什么是倒排索引?
倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
假设我们现在有文件:
test1.txt中存有:我们爱自然语言处理
test2.txt中存有:我们爱计算机视觉
正向索引:
{“test1.txt”:["我们",“爱”,"自然语言","处理"],"test2.txt":["我们","爱","计算机","视觉"]}
那么,我们应该如何通过正向索引找到包含某词语的文件呢?我们只能依次遍历文件中的内容,从内容中找到是否有该词语,正向查询的效率很低。
倒排索引:
{"我们":["test1.txt","test2.txt"],"爱":["test1.txt","test2.txt"],"自然语言":["test1.txt"],"处理":["test1.txt"],"计算机":["test2.txt"],"视觉":["test2.txt"]}
建立倒排索引后,我们要想查找包含某些单词的文件,直接从hash表中获取,是不是就方便多了?接下来,我们用python实现:
现在有基本目录:

python.txt
Python的设计哲学是“优雅”、“明确”、“简单”。因此,Perl语言中“总是有多种方法来做同一件事”的理念在Python开发者中通常是难以忍受的。Python开发者的哲学是“用一种方法,最好是只有一种方法来做一件事”。在设计Python语言时,如果面临多种选择,Python开发者一般会拒绝花俏的语法,而选择明确的没有或者很少有歧义的语法。由于这种设计观念的差异,Python源代码通常被认为比Perl具备更好的可读性,并且能够支撑大规模的软件开发。这些准则被称为Python格言。在Python解释器内运行import this可以获得完整的列表。
Python开发人员尽量避开不成熟或者不重要的优化。一些针对非重要部位的加快运行速度的补丁通常不会被合并到Python内。所以很多人认为Python很慢。不过,根据二八定律,大多数程序对速度要求不高。在某些对运行速度要求很高的情况,Python设计师倾向于使用JIT技术,或者用使用C/C++语言改写这部分程序。可用的JIT技术是PyPy。
Python是完全面向对象的语言。函数、模块、数字、字符串都是对象。并且完全支持继承、重载、派生、多继承,有益于增强源代码的复用性。Python支持重载运算符和动态类型。相对于Lisp这种传统的函数式编程语言,Python对函数式设计只提供了有限的支持。有两个标准库(functools, itertools)提供了Haskell和Standard ML中久经考验的函数式程序设计工具。
java.txt
1.简单性
Java看起来设计得很像C++,但是为了使语言小和容易熟悉,设计者们把C++语言中许多可用的特征去掉了,这些特征是一般程序员很少使用的。例如,Java不支持go to语句,代之以提供break和continue语句以及异常处理。Java还剔除了C++的操作符过载(overload)和多继承特征,并且不使用主文件,免去了预处理程序。因为Java没有结构,数组和串都是对象,所以不需要指针。Java能够自动处理对象的引用和间接引用,实现自动的无用单元收集,使用户不必为存储管理问题烦恼,能更多的时间和精力花在研发上。
2.面向对象
Java是一个面向对象的语言。对程序员来说,这意味着要注意应中的数据和操纵数据的方法(method),而不是严格地用过程来思考。在一个面向对象的系统中,类(class)是数据和操作数据的方法的集合。数据和方法一起描述对象(object)的状态和行为。每一对象是其状态和行为的封装。类是按一定体系和层次安排的,使得子类可以从超类继承行为。在这个类层次体系中有一个根类,它是具有一般行为的类。Java程序是用类来组织的。
Java还包括一个类的扩展集合,分别组成各种程序包(Package),用户可以在自己的程序中使用。例如,Java提供产生图形用户接口部件的类(java.awt包),这里awt是抽象窗口工具集(abstract windowing toolkit)的缩写,处理输入输出的类(java.io包)和支持网络功能的类(java.net包)。
3.分布性
Java设计成支持在网络上应用,它是分布式语言。Java既支持各种层次的网络连接,又以Socket类支持可靠的流(stream)网络连接,所以用户可以产生分布式的客户机和服务器。
网络变成软件应用的分布运载工具。Java程序只要编写一次,就可到处运行。
c.txt
C语言是一种结构化语言,它有着清晰的层次,可按照模块的方式对程序进行编写,十分有利于程序的调试,且c语言的处理和表现能力都非常的强大,依靠非常全面的运算符和多样的数据类型,可以轻易完成各种数据结构的构建,通过指针类型更可对内存直接寻址以及对硬件进行直接操作,因此既能够用于开发系统程序,也可用于开发应用软件。通过对C语言进行研究分析,总结出其主要特点如下:
(1)简洁的语言
C语言包含有各种控制语句仅有9种,关键字也只有32 个,程序的编写要求不严格且多以小写字母为主,对许多不必要的部分进行了精简。实际上,语句构成与硬件有关联的较少,且C语言本身不提供与硬件相关的输入输出、文件管理等功能,如需此类功能,需要通过配合编译系统所支持的各类库进行编程,故c语言拥有非常简洁的编译系统。 [5]
(2)具有结构化的控制语句
C语言是一种结构化的语言,提供的控制语句具有结构化特征,如for语句、if⋯else语句和switch语句等。可以用于实现函数的逻辑控制,方便面向过程的程序设计。 [5]
(3)丰富的数据类型
C语言包含的数据类型广泛,不仅包含有传统的字符型、整型、浮点型、数组类型等数据类型,还具有其他编程语言所不具备的数据类型,其中以指针类型数据使用最为灵活,可以通过编程对各种数据结构进行计算。 [5]
(4)丰富的运算符
C语言包含34个运算符,它将赋值、括号等均视作运算符来操作,使C程序的表达式类型和运算符类型均非常丰富。 [5]
(5)可对物理地址进行直接操作
C语言允许对硬件内存地址进行直接读写,以此可以实现汇编语言的主要功能,并可直接操作硬件。C语言不但具备高级语言所具有的良好特性,又包含了许多低级语言的优势,故在系统软件编程领域有着广泛的应用。 [5]
(6)代码具有较好的可移植性
C语言是面向过程的编程语言,用户只需要关注所被解决问题的本身,而不需要花费过多的精力去了解相关硬件,且针对不同的硬件环境,在用C语言实现相同功能时的代码基本一致,不需或仅需进行少量改动便可完成移植,这就意味着,对于一台计算机编写的C程序可以在另一台计算机上轻松地运行,从而极大的减少了程序移植的工作强度。 [5]
(7)可生成的高质量目标代码,高执行效率的程序
复制代码
首先,我们导入相应的包:#用于获取该目录下得所有txt文件,忽略掉文件夹及里面的
import glob
#主要是一些路径的操作
import os
#对句子进行分词或关键词提取
from jieba import analyse
接下来,我们要获取所有txt文件的绝对路径:
#获取当前pyhtho文件所在的目录:当前是:C:\gongoubo\python-work\direc\files
dir_path = os.path.dirname(os.path.abspath(__file__))
print(dir_path)
#存储txt文件的绝对路径为列表,同时为每个文件建立索引
def file_store():
files_name =[]
files_dict = {}
#获取file文件夹下所有为txt的文件
for i,name in enumerate(glob.glob("file/*.txt")):
files_dict[i] = name.split('\\')[-1]
file_name = dir_path + "\\" + name
files_name.append(file_name)
return files_name,files_dict
然后,我们读取每个txt文件,再对其进行关键词提取,将结果存储到新的txt中,并用原txt文件的索引命名:
#读取每个txt文件
def transform(files_name):
#注意打开的时候需要申明为utf-8编码
for i,j in enumerate(files_name):
#打开文件
tmp = open(j,'r',encoding='utf-8').read()
#提取关键词
content = analyse.extract_tags(tmp)
#也可以进行分词content=jieba.cut_for_search(tmp),关于jieba分词,可以看我的自然语言处理之基础技能
#新建process文件夹
path=dir_path+'\\file\\'+'process'
if not os.path.exists(path):
os.makedirs(path)
#为存储关键词的txt取名,对应这每个文件的索引
fp=open(path+'\\'+str(i)+'.txt','w',encoding='utf-8')
#将关键词写入到txt中
fp.write(" ".join(content))
fp.close()
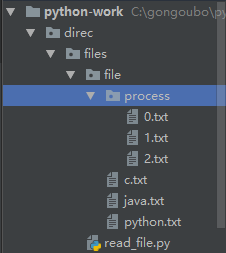
运行后,我们会有如下目录:其中process文件夹下的是提取关键词后的结果,文件名对应索引,即{0:"c.txt",1:"java.txt",2:"python.txt"}
接下来,进行倒排索引的构建:
#建立倒排索引
def invert_index():
path=dir_path+'\\file\\'+'process'
word_dict = {}
# 取包含关键词的txt
for file in glob.glob(path+'/*.txt'):
#取出txt文件名,也就是文件的索引
index = file.split('\\')[-1][0]
#打开文件,并将关键词存储为列表
with open(file,'r',encoding='utf-8') as fp:
word_list=fp.read().split(" ")
#建立倒排索引,如果单词不在单词字典中,就存储文件的索引,否则就添加索引到索引列表后
for word in word_list:
if word not in word_dict:
word_dict[word]=[index]
else:
word_dict[word].append(index)
return word_dict
基本的内容我们有了,再考虑我们的输入,我们希望实现在控制台输入几个单词,找到最符合的几个文件。我们将输入存储为单词列表,以此判断该单词是否出现在文件中,如果出现了,我们将该单词对应的文件的索引+1,否则继续判断下一个单词。之后我们得到了关于文件索引次数的字典,我们按次数从大到小排列,然后取前几个作为我们最后的结果。当然,我们需要的是原始的文件名,因此,我们还要将索引映射回文件名,相关代码如下:
def get_topk(count,topk=None):
print(count)
file_index = []
#如果topk超出了返回的数目,则有多少显示多少
if topk > len(count):
for i in range(0,len(count)):
file_index.append(int(count[i][0]))
return file_index
if len(count)<0:
print("没有找到相关的文件")
return False
else:
for i in range(0,topk):
file_index.append(int(count[i][0]))
return file_index
#得到文件名
def get_files(file_index,files_dict):
res=[]
for i in file_index:
res.append(files_dict[i])
return res
主函数:
def main():
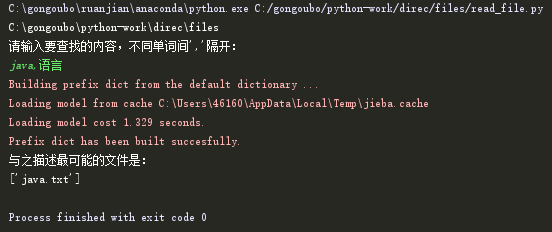
print("请输入要查找的内容,不同单词间','隔开:")
words = input().split(',')
#获得文件名和文件名索引字典
files_name, files_dict = file_store()
#提取关键词或分词
transform(files_name)
#倒排索引建立
word_dict = invert_index()
count={}
#统计文件索引的次数
for word in words:
if word in word_dict:
for file in word_dict[word]:
if file not in count:
count[file]=1
else:
count[file]+=1
else:
continue
#按次数从大到小排列
count=sorted(count.items(),key=lambda i:i[1],reverse=True)
#返回前k个文件索引
file_index=get_topk(count,topk=3)
if file_index != False:
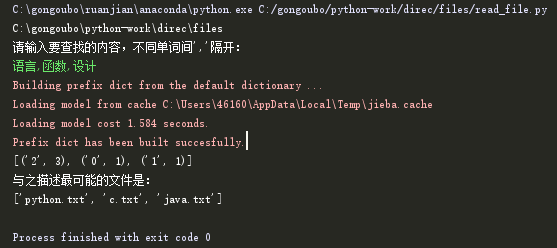
print("与之描述最可能的文件是:")
#返回文件名,并输出结果
res=get_files(file_index,files_dict)
print(res)
最后,我们运行主函数:
if __name__ == '__main__': main()
最终结果:
我们将topk改为3:
总结
以上所述是小编给大家介绍的Python倒排索引之查找包含某主题或单词的文件,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对亿速云网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





