在企业中,一些重要的数据一般都会存储在硬盘中,虽然硬盘本身的性能也在不断提高,但是无论硬盘的存取速度有多快,企业所追寻的首先是可靠性,然后才是效率。如果数据面临丢失的风险,再好的硬件也无法玩会企业的损失,加之近几年云计算的出现,对存储提出了更高的要求。而分布式存储逐渐被人们所接受,它具有更好的性能、高扩展以及可靠性。大部分分布式解决方案都是通过元服务器存放目录结构等元数据,元数据服务器提供了整个分布式存储的索引工作。但是一旦元数据服务器损坏,整个分布式存储都将无法进行工作。下面我们将介绍一种无元服务器的分布式存储解决方案——GlusterFS。
GlusterFS是一个开源的分布式文件系统,同时也是Scale-Out存储解决方案GlusterFS的核心。在存储数据方面具有很强大的扩展能力,通过扩展不同的节点可以支持PB级别的存储容量。GlusterFS借助TCP/IP或InfiniBand RDMA网络将分散的存储资源汇聚在一起,同一提供存储服务,并使用单一全局命令空间来管理数据。GlusterFS基于可堆叠的用户空间以及无元的设计,可为各种不同的数据负载提供优异的性能。
GlusterFS主要由存储服务器、客户端及NFS/Samba存储网关(可选,根据需要选择使用)组成。如图:
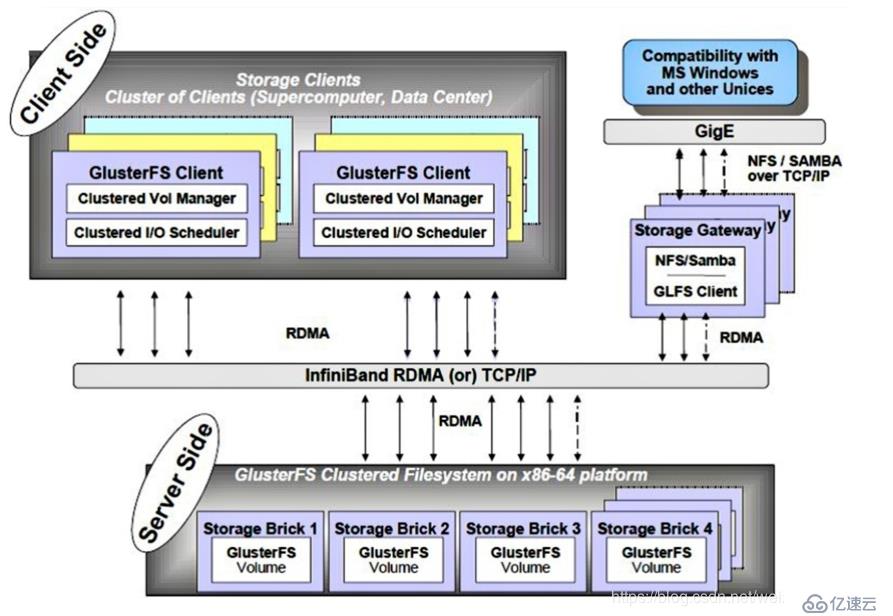
GlusterFS架构中最大的设计特点就是没有元数据服务器组件,这有助于提升整个系统的性能、可靠性和稳定性。传统的分布式文件系统大多通过元服务器来存储元数据,元数据包含存储节点上的目录信息、目录结构等,这样的设计在浏览目录时效率非常高,但是也存在一些缺陷,如单点故障,一旦元数据服务器出现故障,即使节点具备再高的冗余性,整个存储系统也将崩溃,而GlusterFS分布式文件系统是基于无元服务器的设计,数据横向扩展能力强,具备较高的可靠性及存储效率。 GlusterFS支持TCP/IP和InfiniBand RDMA高速网络互联,客户端可通过原声GlusterFS协议访问数据,其他没有运行GlusterFS客户端的终端可通过NFS/CIFS标准协议通过存储网关访问数据。
- 扩展性和高性能。GlusterFS利用双重特性来提供高容量存储解决方案。
(1)Scale-Out架构通过增加存储节点的方式来提高存储容量和性能(磁盘、计算机和I/O资源都可以独立增加),支持10GBE和InfiniBand等高速网络互联;
(2)Gluster弹性哈希解决了GlusterFS对元数据服务器的依赖,GlusterFS采用弹性算法在存储池中定位数据,放弃了传统的通过元数据服务器定位数据,GlusterFS中可以智能的定位任意数据分片(将数据分片存储在不同节点上),不需要查看索引或者想元数据服务器查询。这种设计机制实现了存储的横向扩展,改善了单点故障及性能瓶颈,真正实现了并行化数据访问。- 高可用性。GlusterFS通过配置某些类型的存储卷,可以对文件进行自动复制(类似于RAID1),即使某个节点出现故障,也不影响数据的访问。当数据出现不一致时,自动修复功能能够把数据恢复到正确的状态,数据的修复是以增量的方式在后台执行,不会占用太多系统资源。GlusterFS可以支持所有的存储,以内它没有设计自己的私有数据文件格式,而是采用操作系统中标准的磁盘文件系统(如EXT3、XFS等)来存储文件,数据可以使用传统的访问磁盘的方式被访问;
- 全局统一命名空间。全局统一命名空间将所有的存储资源聚集成一个单一的虚拟存储池,对用户和应用屏蔽了物理存储信息。存储资源(类似于LVM)可以根据生产环境中的需要进行弹性扩展或收缩。在多节点场景中,全局统一命名空间还可以基于不同节点做负载均衡,大大提高了存取效率;
- 弹性卷管理。GlusterFS通过将数据储存在逻辑卷中,逻辑卷从逻辑存储池进行独立逻辑划分。逻辑存储池可以在线进行增加和移除,不会导致业务中断。逻辑卷可以根据需求在线增长或增减,并可以在多个节点中负载均衡。文件系统配置更改也可以实时在线进行并应用,从而可以适应工作负载条件变化或在线性能调优;
- 基于标准协议。Gluster存储服务支持NFS、CIFS、HTTP、FTP、FTP、SMB及Gluster原生协议,完全与POSIX标准兼容。现有应用程序不需要做任何修改就可以对Gluster中的数据进行访问,也可以使用专用API进行访问(效率更高),这在公有云环境中部署Gluster时非常有用,Gluster对云服务提供商专用APl进行抽象,然后提供标准POSIX借口;
- Brick(存储块):指可信主机池中由主机提供的用于物理存储的专用分区,是GlusterFS中的基本存储单元,同时也是可信存储池中服务器上对外提供的存储目录,存储目录的格式由服务器和目录的绝对路径构成,表示方法为SERVER:EXPORT ,比如:192.168.1.4/date/mydir/;
- Volume(逻辑卷):一个逻辑卷是一组Brick的集合。卷是数据存储的逻辑设备,类似于LVM中的逻辑卷。大部分Gluster管理操作是在卷上进行的;
- FUSE:是一个内核模块,允许用户创建自己的文件系统,无须修改内核代码;
- VFS:内核空间对用户空间提供吧的访问磁盘的接口;
- Glusterd(后台管理进程):在存储群集中的每个节点上都要运行;
如图: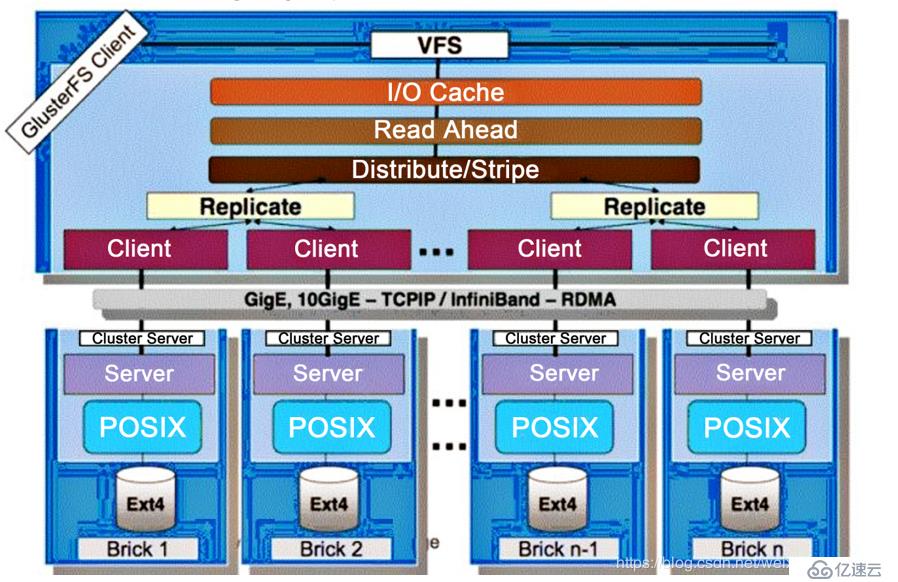
GlusterFS采用模块化、堆栈式的结构,可以根据需求配置定制化的应用环境,如大文件存储、海量小文件存储、云存储、多传输协议应用等。通过对模块进行各种组合,接口实现复杂的功能。例如:Replicate模块可实现RAID1,Stripe模块可实现RAID0,通过两者的组合可实现RAID10和RAID01,同时获得更高的性能和可靠性。
GlusterFS是模块化堆栈式的架构设计。模块成为Translator,是GlusterFS提供的一种强大的机制,借助这种良好定义的接口可以高效简便地扩展文件系统的功能。
(1)服务器与客户端的设计高度模块化的同事模块接口是兼容的,同一个transtator可同事在客户端和服务器加载;
(2)GlusterFS中所有的功能都是通过transtator实现的,其中客户端要比服务器更复杂。所以功能的重点主要集中在客户端上;
GlusterFS数据访问流程如图: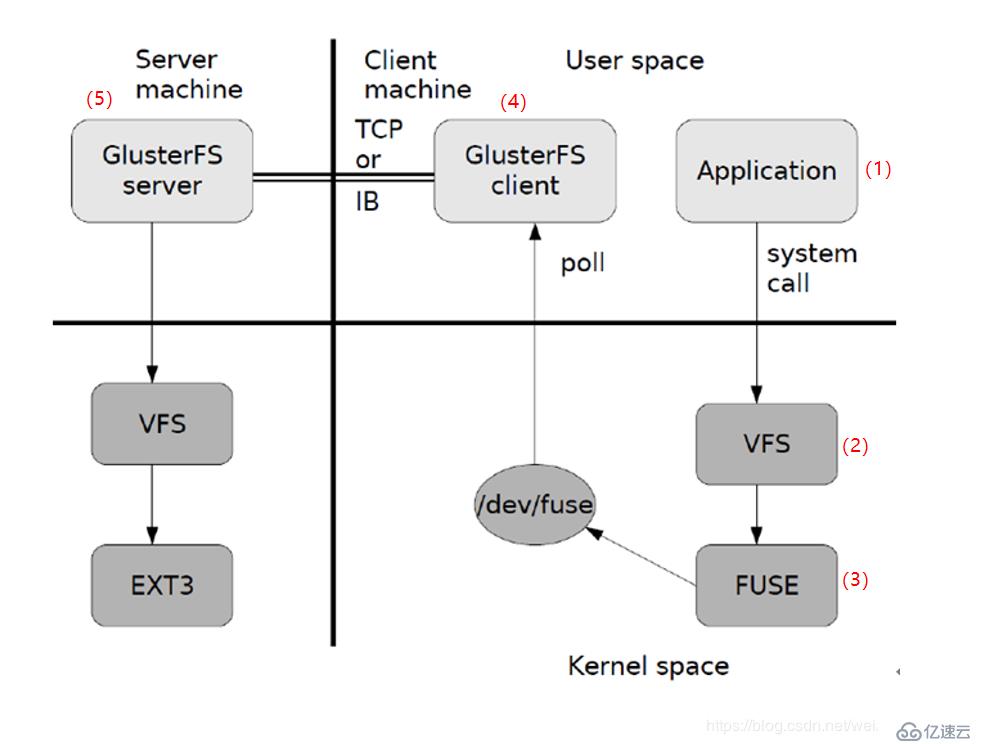
图中所示只是GlusterFS数据访问的一个概要图,大致过程:
(1)客户端或应用程序通过GlusterFS的挂在点访问数据;
(2)Linux系统内核通过VFS API收到请求并处理;
(3)VFS将数据递交给FUSE内核文件系统,并向系统注册了一个实际的文件系统FUSE,而FUSE文件系统则是将数据通过/dev/fuse设备文件递交给GlusterFS client端。可以将FUSE文件系统理解为一个代理;
(4)GlusterFS client收到数据后。client根据配置文件对数据进行处理;
(5)经过GlusterFS client处理后,通过网络将数据传递至远端的GlusterFS Server,并且将数据写入服务器存储设备。
弹性HASH算法使用Davies-Meyer算法,通过HASH算法得到一个32位的整数范围,假设逻辑卷中有N个存储单位Brick,则32位的整数范围被划分为N个连续的子空间,每个空间对应一个Brick。当用户或应用程序访问某一个命名空间时,通过对该命名空间计算HASH值,根据该HASH值对应的32位整数空间定位数据所在的Brick。
弹性HASH算法的优点表现如下:
- 保证数据平均分布在每个Brick中;
- 解决了对元数据服务器的依赖,进而解决了单点故障及访问瓶颈;
现在我们假设创建一个包含四个Brick节点的GlusterFS卷,在服务端的Brick挂载目录会给四个Brick平均分配2^32的区间的范围空间。GlusterFS hash分布区间是保存在目录上而不是根据机器去分布区间。如图:
Brick*表示一个目录,分布区间保存在每个Brick挂载点目录的扩展属性上。
在卷中创建四个文件。访问文件时,通过快速Hash函数计算出对应的HASH值,然后根据计算出来的HASH值对应的子空间散列到服务器的Brick上,如图: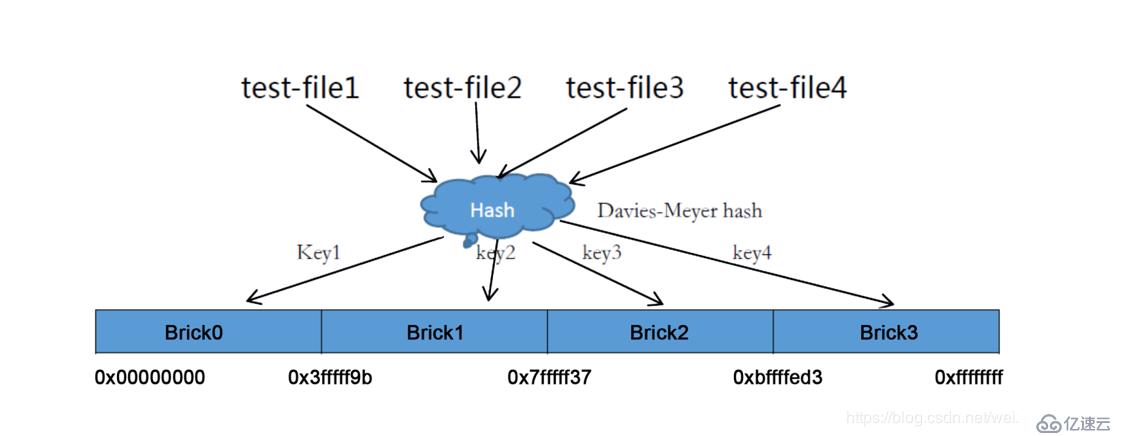
GlusterFS支持七种卷,这七种卷可以满足不同应用对高性能、高可用的需求。这七种卷分别是:
- (1)分布式卷(Distribute volume):文件通过HASH算法分布到所有Brick Server上,这种卷是Glusterf的基础;以文件为单位根据HASH算法散列到不同的Brick,其实只是扩大了磁盘空间,如果有一个磁盘损坏,数据也将丢失,属于文件级的RAID0,不具备容错能力;
- (2)条带卷(Stripe volume):类似于RAID0,文件被分为数据块并以轮询的方式分布到多个Brick Server上,文件存储以数据块为单位,支持大文件存储,文件越大,读取效率越高;
- (3)复制卷(Replica volume):将文件同步到多个Brick上,使其具备多个文件副本,属于文件级RAID1,具有容错能力。因为数据分散到多个Brick中,所以读性能得到了很大提升,但写性能下降;
- (4)分布式条带卷(Distribute Stripe volume):Brick Server数量是条带数(数据块分布的Brick数量)的倍数,兼备分布式卷和条带卷的特点;
- (5)分布式复制卷(Distribute Replica volume):Brick Server数量是镜像数(数据副本数量)的倍数,具有分布式卷和复制卷的特点;
- (6)条带复制卷(Stripe Replica volume):类似于RAID10,同时具有条带卷和复制卷的特点;
- (7)分布式条带复制卷(Distribute Stripe Replica volume):三种基本卷的复合卷,通常用于类Map Reduce应用;
下面详细介绍几种重要的卷类型:
分布式卷是GlusterFS的默认卷,在创建卷时,默认选项就是创建分布式卷。在该模式下,并没有对文件进行分块处理,文件直接存储在某个Server节点上,直接使用本地文件系统进行文件存储,大部分Linux命令和工具可以继续正常使用。需要通过扩展文件属性保存HASH值,目前支持的底层文件系统有ext3、ext4、ZFS、XFS等。
由于使用本地文件系统,所以存取效率并没有提高,反而会因为网络通信的原因而有所降低;另外支持超大型文件也会有一定的难度,因为分布式卷不会对文件进行分块处理。虽然ext4已经可以支持最大16TB的单个文件,但是本地存储设备的容量实在有限。
如图: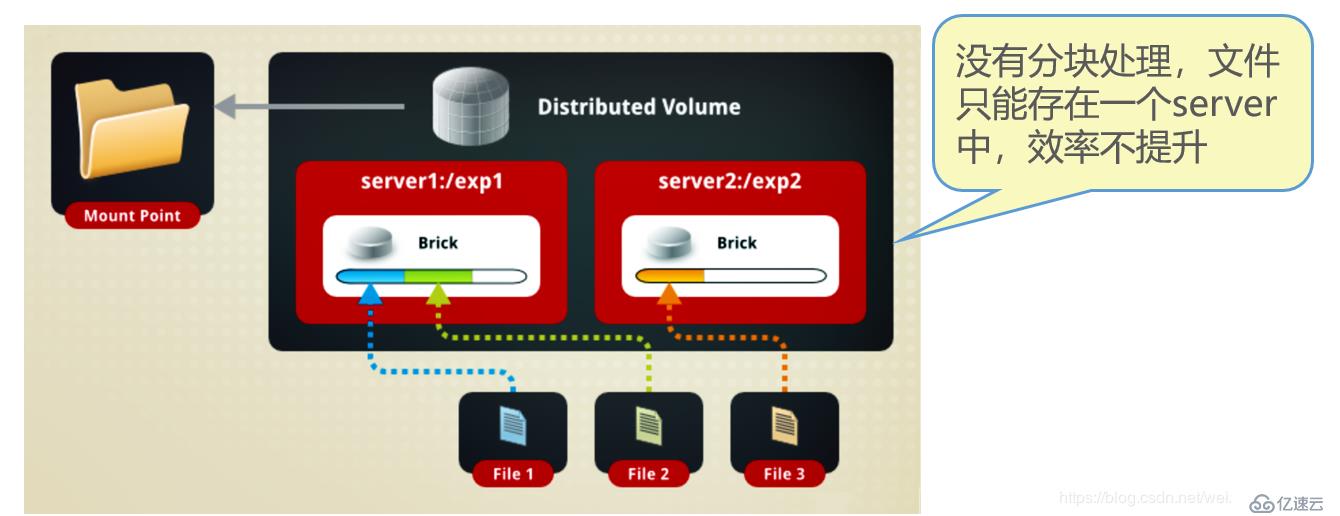
如图所示:File1和File2存放在Server1,而File3存放在Server2,文件都是随机存储,一个文件要么在Server1上,要么在Server2上,不能分块同时存放在Server1和Server2上。
分布式卷具有如下特点:
- 文件分布在不同的服务器,布局别冗余性;
- 更容易廉价地扩展卷的大小;
- 单点故障会造成数据丢失;
- 依赖于底层的数据保护;
创建分布式卷的命令:
[root@localhost ~]# gluster volume create dis-volume server1:/dir1 server2:/dir2
//创建一个名为dis-volume的分布卷,文件将根据HASH分布在server1:/dir1、server2:/dir2中
Creation of dis-volume has been successful
Please start the volume to access dataStripe模式相当于RAID0,在该模式下,根据偏移量将文件分成N块(N个条带节点),轮询地存储在每个Brick Server节点。节点把每个数据块都作为普通文件存入本地文件系统中,通过扩展属性记录总块数和每块的序号。在配置时指定的条带数必须等于卷中Brick所包含的存储服务器数,在存储大文件时,性能尤为突出,但是不具备冗余性。
如图:
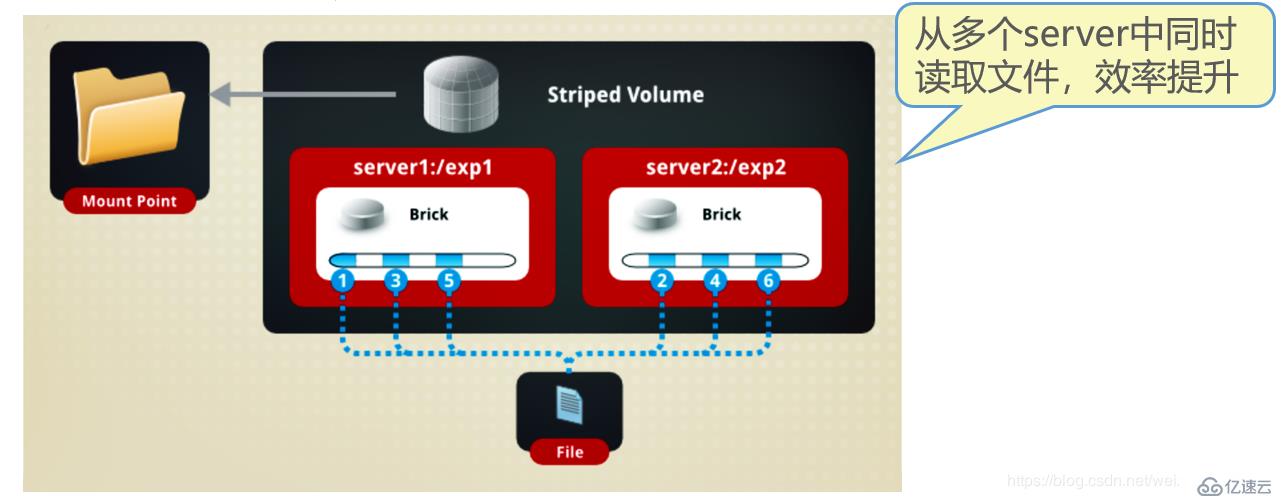
File被分割为6段,1、3、5放在Server1, 2、4、6放在Server2中!
条带卷具有如下特点:
- 数据被分割成更小块分布到块服务器群中的不同条带区;
- 分布减少了负载且更小的文件加速了存取的速度;
- 没有数据冗余;
创建条带卷的命令:
[root@localhost ~]# gluster volume create rep-volume replica 2 transport tcp server1:/dir1 server2:/dir2
//创建一个名为Stripe-volume的条带卷,文件将分块轮询地存储在server1:/dir1 、server2:/dir2两个Brick中
Creation of rep-volume has been successful
Please start the volume to access data复制模式,也称为AFR,相当于RAID1。即同一文件保存一份或多份副本,每个节点保存相同的内容和目录结构。复制模式因为要保存副本,所以磁盘利用率较低。如果多个节点上的存储空间不一致,那么将按照木桶效应取最低节点的容量作为该卷的总容量。在配置复制卷时,复制数必须等于卷中Brick所包含的存储服务器数,复制卷具备冗余性,即使一个节点损坏,也不影响数据的正常使用。
如图: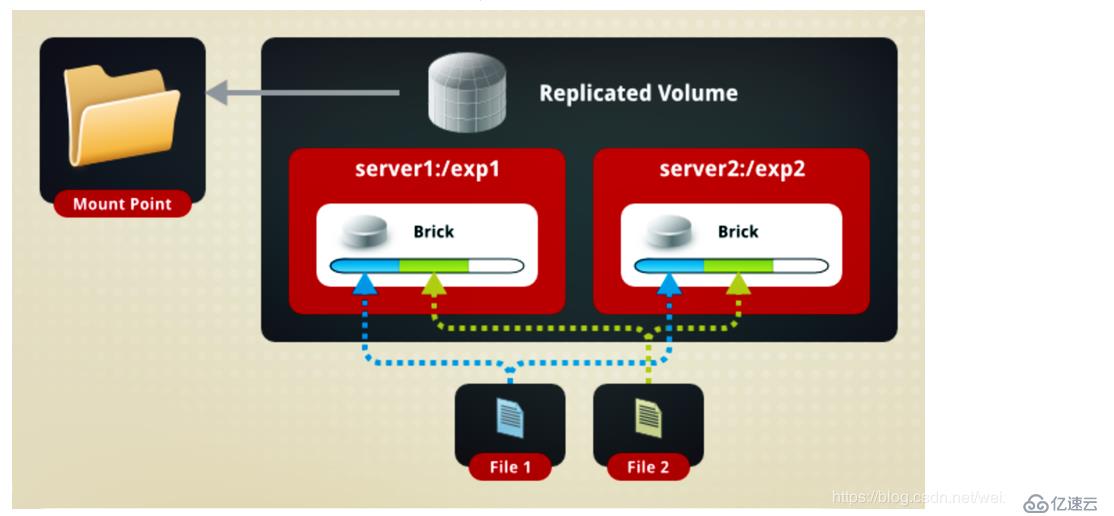
File1和File2同时存放在Server1和Server2上,相当于Server2中的文件是Server1中文件的副本!
复制卷具有以下特点:
- 卷中所有的服务器均保存一个完整的副本;
- 卷的副本数量可由客户创建的时候决定;
- 至少有两个块服务器或者更多的服务器;
- 具有冗余性;
创建复制卷的命令:
[root@localhost ~]# gluster volume create rep-volume replica 2 transport tcp server1:/dir1 server2:/dir2
//创建名为rep-volume的复制卷,文件将同时存储两个副本,分别在Server1:/dir1和Server2:/dir2两个Brick中
Creation of rep-volume has been successful
Please start the volume to access data分布式条带卷兼顾分布式和条带卷的功能,主要用于大文件访问处理,创建一个分布式条带卷最少需要4台服务器。
如图: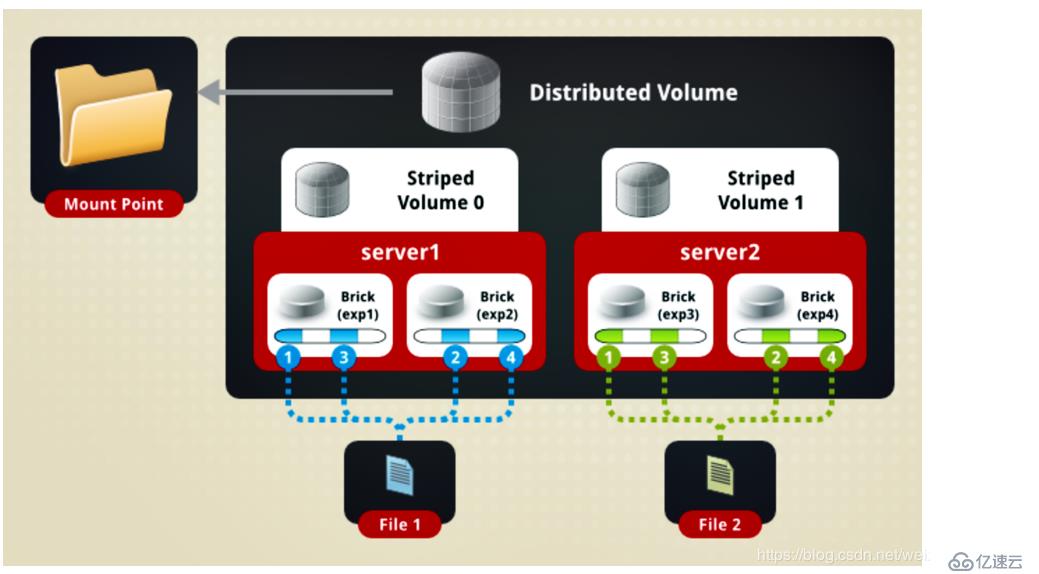
如图所示:File1和File2通过分布式卷的功能分别定位到Server1和Server2。在Server1中,File1被分割成4段,其中1、3在Server1中exp1目录中;2、4在Server1中的exp2目录中。在Server2中,File2也被分割成4段,与File1一样!
创建分布式条带卷的命令:
[root@localhost ~]# gluster volume create dis-stripe stripe 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
//创建了一个名为dis-stripe的分布式条带卷,配置分布式的条带卷时,卷中Brick所包含的存储服务器数必须是条带数的倍数(>=2倍)
Creation of rep-volume has been successful
Please start the volume to access data注意:创建卷时,存储服务器的数量如果等于条带或复制数,那么创建的是条带卷或复制卷;如果存储服务器的数量是条带卷或复制卷的2倍甚至更多,那么将创建分布式条带卷或分布式复制卷。
分布式复制卷兼顾分布式卷和复制卷的功能,主要用于需要冗余的情况下,如图:
如图所示:File1和File2通过分布式jaunty的功能分别定位到Server1和Server2。在存放File1时,File1根据复制卷的特性,将存在两个相同的副本,分别是Server1中的exp1目录和Server2中的exp2目录,在存放File2时,File2根据复制卷的特性,也将存在两个相同的副本,分别是Server3中的exp3目录和Server4中的exp4目录。
创建分布式复制卷的命令:
[root@localhost ~]# gluster volume create dis-rep replica 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
//创建了一个名为dis-rep的分布式条带卷,配置分布式的复制卷时,卷中Brick所包含的存储服务器数必须是条带数的倍数(>=2倍)
Creation of rep-volume has been successful
Please start the volume to access data假如存在8台服务器,当复制副本为2时,按照服务器列表的顺序,服务器1和2作为一个复制,服务器3和4作为一个复制,服务器5和6作为一个复制,服务器7和8作为一个复制;当复制副本为4时,按照服务器列表的顺序,服务器1/2/3./4作为一个复制,服务器5/6/7/8作为一个复制。
关于这些理论概念并不是很难,基本看一遍就能明白其中的意思,那这里也就不多说了!
这篇博文主要介绍理论,关于实战可以参考博文:部署GlusterFS分布式文件系统,实战!!!
———————— 本文至此结束,感谢阅读 ————————
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





