今天就跟大家聊聊有关利用代理IP怎么实现一个Python爬虫,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
获取 IP
代理池使用 Flask 提供了获取的接口:http://localhost:5555/random
只要访问这个接口再返回内容就可以拿到 IP 了
Urllib
先看一下 Urllib 的代理设置方法:
from urllib.error import URLError
import urllib.request
from urllib.request import ProxyHandler, build_opener
# 获取IP
ip_response = urllib.request.urlopen("http://localhost:5555/random")
ip = ip_response.read().decode('utf-8')
proxy_handler = ProxyHandler({
'http': 'http://' + ip,
'https': 'https://' + ip
})
opener = build_opener(proxy_handler)
try:
response = opener.open('http://httpbin.org/get')
print(response.read().decode('utf-8'))
except URLError as e:
print(e.reason)运行结果:
{
"args": {},
"headers": {
"Accept-Encoding": "identity",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.7"
},
"origin": "108.61.201.231, 108.61.201.231",
"url": "https://httpbin.org/get"
}Urllib 使用 ProxyHandler 设置代理,参数是字典类型,键名为协议类型,键值是代理,代理前面需要加上协议,即 http 或 https,当请求的链接是 http 协议的时候,它会调用 http 代理,当请求的链接是 https 协议的时候,它会调用https代理,所以此处生效的代理是:http://108.61.201.231 和 https://108.61.201.231
ProxyHandler 对象创建之后,再利用 build_opener() 方法传入该对象来创建一个 Opener,这样就相当于此 Opener 已经设置好代理了,直接调用它的 open() 方法即可使用此代理访问链接
Requests
Requests 的代理设置只需要传入 proxies 参数:
import requests
# 获取IP
ip_response = requests.get("http://localhost:5555/random")
ip = ip_response.text
proxies = {
'http': 'http://' + ip,
'https': 'https://' + ip,
}
try:
response = requests.get('http://httpbin.org/get', proxies=proxies)
print(response.text)
except requests.exceptions.ConnectionError as e:
print('Error', e.args)运行结果:
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.21.0"
},
"origin": "47.90.28.54, 47.90.28.54",
"url": "https://httpbin.org/get"
}Requests 只需要构造代理字典然后通过 proxies 参数即可设置代理,比较简单
Selenium
import requests
from selenium import webdriver
import time
# 借助requests库获取IP
ip_response = requests.get("http://localhost:5555/random")
ip = ip_response.text
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=http://' + ip)
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('http://httpbin.org/get')
time.sleep(5)运行结果:
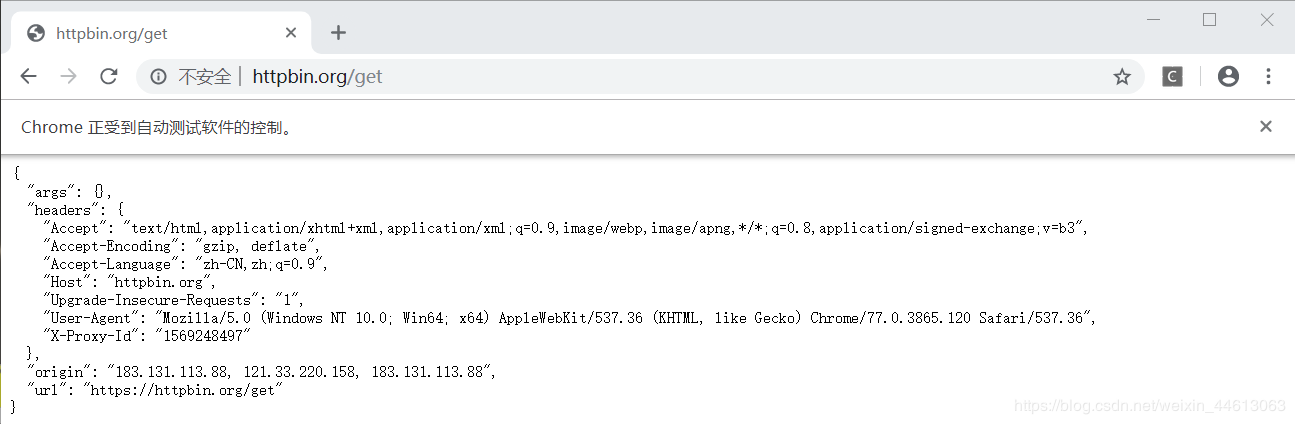
看完上述内容,你们对利用代理IP怎么实现一个Python爬虫有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务


