这篇文章给大家分享的是有关Python中可迭代对象、迭代器、For循环工作机制、生成器的示例分析的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
1.iterable iterator区别
要了解两者区别,先要了解一下迭代器协议:
迭代器协议是指:对象需要提供__next__()方法,它返回迭代中的元素,在没有更多元素后,抛出StopIteration异常,终止迭代。
可迭代对象就是:实现了迭代器协议的对象。
协议是一种约定,可迭代对象实现迭代器协议,Python的内置工具(如for循环,sum,min,max函数等)通过迭代器协议访问对象,因此,for循环并不需要知道对象具体是什么,只需要知道对象能够实现迭代器协议即可。
迭代器(iterator)与可迭代对象(iterable)并不是同一个概念。
直观上:
1.可迭代对象(iterable):凡是具有__iter__的方法的类,都是可迭代的类。可迭代类创建的对象实现了__iter__方法,因此就是可迭代对象。用list、tuple等容器创建的对象,都是可迭代对象。可迭代对象通过__iter__方法返回一个迭代器,然后在内部调用__next__方法进行迭代,最后没有元素时,抛出异常(这个异常python自己会处理,不会让开发者看见)。
2.迭代器(iterator):迭代器对象必须同时实现__iter__和__next__方法才是迭代器。对于迭代器来说,__iter__ 返回的是它自身 self,__next__ 则是返回迭代器中的下一个值,最后没有元素时,抛出异常(异常可以被开发者看到)。
从上面2点可以看出:
1.迭代器一定是可迭代对象,因为它实现了__iter__()方法;
2.通过iter()方法(在类的内部就是__iter__)能够使一个可迭代对象返回一个迭代器。
3.迭代器的 __iter__ 方法返回的是自身,并不产生新的迭代器对象。而可迭代对象的 __iter__ 方法通常会返回一个新的迭代器对象。
第3点性质正是可迭代对象可以重复遍历的原因(每次返回一个独立的迭代器,就可以保证不同的迭代过程不会互相影响);而迭代器由于返回自身,因此只能遍历一次。
上面3点可以通过下面的例子看出来:
from collections import Iterable
from collections import Iterator
print isinstance(iter([1,2]),Iterator)
print isinstance(iter([1,2]),Iterable)
print isinstance([1,2],Iterator)
print isinstance([1,2],Iterable)
##result
True
True
False
True
##id可以查看一个对象在内存中的地址
test=[1,2,3]
testIter=iter(test)
print id(testIter)
print id(testIter)
print id(iter(test))
print id(iter(test))
print id(test.__iter__())
print id(test.__iter__())
##result:可迭代对象每次调用iter方法都会返回一个新的迭代器对象,而迭代器对象调用iter方法返回自身
67162576
67162576
67162688
67162632
67162856
671630242.iterable的工作机制
拿一个例子看看,首先定义一个有__iter__方法,但是没有next()方法的类 (PS:在python2中是next(),python3是__next__()):
from collections import Iterable, Iterator
class Student(object):
def __init__(self,score):
self.score=score
def __iter__(self):
return iter(self.score)
test= Student([80,90,95])
print isinstance(test, Iterable)
print isinstance(test, Iterator)
for i in test:
print i
##result
True
False
80
90
95
##可重复遍历
for i in test:
print i
##result
80
90
95上面代码的结果印证了定义中提到的:
缺少了next()方法,可迭代对象就不是迭代器。
此外,注意到:可迭代对象通过__iter__方法每次都返回了一个独立的迭代器,这样就可以保证不同的迭代过程不会互相影响。
也就是说,通过iterable可以实现重复遍历,而迭代器是无法重复遍历的!
因此,如果想要把可迭代对象转变为迭代器,可以先调用iter()方法返回一个迭代器。然后就可以用next()不断迭代了!
print isinstance(iter(test),Iterator)
testIter=iter(test)
print testIter.next()
print testIter.next()
print testIter.next()
##result
True
80
90
95
##一旦取完了可迭代对象中所有的元素,再次调用next就会发生异常
print testIter.next()
##result
StopIteration:3.迭代器Iterator的工作机制
看下面这个例子:
class Student(object):
def __init__(self,score):
self.score=score
def __iter__(self):
return self
def next(self):
if self.score<100:
self.score+=1
return self.score
else:
raise StopIteration()
test= Student(90)
print isinstance(test, Iterable)
print isinstance(test, Iterator)
print test.next()
print test.next()
print test.next()
for i in test:
print i
##result
True
True
91
92
93
94
95
96
97
98
99
100
##如果此时再对test这个迭代器调用next方法,就会抛出异常
test.next()
##result
StopIteration:这个例子印证了定义中的:迭代器对象必须同时实现__iter__和__next__方法才是迭代器。
那么,使用迭代器好处在哪呢?
Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
一个很常见的应用就是:Python在处理列表的时候,是直接把整个列表读进内存的,当遇到大量样本时的时候会变得很慢。而迭代器的优势在于只把需要的元素读进内存,因此占用内存更少。
换句话说,迭代器是一种惰性求值模式,它是有状态的,只有在调用时才返回值,没有调用的时候就等待下一次调用。这样就节省了大量内存空间。
这个例子印证了定义中的:迭代器对象必须同时实现__iter__和__next__方法才是迭代器。
那么,使用迭代器好处在哪呢?
Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
一个很常见的应用就是:Python在处理列表的时候,是直接把整个列表读进内存的,当遇到大量样本时的时候会变得很慢。而迭代器的优势在于只把需要的元素读进内存,因此占用内存更少。
换句话说,迭代器是一种惰性求值模式,它是有状态的,只有在调用时才返回值,没有调用的时候就等待下一次调用。这样就节省了大量内存空间。
4.for循环的工作机制
有了上面2个例子,就可以总结一下在可迭代对象与迭代器中的For循环工作机制了。
当对象本身就是迭代器时,For循环工作机制:
调用 __iter__方法,返回自身self,也就是返回迭代器。
不断地调用迭代器的next()方法,每次按序返回迭代器中的一个值。
迭代到最后没有元素时,就抛出异常 StopIteration
在可迭代对象中,for循环工作机制:
先判断对象是否为可迭代对象(等价于判断有没有__iter__或__getitem__方法),没有的话直接报错,抛出TypeError异常。有的话,调用 __iter__方法,返回一个迭代器。
在python内部不断地调用迭代器的__next__方法,每次按序返回迭代器中的一个值。
迭代到最后没有元素时,就抛出异常 StopIteration,这个异常 python 自己会处理,不会暴露给开发者。
借用网络上的一张图直观理解一下:
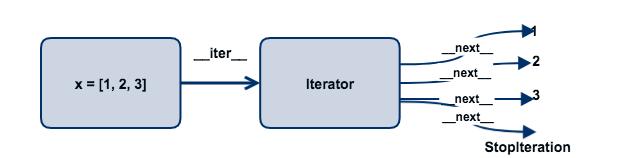
此外,还要注意,python中的for循环其实兼容了两种机制:
如果对象有__iter__会返回一个迭代器。
如果对象没有__iter__,但是实现了__getitem__,会改用下标迭代的方式。
__getitem__可以帮助一个对象进行取数和切片操作。
当for发现没有__iter__但是有__getitem__的时候,会从0开始依次读取相应的下标,直到发生IndexError为止,这是一种旧的迭代协议。iter方法也会处理这种情况,在不存在__iter__的时候,返回一个下标迭代的iterator对象来代替。一个重要的例子是str,字符串就是没有__iter__方法的,但是却依然可以迭代,原因就是其在for循环时调用了__getitem__方法。
看一个例子:
from collections import Iterable, Iterator
class Student(object):
def __init__(self,score):
self.score=score
def __getitem__(self,n):
return self.score[n]
test= Student([80,90,95])
print isinstance(test, Iterable)
print isinstance(test, Iterator)
print isinstance(iter(test), Iterable)
print isinstance(iter(test), Iterator)
for i in test:
print i
##result
False
False
True
True
80
90
95
for i in range(0,3):
print test[i]
##result
80
90
95
for i in iter(test):
print i
##result
80
90
95可以看到,实现了__getitem__方法的对象本身,尽管不是iterable与iterator,仍旧是可以调用for循环的。
通过iter方法,返回一个下标迭代的iterator对象。
5.generator的原理
最后说一下生成器,生成器是一种特殊的迭代器,当然也是可迭代对象。
对于生成器,Python会自动实现迭代器协议,以便应用到迭代中(如for循环,sum函数)。由于生成器自动实现了迭代器协议,所以,我们可以调用它的next方法,并且,在没有值可以返回的时候,生成器自动产生StopIteration异常。
创建生成器的方法:将return 改为yield。具体的实现网络上教程很多,不细说了。
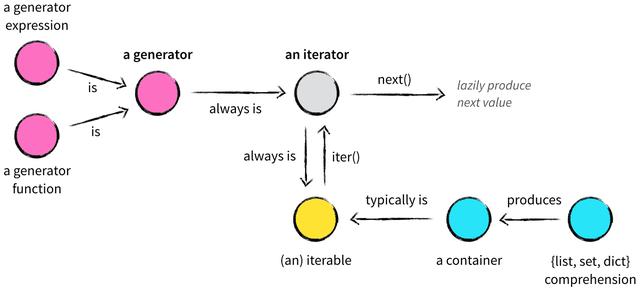
6.总结
到一幅图片很好的描述了本文的所有内容,就拿它作为文末的总结吧!
感谢各位的阅读!关于“Python中可迭代对象、迭代器、For循环工作机制、生成器的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



