什么是推荐系统
维基百科这样解释道:推荐系统属于资讯过滤的一种应用。推荐系统能够将可能受喜好的资讯或实物(例如:电影、电视节目、音乐、书籍、新闻、图片、网页)推荐给使用者。
本质上是根据用户的一些行为数据有针对性的推荐用户更可能感兴趣的内容。比如在网易云音乐听歌,听得越多,它就会推荐越多符合你喜好的音乐。
推荐系统是如何工作的呢?有一种思路如下:
用户 A 听了 收藏了 a,b,c 三首歌。用户 B 收藏了 a, b 两首歌,这时候推荐系统就把 c 推荐给用户 B。因为算法判断用户 A,B 对音乐的品味有极大可能一致。
推荐算法分类
最常见的推荐算法分为基于内容推荐以及协同过滤。协同过滤又可以分为基于用户的协同过滤和基于物品的协同过滤
基于内容推荐是直接判断所推荐内容本身的相关性,比如文章推荐,算法判断某篇文章和用户历史阅读文章的相关性进行推荐。
基于用户的协同过滤就是文章开头举的例子。
基于物品的协同过滤:
假设用户 A,B,C 都收藏了音乐 a,b。然后用户 D 收藏了音乐 a,那么这时候就推荐音乐 b 给他。
动手打造自己的推荐系统
这一次我们要做的是一个简单的电影推荐,虽然离工业应用还差十万八千里,但是非常适合新手一窥推荐系统的内部原理。数据集包含两个文件:ratings.csv 和 movies.csv。
# 载入数据
import pandas as pd
import numpy as np
df = pd.read_csv('data/ratings.csv')
df.head()
ratings.csv 包含四个维度的数据:
要推荐电影还需要有电影的名字,电影名字保存在 movies.csv 中:
movies = pd.read_csv('data/movies.csv')
movies.head()
将 ratings.csv 和 movies.csv 的数据根据 movieId 合并。
df = pd.merge(df, movie_title, on='movieId') df.head()
我们这次要做的推荐系统的核心思路是:
所以我们要先有所有用户对所有电影的评分的列联表:
movie_matrix = df.pivot_table(index = 'userId', columns = 'title' ,values = 'rating') movie_matrix.head()
假设用户 A 观看的电影是 air_force_one (1997),则计算列联表中所有电影与 air_force_one (1997) 的相关性。
AFO_user_rating = movie_matrix['Air Force One (1997)'] simliar_to_air_force_one = movie_matrix.corrwith(AFO_user_rating)
这样我们就得到了所有电影与 air_force_one (1997)的相关性。
但是,直接对这个相关性进行排序并推荐最相关的电影有一个及其严重的问题:
ratings = pd.DataFrame(df.groupby('title')['rating'].mean())#计算电影平均得分
ratings['number_of_ratings'] = df.groupby('title')['rating'].count()
import matplotlib.pyplot as plt
%matplotlib inline
ratings['number_of_ratings'].hist(bins = 60);
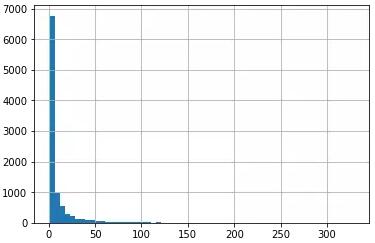
上图是电影被评分次数的直方图,可以看到大量的电影评分次数不足10次。评分次数太少的电影很容易就被判断为高相关性。所以我们要将这部分的评分删掉。
corr_AFO = pd.DataFrame(similar_to_air_force_one, columns = ['Correlation']) corr_AFO.dropna(inplace = True) corr_contact = corr_contact.join(ratings['number_of_ratings'],how = 'left',lsuffix='_left', rsuffix='_right') corr_AFO[corr_AFO['number_of_ratings']>100].sort_values(by = 'Correlation',ascending = False).head()
这样我们就得到了一个与 air_force_one (1997) 高相关的电影列表。但是高相关有可能评分低(概率低),再从列表里挑几部平均得分高的电影推荐就好了。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





