什么是爬虫?
网络爬虫也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛,爬虫程序通过请求url地址,根据响应的内容进行解析采集数据,
比如:如果响应内容是html,分析dom结构,进行dom解析、或者正则匹配,如果响应内容是xml/json数据,就可以转数据对象,然后对数据进行解析。
有什么作用?
通过有效的爬虫手段批量采集数据,可以降低人工成本,提高有效数据量,给予运营/销售的数据支撑,加快产品发展。
业界的情况
目前互联网产品竞争激烈,业界大部分都会使用爬虫技术对竞品产品的数据进行挖掘、采集、大数据分析,这是必备手段,并且很多公司都设立了爬虫工程师的岗位
合法性
爬虫是利用程序进行批量爬取网页上的公开信息,也就是前端显示的数据信息。因为信息是完全公开的,所以是合法的。其实就像浏览器一样,浏览器解析响应内容并渲染为页面,而爬虫解析响应内容采集想要的数据进行存储。
反爬虫
爬虫很难完全的制止,道高一尺魔高一丈,这是一场没有硝烟的战争,码农VS码农
反爬虫一些手段:
爬虫的基本套路
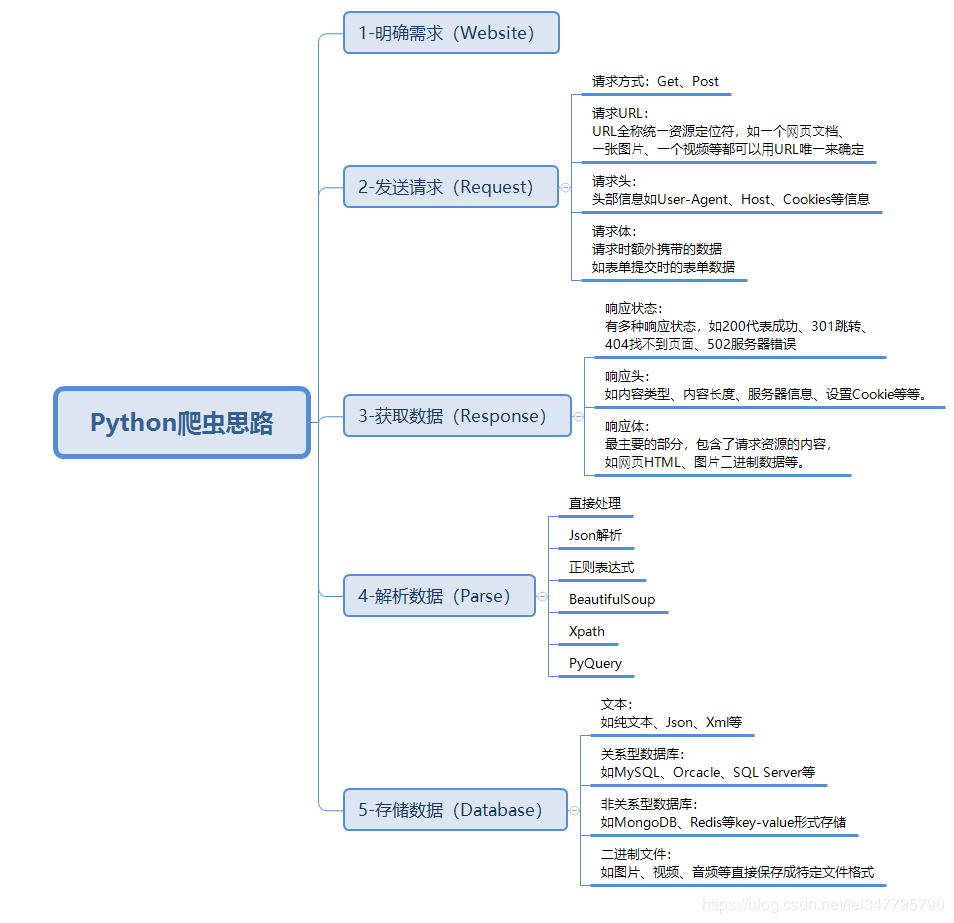
python爬虫
python写爬虫的优势
涉及模块包
请求
多线程
正则
json解析
html dom解析
操作浏览器
以上所述是小编给大家介绍的Python爬虫基本套路详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对亿速云网站的支持!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



