еҰӮдҪ•и§ЈеҶіPython requestsеә“зј–з Ғsocks5д»ЈзҗҶзҡ„й—®йўҳ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іеҰӮдҪ•и§ЈеҶіPython requestsеә“зј–з Ғsocks5д»ЈзҗҶзҡ„й—®йўҳпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
зј–з Ғй—®йўҳ
response = requests.get(URL, params=params,
headers=headers, timeout=10)
print 'self.encoding',response.encoding
output:
self.encoding ISO-8859-1
жҹҘдәҶдёҖдәӣзӣёе…ізҡ„иө„ж–ҷпјҢзңӢдәҶдёӢrequestsзҡ„жәҗз ҒпјҢеҸӘжңүеңЁжңҚеҠЎеҷЁе“Қеә”зҡ„еӨҙйғЁеҢ…еҗ«жңүContent-TypeпјҢдё”йҮҢйқўжңүcharsetдҝЎжҒҜпјҢrequestsиғҪеӨҹжӯЈзЎ®иҜҶеҲ«пјҢеҗҰеҲҷе°ұдјҡдҪҝз”Ёй»ҳи®Өзҡ„ ISO-8859-1зј–з ҒгҖӮgithubдёӯд№ҹжңүи®Ёи®әиҝҷдёӘй—®йўҳ,дҪҶrequestsзҡ„дҪңиҖ…们иҜҙжҳҜж №жҚ®rfcжқҘзҡ„.
еңЁдёҠиҝ°д»Јз ҒдёӯпјҢresponse.text жҳҜrequestsеә“иҝ”еӣһе“Қеә”зҡ„Unicodeзј–з ҒеҶ…е®№
иҝҷж ·,еҪ“жҲ‘们еҺ»иҺ·еҸ–дёҖдәӣдёӯж–ҮзҪ‘йЎөзҡ„е“Қеә”еҶ…е®№ж—¶,дё”е…¶е“Қеә”еӨҙйғЁжІЎжңүcharsetдҝЎжҒҜ,еҲҷresponse.textзҡ„зј–з Ғе°ұдјҡжңүй—®йўҳ(requestsзҡ„json()ж–№жі•д№ҹеҸ—иҝҷдёӘзј–з ҒеҪұе“Қ)
жҜ”еҰӮ,жҲ‘зҲ¬еҸ–зҷҫеәҰзҡ„зҪ‘йЎөзҡ„ж—¶еҖҷ,е…¶дёӯж–ҮжҳҜutf-8зј–з Ғзҡ„
еҰӮдёӢpython2.7д»Јз Ғ
In [14]: a = 'зәҰ' #utf-8зј–з Ғ
In [15]: a
Out[15]: '\xe7\xba\xa6'
In [22]: b=a.decode('ISO-8859-1')#response.text и®Өдёәе“Қеә”еҶ…е®№жҳҜISO-8859-1зј–з Ғ,е°Ҷе…¶decodeдёәUnicode
In [23]: b
Out[23]: u'\xe7\xba\xa6'
In [26]: c=b.encode('utf8')#еҰӮжһңжҲ‘们没жңүжіЁж„ҸISO-8859-1,зӣҙжҺҘд»Ҙutf8еҜ№е…¶иҝӣиЎҢзј–з Ғ
In [27]: c
Out[27]: '\xc3\xa7\xc2\xba\xc2\xa6'#йӮЈд№Ҳencodeеҫ—еҲ°зҡ„utf-8,еңЁжҳҫзӨәеҷЁдёҠжҳҫзӨәзҡ„е°ұжҳҜд№ұз Ғ,еӣ дёә'зәҰ'зҡ„utf-8зј–з ҒжҳҜ'\xe7\xba\xa6'и§ЈеҶіж–№жі•1: з”Ёresponse.content ,response.content in bytes,жүҖд»Ҙз”ЁcontentеҸҜд»ҘиҮӘе·ұеҶіе®ҡеҜ№е…¶зҡ„зј–з Ғ
и§ЈеҶіж–№жі•2: иҺ·еҫ—иҜ·жұӮеҗҺдҪҝз”Ё response.encoding = вҖҳutf-8'
и§ЈеҶіж–№жі•3: еҲ©з”Ёrequestsеә“йҮҢж №жҚ®иҺ·еҫ—е“Қеә”еҶ…е®№жқҘеҲӨж–ӯзј–з Ғзҡ„еҮҪж•°,еҸӮиҖғж–ҮзҢ®йҮҢжңүи®ІеҲ°
python2зҡ„зј–з ҒиҝҳжҳҜеҫҲд№ұзҡ„ strеҸҜд»ҘжҳҜеҗ„з§Қзј–з Ғ,python3з»ҹдёҖstrдёәUnicode, byteеҸҜд»ҘжҳҜеҗ„з§Қзј–з Ғ
python2дёӯencodeеҗҺжҳҜstrзұ»еһӢ,decodeеҗҺжҳҜUnicodeзұ»еһӢ,python3дёӯencodeеҗҺжҳҜbyteзұ»еһӢ,decodeеҗҺжҳҜstrзұ»еһӢ(Unicodeзј–з Ғ)
з”Ёpython3еҗ§,дёӢйқўжҳҜpython3зҡ„д»Јз Ғ
In [13]: a = 'зәҰ' #Unicode
In [14]: type(a)
Out[14]: str
In [15]: b=a.encode('utf8')
In [16]: b
Out[16]: b'\xe7\xba\xa6'
In [17]: type(b)
Out[17]: bytes
In [27]: b'\xe7\xba\xa623,000'.decode('ISO-8859-1')
Out[27]: '约23,000'
In [28]: type(b'\xe7\xba\xa623,000'.decode('ISO-8859-1'))
Out[28]: str
In [29]: b'\xe7\xba\xa623,000'.decode('utf8')
Out[29]: 'зәҰ23,000'socks5д»ЈзҗҶй—®йўҳ
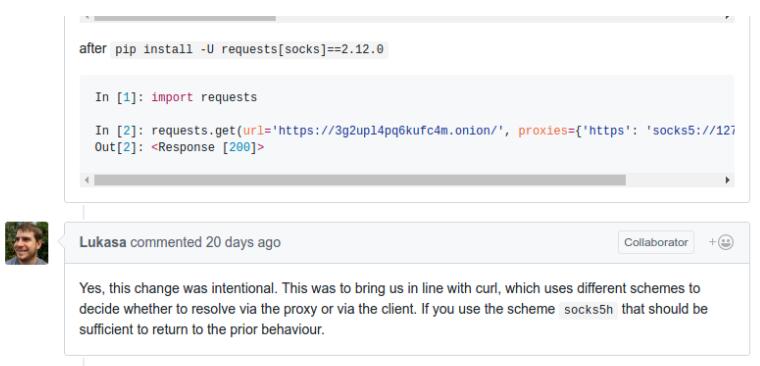
зҺ°еңЁзҡ„requests2.13.0зҡ„socks5д»ЈзҗҶжҲ‘еңЁдҪҝз”Ёзҡ„ж—¶еҖҷдјҡеҮәзҺ°й—®йўҳ,
жҲ‘з”Ёзҡ„д»ЈзҗҶжҳҜshadowsocks,жҜ”еҰӮжҲ‘жғіиҰҒи®ҝй—®https://www.facebook.com еңЁеҗ‘жң¬ең°127.0.0.1:1080з«ҜеҸЈеҸ‘йҖҒsocks5иҜ·жұӮж—¶,жҲ‘еҸ‘зҺ°shadowsocksеңЁеҗ‘дёҖдёӘIPең°еқҖиҝһжҺҘ,иҝһжҺҘдёҚдёҠ,жҲ‘з”ЁchromeиҝһжҺҘFacebookзҡ„ж—¶еҖҷ,жҲ‘еҸ‘зҺ°shadowsocksжҳҜеңЁеҗ‘www.facebook.comиҝһжҺҘ,иғҪеӨҹжҲҗеҠҹиҝһжҺҘ,еә”иҜҘжҳҜDNSи§Јжһҗй—®йўҳ,еҮәзҺ°дәҶйҮҚеӨҚи§Јжһҗзҡ„й—®йўҳ,дҪҝз”Ёrequests2.12дёҚдјҡжңүиҝҷдёӘй—®йўҳ,еңЁgithubдёҠд№ҹжүҫеҲ°дәҶзӣёе…ізҡ„issue
import requests
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/56.0.2924.87 Safari/537.36'}
proxies = {'http': 'socks5://127.0.0.1:1080','https':'socks5://127.0.0.1:1080'}
url = 'https://www.facebook.com'
response = requests.get(url, proxies=proxies)
print(response.content)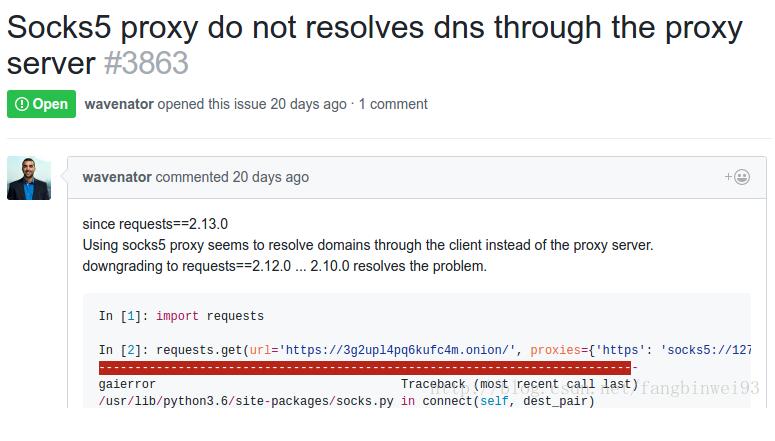
е…ідәҺвҖңеҰӮдҪ•и§ЈеҶіPython requestsеә“зј–з Ғsocks5д»ЈзҗҶзҡ„й—®йўҳвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





