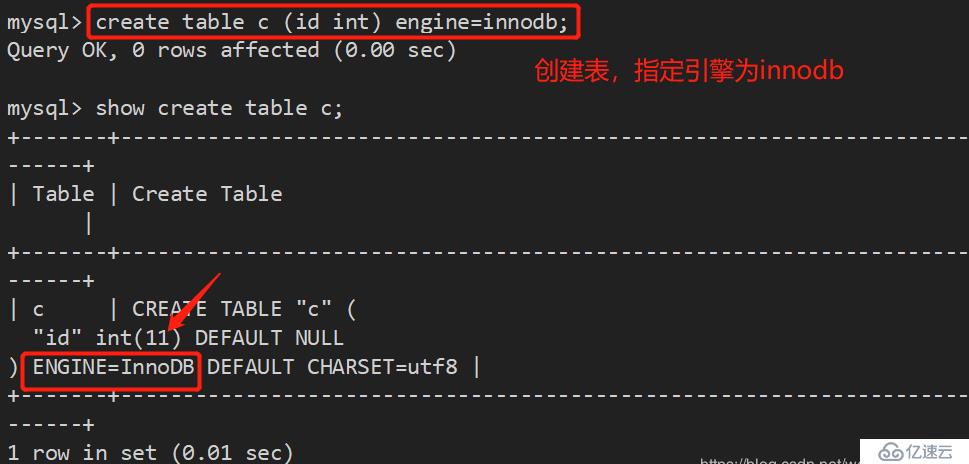
方法三:create table 创建表时指定存储引擎
create table 表名(字段) engine=引擎
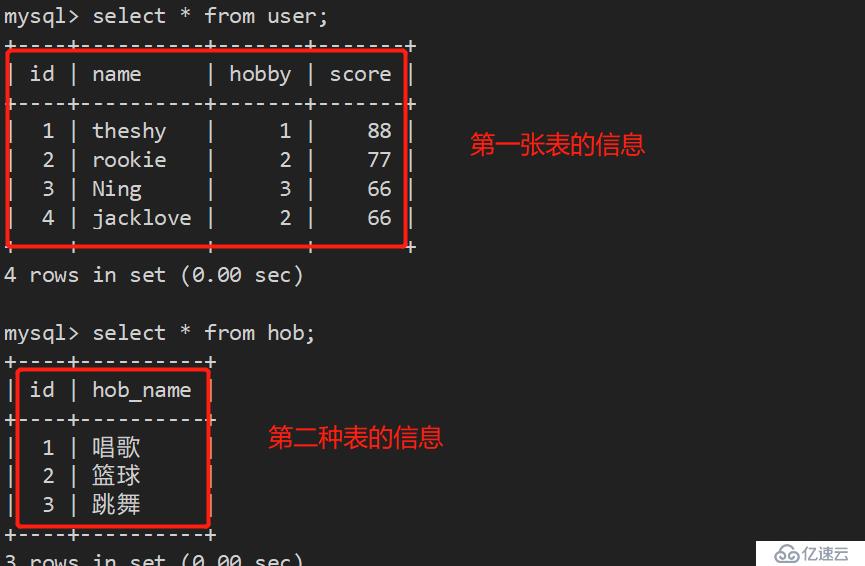
四、两表相连查询:
例如,下面有两张表,第一张名为 user;第二种名为 hob,因为这两张表中有部分信息时相关联的,如何操作:
输入以下命令,将两张表相关联:
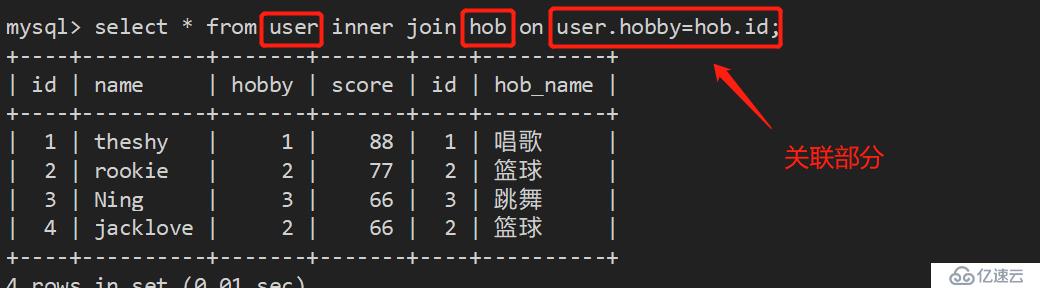
1、直接关联:
mysql> select * from user inner join hob on user.hobby=hob.id;
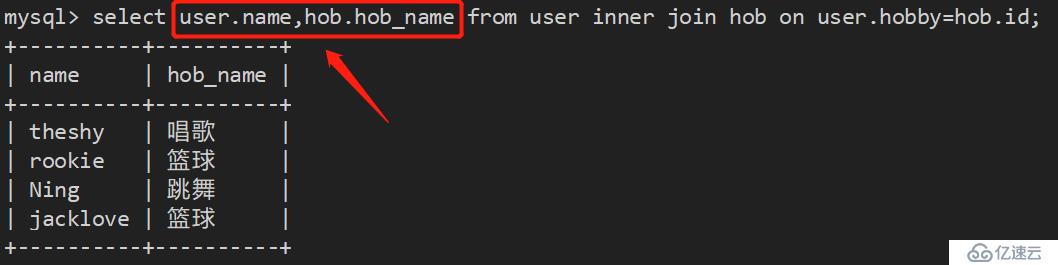
2、还可以按条件关联:
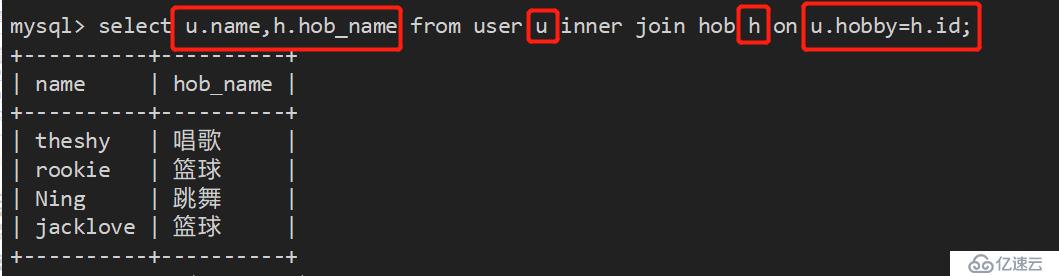
3、如果感觉表名有点长,还可以起别名:
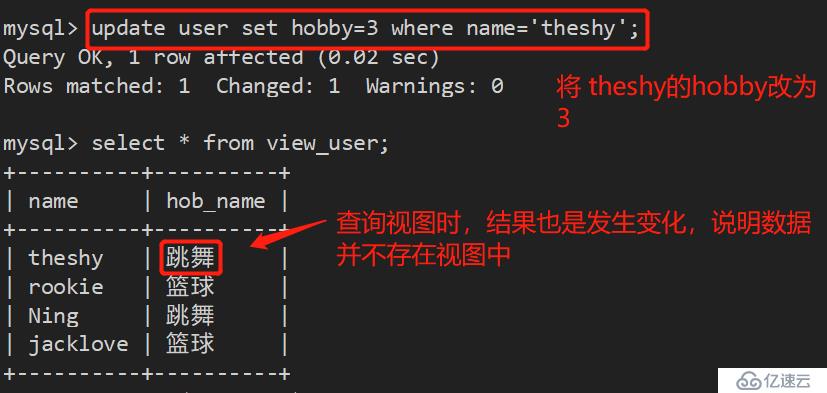
4、创建视图查询:
mysql> create view view_user as select u.name,h.hob_name from user u inner join hob h on u.hobby=h.id;
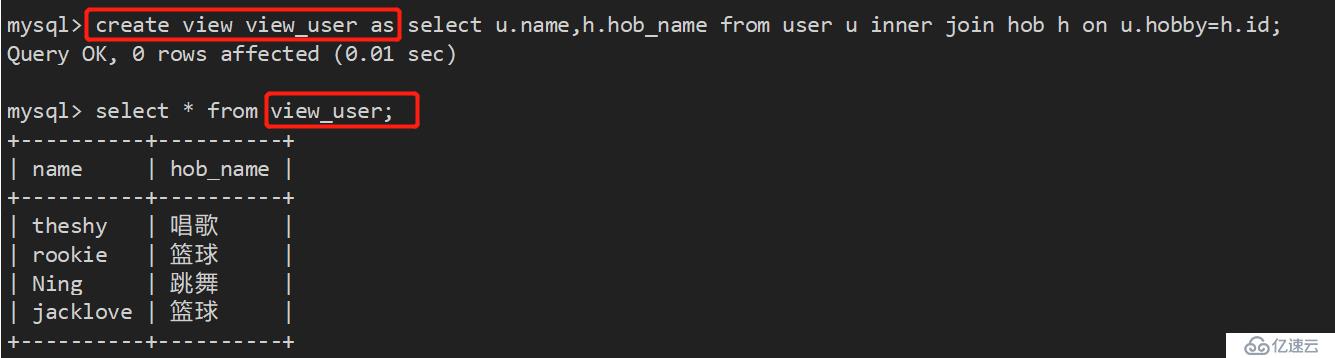
注意:视图是一个虚拟的东西,数据并不存在其中,只是方便用户查询,其作用类似于window桌面的快捷方式。
对于以上关于Mysql中索引、事物及存储引擎的详细介绍,大家是不是觉得非常有帮助。如果需要了解更多内容,请继续关注我们的行业资讯,相信你会喜欢上这些内容的。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





