这篇文章将为大家详细讲解有关如何使用Python对微信好友进行数据分析,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
1、云计算,典型应用OpenStack。2、WEB前端开发,众多大型网站均为Python开发。3.人工智能应用,基于大数据分析和深度学习而发展出来的人工智能本质上已经无法离开python。4、系统运维工程项目,自动化运维的标配就是python+Django/flask。5、金融理财分析,量化交易,金融分析。6、大数据分析。
只有登录微信才能获取到微信好友的信息,本文采用wxpy该第三方库进行微信的登录以及信息的获取。
wxpy 在 itchat 的基础上,通过大量接口优化提升了模块的易用性,并进行丰富的功能扩展。
wxpy一些常见的场景:
•控制路由器、智能家居等具有开放接口的玩意儿
•运行脚本时自动把日志发送到你的微信
•加群主为好友,自动拉进群中
•跨号或跨群转发消息
•自动陪人聊天
•逗人玩
总而言之,可用来实现各种微信个人号的自动化操作。
wxpy 支持 Python 3.4-3.6,以及 2.7 版本
将下方命令中的 “pip” 替换为 “pip3” 或 “pip2”,可确保安装到对应的 Python 版本中
1.从 PYPI 官方源下载安装 (在国内可能比较慢或不稳定):
pip install -U wxpy1
1.从豆瓣 PYPI 镜像源下载安装 (推荐国内用户选用):
pip install -U wxpy -i "https://pypi.doubanio.com/simple/"1
wxpy中有一个机器人对象,机器人 Bot 对象可被理解为一个 Web 微信客户端。Bot 在初始化时便会执行登陆操作,需要手机扫描登陆。
通过机器人对象 Bot 的 chats(), friends(),groups(), mps() 方法, 可分别获取到当前机器人的 所有聊天对象、好友、群聊,以及公众号列表。
本文主要通过friends()获取到所有好友信息,然后进行数据的处理。
from wxpy import *
# 初始化机器人,扫码登陆
bot = Bot()
# 获取所有好友
my_friends = bot.friends()
print(type(my_friends))以下为输出消息:
Getting uuid of QR code.
Downloading QR code.
Please scan the QR code to log in.
Please press confirm on your phone.
Loading the contact, this may take a little while.
<Login successfully as 王强?>
<class 'wxpy.api.chats.chats.Chats'>
wxpy.api.chats.chats.Chats对象是多个聊天对象的合集,可用于搜索或统计,可以搜索和统计的信息包括sex(性别)、province(省份)、city(城市)和signature(个性签名)等。
使用一个字典sex_dict来统计好友中男性和女性的数量。
# 使用一个字典统计好友男性和女性的数量
sex_dict = {'male': 0, 'female': 0}
for friend in my_friends:
# 统计性别
if friend.sex == 1:
sex_dict['male'] += 1
elif friend.sex == 2:
sex_dict['female'] += 1
print(sex_dict)以下为输出结果:
{'male': 255, 'female': 104}
本文采用 ECharts饼图 进行数据的呈现,打开链接http://echarts.baidu.com/echarts2/doc/example/pie1.html,可以看到如下内容:
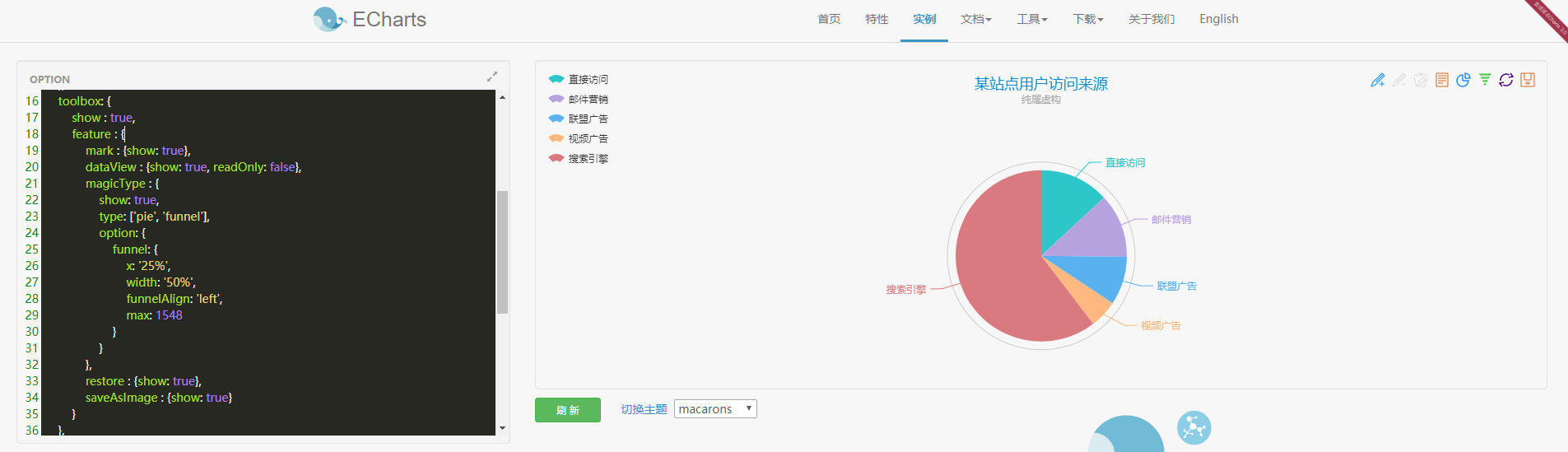
1、echarts饼图原始内容
从图中可以看到左侧为数据,右侧为呈现的数据图,其他的形式的图也是这种左右结构。看一下左边的数据:
option = {
title : {
text: '某站点用户访问来源',
subtext: '纯属虚构',
x:'center'
},
tooltip : {
trigger: 'item',
formatter: "{a} <br/>{b} : {c} ({d}%)"
},
legend: {
orient : 'vertical',
x : 'left',
data:['直接访问','邮件营销','联盟广告','视频广告','搜索引擎']
},
toolbox: {
show : true,
feature : {
mark : {show: true},
dataView : {show: true, readOnly: false},
magicType : {
show: true,
type: ['pie', 'funnel'],
option: {
funnel: {
x: '25%',
width: '50%',
funnelAlign: 'left',
max: 1548
}
}
},
restore : {show: true},
saveAsImage : {show: true}
}
},
calculable : true,
series : [
{
name:'访问来源',
type:'pie',
radius : '55%',
center: ['50%', '60%'],
data:[
{value:335, name:'直接访问'},
{value:310, name:'邮件营销'},
{value:234, name:'联盟广告'},
{value:135, name:'视频广告'},
{value:1548, name:'搜索引擎'}
]
}
]
};可以看到option =后面的大括号里是JSON格式的数据,接下来分析一下各项数据:
•title:标题
•text:标题内容
•subtext:子标题
•x:标题位置
•tooltip:提示,将鼠标放到饼状图上就可以看到提示
•legend:图例
•orient:方向
•x:图例位置
•data:图例内容
•toolbox:工具箱,在饼状图右上方横向排列的图标
•mark:辅助线开关
•dataView:数据视图,点击可以查看饼状图数据
•magicType:饼图(pie)切换和漏斗图(funnel)切换
•restore:还原
•saveAsImage:保存为图片
•calculable:暂时不知道它有什么用
•series:主要数据
•data:呈现的数据
其它类型的图数据格式类似,后面不再详细分析。只需要修改data、l**egend->data**、series->data即可,修改后的数据为:
option = {
title : {
text: '微信好友性别比例',
subtext: '真实数据',
x:'center'
},
tooltip : {
trigger: 'item',
formatter: "{a} <br/>{b} : {c} ({d}%)"
},
legend: {
orient : 'vertical',
x : 'left',
data:['男性','女性']
},
toolbox: {
show : true,
feature : {
mark : {show: true},
dataView : {show: true, readOnly: false},
magicType : {
show: true,
type: ['pie', 'funnel'],
option: {
funnel: {
x: '25%',
width: '50%',
funnelAlign: 'left',
max: 1548
}
}
},
restore : {show: true},
saveAsImage : {show: true}
}
},
calculable : true,
series : [
{
name:'访问来源',
type:'pie',
radius : '55%',
center: ['50%', '60%'],
data:[
{value:255, name:'男性'},
{value:104, name:'女性'}
]
}
]
};数据修改完成后,点击页面中绿色的刷新按钮,可以得到饼图如下(可以根据自己的喜好修改主题):
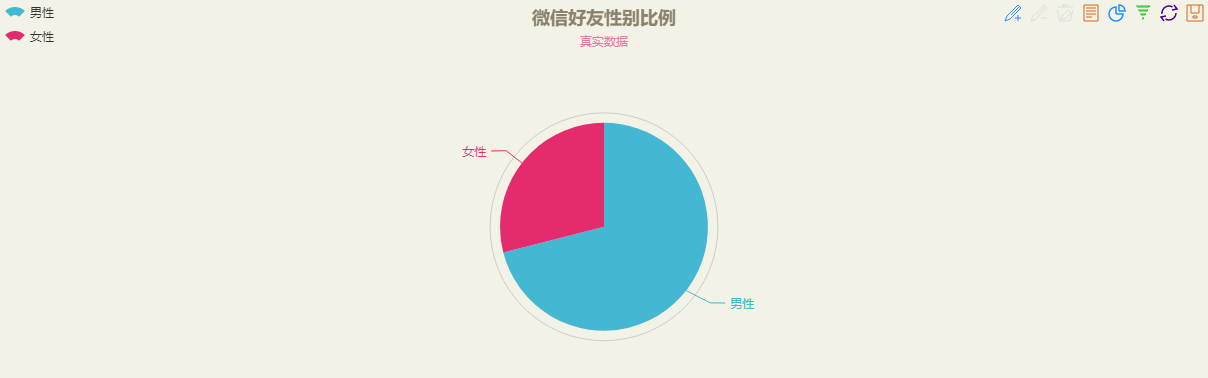
2、好友性别比例
将鼠标放到饼图上可以看到详细数据:
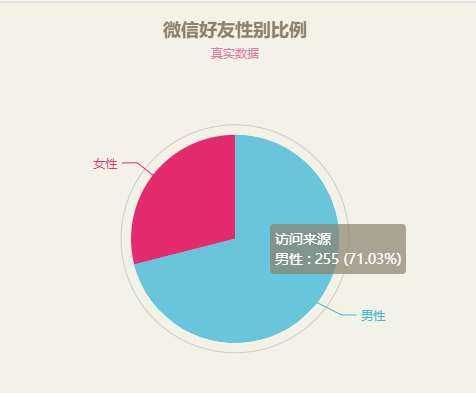
3、好友性别比例查看数据
3、微信好友全国分布图
# 使用一个字典统计各省好友数量
province_dict = {'北京': 0, '上海': 0, '天津': 0, '重庆': 0,
'河北': 0, '山西': 0, '吉林': 0, '辽宁': 0, '黑龙江': 0,
'陕西': 0, '甘肃': 0, '青海': 0, '山东': 0, '福建': 0,
'浙江': 0, '台湾': 0, '河南': 0, '湖北': 0, '湖南': 0,
'江西': 0, '江苏': 0, '安徽': 0, '广东': 0, '海南': 0,
'四川': 0, '贵州': 0, '云南': 0,
'内蒙古': 0, '新疆': 0, '宁夏': 0, '广西': 0, '西藏': 0,
'香港': 0, '澳门': 0}
# 统计省份
for friend in my_friends:
if friend.province in province_dict.keys():
province_dict[friend.province] += 1
# 为了方便数据的呈现,生成JSON Array格式数据
data = []
for key, value in province_dict.items():
data.append({'name': key, 'value': value})
print(data)以下为输出结果:
[{'name': '北京', 'value': 91}, {'name': '上海', 'value': 12}, {'name': '天津', 'value': 15}, {'name': '重庆', 'value': 1}, {'name': '河北', 'value': 53}, {'name': '山西', 'value': 2}, {'name': '吉林', 'value': 1}, {'name': '辽宁', 'value': 1}, {'name': '黑龙江', 'value': 2}, {'name': '陕西', 'value': 3}, {'name': '甘肃', 'value': 0}, {'name': '青海', 'value': 0}, {'name': '山东', 'value': 7}, {'name': '福建', 'value': 3}, {'name': '浙江', 'value': 4}, {'name': '台湾', 'value': 0}, {'name': '河南', 'value': 1}, {'name': '湖北', 'value': 4}, {'name': '湖南', 'value': 4}, {'name': '江西', 'value': 4}, {'name': '江苏', 'value': 9}, {'name': '安徽', 'value': 2}, {'name': '广东', 'value': 63}, {'name': '海南', 'value': 0}, {'name': '四川', 'value': 2}, {'name': '贵州', 'value': 0}, {'name': '云南', 'value': 1}, {'name': '内蒙古', 'value': 0}, {'name': '新疆', 'value': 2}, {'name': '宁夏', 'value': 0}, {'name': '广西', 'value': 1}, {'name': '西藏', 'value': 0}, {'name': '香港', 'value': 0}, {'name': '澳门', 'value': 0}]
可以看出,好友最多的省份为北京。那么问题来了:为什么要把数据重组成这种格式?因为ECharts的地图需要这种格式的数据。
采用ECharts地图 来进行好友分布的数据呈现。打开该网址,将左侧数据修改为:
option = {
title : {
text: '微信好友全国分布图',
subtext: '真实数据',
x:'center'
},
tooltip : {
trigger: 'item'
},
legend: {
orient: 'vertical',
x:'left',
data:['好友数量']
},
dataRange: {
min: 0,
max: 100,
x: 'left',
y: 'bottom',
text:['高','低'], // 文本,默认为数值文本
calculable : true
},
toolbox: {
show: true,
orient : 'vertical',
x: 'right',
y: 'center',
feature : {
mark : {show: true},
dataView : {show: true, readOnly: false},
restore : {show: true},
saveAsImage : {show: true}
}
},
roamController: {
show: true,
x: 'right',
mapTypeControl: {
'china': true
}
},
series : [
{
name: '好友数量',
type: 'map',
mapType: 'china',
roam: false,
itemStyle:{
normal:{label:{show:true}},
emphasis:{label:{show:true}}
},
data:[
{'name': '北京', 'value': 91},
{'name': '上海', 'value': 12},
{'name': '天津', 'value': 15},
{'name': '重庆', 'value': 1},
{'name': '河北', 'value': 53},
{'name': '山西', 'value': 2},
{'name': '吉林', 'value': 1},
{'name': '辽宁', 'value': 1},
{'name': '黑龙江', 'value': 2},
{'name': '陕西', 'value': 3},
{'name': '甘肃', 'value': 0},
{'name': '青海', 'value': 0},
{'name': '山东', 'value': 7},
{'name': '福建', 'value': 3},
{'name': '浙江', 'value': 4},
{'name': '台湾', 'value': 0},
{'name': '河南', 'value': 1},
{'name': '湖北', 'value': 4},
{'name': '湖南', 'value': 4},
{'name': '江西', 'value': 4},
{'name': '江苏', 'value': 9},
{'name': '安徽', 'value': 2},
{'name': '广东', 'value': 63},
{'name': '海南', 'value': 0},
{'name': '四川', 'value': 2},
{'name': '贵州', 'value': 0},
{'name': '云南', 'value': 1},
{'name': '内蒙古', 'value': 0},
{'name': '新疆', 'value': 2},
{'name': '宁夏', 'value': 0},
{'name': '广西', 'value': 1},
{'name': '西藏', 'value': 0},
{'name': '香港', 'value': 0},
{'name': '澳门', 'value': 0}
]
}
]
};注意两点:
•dataRange->max 根据统计数据适当调整
•series->data 的数据格式
点击刷新按钮后,可以生成如下地图:
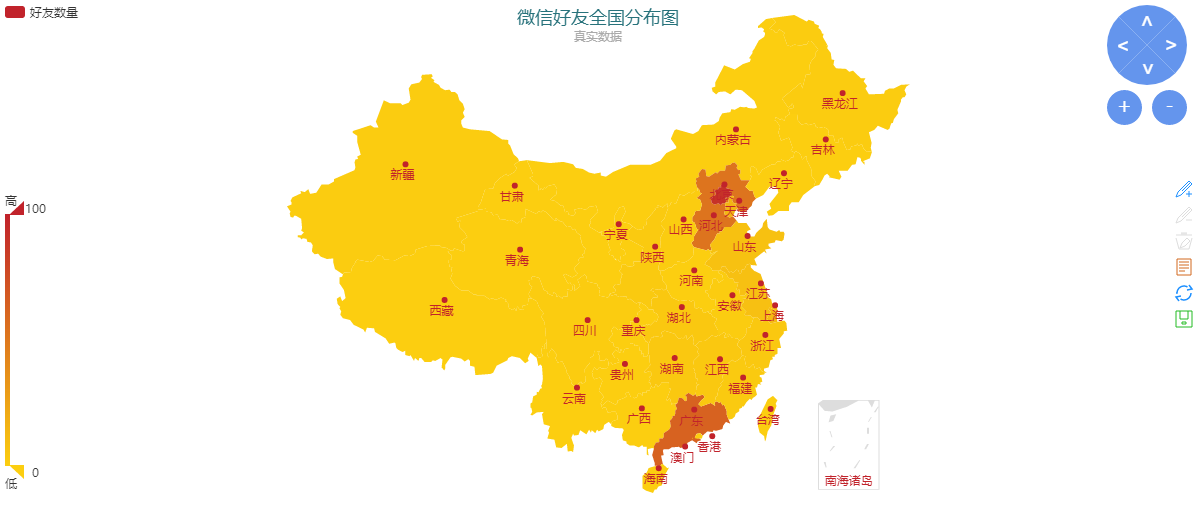
4、好友全国分布图
从图中可以看出我的好友主要分布在北京、河北和广东。
有趣的是,地图左边有一个滑块,代表地图数据的范围,我们将上边的滑块拉到最下面可以看到没有微信好友分布的省份:
5、没有微信好友的省份
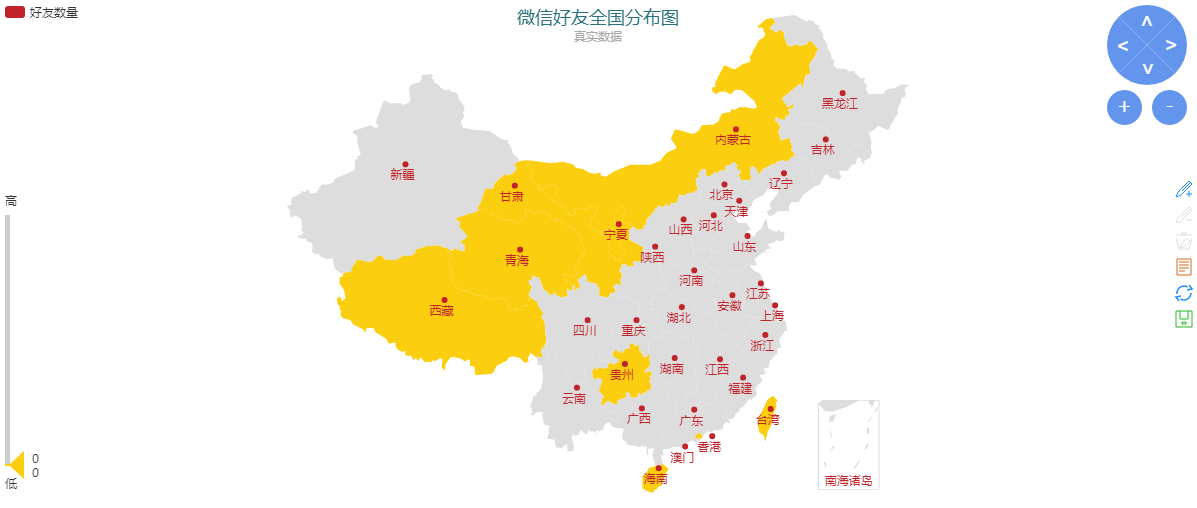
按照这个思路,我们可以在地图上看到确切数量好友分布的省份,读者可以动手试试。
def write_txt_file(path, txt):
'''
写入txt文本
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f.write(txt)
# 统计签名
for friend in my_friends:
# 对数据进行清洗,将标点符号等对词频统计造成影响的因素剔除
pattern = re.compile(r'[一-龥]+')
filterdata = re.findall(pattern, friend.signature)
write_txt_file('signatures.txt', ''.join(filterdata))上面代码实现了对好友签名进行清洗以及保存的功能,执行完成之后会在当前目录生成signatures.txt文件。
数据呈现采用词频统计和词云展示,通过词频可以了解到微信好友的生活态度。
词频统计用到了 jieba、numpy、pandas、scipy、wordcloud库。如果电脑上没有这几个库,执行安装指令:
•pip install jieba
•pip install pandas
•pip install numpy
•pip install scipy
•pip install wordcloud
4.2.1 读取txt文件
前面已经将好友签名保存到txt文件里了,现在我们将其读出:
def read_txt_file(path):
'''
读取txt文本
'''
with open(path, 'r', encoding='gb18030', newline='') as f:
return f.read()4.2.2 stop word
下面引入一个概念:stop word, 在网站里面存在大量的常用词比如:“在”、“里面”、“也”、“的”、“它”、“为”这些词都是停止词。这些词因为使用频率过高,几乎每个网页上都存在,所以搜索引擎开发人员都将这一类词语全部忽略掉。如果我们的网站上存在大量这样的词语,那么相当于浪费了很多资源。
在百度搜索stpowords.txt进行下载,放到py文件同级目录。
content = read_txt_file(txt_filename)
segment = jieba.lcut(content)
words_df=pd.DataFrame({'segment':segment})
stopwords=pd.read_csv("stopwords.txt",index_col=False,quoting=3,sep=" ",names=['stopword'],encoding='utf-8')
words_df=words_df[~words_df.segment.isin(stopwords.stopword)]4.2.3 词频统计
重头戏来了,词频统计使用numpy:
import numpy
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["计数"],ascending=False)4.2.4 词频可视化:词云
词频统计虽然出来了,可以看出排名,但是不完美,接下来我们将它可视化。使用到wordcloud库,详细介绍见 github 。
from scipy.misc import imread
from wordcloud import WordCloud, ImageColorGenerator
# 设置词云属性
color_mask = imread('background.jfif')
wordcloud = WordCloud(font_path="simhei.ttf", # 设置字体可以显示中文
background_color="white", # 背景颜色
max_words=100, # 词云显示的最大词数
mask=color_mask, # 设置背景图片
max_font_size=100, # 字体最大值
random_state=42,
width=1000, height=860, margin=2,# 设置图片默认的大小,但是如果使用背景图片的话, # 那么保存的图片大小将会按照其大小保存,margin为词语边缘距离
)
# 生成词云, 可以用generate输入全部文本,也可以我们计算好词频后使用generate_from_frequencies函数
word_frequence = {x[0]:x[1]for x in words_stat.head(100).values}
print(word_frequence)
word_frequence_dict = {}
for key in word_frequence:
word_frequence_dict[key] = word_frequence[key]
wordcloud.generate_from_frequencies(word_frequence_dict)
# 从背景图片生成颜色值
image_colors = ImageColorGenerator(color_mask)
# 重新上色
wordcloud.recolor(color_func=image_colors)
# 保存图片
wordcloud.to_file('output.png')
plt.imshow(wordcloud)
plt.axis("off")
plt.show()运行效果图如下(左图为背景图,右图为生成词云图片):

6、背景图和词云图对比
从词云图可以分析好友特点:
•做——————–行动派
•人生、生活——–热爱生活
•快乐—————–乐观
•选择—————–决断
•专业—————–专业
•爱——————–爱
至此,微信好友的分析工作已经完成,wxpy的功能还有很多,比如聊天、查看公众号信息等,有意的读者请自行查阅官方文档。
上面的代码比较松散,下面展示的完整代码我将各功能模块封装成函数:
#-*- coding: utf-8 -*-
import re
from wxpy import *
import jieba
import numpy
import pandas as pd
import matplotlib.pyplot as plt
from scipy.misc import imread
from wordcloud import WordCloud, ImageColorGenerator
def write_txt_file(path, txt):
'''
写入txt文本
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f.write(txt)
def read_txt_file(path):
'''
读取txt文本
'''
with open(path, 'r', encoding='gb18030', newline='') as f:
return f.read()
def login():
# 初始化机器人,扫码登陆
bot = Bot()
# 获取所有好友
my_friends = bot.friends()
print(type(my_friends))
return my_friends
def show_sex_ratio(friends):
# 使用一个字典统计好友男性和女性的数量
sex_dict = {'male': 0, 'female': 0}
for friend in friends:
# 统计性别
if friend.sex == 1:
sex_dict['male'] += 1
elif friend.sex == 2:
sex_dict['female'] += 1
print(sex_dict)
def show_area_distribution(friends):
# 使用一个字典统计各省好友数量
province_dict = {'北京': 0, '上海': 0, '天津': 0, '重庆': 0,
'河北': 0, '山西': 0, '吉林': 0, '辽宁': 0, '黑龙江': 0,
'陕西': 0, '甘肃': 0, '青海': 0, '山东': 0, '福建': 0,
'浙江': 0, '台湾': 0, '河南': 0, '湖北': 0, '湖南': 0,
'江西': 0, '江苏': 0, '安徽': 0, '广东': 0, '海南': 0,
'四川': 0, '贵州': 0, '云南': 0,
'内蒙古': 0, '新疆': 0, '宁夏': 0, '广西': 0, '西藏': 0,
'香港': 0, '澳门': 0}
# 统计省份
for friend in friends:
if friend.province in province_dict.keys():
province_dict[friend.province] += 1
# 为了方便数据的呈现,生成JSON Array格式数据
data = []
for key, value in province_dict.items():
data.append({'name': key, 'value': value})
print(data)
def show_signature(friends):
# 统计签名
for friend in friends:
# 对数据进行清洗,将标点符号等对词频统计造成影响的因素剔除
pattern = re.compile(r'[一-龥]+')
filterdata = re.findall(pattern, friend.signature)
write_txt_file('signatures.txt', ''.join(filterdata))
# 读取文件
content = read_txt_file('signatures.txt')
segment = jieba.lcut(content)
words_df = pd.DataFrame({'segment':segment})
# 读取stopwords
stopwords = pd.read_csv("stopwords.txt",index_col=False,quoting=3,sep=" ",names=['stopword'],encoding='utf-8')
words_df = words_df[~words_df.segment.isin(stopwords.stopword)]
print(words_df)
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["计数"],ascending=False)
# 设置词云属性
color_mask = imread('background.jfif')
wordcloud = WordCloud(font_path="simhei.ttf", # 设置字体可以显示中文
background_color="white", # 背景颜色
max_words=100, # 词云显示的最大词数
mask=color_mask, # 设置背景图片
max_font_size=100, # 字体最大值
random_state=42,
width=1000, height=860, margin=2,# 设置图片默认的大小,但是如果使用背景图片的话, # 那么保存的图片大小将会按照其大小保存,margin为词语边缘距离
)
# 生成词云, 可以用generate输入全部文本,也可以我们计算好词频后使用generate_from_frequencies函数
word_frequence = {x[0]:x[1]for x in words_stat.head(100).values}
print(word_frequence)
word_frequence_dict = {}
for key in word_frequence:
word_frequence_dict[key] = word_frequence[key]
wordcloud.generate_from_frequencies(word_frequence_dict)
# 从背景图片生成颜色值
image_colors = ImageColorGenerator(color_mask)
# 重新上色
wordcloud.recolor(color_func=image_colors)
# 保存图片
wordcloud.to_file('output.png')
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
def main():
friends = login()
show_sex_ratio(friends)
show_area_distribution(friends)
show_signature(friends)
if __name__ == '__main__':
main()关于“如何使用Python对微信好友进行数据分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



