哈希表
哈希表(Hash Table, 又称为散列表),是一种线性表的存储结构。哈希表由一个直接寻址表和一个哈希函数组成。哈希函数h(k)将元素关键字k作为自变量,返回元素的存储下标。
简单哈希函数:
除法哈希:h(k) = k mod m乘法哈希:h(k) = floor(m(kA mod 1)) 0<A<1
假设有一个长度为7的数组,哈希函数h(k) = k mod 7,元素集合{14, 22, 3, 5}的存储方式如下图:

哈希冲突
由于哈希表的大小是有限的,而要存储的值的总数量是无限的,因此对于任何哈希函数,都会出现两个不同的元素映射到同一个位置上的情况,这种情况叫做哈希冲突。
比如:h(k) = k mod 7, h(0) = h(7) = h(14) = ...
解决哈希冲突--开放寻址法
开放寻址法:如果哈希函数返回的位置已经有值,则可以向后探查新的位置来存储这个值
线性探查:如果位置i被占用,则探查i+1, i+2,...二次探查:如果位置i被占用,则探查i+12, i-12, i+22, i-22,...二度哈希:有n个哈希函数,当使用第一个哈希函数h2发生冲突时,则尝试使用h3, h4,...
解决哈希冲突--拉链法
拉链法:哈希表每一个位置都连接一个链表,当冲突发生时,冲突的元素将被加到该位置链表的最后。
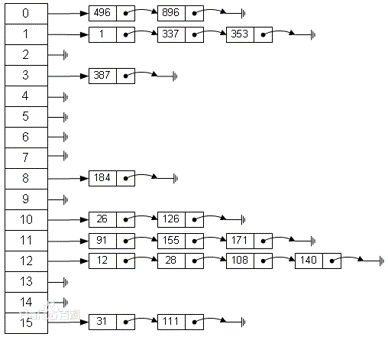
哈希表的实现
class Array(object):
def __init__(self, size=32, init=None):
self._size = size
self._items = [init] * size
def __getitem__(self, index):
return self._items[index]
def __setitem__(self, index, value):
self._items[index] = value
def __len__(self):
return self._size
def clear(self, value=None):
for i in range(len(self._items)):
self._items[i] = value
def __iter__(self):
for item in self._items:
yield item
class Slot(object):
"""
定义一个 hash 表数组的槽(slot 这里指的就是数组的一个位置)
hash table 就是一个数组,每个数组的元素(也叫slot槽)是一个对象,对象包含两个属性 key 和 value。
注意,一个槽有三种状态,看你能否想明白。相比链接法解决冲突,探查法删除一个 key 的操作稍微复杂。
1.从未使用 HashMap.UNUSED。此槽没有被使用和冲突过,查找时只要找到 UNUSED 就不用再继续探查了
2.使用过但是 remove 了,此时是 HashMap.EMPTY,该探查点后边的元素仍然可能是有key的,需要继续查找
3.槽正在使用 Slot 节点
"""
def __init__(self, key, value):
self.key, self.value = key, value
class HashTable(object):
UNUSED = None # 没被使用过
EMPTY = Slot(None, None) # 使用却被删除过
def __init__(self):
self._table = Array(8, init=HashTable.UNUSED) # 保持 2*i 次方
self.length = 0
@property
def _load_factor(self):
# load_factor 超过 0.8 重新分配
return self.length / float(len(self._table))
def __len__(self):
return self.length
# 进行哈希
def _hash(self, key):
return abs(hash(key)) % len(self._table)
# 查找key
def _find_key(self, key):
"""
解释一个 slot 为 UNUSED 和 EMPTY 的区别
因为使用的是二次探查的方式,假如有两个元素 A,B 冲突了,
首先A hash 得到是 slot 下标5,A 放到了第5个槽,之后插入 B 因为冲突了,所以继续根据二次探查方式放到了 slot下标8。
然后删除 A,槽 5 被置为 EMPTY。然后我去查找 B,
第一次 hash 得到的是 槽5,但是这个时候我还是需要第二次计算 hash 才能找到 B。
但是如果槽是 UNUSED 我就不用继续找了,我认为 B 就是不存在的元素。这个就是 UNUSED 和 EMPTY 的区别。
"""
origin_index = index = self._hash(key) # origin_index 判断是否又走到了起点,如果查找一圈了都找不到则无此元素
_len = len(self._table)
while self._table[index] is not HashTable.UNUSED:
if self._table[index] is HashTable.EMPTY: # 注意如果是 EMPTY,继续寻找下一个槽
index = (index * 5 + 1) % _len
if index == origin_index:
break
continue
if self._table[index].key == key: # 找到了key
return index
else:
index = (index * 5 + 1) % _len # 没有找到继续找下一个位置
if index == origin_index:
break
return None
# 找能插入的槽
def _find_slot_for_insert(self, key):
index = self._hash(key)
_len = len(self._table)
while not self._slot_can_insert(index): # 直到找到一个可以用的槽
index = (index * 5 + 1) % _len
return index
# 槽是否能插入
def _slot_can_insert(self, index):
return self._table[index] is HashTable.EMPTY or self._table[index] is HashTable.UNUSED
# in operator,实现之后可以使用 in 操作符判断
def __contains__(self, key):
index = self._find_key(key)
return index is not None
# 添加元素
def add(self, key, value):
if key in self: # update
index = self._find_key(key)
self._table[index].value = value
return False
else:
index = self._find_slot_for_insert(key)
self._table[index] = Slot(key, value)
self.length += 1
if self._load_factor >= 0.8:
self._rehash()
return True
# 槽不够时,重哈希
def _rehash(self):
old_table = self._table
newsize = len(self._table) * 2
self._table = Array(newsize, HashTable.UNUSED)
self.length = 0
for slot in old_table:
if slot is not HashTable.UNUSED and slot is not HashTable.EMPTY:
index = self._find_slot_for_insert(slot.key)
self._table[index] = slot
self.length += 1
# 获取值
def get(self, key, default=None):
index = self._find_key(key)
if index is None:
return default
else:
return self._table[index].value
# 移除
def remove(self, key):
index = self._find_key(key)
if index is None:
raise KeyError()
value = self._table[index].value
self.length -= 1
self._table[index] = HashTable.EMPTY
return value
# 遍历
def __iter__(self):
for slot in self._table:
if slot not in (HashTable.EMPTY, HashTable.UNUSED):
yield slot.key
哈希表的使用
h = HashTable()
h.add('a', 0)
h.add('b', 1)
h.add('c', 2)
print(len(h)) # 3
print(h.get('a')) # 0
print(h.get('b')) # 1
print(h.get('hehe')) # None
h.remove('a')
print(h.get('a')) # None
print(sorted(list(h))) # ['b', 'c']
字典
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值key=>value对用冒号:分割,每个键值对之间用逗号,分割,整个字典包括在花括号{}中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }
基于哈希表实现字典
class Array(object):
def __init__(self, size=32, init=None):
self._size = size
self._items = [init] * size
def __getitem__(self, index):
return self._items[index]
def __setitem__(self, index, value):
self._items[index] = value
def __len__(self):
return self._size
def clear(self, value=None):
for i in range(len(self._items)):
self._items[i] = value
def __iter__(self):
for item in self._items:
yield item
class Slot(object):
"""
定义一个 hash 表数组的槽(slot 这里指的就是数组的一个位置)
hash table 就是一个数组,每个数组的元素(也叫slot槽)是一个对象,对象包含两个属性 key 和 value。
注意,一个槽有三种状态,看你能否想明白。相比链接法解决冲突,探查法删除一个 key 的操作稍微复杂。
1.从未使用 HashMap.UNUSED。此槽没有被使用和冲突过,查找时只要找到 UNUSED 就不用再继续探查了
2.使用过但是 remove 了,此时是 HashMap.EMPTY,该探查点后边的元素仍然可能是有key的,需要继续查找
3.槽正在使用 Slot 节点
"""
def __init__(self, key, value):
self.key, self.value = key, value
class HashTable(object):
UNUSED = None # 没被使用过
EMPTY = Slot(None, None) # 使用却被删除过
def __init__(self):
self._table = Array(8, init=HashTable.UNUSED) # 保持 2*i 次方
self.length = 0
@property
def _load_factor(self):
# load_factor 超过 0.8 重新分配
return self.length / float(len(self._table))
def __len__(self):
return self.length
# 进行哈希
def _hash(self, key):
return abs(hash(key)) % len(self._table)
# 查找key
def _find_key(self, key):
"""
解释一个 slot 为 UNUSED 和 EMPTY 的区别
因为使用的是二次探查的方式,假如有两个元素 A,B 冲突了,
首先A hash 得到是 slot 下标5,A 放到了第5个槽,之后插入 B 因为冲突了,所以继续根据二次探查方式放到了 slot下标8。
然后删除 A,槽 5 被置为 EMPTY。然后我去查找 B,
第一次 hash 得到的是 槽5,但是这个时候我还是需要第二次计算 hash 才能找到 B。
但是如果槽是 UNUSED 我就不用继续找了,我认为 B 就是不存在的元素。这个就是 UNUSED 和 EMPTY 的区别。
"""
origin_index = index = self._hash(key) # origin_index 判断是否又走到了起点,如果查找一圈了都找不到则无此元素
_len = len(self._table)
while self._table[index] is not HashTable.UNUSED:
if self._table[index] is HashTable.EMPTY: # 注意如果是 EMPTY,继续寻找下一个槽
index = (index * 5 + 1) % _len
if index == origin_index:
break
continue
if self._table[index].key == key: # 找到了key
return index
else:
index = (index * 5 + 1) % _len # 没有找到继续找下一个位置
if index == origin_index:
break
return None
# 找能插入的槽
def _find_slot_for_insert(self, key):
index = self._hash(key)
_len = len(self._table)
while not self._slot_can_insert(index): # 直到找到一个可以用的槽
index = (index * 5 + 1) % _len
return index
# 槽是否能插入
def _slot_can_insert(self, index):
return self._table[index] is HashTable.EMPTY or self._table[index] is HashTable.UNUSED
# in operator,实现之后可以使用 in 操作符判断
def __contains__(self, key):
index = self._find_key(key)
return index is not None
# 添加元素
def add(self, key, value):
if key in self: # update
index = self._find_key(key)
self._table[index].value = value
return False
else:
index = self._find_slot_for_insert(key)
self._table[index] = Slot(key, value)
self.length += 1
if self._load_factor >= 0.8:
self._rehash()
return True
# 槽不够时,重哈希
def _rehash(self):
old_table = self._table
newsize = len(self._table) * 2
self._table = Array(newsize, HashTable.UNUSED)
self.length = 0
for slot in old_table:
if slot is not HashTable.UNUSED and slot is not HashTable.EMPTY:
index = self._find_slot_for_insert(slot.key)
self._table[index] = slot
self.length += 1
# 获取值
def get(self, key, default=None):
index = self._find_key(key)
if index is None:
return default
else:
return self._table[index].value
# 移除
def remove(self, key):
index = self._find_key(key)
if index is None:
raise KeyError()
value = self._table[index].value
self.length -= 1
self._table[index] = HashTable.EMPTY
return value
# 遍历
def __iter__(self):
for slot in self._table:
if slot not in (HashTable.EMPTY, HashTable.UNUSED):
yield slot.key
class DictADT(HashTable):
# 执行dict[key]=value时执行
def __setitem__(self, key, value):
self.add(key, value)
# 执行dict[key]时执行
def __getitem__(self, key, default=None):
if key not in self:
raise KeyError()
return self.get(key, default)
# 遍历时执行
def _iter_slot(self):
for slot in self._table:
if slot not in (self.UNUSED, self.EMPTY):
yield slot
# 实现items方法
def items(self):
for slot in self._iter_slot():
yield (slot.key, slot.value)
# 实现keys方法
def keys(self):
for slot in self._iter_slot():
yield slot.key
# 实现values方法
def values(self):
for slot in self._iter_slot():
yield slot.value
字典的使用
d = DictADT() d['a'] = 1 print(d['a']) # 1
集合
集合是一种不包含重复元素的数据结构,经常用来判断是否重复这种操作,或者集合中是否存在一个元素。
集合可能最常用的就是去重,判断是否存在一个元素等,但是 set 相比 dict 有更丰富的操作,主要是数学概念上的。
如果你学过《离散数学》中集合相关的概念,基本上是一致的。 python 的 set 提供了如下基本的集合操作, 假设有两个集合 A,B,有以下操作
基于哈希表实现集合
class Array(object):
def __init__(self, size=32, init=None):
self._size = size
self._items = [init] * size
def __getitem__(self, index):
return self._items[index]
def __setitem__(self, index, value):
self._items[index] = value
def __len__(self):
return self._size
def clear(self, value=None):
for i in range(len(self._items)):
self._items[i] = value
def __iter__(self):
for item in self._items:
yield item
class Slot(object):
"""
定义一个 hash 表数组的槽(slot 这里指的就是数组的一个位置)
hash table 就是一个数组,每个数组的元素(也叫slot槽)是一个对象,对象包含两个属性 key 和 value。
注意,一个槽有三种状态,看你能否想明白。相比链接法解决冲突,探查法删除一个 key 的操作稍微复杂。
1.从未使用 HashMap.UNUSED。此槽没有被使用和冲突过,查找时只要找到 UNUSED 就不用再继续探查了
2.使用过但是 remove 了,此时是 HashMap.EMPTY,该探查点后边的元素仍然可能是有key的,需要继续查找
3.槽正在使用 Slot 节点
"""
def __init__(self, key, value):
self.key, self.value = key, value
class HashTable(object):
UNUSED = None # 没被使用过
EMPTY = Slot(None, None) # 使用却被删除过
def __init__(self):
self._table = Array(8, init=HashTable.UNUSED) # 保持 2*i 次方
self.length = 0
@property
def _load_factor(self):
# load_factor 超过 0.8 重新分配
return self.length / float(len(self._table))
def __len__(self):
return self.length
# 进行哈希
def _hash(self, key):
return abs(hash(key)) % len(self._table)
# 查找key
def _find_key(self, key):
"""
解释一个 slot 为 UNUSED 和 EMPTY 的区别
因为使用的是二次探查的方式,假如有两个元素 A,B 冲突了,
首先A hash 得到是 slot 下标5,A 放到了第5个槽,之后插入 B 因为冲突了,所以继续根据二次探查方式放到了 slot下标8。
然后删除 A,槽 5 被置为 EMPTY。然后我去查找 B,
第一次 hash 得到的是 槽5,但是这个时候我还是需要第二次计算 hash 才能找到 B。
但是如果槽是 UNUSED 我就不用继续找了,我认为 B 就是不存在的元素。这个就是 UNUSED 和 EMPTY 的区别。
"""
origin_index = index = self._hash(key) # origin_index 判断是否又走到了起点,如果查找一圈了都找不到则无此元素
_len = len(self._table)
while self._table[index] is not HashTable.UNUSED:
if self._table[index] is HashTable.EMPTY: # 注意如果是 EMPTY,继续寻找下一个槽
index = (index * 5 + 1) % _len
if index == origin_index:
break
continue
if self._table[index].key == key: # 找到了key
return index
else:
index = (index * 5 + 1) % _len # 没有找到继续找下一个位置
if index == origin_index:
break
return None
# 找能插入的槽
def _find_slot_for_insert(self, key):
index = self._hash(key)
_len = len(self._table)
while not self._slot_can_insert(index): # 直到找到一个可以用的槽
index = (index * 5 + 1) % _len
return index
# 槽是否能插入
def _slot_can_insert(self, index):
return self._table[index] is HashTable.EMPTY or self._table[index] is HashTable.UNUSED
# in operator,实现之后可以使用 in 操作符判断
def __contains__(self, key):
index = self._find_key(key)
return index is not None
# 添加元素
def add(self, key, value):
if key in self: # update
index = self._find_key(key)
self._table[index].value = value
return False
else:
index = self._find_slot_for_insert(key)
self._table[index] = Slot(key, value)
self.length += 1
if self._load_factor >= 0.8:
self._rehash()
return True
# 槽不够时,重哈希
def _rehash(self):
old_table = self._table
newsize = len(self._table) * 2
self._table = Array(newsize, HashTable.UNUSED)
self.length = 0
for slot in old_table:
if slot is not HashTable.UNUSED and slot is not HashTable.EMPTY:
index = self._find_slot_for_insert(slot.key)
self._table[index] = slot
self.length += 1
# 获取值
def get(self, key, default=None):
index = self._find_key(key)
if index is None:
return default
else:
return self._table[index].value
# 移除
def remove(self, key):
index = self._find_key(key)
if index is None:
raise KeyError()
value = self._table[index].value
self.length -= 1
self._table[index] = HashTable.EMPTY
return value
# 遍历
def __iter__(self):
for slot in self._table:
if slot not in (HashTable.EMPTY, HashTable.UNUSED):
yield slot.key
class SetADT(HashTable):
# 添加元素
def add(self, key):
super().add(key, True)
def __and__(self, other_set):
"""交集 A&B"""
new_set = SetADT()
for element_a in self:
if element_a in other_set:
new_set.add(element_a)
return new_set
def __sub__(self, other_set):
"""差集 A-B"""
new_set = SetADT()
for element_a in self:
if element_a not in other_set:
new_set.add(element_a)
return new_set
def __or__(self, other_set):
"""并集 A|B"""
new_set = SetADT()
for element_a in self:
new_set.add(element_a)
for element_b in other_set:
new_set.add(element_b)
return new_set
集合的使用
sa = SetADT() sa.add(1) sa.add(2) sa.add(3) sb = SetADT() sb.add(3) sb.add(4) sb.add(5) print(sorted(list(sa & sb))) # [3] print(sorted(list(sa - sb))) # [1, 2] print(sorted(list(sa | sb))) # [1, 2, 3, 4, 5]
总结
以上所述是小编给大家介绍的使用python实现哈希表、字典、集合操作,希望对大家有所帮助!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





