本文实例为大家分享了使用RNN进行文本分类,python代码实现,供大家参考,具体内容如下
1、本博客项目由来是oxford 的nlp 深度学习课程第三周作业,作业要求使用LSTM进行文本分类。和上一篇CNN文本分类类似,本此代码风格也是仿照sklearn风格,三步走形式(模型实体化,模型训练和模型预测)但因为训练时间较久不知道什么时候训练比较理想,因此在次基础上加入了继续训练的功能。
2、构造文本分类的rnn类,(保存文件为ClassifierRNN.py)
2.1 相应配置参数因为较为繁琐,不利于阅读,因此仿照tensorflow源码形式,将代码分成 网络配置参数 nn_config 和计算配置参数: calc_config,也相应声明了其对应的类:NN_config,CALC_config。
2.2 声明 ClassifierRNN类,该类的主要函数有:(init, build_inputs, build_rnns, build_loss, build_optimizer, random_batches,fit, load_model, predict_accuracy, predict),代码如下:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import os
import time
class NN_config(object):
def __init__(self,num_seqs=1000,num_steps=10,num_units=128,num_classes = 8,\
num_layers = 1,embedding_size=100,vocab_size = 10000,\
use_embeddings=False,embedding_init=None):
self.num_seqs = num_seqs
self.num_steps = num_steps
self.num_units = num_units
self.num_classes = num_classes
self.num_layers = num_layers
self.vocab_size = vocab_size
self.embedding_size = embedding_size
self.use_embeddings = use_embeddings
self.embedding_init = embedding_init
class CALC_config(object):
def __init__(self,batch_size=64,num_epoches = 20,learning_rate = 1.0e-3, \
keep_prob=0.5,show_every_steps = 10,save_every_steps=100):
self.batch_size = batch_size
self.num_epoches = num_epoches
self.learning_rate = learning_rate
self.keep_prob = keep_prob
self.show_every_steps = show_every_steps
self.save_every_steps = save_every_steps
class ClassifierRNN(object):
def __init__(self, nn_config, calc_config):
# assign revalent parameters
self.num_seqs = nn_config.num_seqs
self.num_steps = nn_config.num_steps
self.num_units = nn_config.num_units
self.num_layers = nn_config.num_layers
self.num_classes = nn_config.num_classes
self.embedding_size = nn_config.embedding_size
self.vocab_size = nn_config.vocab_size
self.use_embeddings = nn_config.use_embeddings
self.embedding_init = nn_config.embedding_init
# assign calc ravalant values
self.batch_size = calc_config.batch_size
self.num_epoches = calc_config.num_epoches
self.learning_rate = calc_config.learning_rate
self.train_keep_prob= calc_config.keep_prob
self.show_every_steps = calc_config.show_every_steps
self.save_every_steps = calc_config.save_every_steps
# create networks models
tf.reset_default_graph()
self.build_inputs()
self.build_rnns()
self.build_loss()
self.build_optimizer()
self.saver = tf.train.Saver()
def build_inputs(self):
with tf.name_scope('inputs'):
self.inputs = tf.placeholder(tf.int32, shape=[None,self.num_seqs],\
name='inputs')
self.targets = tf.placeholder(tf.int32, shape=[None, self.num_classes],\
name='classes')
self.keep_prob = tf.placeholder(tf.float32,name='keep_prob')
self.embedding_ph = tf.placeholder(tf.float32, name='embedding_ph')
if self.use_embeddings == False:
self.embeddings = tf.Variable(tf.random_uniform([self.vocab_size,\
self.embedding_size],-0.1,0.1),name='embedding_flase')
self.rnn_inputs = tf.nn.embedding_lookup(self.embeddings,self.inputs)
else:
embeddings = tf.Variable(tf.constant(0.0,shape=[self.vocab_size,self.embedding_size]),\
trainable=False,name='embeddings_true')
self.embeddings = embeddings.assign(self.embedding_ph)
self.rnn_inputs = tf.nn.embedding_lookup(self.embeddings,self.inputs)
print('self.rnn_inputs.shape:',self.rnn_inputs.shape)
def build_rnns(self):
def get_a_cell(num_units,keep_prob):
rnn_cell = tf.contrib.rnn.BasicLSTMCell(num_units=num_units)
drop = tf.contrib.rnn.DropoutWrapper(rnn_cell, output_keep_prob=keep_prob)
return drop
with tf.name_scope('rnns'):
self.cell = tf.contrib.rnn.MultiRNNCell([get_a_cell(self.num_units,self.keep_prob) for _ in range(self.num_layers)])
self.initial_state = self.cell.zero_state(self.batch_size,tf.float32)
self.outputs, self.final_state = tf.nn.dynamic_rnn(self.cell,tf.cast(self.rnn_inputs,tf.float32),\
initial_state = self.initial_state )
print('rnn_outputs',self.outputs.shape)
def build_loss(self):
with tf.name_scope('loss'):
self.logits = tf.contrib.layers.fully_connected(inputs = tf.reduce_mean(self.outputs, axis=1), \
num_outputs = self.num_classes, activation_fn = None)
print('self.logits.shape:',self.logits.shape)
self.cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=self.logits,\
labels = self.targets))
print('self.cost.shape',self.cost.shape)
self.predictions = self.logits
self.correct_predictions = tf.equal(tf.argmax(self.predictions, axis=1), tf.argmax(self.targets, axis=1))
self.accuracy = tf.reduce_mean(tf.cast(self.correct_predictions,tf.float32))
print(self.cost.shape)
print(self.correct_predictions.shape)
def build_optimizer(self):
with tf.name_scope('optimizer'):
self.optimizer = tf.train.AdamOptimizer(self.learning_rate).minimize(self.cost)
def random_batches(self,data,shuffle=True):
data = np.array(data)
data_size = len(data)
num_batches_per_epoch = int(data_size/self.batch_size)
#del data
for epoch in range(self.num_epoches):
if shuffle :
shuffle_index = np.random.permutation(np.arange(data_size))
shuffled_data = data[shuffle_index]
else:
shuffled_data = data
for batch_num in range(num_batches_per_epoch):
start = batch_num * self.batch_size
end = min(start + self.batch_size,data_size)
yield shuffled_data[start:end]
def fit(self,data,restart=False):
if restart :
self.load_model()
else:
self.session = tf.Session()
self.session.run(tf.global_variables_initializer())
with self.session as sess:
step = 0
accuracy_list = []
# model saving
save_path = os.path.abspath(os.path.join(os.path.curdir, 'models'))
if not os.path.exists(save_path):
os.makedirs(save_path)
plt.ion()
#new_state = sess.run(self.initial_state)
new_state = sess.run(self.initial_state)
batches = self.random_batches(data)
for batch in batches:
x,y = zip(*batch)
x = np.array(x)
y = np.array(y)
print(len(x),len(y),step)
step += 1
start = time.time()
if self.use_embeddings == False:
feed = {self.inputs :x,
self.targets:y,
self.keep_prob : self.train_keep_prob,
self.initial_state: new_state}
else:
feed = {self.inputs :x,
self.targets:y,
self.keep_prob : self.train_keep_prob,
self.initial_state: new_state,
self.embedding_ph: self.embedding_init}
batch_loss, new_state, batch_accuracy , _ = sess.run([self.cost,self.final_state,\
self.accuracy, self.optimizer],feed_dict = feed)
end = time.time()
accuracy_list.append(batch_accuracy)
# control the print lines
if step%self.show_every_steps == 0:
print('steps/epoch:{}/{}...'.format(step,self.num_epoches),
'loss:{:.4f}...'.format(batch_loss),
'{:.4f} sec/batch'.format((end - start)),
'batch_Accuracy:{:.4f}...'.format(batch_accuracy)
)
plt.plot(accuracy_list)
plt.pause(0.5)
if step%self.save_every_steps == 0:
self.saver.save(sess,os.path.join(save_path, 'model') ,global_step = step)
self.saver.save(sess, os.path.join(save_path, 'model'), global_step=step)
def load_model(self, start_path=None):
if start_path == None:
model_path = os.path.abspath(os.path.join(os.path.curdir,"models"))
ckpt = tf.train.get_checkpoint_state(model_path)
path = ckpt.model_checkpoint_path
print("this is the start path of model:",path)
self.session = tf.Session()
self.saver.restore(self.session, path)
print("Restored model parameters is complete!")
else:
self.session = tf.Session()
self.saver.restore(self.session,start_path)
print("Restored model parameters is complete!")
def predict_accuracy(self,data,test=True):
# loading_model
self.load_model()
sess = self.session
iterations = 0
accuracy_list = []
predictions = []
epoch_temp = self.num_epoches
self.num_epoches = 1
batches = self.random_batches(data,shuffle=False)
for batch in batches:
iterations += 1
x_inputs, y_inputs = zip(*batch)
x_inputs = np.array(x_inputs)
y_inputs = np.array(y_inputs)
if self.use_embeddings == False:
feed = {self.inputs: x_inputs,
self.targets: y_inputs,
self.keep_prob: 1.0}
else:
feed = {self.inputs: x_inputs,
self.targets: y_inputs,
self.keep_prob: 1.0,
self.embedding_ph: self.embedding_init}
to_train = [self.cost, self.final_state, self.predictions,self.accuracy]
batch_loss,new_state,batch_pred,batch_accuracy = sess.run(to_train, feed_dict = feed)
accuracy_list.append(np.mean(batch_accuracy))
predictions.append(batch_pred)
print('The trainning step is {0}'.format(iterations),\
'trainning_accuracy: {:.3f}'.format(accuracy_list[-1]))
accuracy = np.mean(accuracy_list)
predictions = [list(pred) for pred in predictions]
predictions = [p for pred in predictions for p in pred]
predictions = np.array(predictions)
self.num_epoches = epoch_temp
if test :
return predictions, accuracy
else:
return accuracy
def predict(self, data):
# load_model
self.load_model()
sess = self.session
iterations = 0
predictionss = []
epoch_temp = self.num_epoches
self.num_epoches = 1
batches = self.random_batches(data)
for batch in batches:
x_inputs = batch
if self.use_embeddings == False:
feed = {self.inputs : x_inputs,
self.keep_prob:1.0}
else:
feed = {self.inputs : x_inputs,
self.keep_prob:1.0,
self.embedding_ph: self.embedding_init}
batch_pred = sess.run([self.predictions],feed_dict=feed)
predictions.append(batch_pred)
predictions = [list(pred) for pred in predictions]
predictions = [p for pred in predictions for p in pred]
predictions = np.array(predictions)
return predictions3、 进行模型数据的导入以及处理和模型训练,集中在一个处理文件中(sampling_trainning.py)
相应代码如下:
ps:在下面文档用用到glove的文档,这个可网上搜索进行相应的下载,下载后需要将glove对应的生成格式转化成word2vec对应的格式,就是在文件头步加入一行 两个整数(字典的数目和嵌入的特征长度),也可用python库自带的转化工具,网上进行相应使用方法的搜索便可。
import numpy as np
import os
import time
import matplotlib.pyplot as plt
import tensorflow as tf
import re
import urllib.request
import zipfile
import lxml.etree
from collections import Counter
from random import shuffle
from gensim.models import KeyedVectors
# Download the dataset if it's not already there
if not os.path.isfile('ted_en-20160408.zip'):
urllib.request.urlretrieve("https://wit3.fbk.eu/get.php?path=XML_releases/xml/ted_en-20160408.zip&filename=ted_en-20160408.zip", filename="ted_en-20160408.zip")
# extract both the texts and the labels from the xml file
with zipfile.ZipFile('ted_en-20160408.zip', 'r') as z:
doc = lxml.etree.parse(z.open('ted_en-20160408.xml', 'r'))
texts = doc.xpath('//content/text()')
labels = doc.xpath('//head/keywords/text()')
del doc
print("There are {} input texts, each a long string with text and punctuation.".format(len(texts)))
print("")
print(texts[0][:100])
# method remove unused words and labels
inputs_text = [ re.sub(r'\([^)]*\)',' ', text) for text in texts]
inputs_text = [re.sub(r':', ' ', text) for text in inputs_text]
#inputs_text = [text.split() for text in inputs_text]
print(inputs_text[0][0:100])
inputs_text = [ text.lower() for text in texts]
inputs_text = [ re.sub(r'([^a-z0-9\s])', r' <\1_token> ',text) for text in inputs_text]
#input_texts = [re.sub(r'([^a-z0-9\s])', r' <\1_token> ', input_text) for input_text in input_texts]
inputs_text = [text.split() for text in inputs_text]
print(inputs_text[0][0:100])
# label procession
label_lookup = ['ooo','Too','oEo','ooD','TEo','ToD','oED','TED']
new_label = []
for i in range(len(labels)):
labels_pre = ['o','o','o']
label = labels[i].split(', ')
#print(label,i)
if 'technology' in label:
labels_pre[0] = 'T'
if 'entertainment' in label:
labels_pre[1] = 'E'
if 'design' in label:
labels_pre[2] = 'D'
labels_temp = ''.join(labels_pre)
label_index = label_lookup.index(labels_temp)
new_label.append(label_index)
print('the length of labels:{0}'.format(len(new_label)))
print(new_label[0:50])
labels_index = np.zeros((len(new_label),8))
#for i in range(labels_index.shape[0]):
# labels_index[i,new_label[i]] = 1
labels_index[range(len(new_label)),new_label] = 1.0
print(labels_index[0:10])
# feature selections
unions = list(zip(inputs_text,labels_index))
unions = [union for union in unions if len(union[0]) >300]
print(len(unions))
inputs_text, labels_index = zip(*unions)
inputs_text = list(inputs_text)
labels = list(labels_index)
print(inputs_text[0][0:50])
print(labels_index[0:10])
# feature filttering
all_context = [word for text in inputs_text for word in text]
print('the present datas word is :{0}'.format(len(all_context)))
words_count = Counter(all_context)
most_words = [word for word, count in words_count.most_common(50)]
once_words = [word for word, count in words_count.most_common() if count == 1]
print('there {0} words only once to be removed'.format(len(once_words)))
print(most_words)
#print(once_words)
remove_words = set(most_words + once_words)
#print(remove_words)
inputs_new = [[word for word in text if word not in remove_words] for text in inputs_text]
new_all_counts =[word for text in inputs_new for word in text]
print('there new all context length is:{0}'.format(len(new_all_counts)))
# word2index and index2word processings
words_voca = set([word for text in inputs_new for word in text])
word2index = {}
index2word = {}
for i, word in enumerate(words_voca):
word2index[word] = i
index2word[i] = word
inputs_index = []
for text in inputs_new:
inputs_index.append([word2index[word] for word in text])
print(len(inputs_index))
print(inputs_index[0][0:100])
model_glove = KeyedVectors.load_word2vec_format('glove.6B.300d.txt', binary=False)
n_features = 300
embeddings = np.random.uniform(-0.1,0.1,(len(word2index),n_features))
inwords = 0
for word in words_voca:
if word in model_glove.vocab:
inwords += 1
embeddings[word2index[word]] = model_glove[word]
print('there {} words in model_glove'.format(inwords))
print('The voca_word in presents text is:{0}'.format(len(words_voca)))
print('the precentage of words in glove is:{0}'.format(np.float(inwords)/len(words_voca)))
# truncate the sequence length
max_length = 1000
inputs_concat = []
for text in inputs_index:
if len(text)>max_length:
inputs_concat.append(text[0:max_length])
else:
inputs_concat.append(text + [0]*(max_length-len(text)))
print(len(inputs_concat))
inputs_index = inputs_concat
print(len(inputs_index))
# sampling the train data use category sampling
num_class = 8
label_unions = list(zip(inputs_index,labels_index))
print(len(label_unions))
trains = []
devs = []
tests = []
for c in range(num_class):
type_sample = [union for union in label_unions if np.argmax(union[1]) == c]
print('the length of this type length',len(type_sample),c)
shuffle(type_sample)
num_all = len(type_sample)
num_train = int(num_all*0.8)
num_dev = int(num_all*0.9)
trains.extend(type_sample[0:num_train])
devs.extend(type_sample[num_train:num_dev])
tests.extend(type_sample[num_dev:num_all])
shuffle(trains)
shuffle(devs)
shuffle(tests)
print('the length of trains is:{0}'.format(len(trains)))
print('the length of devs is:{0}'.format(len(devs)))
print('the length of tests is:{0}'.format(len(tests)))
#--------------------------------------------------------------------
#------------------------ model processing --------------------------
#--------------------------------------------------------------------
from ClassifierRNN import NN_config,CALC_config,ClassifierRNN
# parameters used by rnns
num_layers = 1
num_units = 60
num_seqs = 1000
step_length = 10
num_steps = int(num_seqs/step_length)
embedding_size = 300
num_classes = 8
n_words = len(words_voca)
# parameters used by trainning models
batch_size = 64
num_epoch = 100
learning_rate = 0.0075
show_every_epoch = 10
nn_config = NN_config(num_seqs =num_seqs,\
num_steps = num_steps,\
num_units = num_units,\
num_classes = num_classes,\
num_layers = num_layers,\
vocab_size = n_words,\
embedding_size = embedding_size,\
use_embeddings = False,\
embedding_init = embeddings)
calc_config = CALC_config(batch_size = batch_size,\
num_epoches = num_epoch,\
learning_rate = learning_rate,\
show_every_steps = 10,\
save_every_steps = 100)
print("this is checking of nn_config:\\\n",
"out of num_seqs:{}\n".format(nn_config.num_seqs),
"out of num_steps:{}\n".format(nn_config.num_steps),
"out of num_units:{}\n".format(nn_config.num_units),
"out of num_classes:{}\n".format(nn_config.num_classes),
"out of num_layers:{}\n".format(nn_config.num_layers),
"out of vocab_size:{}\n".format(nn_config.vocab_size),
"out of embedding_size:{}\n".format(nn_config.embedding_size),
"out of use_embeddings:{}\n".format(nn_config.use_embeddings))
print("this is checing of calc_config: \\\n",
"out of batch_size {} \n".format(calc_config.batch_size),
"out of num_epoches {} \n".format(calc_config.num_epoches),
"out of learning_rate {} \n".format(calc_config.learning_rate),
"out of keep_prob {} \n".format(calc_config.keep_prob),
"out of show_every_steps {} \n".format(calc_config.show_every_steps),
"out of save_every_steps {} \n".format(calc_config.save_every_steps))
rnn_model = ClassifierRNN(nn_config,calc_config)
rnn_model.fit(trains,restart=False)
accuracy = rnn_model.predict_accuracy(devs,test=False)
print("Final accuracy of devs is {}".format(accuracy))
test_accuracy = rnn_model.predict_accuracy(tests,test=False)
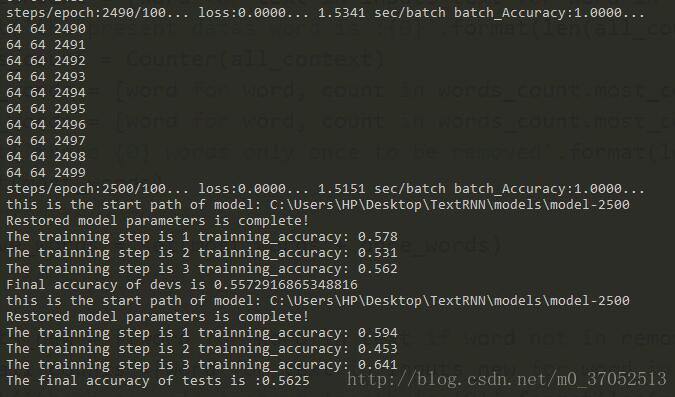
print("The final accuracy of tests is :{}".format(test_accuracy)) 4、模型评估, 因为在本次算例中模型数据较少,总共有2000多个样本,相对较少,因此难免出现过拟合的状态,rnn在训练trains样本时其准确率为接近1.0 但在进行devs和tests集合验证的时候,发现准确率为6.0左右,可适当的增加l2 但不在本算例考虑范围内,将本模型用于IMDB算例计算的时候,相抵25000个样本的时候的准确率为89.0%左右。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



