这篇文章主要介绍了python中Pandas对数据集随机抽样的案例分析,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
摘要:有时候我们只需要数据集中的一部分,并不需要全部的数据。这个时候我们就要对数据集进行随机的抽样。pandas中自带有抽样的方法。
应用场景:
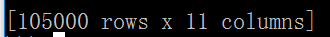
我有10W行数据,每一行都11列的属性。
现在,我们只需要随机抽取其中的2W行。
实现方法很简单:
利用Pandas库中的sample。
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
n是要抽取的行数。(例如n=20000时,抽取其中的2W行)
frac是抽取的比列。(有一些时候,我们并对具体抽取的行数不关系,我们想抽取其中的百分比,这个时候就可以选择使用frac,例如frac=0.8,就是抽取其中80%)
replace:是否为有放回抽样,取replace=True时为有放回抽样。
weights这个是每个样本的权重,具体可以看官方文档说明。
random_state这个在之前的文章已经介绍过了。
axis是选择抽取数据的行还是列。axis=0的时是抽取行,axis=1时是抽取列(也就是说axis=1时,在列中随机抽取n列,在axis=0时,在行中随机抽取n行)
具体用法:
假设DataFrame为df
import pandas as pd
df.sample(n=20000)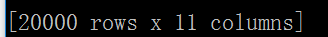
另外,介绍一种不是Pandas中的方法。如果想用Numpy这个库进行也可以。
import numpy as np
np.random.sample(Your_index)感谢你能够认真阅读完这篇文章,希望小编分享的“python中Pandas对数据集随机抽样的案例分析”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



