这篇文章主要介绍了怎么使用Docker Swarm搭建分布式爬虫集群,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
在爬虫开发过程中,你肯定遇到过需要把爬虫部署在多个服务器上面的情况。此时你是怎么操作的呢?逐一SSH登录每个服务器,使用git拉下代码,然后运行?代码修改了,于是又要一个服务器一个服务器登录上去依次更新?
有时候爬虫只需要在一个服务器上面运行,有时候需要在200个服务器上面运行。你是怎么快速切换的呢?一个服务器一个服务器登录上去开关?或者聪明一点,在Redis里面设置一个可以修改的标记,只有标记对应的服务器上面的爬虫运行?
A爬虫已经在所有服务器上面部署了,现在又做了一个B爬虫,你是不是又得依次登录每个服务器再一次部署?
如果你确实是这么做的,那么你应该后悔没有早一点看到这篇文章。看完本文以后,你能够做到:
2分钟内把一个新爬虫部署到50台服务器上:
docker build -t localhost:8003/spider:0.01 . docker push localhost:8002/spider:0.01 docker service create --name spider --replicas 50 --network host 45.77.138.242:8003/spider:0.01
30秒内把爬虫从50台服务器扩展到500台服务器:
docker service scale spider=500
30秒内批量关闭所有服务器上的爬虫:
docker service scale spider=0
1分钟内批量更新所有机器上的爬虫:
docker build -t localhost:8003/spider:0.02 . docker push localhost:8003/spider:0.02 docker service update --image 45.77.138.242:8003/spider:0.02 spider
这篇文章不会教你怎么使用Docker,所以请确定你有一些Docker基础再来看本文。
Docker Swarm是什么
Docker Swarm是Docker自带的一个集群管理模块。他能够实现Docker集群的创建和管理。
环境搭建
本文将会使用3台Ubuntu 18.04的服务器来进行演示。这三台服务器安排如下:
Master:45.77.138.242
Slave-1:199.247.30.74
Slave-2:95.179.143.21
Docker Swarm是基于Docker的模块,所以首先要在3台服务器上安装Docker。安装完成Docker以后,所有的操作都在Docker中完成。
在Master上安装Docker
通过依次执行下面的命令,在Master服务器上安装Docker
apt-get update
apt-get install -y apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu bionic stable"
apt-get update
apt-get install -y docker-ce创建Manager节点
一个Docker Swarm集群需要Manager节点。现在初始化Master服务器,作为集群的Manager节点。运行下面一条命令。
docker swarm init运行完成以后,可以看到的返回结果下图所示。
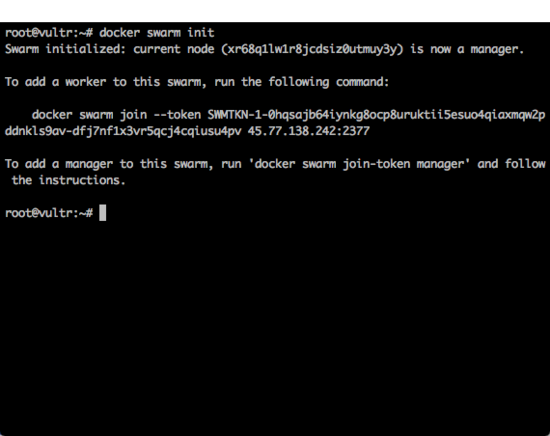
这个返回结果中,给出了一条命令:
复制代码 代码如下:
docker swarm join --token SWMTKN-1-0hqsajb64iynkg8ocp8uruktii5esuo4qiaxmqw2pddnkls9av-dfj7nf1x3vr5qcj4cqiusu4pv 45.77.138.242:2377
这条命令需要在每一个从节点(Slave)中执行。现在先把这个命令记录下来。
初始化完成以后,得到一个只有1台服务器的Docker 集群。执行如下命令:
docker node ls可以看到当前这个集群的状态,如下图所示。

创建私有源(可选)
创建私有源并不是一个必需的操作。之所以需要私有源,是因为项目的Docker镜像可能会涉及到公司机密,不能上传到DockerHub这种公共平台。如果你的镜像可以公开上传DockerHub,或者你已经有一个可以用的私有镜像源,那么你可以直接使用它们,跳过本小节和下一小节。
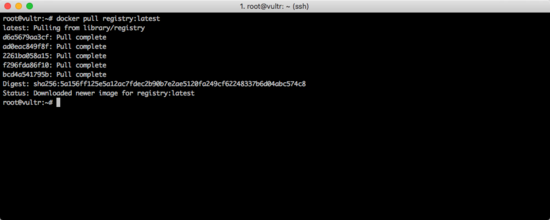
私有源本身也是一个Docker的镜像,先将拉取下来:
docker pull registry:latest
如下图所示。
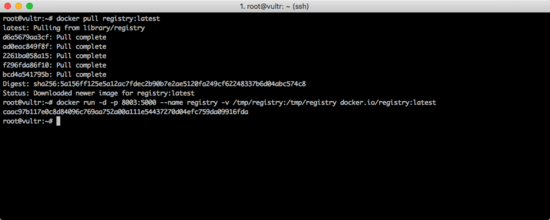
现在启动私有源:
复制代码 代码如下:
docker run -d -p 8003:5000 --name registry -v /tmp/registry:/tmp/registry docker.io/registry:latest
如下图所示。
在启动命令中,设置了对外开放的端口为8003端口,所以私有源的地址为:45.77.138.242:8003
提示:
这样搭建的私有源是HTTP方式,并且没有权限验证机制,所以如果对公网开放,你需要再使用防火墙做一下IP白名单,从而保证数据的安全。
允许docker使用可信任的http私有源(可选)
如果你使用上面一个小节的命令搭建了自己的私有源,由于Docker默认是不允许使用HTTP方式的私有源的,因此你需要配置Docker,让Docker信任它。
使用下面命令配置Docker:
echo '{ "insecure-registries":["45.77.138.242:8003"] }' >> /etc/docker/daemon.json然后使用下面这个命令重启docker。
systemctl restart docker
如下图所示。

重启完成以后,Manager节点就配置好了。
创建子节点初始化脚本
对于Slave服务器来说,只需要做三件事情:
安装Docker
加入集群
信任源
从此以后,剩下的事情全部交给Docker Swarm自己管理,你再也不用SSH登录这个服务器了。
为了简化操作,可以写一个shell脚本来批量运行。在Slave-1和Slave-2服务器下创建一个 init.sh 文件,其内容如下。
apt-get update
apt-get install -y apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu bionic stable"
apt-get update
apt-get install -y docker-ce
echo '{ "insecure-registries":["45.77.138.242:8003"] }' >> /etc/docker/daemon.json
systemctl restart docker
docker swarm join --token SWMTKN-1-0hqsajb64iynkg8ocp8uruktii5esuo4qiaxmqw2pddnkls9av-dfj7nf1x3vr5qcj4cqiusu4pv 45.77.138.242:2377把这个文件设置为可自行文件,并运行:
chmod +x init.sh
./init.sh如下图所示。
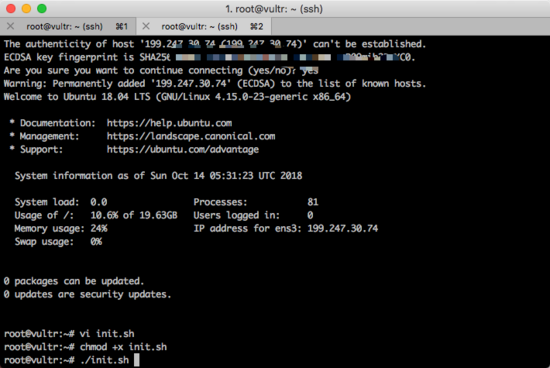
等待脚本运行完成以后,你就可以从Slave-1和Slave-2的SSH上面登出了。以后也不需要再进来了。
回到Master服务器,执行下面的命令,来确认现在集群已经有3个节点了:
docker node ls看到现在集群中已经有3个节点了。如下图所示。

到止为止,最复杂最麻烦的过程已经结束了。剩下的就是体验Docker Swarm带来的便利了。
创建测试程序
搭建测试Redis
由于这里需要模拟一个分布式爬虫的运行效果,所以先使用Docker搭建一个临时的Redis服务:
在Master服务器上执行以下命令:
复制代码 代码如下:
docker run -d --name redis -p 7891:6379 redis --requirepass "KingnameISHandSome8877"
这个Redis对外使用 7891 端口,密码为 KingnameISHandSome8877 ,IP就是Master服务器的IP地址。
编写测试程序
编写一个简单的Python程序:
import time
import redis
client = redis.Redis(host='45.77.138.242', port='7891', password='KingnameISHandSome8877')
while True:
data = client.lpop('example:swarm:spider')
if not data:
break
print(f'我现在获取的数据为:{data.decode()}')
time.sleep(10)这个Python每10秒钟从Redis中读取一个数,并打印出来。
编写Dockerfile
编写Dockerfile,基于Python3.6的镜像创建我们自己的镜像:
from python:3.6
label mantainer='[email protected]'
user root
ENV PYTHONUNBUFFERED=0
ENV PYTHONIOENCODING=utf-8
run python3 -m pip install redis
copy spider.py spider.py
cmd python3 spider.py构建镜像
编写完成Dockerfile以后,执行下面的命令,开始构建我们自己的镜像:
docker build -t localhost:8003/spider:0.01 .
这里需要特别注意,由于我们要把这个镜像上传到私有源供Slave服务器上面的从节点下载,所以镜像的命名方式需要满足 localhost:8003/自定义名字:版本号 这样的格式。其中的 自定义名字 和 版本号 可以根据实际情况进行修改。在本文的例子中,我由于要模拟一个爬虫的程序,所以给它取名为spider,由于是第1次构建,所以版本号用的是0.01。
整个过程如下图所示。
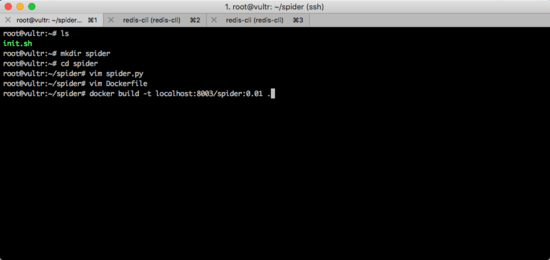
上传镜像到私有源
镜像构建完成以后,需要把它上传到私有源。此时需要执行命令:
docker push localhost:8003/spider:0.01
如下图所示。
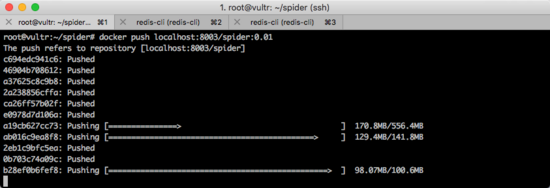
大家记住这个构建和上传的命令,以后每一次更新代码,都需要使用这两条命令。
创建服务
Docker Swarm上面运行的是一个一个的服务,因此需要使用docker service命令创建服务。
复制代码 代码如下:
docker service create --name spider --network host 45.77.138.242:8003/spider:0.01
这个命令创建了一个名为 spider 的服务。默认运行1个容器。运行情况如下图所示。

当然也可以一创建就用很多容器来运行,此时只需要添加一个 --replicas 参数即可。例如一创建服务就使用50个容器运行:
复制代码 代码如下:
docker service create --name spider --replicas 50 --network host 45.77.138.242:8003/spider:0.01
但是一般一开始的代码可能会有不少bug,所以建议先使用1个容器来运行,观察日志,发现没有问题以后再进行扩展。
回到默认1个容器的情况下,这个容器可能在目前三台机器在的任何一台上面。通过执行下面的命令来观察这一个默认的容器运行情况:
docker service ps spider
如下图所示。

查看节点Log
根据上图执行结果,可以看到这个运行中的容器的ID为 rusps0ofwids ,那么执行下面的命令动态查看Log:
docker service logs -f 容器ID
此时就会持续跟踪这一个容器的Log。如下图所示。
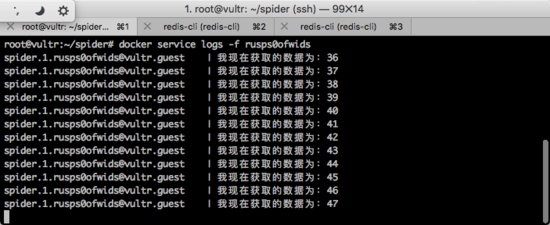
横向扩展
现在,只有1台服务器运行了一个容器,我想使用3台服务器运行这个爬虫,那么我需要执行一条命令即可:
docker service scale spider=3
运行效果如下图所示。
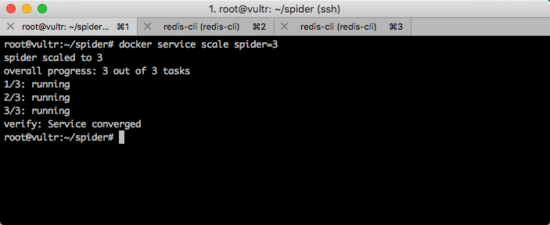
此时,再一次查看爬虫的运行情况,可以发现三台机器上面会各自运行一个容器。如下图所示。

现在,我们登录slave-1机器上,看看是不是真的有一个任务在运行。如下图所示。
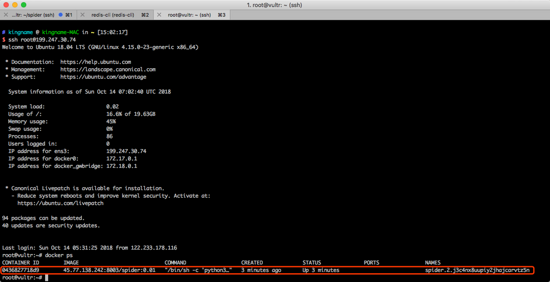
可以看到确实有一个容器在上面运行着。这是Docker Swarm自动分配过来的。
现在我们使用下面的命令强行把slave-1上面的Docker给关了,再来看看效果。
systemctl stop docker回到master服务器,再次查看爬虫的运行效果,如下图所示。

可以看到,Docker Swarm探测到Slave-1掉线以后,他就会自动重新找个机器启动任务,保证始终有3个任务在运行。在这一次的例子中,Docker Swarm自动在master机器上启动了2个spider容器。
如果机器性能比较好,甚至可以在3每台机器上面多运行几个容器:
docker service scale spider=10
此时,就会启动10个容器来运行这些爬虫。这10个爬虫之间互相隔离。
如果想让所有爬虫全部停止怎么办?非常简单,一条命令:
docker service scale spider=0
这样所有爬虫就会全部停止。
同时查看多个容器的日志
如果想同时看所有容器怎么办呢?可以使用如下命令查看所有容器的最新的20行日志:
docker service ps robot | grep Running | awk '{print $1}' | xargs -i docker service logs --tail 20 {}这样,日志就会按顺序显示出来了。如下图所示。

更新爬虫
如果你的代码做了修改。那么你需要更新爬虫。
先修改代码,重新构建,重新提交新的镜像到私有源中。如下图所示。
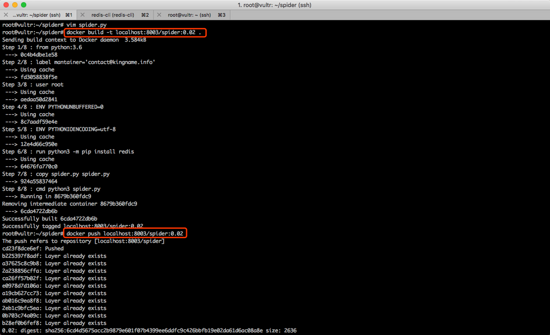
接下来需要更新服务中的镜像。更新镜像有两种做法。一种是先把所有爬虫关闭,再更新。
docker service scale spider=0
docker service update --image 45.77.138.242:8003/spider:0.02 spider
docker service scale spider=3第二种是直接执行更新命令。
docker service update --image 45.77.138.242:8003/spider:0.02 spider他们的区别在于,直接执行更新命令时,正在运行的容器会一个一个更新。
运行效果如下图所示。
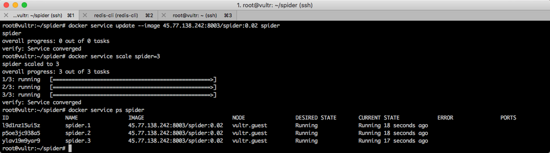
你可以用Docker Swarm做更多事情
本文使用的是一个模拟爬虫的例子,但是显然,任何可以批量运行的程序都能够用Docker Swarm来运行,无论你用Redis还是Celery来通信,无论你是否需要通信,只要能批量运行,就能用Docker Swarm。
在同一个Swarm集群里面,可以运行多个不同的服务,各个服务之间互不影响。真正做到了搭建一次Docker Swarm集群,然后就再也不用管了,以后的所有操作你都只需要在Manager节点所在的这个服务器上面运行。
感谢你能够认真阅读完这篇文章,希望小编分享的“怎么使用Docker Swarm搭建分布式爬虫集群”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



