这期内容当中小编将会给大家带来有关如何在Oracle中使用ROLLUP分组函数,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
环境准备
create table dept as select * from scott.dept; create table emp as select * from scott.emp;
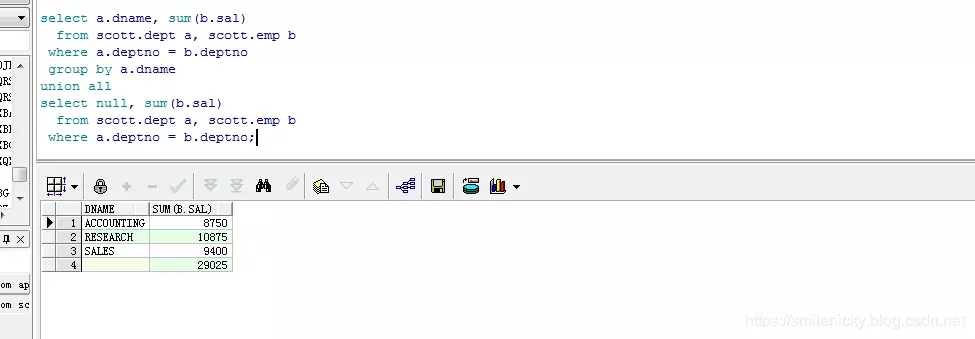
业务场景:求各部门的工资总和及其所有部门的工资总和
这里可以用union来做,先按部门统计工资之和,然后在统计全部部门的工资之和
select a.dname, sum(b.sal) from scott.dept a, scott.emp b where a.deptno = b.deptno group by a.dname union all select null, sum(b.sal) from scott.dept a, scott.emp b where a.deptno = b.deptno;
上面是用union来做,然后用rollup来做,语法更简单,而且性能更好
select a.dname, sum(b.sal) from scott.dept a, scott.emp b where a.deptno = b.deptno group by rollup(a.dname);
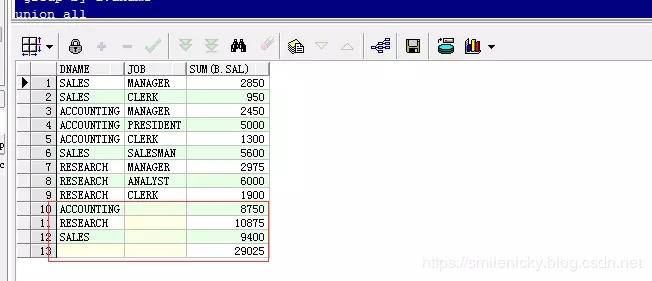
业务场景:基于上面的统计,再加需求,现在要看看每个部门岗位对应的工资之和
select a.dname, b.job, sum(b.sal) from scott.dept a, scott.emp b where a.deptno = b.deptno group by a.dname, b.job union all//各部门的工资之和 select a.dname, null, sum(b.sal) from scott.dept a, scott.emp b where a.deptno = b.deptno group by a.dname union all//所有部门工资之和 select null, null, sum(b.sal) from scott.dept a, scott.emp b where a.deptno = b.deptno;
用rollup实现,语法更简单
select a.dname, b.job, sum(b.sal) from scott.dept a, scott.emp b where a.deptno = b.deptno group by rollup(a.dname, b.job);
假如再加个时间统计的,可以用下面sql:
select to_char(b.hiredate, 'yyyy') hiredate, a.dname, b.job, sum(b.sal) from scott.dept a, scott.emp b where a.deptno = b.deptno group by rollup(to_char(b.hiredate, 'yyyy'), a.dname, b.job);
cube函数
select a.dname, b.job, sum(b.sal) from scott.dept a, scott.emp b where a.deptno = b.deptno group by cube(a.dname, b.job);
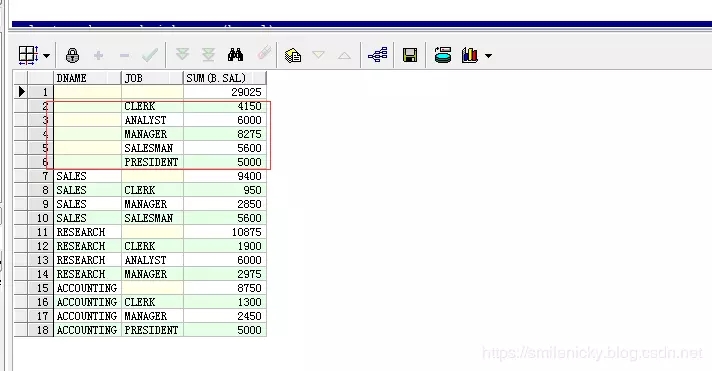 cube
cube
函数是维度更细的统计,语法和rollup类似
假设有n个维度,那么rollup会有n个聚合,cube会有2n个聚合
rollup统计列
rollup(a,b) 统计列包含:(a,b)、(a)、()
rollup(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a)、()
....
cube统计列
cube(a,b) 统计列包含:(a,b)、(a)、(b)、()
cube(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a,c)、(b,c)、(a)、(b)、(c)、()
上述就是小编为大家分享的如何在Oracle中使用ROLLUP分组函数了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





