дҝқиҜҒLinuxзі»з»ҹе®үе…Ёд№ӢеҲҶжһҗе’ҢжҺ’жҹҘзі»з»ҹж•…йҡң
еңЁеӨ„зҗҶLinuxж“ҚдҪңзі»з»ҹеҮәзҺ°зҡ„еҗ„з§Қж•…йҡңж—¶пјҢж•…йҡңзҡ„з—ҮзҠ¶жҳҜжңҖе®№жҳ“еҸ‘зҺ°зҡ„пјҢдҪҶеҜјиҮҙж•…йҡңзҡ„еҺҹеӣ жүҚжҳҜжңҖз»ҲжҺ’йҷӨж•…йҡңзҡ„е…ій”®гҖӮзҶҹжӮүLinuxж“ҚдҪңзі»з»ҹдёӯеёёи§Ғзҡ„ж—Ҙеҝ—ж–Ү件пјҢдәҶи§ЈдёҖиҲ¬ж•…йҡңзҡ„еҲҶжһҗдёҺи§ЈеҶіеҠһжі•пјҢе°ҶжңүеҠ©дәҺз®ЎзҗҶе‘ҳеҝ«йҖҹе®ҡдҪҚж•…йҡңзӮ№пјҢвҖңеҜ№з—ҮдёӢиҚҜвҖқпјҢеҸҠж—¶и§ЈеҶіеҗ„з§Қзі»з»ҹй—®йўҳгҖӮ
еҚҡж–ҮеӨ§зәІпјҡ
дёҖгҖҒеҲҶжһҗж—Ҙеҝ—ж–Ү件пјӣ
дәҢгҖҒжҺ’йҷӨзі»з»ҹеҗҜеҠЁзұ»ж•…йҡңпјӣ
дёүгҖҒжҺ’йҷӨж–Ү件系з»ҹзұ»ж•…йҡңпјӣ
дёҖгҖҒеҲҶжһҗж—Ҙеҝ—ж–Ү件
ж—Ҙеҝ—ж–Ү件жҳҜз”ЁдәҺи®°еҪ•Linuxж“ҚдҪңзі»з»ҹдёӯеҗ„з§ҚиҝҗиЎҢж¶ҲжҒҜзҡ„ж–Ү件пјҢзӣёеҪ“дәҺLinuxдё»жңәзҡ„вҖңж—Ҙи®°вҖқгҖӮдёҚеҗҢзҡ„ж—Ҙеҝ—ж–Ү件记иҪҪдәҶдёҚеҗҢзұ»еһӢзҡ„дҝЎжҒҜпјҢеҰӮLinuxеҶ…ж ёж¶ҲжҒҜгҖҒз”ЁжҲ·зҷ»еҪ•дәӢ件гҖҒзЁӢеәҸй”ҷиҜҜзӯүгҖӮ
ж—Ҙеҝ—ж–Ү件еҜ№дәҺиҜҠж–ӯе’Ңи§ЈеҶізі»з»ҹдёӯзҡ„й—®йўҳеҫҲжңүеё®еҠ©пјҢеӣ дёәеңЁLinuxж“ҚдҪңзі»з»ҹдёӯиҝҗиЎҢзҡ„зЁӢеәҸйҖҡеёёдјҡжҠҠзі»з»ҹж¶ҲжҒҜе’Ңй”ҷиҜҜж¶ҲжҒҜеҶҷе…Ҙзӣёеә”зҡ„ж—Ҙеҝ—ж–Ү件пјҢиҝҷж ·зі»з»ҹдёҖж—ҰеҮәзҺ°й—®йўҳе°ұдјҡвҖңжңүжҚ®еҸҜжҹҘвҖқпјҢжӯӨеӨ–пјҢеҪ“дё»жңәйҒӯеҸ— з ҙеқҸж—¶пјҢж—Ҙеҝ—ж–Ү件иҝҳеҸҜд»Ҙеё®еҠ©еҜ»жүҫз ҙеқҸ иҖ…з•ҷдёӢеҲ«зҡ„з—•иҝ№гҖӮ
1.дё»иҰҒж—Ҙеҝ—ж–Ү件
еңЁLinuxж“ҚдҪңзі»з»ҹдёӯпјҢж—Ҙеҝ—ж•°жҚ®дё»иҰҒеҢ…жӢ¬д»ҘдёӢдёүз§Қзұ»еһӢпјҡ
- еҶ…ж ёеҸҠзі»з»ҹж—Ҙеҝ—пјҡиҝҷз§Қж—Ҙеҝ—ж•°жҚ®з”ұзі»з»ҹжңҚеҠЎrsyslogз»ҹдёҖз®ЎзҗҶпјҢж №жҚ®е…¶дё»й…ҚзҪ®ж–Ү件/etc/rsyslog.confдёӯзҡ„и®ҫзҪ®еҶіе®ҡе°ҶеҶ…ж ёж¶ҲжҒҜеҸҠеҗ„з§Қзі»з»ҹзЁӢеәҸж¶ҲжҒҜи®°еҪ•еҲ°д»Җд№ҲдҪҚзҪ®гҖӮ зі»з»ҹдёӯжңүзӣёеҪ“дёҖйғЁеҲҶзЁӢеәҸдјҡжҠҠиҮӘе·ұзҡ„ж—Ҙеҝ—ж–Ү件дәӨз”ұrsyslogз®ЎзҗҶпјҢеӣ иҖҢиҝҷдәӣзЁӢеәҸдҪҝз”Ёзҡ„ж—Ҙеҝ—и®°еҪ•д№ҹе…·жңүзӣёдјјзҡ„ж јејҸпјӣ
- з”ЁжҲ·ж—Ҙеҝ—пјҡиҝҷз§Қж—Ҙеҝ—ж•°жҚ®з”ЁдәҺи®°еҪ•Linuxж“ҚдҪңзі»з»ҹз”ЁжҲ·зҷ»еҪ•еҸҠйҖҖеҮәзі»з»ҹзҡ„зӣёе…ідҝЎжҒҜпјҢеҢ…жӢ¬з”ЁжҲ·еҗҚгҖҒзҷ»еҪ•зҡ„з»Ҳз«ҜгҖҒзҷ»еҪ•ж—¶й—ҙгҖҒжқҘжәҗдё»жңәгҖҒжӯЈеңЁдҪҝз”Ёзҡ„иҝӣзЁӢж“ҚдҪңзӯүпјӣ
- зЁӢеәҸж—Ҙеҝ—пјҡжңүдәӣеә”з”ЁзЁӢеәҸдјҡйҖүжӢ©з”ұиҮӘе·ұзӢ¬з«Ӣз®ЎзҗҶдёҖд»Ҫж—Ҙеҝ—ж–Ү件пјҲиҖҢдёҚжҳҜдәӨз»ҷrsyslogжңҚеҠЎз®ЎзҗҶпјүпјҢз”ЁдәҺи®°еҪ•жң¬зЁӢеәҸиҝҗиЎҢиҝҮзЁӢдёӯзҡ„еҗ„з§ҚдәӢ件дҝЎжҒҜгҖӮз”ұдәҺиҝҷдәӣзЁӢеәҸеҸӘиҙҹиҙЈз®ЎзҗҶиҮӘе·ұзҡ„ж—Ҙеҝ—ж–Ү件пјҢеӣ жӯӨдёҚеҗҢзЁӢеәҸжүҖдҪҝз”Ёзҡ„ж—Ҙеҝ—и®°еҪ•ж јејҸеҸҜиғҪдјҡеӯҳеңЁиҫғеӨ§зҡ„е·®ејӮпјӣ
Linuxж“ҚдҪңзі»з»ҹжң¬иә«е’ҢеӨ§йғЁеҲҶзҡ„жңҚеҠЎеҷЁзЁӢеәҸзҡ„ж—Ҙеҝ—ж–Ү件йғҪй»ҳи®Өж”ҫеңЁзӣ®еҪ•/var/log/дёӢгҖӮдёҖйғЁеҲҶзЁӢеәҸе…¬з”ЁдёҖдёӘж—Ҙеҝ—ж–Ү件пјҢдёҖйғЁеҲҶзЁӢеәҸдҪҝз”ЁеҚ•дёӘж—Ҙеҝ—ж–Ү件пјӣиҖҢжңүдәӣеӨ§еһӢзҡ„жңҚеҠЎзЁӢеәҸз”ұдәҺж—Ҙеҝ—ж–Ү件дёҚжӯўдёҖдёӘпјҢжүҖд»ҘдјҡеңЁ/var/log/зӣ®еҪ•дёӯе»әз«Ӣзӣёеә”зҡ„еӯҗзӣ®еҪ•жқҘеӯҳж”ҫж—Ҙеҝ—ж–Ү件пјҢиҝҷж ·ж—ўдҝқиҜҒдәҶж—Ҙеҝ—ж–Ү件зӣ®еҪ•зҡ„з»“жһ„жё…жҷ°пјҢеҸҲеҸҜд»Ҙеҝ«йҖҹе®ҡдҪҚж—Ҙеҝ—ж–Ү件гҖӮжңүзӣёеҪ“дёҖйғЁеҲҶж—Ҙеҝ—ж–Ү件еҸӘжңүrootз”ЁжҲ·жүҚжңүжқғйҷҗиҜ»еҸ–пјҢиҝҷдҝқиҜҒдәҶзӣёе…ідҝЎжҒҜзҡ„е®үе…ЁжҖ§гҖӮ
еҜ№дәҺLinuxж“ҚдҪңзі»з»ҹдёӯзҡ„ж—Ҙеҝ—ж–Ү件пјҢжңүеҝ…иҰҒдәҶи§Је…¶еҗ„иҮӘзҡ„з”ЁйҖ”пјҢиҝҷж ·жүҚиғҪеңЁйңҖиҰҒзҡ„ж—¶еҖҷжӣҙеҝ«ең°жүҫеҲ°й—®йўҳжүҖеңЁгҖҒеҸҠж—¶ең°и§ЈеҶіеҗ„з§Қж•…йҡңгҖӮ
еёёи§Ғзҡ„дёҖдәӣж—Ҙеҝ—ж–Ү件пјҢеҰӮеӣҫпјҡ

2.ж—Ҙеҝ—ж–Ү件еҲҶжһҗ
еҲҶжһҗж—Ҙеҝ—ж–Ү件зҡ„зӣ®зҡ„еңЁдәҺйҖҡиҝҮжөҸи§Ҳж—Ҙеҝ—жҹҘжүҫе…ій”®дҝЎжҒҜпјҢеҜ№зі»з»ҹжңҚеҠЎиҝӣиЎҢи°ғиҜ•пјҢд»ҘеҸҠеҲӨж–ӯеҸ‘з”ҹж•…йҡңзҡ„еҺҹеӣ зӯүгҖӮ
еҜ№дәҺеӨ§еӨҡж•°ж–Үжң¬ж јејҸзҡ„ж—Ҙеҝ—ж–Ү件пјҲеҰӮеҶ…ж ёеҸҠзі»з»ҹж—Ҙеҝ—гҖҒеӨ§еӨҡж•°зҡ„зЁӢеәҸж—Ҙеҝ—пјүпјҢеҸҜд»ҘдҪҝз”ЁtailгҖҒmoreгҖҒcatгҖҒlessзӯүе‘Ҫд»ӨиҝӣиЎҢжҹҘзңӢпјҢеҜ№дәҺдёҖдәӣзү№ж®Ҡзҡ„дәҢиҝӣеҲ¶зҡ„ж—Ҙеҝ—ж–Ү件пјҲеҰӮз”ЁжҲ·ж—Ҙеҝ—пјүеҲҷйңҖиҰҒдҪҝз”Ёзү№е®ҡзҡ„жҹҘиҜўе‘Ҫд»ӨгҖӮ
пјҲ1пјүеҶ…ж ёеҸҠзі»з»ҹж—Ҙеҝ—
rsyslogжңҚеҠЎжүҖдҪҝз”Ёзҡ„й…ҚзҪ®ж–Ү件дёә/etc/rsyslog.confгҖӮ
[root@localhost ~]# grep -v "^$" /etc/rsyslog.conf
//иҝҮж»Өз©әиЎҢ
# rsyslog configuration file
# For more information see /usr/share/doc/rsyslog-*/rsyslog_conf.html
# If you experience problems, see http://www.rsyslog.com/doc/troubleshoot.html
#### MODULES ####
# The imjournal module bellow is now used as a message source instead of imuxsock.
$ModLoad imuxsock # provides support for local system logging (e.g. via logger command)
вҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰ //зңҒз•ҘйғЁеҲҶеҶ…е®№
д»Һй…ҚзҪ®ж–Ү件дёӯеҸҜд»ҘзңӢеҮәпјҢеҸ—rsyslogжңҚеҠЎз®ЎзҗҶзҡ„ж—Ҙеҝ—ж–Ү件йғҪжҳҜLinuxж“ҚдҪңзі»з»ҹдёӯдё»иҰҒзҡ„ж—Ҙеҝ—ж–Ү件пјҢе®ғ们记еҪ•дәҶLinuxж“ҚдҪңзі»з»ҹдёӯеҶ…ж ёгҖҒз”ЁжҲ·и®ӨиҜҒгҖҒз”өеӯҗйӮ®д»¶гҖҒи®ЎеҲ’д»»еҠЎзӯүеҹәжң¬зҡ„зі»з»ҹж¶ҲжҒҜгҖӮеңЁLinuxеҶ…ж ёдёӯпјҢж №жҚ®ж—Ҙеҝ—ж¶ҲжҒҜзҡ„йҮҚиҰҒзЁӢеәҰдёҚеҗҢпјҢе°Ҷе…¶еҲҶдёәдёҚеҗҢзҡ„дјҳе…Ҳзә§еҲ«пјҲж•°еӯ—и¶Ҡе°ҸпјҢдјҳе…Ҳзә§и¶Ҡй«ҳпјҢж¶ҲжҒҜи¶ҠйҮҚиҰҒпјүгҖӮеҰӮеӣҫпјҡ

еҶ…ж ёеҸҠеӨ§еӨҡж•°зі»з»ҹж¶ҲжҒҜиў«и®°еҪ•еҲ°е…¬е…ұж—Ҙеҝ—ж–Ү件/var/log/messagesдёӯпјҢиҖҢе…¶д»–дёҖдәӣзЁӢеәҸж¶ҲжҒҜиў«и®°еҪ•еҲ°еҗ„иҮӘзӢ¬з«Ӣзҡ„ж—Ҙеҝ—ж–Ү件дёӯпјҢжӯӨеӨ–ж—Ҙеҝ—ж¶ҲжҒҜиҝҳиғҪеӨҹи®°еҪ•еҲ°зү№е®ҡзҡ„еӯҳеӮЁи®ҫеӨҮдёӯпјҢжҲ–иҖ…зӣҙжҺҘеҸ‘йҖҒз»ҷжҢҮе®ҡз”ЁжҲ·гҖӮ
еҜ№дәҺrsyslogжңҚеҠЎз»ҹдёҖз®ЎзҗҶзҡ„еӨ§йғЁеҲҶж—Ҙеҝ—ж–Ү件пјҢдҪҝз”Ёзҡ„ж—Ҙеҝ—и®°еҪ•ж јејҸеҹәжң¬дёҠжҳҜзӣёеҗҢзҡ„гҖӮд»Ҙе…¬е…ұж—Ҙеҝ—/var/log/messagesж–Ү件зҡ„и®°еҪ•ж јејҸдёәдҫӢпјҢе…¶дёӯжҜҸдёҖиЎҢиЎЁзӨәдёҖжқЎж—Ҙеҝ—ж¶ҲжҒҜпјҢжҜҸдёҖжқЎж¶ҲжҒҜеқҮеҢ…жӢ¬д»ҘдёӢеӣӣдёӘеӯ—ж®өпјҡ
- ж—¶й—ҙж Үзӯҫпјҡж¶ҲжҒҜеҸ‘еҮәзҡ„ж—Ҙжңҹе’Ңж—¶й—ҙпјӣ
- дё»жңәеҗҚпјҡз”ҹжҲҗж¶ҲжҒҜзҡ„и®Ўз®—жңәеҗҚз§°пјӣ
- еӯҗзі»з»ҹеҗҚз§°пјҡеҸ‘еҮәж¶ҲжҒҜзҡ„еә”з”ЁзЁӢеәҸзҡ„еҗҚз§°пјӣ
- ж¶ҲжҒҜпјҡж¶ҲжҒҜзҡ„е…·дҪ“еҶ…е®№пјӣ
еңЁжңүдәӣжғ…еҶөдёӢпјҢеҸҜд»Ҙи®ҫзҪ®rsyslogпјҢдҪҝе…¶еңЁжҠҠж—Ҙеҝ—дҝЎжҒҜи®°еҪ•еҲ°ж–Ү件зҡ„еҗҢж—¶е°Ҷж—Ҙеҝ—дҝЎжҒҜеҸ‘йҖҒеҲ°жү“еҚ°жңәиҝӣиЎҢжү“еҚ°пјҢиҝҷж ·ж— и®әзҪ‘з»ң йқһжі•иҝӣе…Ҙ иҖ…жҖҺд№Ҳдҝ®ж”№ж—Ҙеҝ—йғҪдёҚиғҪжё…йҷӨ***зҡ„з—•иҝ№гҖӮrsyslogж—Ҙеҝ—жңҚеҠЎжҳҜдёҖдёӘеёёиў« з ҙеқҸ зҡ„зҡ„жҳҫи‘—зӣ®ж ҮпјҢз ҙеқҸдәҶе®ғе°Ҷз®ЎзҗҶе‘ҳйҡҫд»ҘеҸ‘зҺ° йқһжі•иҝӣе…Ҙ еҸҠзӣёе…ідҝЎжҒҜпјҢеӣ жӯӨиҰҒзү№еҲ«жіЁж„Ҹзӣ‘жҺ§е…¶е®ҲжҠӨиҝӣзЁӢеҸҠй…ҚзҪ®ж–Ү件гҖӮ
пјҲ2пјүз”ЁжҲ·ж—Ҙеҝ—
еңЁwtmpгҖҒbtmpгҖҒlastlogзӯүж—Ҙеҝ—ж–Ү件дёӯпјҢдҝқеӯҳдәҶзі»з»ҹз”ЁжҲ·зҷ»еҪ•гҖҒйҖҖеҮәзӯүзӣёе…ізҡ„ж—¶й—ҙж¶ҲжҒҜгҖӮдҪҶжҳҜиҝҷдәӣж–Ү件йғҪжҳҜдәҢиҝӣеҲ¶зҡ„ж•°жҚ®ж–Ү件пјҢдёҚиғҪзӣҙжҺҘдҪҝз”ЁtailгҖҒlessзӯүж–Үжң¬жҹҘзңӢе·Ҙе…·иҝӣиЎҢжөҸи§ҲпјҢйңҖиҰҒдҪҝз”ЁwhoгҖҒwгҖҒusersгҖҒlastе’Ңlastbзӯүз”ЁжҲ·жҹҘиҜўе‘Ҫд»ӨжқҘиҺ·еҸ–ж—Ҙеҝ—дҝЎжҒҜгҖӮ
1пјүжҹҘиҜўеҪ“еүҚзҷ»еҪ•зҡ„з”ЁжҲ·жғ…еҶөвҖ”вҖ”usersгҖҒwhoгҖҒwе‘Ҫд»Ө
userе‘Ҫд»ӨеҸӘжҳҜз®ҖеҚ•ең°иҫ“еҮәеҪ“еүҚзҷ»еҪ•зҡ„з”ЁжҲ·еҗҚз§°пјҢжҜҸдёӘжҳҫзӨәзҡ„з”ЁжҲ·еҗҚеҜ№еә”дёҖдёӘзҷ»еҪ•дјҡиҜқгҖӮеҰӮжһңдёҖдёӘз”ЁжҲ·жңүдёҚжӯўдёҖдёӘзҷ»еҪ•дјҡиҜқпјҢйӮЈд№Ҳд»–зҡ„з”ЁжҲ·еҗҚе°ҶжҳҫзӨәдёҺе…¶зӣёеҗҢзҡ„ж¬Ўж•°гҖӮж“ҚдҪңеҰӮдёӢпјҡ
[root@localhost ~]# users
(unknown) root root root
whoе‘Ҫд»Өз”ЁдәҺжҠҘе‘ҠеҪ“еүҚзҷ»еҪ•еҲ°зі»з»ҹдёӯзҡ„жҜҸдёӘз”ЁжҲ·зҡ„дҝЎжҒҜгҖӮдҪҝз”ЁиҜҘе‘Ҫд»ӨпјҢзі»з»ҹз®ЎзҗҶе‘ҳеҸҜд»ҘжҹҘзңӢеҪ“еүҚзі»з»ҹеӯҳеңЁе“ӘдәӣдёҚеҗҲжі•зҡ„з”ЁжҲ·пјҢд»ҺиҖҢеҜ№е…¶иҝӣиЎҢе®Ўи®Ўе’ҢеӨ„зҗҶгҖӮwhoзҡ„й»ҳи®Өиҫ“еҮәеҢ…жӢ¬з”ЁжҲ·еҗҚгҖҒз»Ҳз«Ҝзұ»еһӢгҖҒзҷ»еҪ•ж—ҘжңҹеҸҠиҝңзЁӢдё»жңәгҖӮж“ҚдҪңеҰӮдёӢпјҡ
[root@localhost ~]# who
(unknown) :0 2019-09-10 00:01 (:0)
root tty2 2019-09-10 00:10
root pts/0 2019-09-09 16:25 (192.168.1.253)
root tty3 2019-09-09 16:42
wе‘Ҫд»Өз”ЁдәҺжҳҫзӨәеҪ“еүҚзі»з»ҹдёӯзҡ„жҜҸдёӘз”ЁжҲ·еҸҠе…¶иҝҗиЎҢзҡ„иҝӣзЁӢдҝЎжҒҜпјҢжҜ”usersгҖҒwhoе‘Ҫд»Өзҡ„иҫ“еҮәеҶ…е®№жӣҙдё°еҜҢдёҖдәӣпјҢж“ҚдҪңеҰӮдёӢпјҡ
[root@localhost ~]# w
16:49:29 up 48 min, 4 users, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCU WHAT
root tty2 00:10 ? 0.84s 0.84s -bash
root pts/0 192.168.1.253 16:25 1.00s 0.10s 0.06s w
root tty3 16:42 ? 0.08s 0.03s -bash
2пјүжҹҘиҜўз”ЁжҲ·зҷ»еҪ•зҡ„еҺҶеҸІи®°еҪ•вҖ”вҖ”lastгҖҒlastbе‘Ҫд»Ө
lastе‘Ҫд»Өз”ЁдәҺжҹҘиҜўжҲҗеҠҹзҷ»еҪ•еҲ°зі»з»ҹзҡ„з”ЁжҲ·и®°еҪ•пјҢжңҖиҝ‘зҡ„зҷ»еҪ•жғ…еҶөе°ҶжҳҫзӨәеңЁжңҖеүҚйқўгҖӮ
[root@localhost ~]# last
xiaoli tty3 Thu Sep 12 04:49 still logged in
root pts/0 192.168.1.253 Thu Sep 12 04:47 still logged in
root tty2 Thu Sep 12 04:46 still logged in
lastbе‘Ҫд»Өз”ЁдәҺжҹҘиҜўзҷ»еҪ•еӨұиҙҘзҡ„з”ЁжҲ·и®°еҪ•пјҢеҰӮзҷ»еҪ•зҡ„з”ЁжҲ·еҗҚй”ҷиҜҜпјҢеҜҶз ҒдёҚжӯЈзЎ®зӯүжғ…еҶөйғҪе°Ҷи®°еҪ•дёӢжқҘгҖӮ
[root@localhost ~]# lastb
xiaowang tty3 Thu Sep 12 04:52 - 04:52 (00:00)
xiaoli tty3 Thu Sep 12 04:52 - 04:52 (00:00)
йҷӨдәҶдҪҝз”Ёlastbе‘Ҫд»Өд»ҘеӨ–пјҢиҝҳеҸҜд»ҘжҹҘзңӢе®үе…Ёж—Ҙеҝ—/var/log/secureгҖӮжҹҘзңӢж—Ҙеҝ—ж–Ү件еҸҜд»ҘдҪҝз”ЁwebalizerгҖҒAwstatsиҪҜ件еҸҜд»ҘйҖҡиҝҮеӣҫеҪўеҢ–жҹҘзңӢж—Ҙеҝ—пјҢйҖҡдҝ—жҳ“жҮӮпјҒ
3пјүзЁӢеәҸж—Ҙеҝ—
еңЁLinuxж“ҚдҪңзі»з»ҹдёӯпјҢиҝҳжңүзӣёеҪ“дёҖйғЁеҲҶеә”з”ЁзЁӢеәҸжІЎжңүдҪҝз”ЁrsyslogжңҚеҠЎжқҘз®ЎзҗҶж—Ҙеҝ—пјҢиҖҢжҳҜз”ұзЁӢеәҸиҮӘе·ұз»ҙжҠӨж—Ҙеҝ—и®°еҪ•гҖӮдҫӢеҰӮпјҡhttpзҪ‘з«ҷжңҚеҠЎзӯүгҖӮдёҚеҗҢеә”з”ЁзЁӢеәҸiзҡ„ж—Ҙеҝ—и®°еҪ•ж јејҸе·®еҲ«еҫҲеӨ§пјҢдё”жІЎжңүдёҘж јдҪҝз”Ёз»ҹдёҖзҡ„ж јејҸгҖӮ
дҪңдёәдёҖеҗҚеҗҲж јзҡ„зі»з»ҹз®ЎзҗҶдәәе‘ҳпјҢеә”иҜҘжҸҗй«ҳиӯҰжғ•пјҢйҡҸж—¶жіЁж„Ҹеҗ„з§ҚеҸҜз–‘зҠ¶еҶөпјҢе®ҡжңҹ并йҡҸжңәжЈҖжҹҘеҗ„з§Қзі»з»ҹж—Ҙеҝ—ж–Ү件пјҢеҢ…жӢ¬дёҖиҲ¬дҝЎжҒҜж—Ҙеҝ—гҖҒзҪ‘з»ңиҝһжҺҘж—Ҙеҝ—гҖҒж–Үд»¶дј иҫ“ж—Ҙеҝ—еҸҠз”ЁжҲ·зҷ»еҪ•ж—Ҙеҝ—и®°еҪ•зӯүгҖӮеңЁжЈҖжҹҘиҝҷдәӣж—Ҙеҝ—ж—¶пјҢиҰҒжіЁж„ҸжҳҜеҗҰжңүдёҚе’ҢеёёзҗҶзҡ„ж—¶й—ҙжҲ–ж“ҚдҪңи®°еҪ•гҖӮ
еҮәзҺ°д»ҘдёӢжғ…еҶөд№ӢдёҖпјҢе°ұйңҖиҰҒеӨҡеҠ жіЁж„Ҹпјҡ
- з”ЁжҲ·еңЁйқһ常规зҡ„ж—¶й—ҙзҷ»еҪ•пјҢжҲ–иҖ…з”ЁжҲ·зҷ»еҪ•зі»з»ҹзҡ„IPең°еқҖе’ҢеҫҖеёёзҡ„дёҚдёҖж ·пјӣ
- з”ЁжҲ·зҷ»еҪ•еӨұиҙҘзҡ„ж—Ҙеҝ—и®°еҪ•пјҢе°Өе…¶жҳҜйӮЈдәӣдёҖеҶҚиҝһз»ӯе°қиҜ•иҝӣе…Ҙзі»з»ҹеӨұиҙҘзҡ„ж—Ҙеҝ—и®°еҪ•пјӣ
- йқһжі•дҪҝз”ЁжҲ–дёҚжӯЈеҪ“дҪҝз”Ёи¶…зә§з”ЁжҲ·жқғйҷҗпјӣ
- ж— ж•…жҲ–иҖ…йқһжі•йҮҚж–°еҗҜеҠЁеҗ„йЎ№зҪ‘з»ңжңҚеҠЎзҡ„и®°еҪ•пјӣ
- дёҚжӯЈеёёзҡ„ж—Ҙеҝ—и®°еҪ•пјҢеҰӮж—Ҙеҝ—ж®ӢзјәдёҚе…ЁпјҢжҲ–иҖ…жҜ”еҰӮwtmpиҝҷж ·зҡ„ж—Ҙеҝ—ж–Үд»¶ж— ж•…зјәе°‘дәҶдёӯй—ҙзҡ„и®°еҪ•ж–Ү件гҖӮ
еҸҰеӨ–пјҢйңҖиҰҒз®ЎзҗҶдәәе‘ҳжіЁж„Ҹзҡ„жҳҜпјҢж—Ҙеҝ—并дёҚжҳҜе®Ңе…ЁеҸҜйқ зҡ„пјҢиҒӘжҳҺзҡ„й»‘ е®ўеңЁиҝӣе…Ҙзі»з»ҹеҗҺз»ҸиҝҮдјҡжү“жү«зҺ°еңәгҖӮжүҖд»Ҙз®ЎзҗҶдәәе‘ҳйңҖиҰҒз»јеҗҲиҝҗз”Ёд»ҘдёҠзҡ„зі»з»ҹе‘Ҫд»ӨпјҢе…ЁйқўгҖҒз»јеҗҲең°иҝӣиЎҢе®ЎжҹҘе’ҢжЈҖжөӢгҖӮеҲҮи®°дёҚиҰҒж–ӯз« еҸ–д№үпјҢеҗҰеҲҷе°ҶдјҡеҒҡеҮәй”ҷиҜҜзҡ„еҲӨж–ӯгҖӮ
дәҢгҖҒжҺ’йҷӨзі»з»ҹеҗҜеҠЁзұ»ж•…йҡң
Linuxж“ҚдҪңзі»з»ҹзҡ„еҗҜеҠЁиҝҮзЁӢж¶үеҸҠеҲ°MBRгҖҒGRUBеҗҜеҠЁиҸңеҚ•гҖҒзі»з»ҹеҲқе§ӢеҢ–й…ҚзҪ®ж–Ү件зӯүеҗ„ж–№йқўпјҢе…¶дёӯд»»дҪ•дёҖдёӘзҺҜиҠӮеҮәзҺ°ж•…йҡңйғҪеҸҜиғҪеҜјиҮҙзі»з»ҹеҗҜеҠЁеӨұеёёпјҢеӣ жӯӨдёҖе®ҡиҰҒеңЁжіЁж„ҸеҘҪзӣёе…іж–Ү件зҡ„еӨҮд»Ҫе·ҘдҪңгҖӮ
1.MBRжүҮеҢәж•…йҡң
MBRжүҮеҢәеҢ…жӢ¬дёүйғЁеҲҶпјҡ
- зі»з»ҹеј•еҜјзЁӢеәҸпјҲGRUBеј•еҜјиҸңеҚ•еҚ з”Ё446еӯ—иҠӮпјүпјӣ
- еҲҶеҢәиЎЁпјҲжңҖеӨҡеҸҜд»ҘжңүеӣӣдёӘдё»еҲҶеҢәпјҢжҜҸдёӘеҲҶеҢәеҚ з”Ё16еӯ—иҠӮпјүпјӣ
- жүҮеҢәзҡ„з»“жқҹж Үеҝ—еҚ з”Ё2еӯ—иҠӮпјӣ
MBRдҪҚдәҺзү©зҗҶзЎ¬зӣҳзҡ„第дёҖдёӘжүҮеҢәпјҲ512еӯ—иҠӮпјүпјҢиҜҘжүҮеҢәеҸҲз§°дёәдё»еј•еҜјжүҮеҢәпјҲMBRжүҮеҢәпјүпјҢйҷӨдәҶеҢ…еҗ«зі»з»ҹеј•еҜјзЁӢеәҸзҡ„йғЁеҲҶж•°жҚ®еӨ–йғЁеҲҶж•°жҚ®еӨ–пјҢиҝҳеҢ…еҗ«ж•ҙдёӘзЎ¬зӣҳзҡ„еҲҶеҢәиЎЁи®°еҪ•гҖӮеҪ“дё»еј•еҜјжүҮеҢәеҸ‘з”ҹж•…йҡңж—¶пјҢе°ҶеҫҲжңүеҸҜиғҪж— жі•иҝӣе…Ҙеј•еҜјжүҚж•ЈпјҢжҲ–иҖ…ж— жі•жүҫеҲ°жӯЈзЎ®зҡ„еҲҶеҢәдҪҚзҪ®иҖҢж— жі•еҠ иҪҪзі»з»ҹпјҢйҖҡиҝҮиҜҘзЎ¬зӣҳеј•еҜјдё»жңәж—¶еҫҲеҸҜиғҪиҝӣе…Ҙй»‘еұҸгҖҒжӯ»жңәзҠ¶жҖҒгҖӮ
йҖҡиҝҮдёӢйқўзӨәдҫӢжҲ‘们ејҖе§ӢеҜ№MBRжүҮеҢәиҝӣиЎҢеӨҮд»ҪгҖҒжЁЎжӢҹз ҙеқҸгҖҒдҝ®еӨҚзҡ„иҝҮзЁӢпјҡ
пјҲ1пјүеӨҮд»ҪMBRжүҮеҢәж•°жҚ®
з”ұдәҺMBRжүҮеҢәдёӯеҢ…еҗ«дәҶж•ҙдёӘзЎ¬зӣҳзҡ„еҲҶеҢәиЎЁи®°еҪ•пјҢеӣ жӯӨиҜҘжүҮеҢәзҡ„еӨҮд»Ҫж–Ү件еҝ…йЎ»еӯҳж”ҫеҲ°е…¶д»–зҡ„еӯҳеӮЁи®ҫеӨҮдёӯпјҢеҗҰеҲҷеңЁжҒўеӨҚж—¶е°Ҷж— жі•иҜ»еҸ–еҲ°еӨҮд»Ҫж–Ү件гҖӮдҫӢеҰӮпјҡ
[root@localhost ~]# mkdir /backup
[root@localhost ~]# mount /dev/sdb1 /backup
[root@localhost ~]# dd if=/dev/sda of=/backup/sda.mbr.bak bs=512 count=1
//дҪҝз”Ёddе‘Ҫд»Өе°Ҷ第дёҖеқ—зЎ¬зӣҳдёӯзҡ„MBRжүҮеҢәж•°жҚ®еӨҮд»ҪеҲ°з¬¬дәҢеқ—зЎ¬зӣҳsdb1еҲҶеҢәдёӯ
е…ідәҺзЎ¬зӣҳеҲҶеҢәзӯүиҜҰз»Ҷжғ…еҶөеҸҜд»ҘеҸӮиҖғеҚҡж–ҮпјҡLinuxзЈҒзӣҳе’Ңж–Ү件系з»ҹз®ЎзҗҶпјҲдёҖпјү
пјҲ2пјүжЁЎжӢҹMBRжүҮеҢәж•…йҡң
[root@localhost ~]# dd if=/dev/zero of=/dev/sda bs=512 count=1
//дҪҝз”Ё/dev/zeroпјҲж— йҷҗеҶҷйӣ¶пјүж–Ү件иҰҶзӣ–еҺҹжң¬зҡ„MBRжүҮеҢәж•°жҚ®
зі»з»ҹйҮҚеҗҜпјҢе°ҶдјҡеҮәзҺ°вҖңOperating system not foundвҖқзҡ„жҸҗзӨәдҝЎжҒҜпјҢиЎЁзӨәж— жі•жүҫеҲ°еҸҜз”Ёзҡ„ж“ҚдҪңзі»з»ҹпјҢеӣ жӯӨж— жі•еҗҜеҠЁдё»жңәгҖӮ
пјҲ3пјүд»ҺеӨҮд»Ҫж–Ү件дёӯжҒўеӨҚMBRжүҮеҢәж•°жҚ®
з”ұдәҺMBRжүҮеҢәиў«з ҙеқҸд»ҘеҗҺпјҢе°ұж— жі•еҶҚд»ҺзЎ¬зӣҳеҗҜеҠЁзі»з»ҹеҢ–пјҢжүҖд»ҘйңҖиҰҒдҪҝз”Ёе…¶д»–зЎ¬зӣҳдёӯзҡ„ж“ҚдҪңзі»з»ҹиҝӣиЎҢеј•еҜјпјҢжҲ–иҖ…дҪҝз”ЁCentosзі»з»ҹзҡ„е®үиЈ…е…үзӣҳиҝӣиЎҢеј•еҜјпјҢдёҚз®ЎдҪҝз”Ёд»Җд№Ҳж–№ејҸпјҢзӣ®зҡ„йғҪжҳҜзӣёеҗҢзҡ„вҖ”вҖ”иҺ·еҫ—дёҖдёӘеҸҜд»Ҙжү§иЎҢе‘Ҫд»Өзҡ„ShellзҺҜеўғпјҢд»Ҙдҫҝд»ҺеӨҮд»Ҫж–Ү件дёӯжҒўеӨҚMBRжүҮеҢәдёӯзҡ„ж•°жҚ®гҖӮ
жҲ‘们дҪҝз”Ёзі»з»ҹзӣҳеј•еҜјдёәдҫӢпјҢж“ҚдҪңеҰӮеӣҫпјҡ
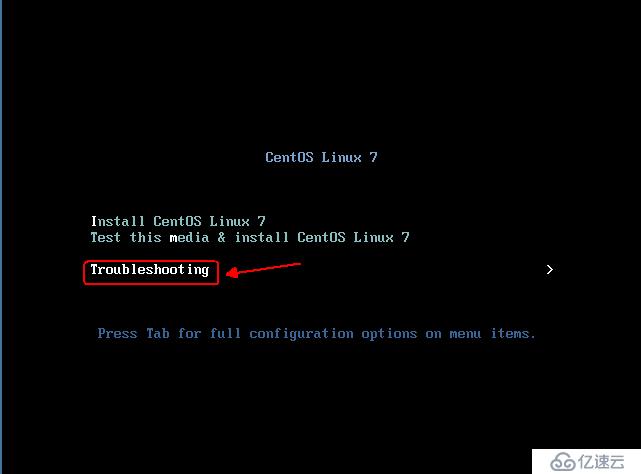

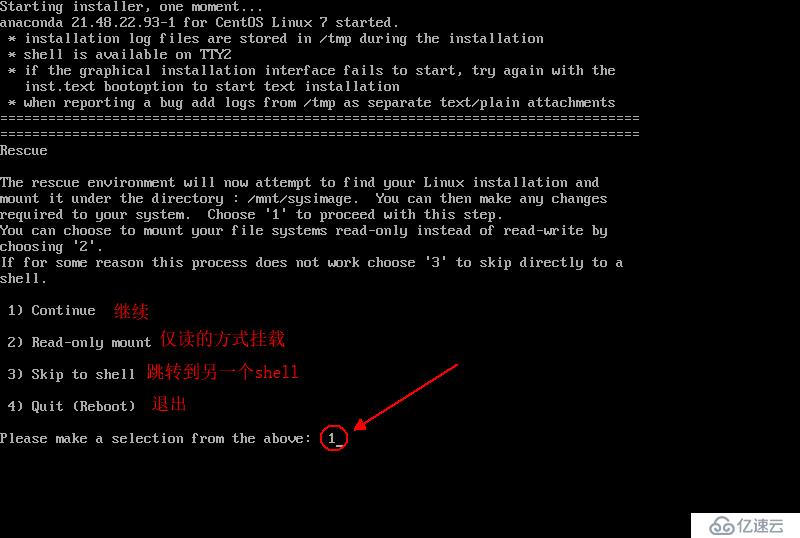
е®ҢжҲҗд»ҘдёҠж“ҚдҪңеҗҺпјҢе°ұдјҡеҮәзҺ°дёҖдёӘеёҰвҖңsh-4.2#вҖқжҸҗзӨәз¬Ұзҡ„bashзҺҜеўғпјҢеҰӮеӣҫпјҡ

е®ҢжҲҗжҒўеӨҚж“ҚдҪңд»ҘеҗҺпјҢжү§иЎҢвҖңexitвҖқе‘Ҫд»ӨйҖҖеҮәеҪ“еүҚдёҙж—¶shellзҺҜеўғпјҢзі»з»ҹе°ҶдјҡиҮӘеҠЁйҮҚеҗҜпјҒ
2.GRUBеј•еҜјиҸңеҚ•ж•…йҡң
GRUBжҳҜеӨ§еӨҡж•°Linuxж“ҚдҪңзі»з»ҹй»ҳи®ӨдҪҝз”Ёзҡ„еј•еҜјзЁӢеәҸпјҢеҸҜд»ҘйҖҡиҝҮеҗҜеҠЁиҸңеҚ•зҡ„ж–№ејҸйҖүжӢ©иҝӣе…ҘдёҚеҗҢзҡ„ж“ҚдҪңзі»з»ҹпјҲеҰӮжһңжңүеҲ«зҡ„зі»з»ҹпјүпјҢеҪ“й…ҚзҪ®ж–Ү件/boot/grub2/grub.cfg дёўеӨұпјҢжҲ–иҖ…е…ій”®й…ҚзҪ®еҮәзҺ°й”ҷиҜҜпјҢжҲ–иҖ…MBRдёӯзҡ„еј•еҜјзЁӢеәҸйҒӯеҲ°з ҙеқҸж—¶пјҢ
жҸҗеүҚеӨҮд»Ҫgrubй…ҚзҪ®ж–Ү件пјҡ
[root@localhost ~]# vim /boot/grub2/grub.cfg
[root@localhost ~]# mv /boot/grub2/grub.cfg /boot/grub2/grub.cfg.bak
//е°ҶеҺҹжң¬зҡ„grubй…ҚзҪ®ж–Ү件改еҗҚ
йҮҚеҗҜд№ӢеҗҺпјҢLinuxдё»жңәеҗҜеҠЁеҗҺеҸҜиғҪдјҡеҮәзҺ°вҖңgrub>вҖқзҡ„жҸҗзӨәз¬ҰпјҢж— жі•е®ҢжҲҗиҝӣдёҖжӯҘзҡ„зі»з»ҹеҗҜеҠЁиҝҮзЁӢгҖӮеҰӮеӣҫпјҡ
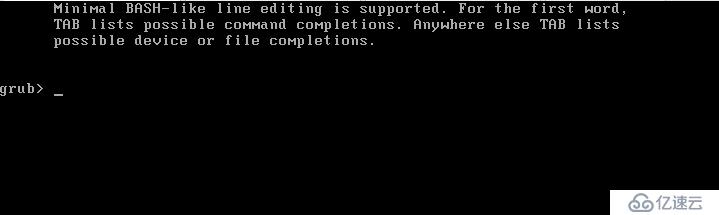
и§ЈеҶіж–№жЎҲпјҡ
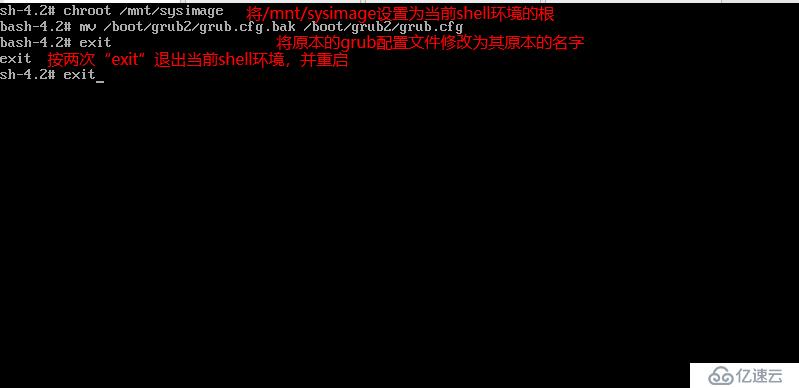
иҝӣе…ҘжҖҘж•‘жЁЎејҸпјҢеҰӮеӣҫпјҡ
е®ҢжҲҗд»ҘдёҠж“ҚдҪңеҗҺпјҢе°ұдјҡеҮәзҺ°дёҖдёӘеёҰвҖңsh-4.2#вҖқжҸҗзӨәз¬Ұзҡ„bashзҺҜеўғпјҢе…·дҪ“ж“ҚдҪңе‘Ҫд»ӨеҰӮеӣҫпјҡ
еҪ“йҖүжӢ©еҗҜеҠЁж–№ејҸдёәе…үзӣҳеҗҜеҠЁж—¶пјҢе»әи®®дҝ®ж”№е®ҢжҲҗд№ӢеҗҺдҫқ然йҖүжӢ©зЎ¬зӣҳеҗҜеҠЁпјҢд№ҹеҸҜд»Ҙж №жҚ®е…үзӣҳеҗҜеҠЁзҡ„жҸҗзӨәдҝЎжҒҜжүӢе·ҘйҖүжӢ©жң¬ең°зЎ¬зӣҳеҗҜеҠЁпјҢеҰӮеӣҫпјҡ
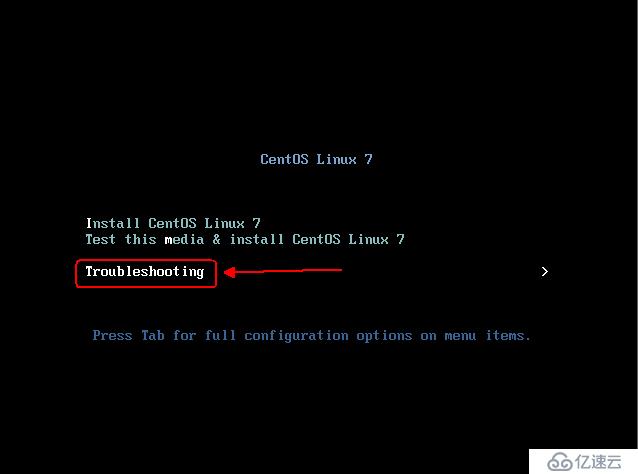
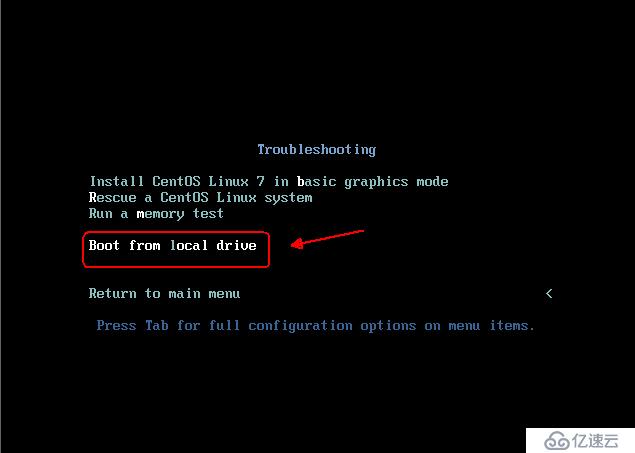
е®ҢжҲҗд»ҘеҗҺж“ҚдҪңеҗҺпјҢзі»з»ҹе°ұеҸҜжӯЈеёёеҗҜеҠЁпјҒ
жіЁж„ҸпјҡCentOS7еӣ дёәдҪҝз”Ёзҡ„жҳҜgrub2пјҢй…ҚзҪ®ж–Ү件еҗҢgrubжңүдёҚе°‘еҸҳеҢ–пјҢдёҖе®ҡиҰҒеҲҮи®°еӨҮд»Ҫgrub.cfgд»ҘдҫҝжҒўеӨҚгҖӮ
йҒ—еҝҳrootеҜҶз ҒеҸҜд»ҘеҸӮиҖғеҚҡж–ҮпјҡйҒ—еҝҳLinuxзі»з»ҹrootеҜҶз ҒжүҖйҮҮеҸ–зҡ„еҝ…иҰҒжҺӘж–Ҫ
ж— и®әжҳҜMBRжүҮеҢәж•…йҡңгҖҒGRUBеј•еҜјиҸңеҚ•иҝҳжҳҜйҒ—еҝҳrootеҜҶз Ғзӣёе…іж“ҚдҪңпјҢйғҪеҸҜиҝӣе…ҘжҖҘж•‘жЁЎејҸиҝӣиЎҢдҝ®еӨҚгҖӮ
дёүгҖҒжҺ’йҷӨж–Ү件系з»ҹзұ»ж•…йҡң
ж–Ү件系з»ҹеҸҠзЈҒзӣҳдёӯжүҖеӯҳеӮЁзҡ„ж•°жҚ®зҡ„д»·еҖјжҳҜж— жі•дј°йҮҸзҡ„пјҢз®ЎзҗҶе‘ҳзҡ„е·ҘдҪңиҒҢиҙЈд№ӢдёҖе°ұжҳҜеҝ…йЎ»зЎ®дҝқж•°жҚ®зҡ„е®үе…ЁгҖӮз”ұдәҺзЈҒзӣҳеұһдәҺжҳ“жҚҹиҖ—е“ҒпјҢж— жі•йў„дј°е®ғд»Җд№Ҳж—¶еҖҷдјҡжҚҹеқҸпјҢжүҖд»ҘжңҖеҘҪзҡ„еҠһжі•е°ұжҳҜе»әз«Ӣе®Ңж•ҙзҡ„еӨҮд»ҪжңәеҲ¶гҖӮеҪ“зі»з»ҹеҮәзҺ°ж–Ү件系з»ҹжҲ–зЈҒзӣҳж•…йҡңж—¶жІЎдёҖе®ҡиҰҒж…ҺйҮҚеӨ„зҗҶгҖӮ
1.дҝ®еӨҚж–Ү件系з»ҹ
еңЁLinuxдё»жңәдёӯпјҢеҸҜиғҪдјҡеӣ дёәйқһжӯЈеёёе…іжңәгҖҒзӘҒ然ж–ӯз”өгҖҒи®ҫеӨҮж•°жҚ®иҜ»еҶҷејӮеёёзӯүеҺҹеӣ еҜјиҮҙж–Ү件系з»ҹз ҙеқҸгҖӮжҜ”иҫғеёёи§Ғзҡ„жҳҜи¶…зә§еҝ«жҚҹеқҸгҖӮи¶…зә§еҝ«жҳҜж–Ү件系з»ҹзҡ„ж ёеҝғвҖңжЎЈжЎҲвҖқпјҢе®ғи®°еҪ•дәҶиҜҘж–Ү件系з»ҹзҡ„зұ»еһӢгҖҒеӨ§е°ҸгҖҒз©әй—ІзЈҒзӣҳеқ—зӯүдҝЎжҒҜгҖӮ
еҪ“ж–Ү件系з»ҹзҡ„и¶…зә§еқ—ж•°жҚ®жҚҹеқҸжҳҜпјҢLinuxе°Ҷж— жі•иҜҶеҲ«иҜҘж–Ү件系з»ҹпјҢжҢӮиҪҪж—¶дјҡеҮәзҺ°й”ҷиҜҜжҸҗзӨәд»ҘиҮҙдёҚиғҪжӯЈеёёдҪҝз”ЁгҖӮжү§иЎҢдёӢеҲ—ж“ҚдҪңеҸҜд»Ҙз ҙеқҸж–Ү件зҡ„и¶…зә§еқ—ж•°жҚ®еә“гҖӮе‘Ҫд»ӨеҰӮдёӢпјҡ
[root@localhost ~]# dd if=/dev/zero of=/dev/sdb1 bs=512 count=4
и®°еҪ•дәҶ4+0 зҡ„иҜ»е…Ҙ
и®°еҪ•дәҶ4+0 зҡ„еҶҷеҮә
2048еӯ—иҠӮ(2.0 kB)е·ІеӨҚеҲ¶пјҢ0.000868901 з§’пјҢ2.4 MB/з§’
[root@localhost ~]# mkdir /a
[root@localhost ~]# mount /dev/sdb1 /a
mount: /dev/sdb1 еҶҷдҝқжҠӨпјҢе°Ҷд»ҘеҸӘиҜ»ж–№ејҸжҢӮиҪҪ
mount: жңӘзҹҘзҡ„ж–Ү件系з»ҹзұ»еһӢвҖң(null)вҖқ
[root@localhost ~]# vim /etc/fstab
вҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰ //зңҒз•ҘйғЁеҲҶеҶ…е®№
/dev/sdb1 /a xfs defaults 0 1
//е®һзҺ°иҮӘеҠЁжҢӮиҪҪ
йҮҚеҗҜзі»з»ҹеҗҺпјҢдјҡеҮәзҺ°д»ҘдёӢй”ҷиҜҜпјҢеҰӮеӣҫпјҡ
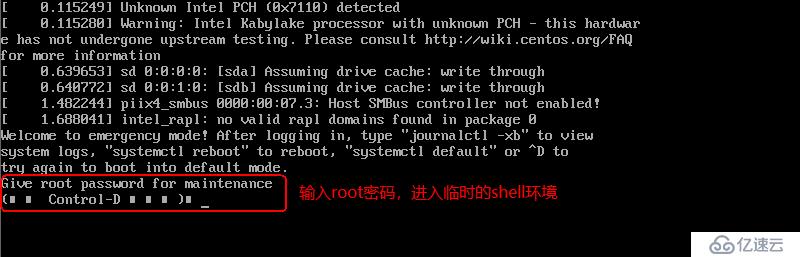
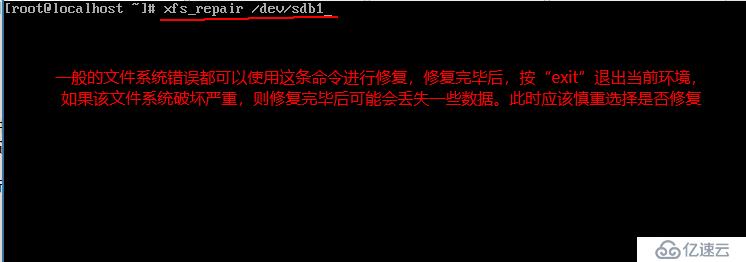
дҝ®еӨҚе®ҢжҜ•пјҒпјҒпјҒ
2.зЈҒзӣҳиө„жәҗиҖ—е°Ҫж•…йҡң
жҳҫиҖҢжҳ“и§ҒпјҢеҪ“дёҖдёӘж–Ү件系з»ҹзҡ„зЈҒзӣҳз©әй—ҙиҖ—е°Ҫд»ҘеҗҺпјҢе°Ҷж— жі•з»§з»ӯеңЁиҜҘеҲҶеҢәдёӯеҲӣе»әж–°зҡ„ж–Ү件数жҚ®пјҢд»ҺиҖҢеҜјиҮҙж•…йҡңзҡ„еҮәзҺ°гҖӮ
еҪ“еӣ дёәж №еҲҶеҢәзЈҒзӣҳз©әй—ҙдёҚи¶іпјҢиҖҢж— жі•еҗҜеҠЁиҝӣе…ҘLinuxж“ҚдҪңзі»з»ҹж—¶пјҢеҸҜд»Ҙиҝӣе…ҘжҖҘж•‘жЁЎејҸпјҢжё…зҗҶеҚ з”ЁеӨ§йҮҸз©әй—ҙзҡ„ж–Ү件гҖӮеҸҜд»ҘдҪҝз”Ёе‘Ҫд»ӨвҖңdd if=/dev/zer0 of=/a bs=1M count=999999вҖқжЁЎжӢҹж•…йҡңгҖӮ
йҷӨжӯӨд№ӢеӨ–пјҢеңЁжҜҸдёҖдёӘж–Ү件系з»ҹдёӯпјҢиғҪеӨҹдҪҝз”Ёзҡ„ж–Ү件数йҮҸпјҲеҜ№еә”iз»“зӮ№зҡ„ж•°йҮҸпјүд№ҹжҳҜжңүйҷҗзҡ„пјҢеҪ“дёҖдёӘж–Ү件系з»ҹиў«ж јејҸеҢ–еҗҺпјҢе…¶iз»“зӮ№ж•°д№ҹе°ұеӣәе®ҡдәҶпјҢеҰӮжһңз”ЁжҲ·ж•…ж„Ҹж¶ҲиҖ—iз»“зӮ№ж•°йҮҸпјҢйӮЈд№ҲпјҢеҸҠж—¶иҜҘеҲҶеҢәжңүеӨ§йҮҸзҡ„з©әй—ҙпјҢд№ҹдёҚеҸҜд»ҘеҲӣе»әж–Ү件гҖӮ
йҖҡиҝҮзӨәдҫӢдәҶи§ЈдёҖдёӢпјҡ
пјҲ1пјүжЁЎжӢҹiз»“зӮ№иҖ—е°Ҫж•…йҡң
[root@localhost ~]# mkdir /a
[root@localhost ~]# mount /dev/sdb1 /a
[root@localhost ~]# df -i /a
ж–Ү件系з»ҹ Inode е·Із”Ё(I) еҸҜз”Ё(I) е·Із”Ё(I)% жҢӮиҪҪзӮ№
/dev/sdb1 10485248 3 10485245 1% /a
зј–еҶҷдёҖдёӘе°Ҹи„ҡжң¬пјҢж¶ҲиҖ—iз»“зӮ№ж•°йҮҸпјҢи„ҡжң¬еҶ…е®№еҰӮдёӢпјҡ
[root@localhost ~]# vim a.sh
#!/bin/bash
i=1
while [ $i -le 310485245 ]
do
touch /a/file$i
let i++
done
[root@localhost ~]# sh a.sh &
[root@localhost ~]# df -i /a
ж–Ү件系з»ҹ Inode е·Із”Ё(I) еҸҜз”Ё(I) е·Із”Ё(I)% жҢӮиҪҪзӮ№
/dev/sdb1 10485248 0 3 10485245 100% /a
[root@localhost ~]# touch /a/newfile
touchпјҡ ж— жі•еҲӣе»әвҖң/a/newfileвҖқ пјҡи®ҫеӨҮдёҠжІЎжңүз©әй—ҙ
[root@localhost ~]# df -hT /a
ж–Ү件系з»ҹ зұ»еһӢ е®№йҮҸ е·Із”Ё еҸҜз”Ё е·Із”Ё% жҢӮиҪҪзӮ№
/dev/mapper/cl-root xfs 17G 4.5G 13G 26% /
пјҲ2пјүдҝ®еӨҚiз»“зӮ№ж•…йҡң
[root@localhost ~]# rm -rf /a/file*
3.жЈҖжөӢзЎ¬зӣҳеқҸйҒ“
зЈҒзӣҳеқҸйҒ“еҲҶдёәйҖ»иҫ‘еқҸйҒ“е’Ңзү©зҗҶеқҸйҒ“жқҘе“Әз§ҚпјҢеүҚиҖ…жҳҜз”ұдәҺиҪҜ件ж“ҚдҪңдёҚеҪ“йҖ жҲҗпјҢеҸҜд»ҘдҪҝз”ЁиҪҜ件дҝ®еӨҚе·Ҙе…·иҝӣиЎҢдҝ®еӨҚпјҢиҖҢеҗҺиҖ…жҳҜзү©зҗҶжҖ§жҚҹеқҸпјҢеҸӘиғҪйҖҡиҝҮжӣҙж”№зЈҒзӣҳеҲҶеҢәжҲ–жүҮеҢәзҡ„еҚ з”ЁдҪҚзҪ®иҝӣиЎҢиҝӣиЎҢж”№е–„пјҢд»ҺиҖҢжҺ’йҷӨеҢ…еҗ«еқҸеқ—зҡ„зЈҒзӣҳз©әй—ҙпјҢиӢҘзЈҒзӣҳеҮәзҺ°д»ҘдёӢзҺ°иұЎпјҢеҲҷжңүеҸҜиғҪжҳҜзЈҒзӣҳеҮәзҺ°еқҸйҒ“пјҢйңҖиҰҒжЈҖжөӢе’Ңдҝ®еӨҚгҖӮ
- иҜ»еҸ–зЈҒзӣҳдёӯзҡ„ж•°жҚ®ж—¶пјҢзЈҒзӣҳи®ҫеӨҮеҸ‘еҮәејӮе“Қпјӣ
- и®ҝй—®зЈҒзӣҳдёӯзҡ„жҹҗдёӘж–Ү件时пјҢеҸҚеӨҚиҜ»еҸ–дё”еҮәй”ҷпјҢжҸҗзӨәж–Ү件жҚҹеқҸпјӣ
- еҜ№дәҺж–°е»әз«Ӣзҡ„еҲҶеҢәж— жі•ж јејҸеҢ–пјӣ
- зі»з»ҹдҪҝз”ЁиҜҘзЈҒзӣҳж—¶пјҢйў‘з№Ғжӯ»жңәпјӣ
- жӯӨжЎҲеҮәзҺ°еқҸйҒ“еҗҺпјҢеҰӮжһңдёҚеҸҠж—¶жӣҙжҚўжҲ–иҝӣиЎҢжҠҖжңҜеӨ„зҗҶпјҢеқҸйҒ“еҲҷдјҡи¶ҠжқҘи¶ҠеӨҡпјҢдё”еҸҜиғҪйҖ жҲҗйў‘з№Ғжӯ»жңәе’Ңж•°жҚ®дёўеӨұзҡ„еҗҺжһңпјҢеӣ жӯӨеҝ…иҰҒж—¶еә”иҜҘеҜ№зЈҒзӣҳиҝӣиЎҢе®ҡжңҹжЈҖжөӢпјҢжЈҖжөӢжҳҜеҗҰеӯҳеңЁеқҸйҒ“гҖӮ
еңЁLinuxзі»з»ҹдёӯпјҢжЈҖжөӢзЈҒзӣҳзҡ„еқҸйҒ“жғ…еҶөеҸҜд»ҘдҪҝз”Ёbadblocksе‘Ҫд»ӨиҝӣиЎҢпјҢз»“еҗҲвҖң-sвҖқз”ЁдәҺжҳҫзӨәиҝӣеәҰдҝЎжҒҜпјӣвҖң-vвҖқйҖүйЎ№з”ЁдәҺжҳҫзӨәиҜҰжғ…гҖӮ
[root@localhost ~]# badblocks -sv /sdb/sdb
еңЁй•ҝжңҹдҪҝз”Ёи®Ўз®—жңәзҡ„иҝҮзЁӢдёӯпјҢж–Ү件系з»ҹе’ҢзЈҒзӣҳзұ»зҡ„ж•…йҡңзҺ°иұЎеҫҲйҡҫе®Ңе…ЁйҒҝе…ҚпјҢеҜ№дәҺжӯӨзұ»ж•…йҡңзҡ„дҝ®еӨҚйңҖиҰҒеҚҒеҲҶи°Ёж…ҺпјҢеҰӮжһңж“ҚдҪңдёҚеҪ“еҸҜиғҪдјҡеҠ йҮҚж•°жҚ®з ҙеқҸзҡ„зЁӢеәҰгҖӮеҪ“еҸ‘зҺ°зЈҒзӣҳдёӯеӯҳеңЁеқҸйҒ“ж—¶пјҢеә”е°Ҫеҝ«еҒңжӯўзі»з»ҹдёӯзҡ„еә”з”ЁжңҚеҠЎгҖҒеӨҮд»Ҫзӣёе…іж•°жҚ®пјҢеҝ…иҰҒж—¶з«ӢеҚіе…ій—ӯзі»з»ҹдёҖж–№зЈҒзӣҳеқҸйҒ“иҝӣдёҖжӯҘжү©ж•ЈпјҢйҒҝе…ҚеҜјиҮҙжӣҙеӨ§зҡ„жҚҹеӨұгҖӮеҜ№дәҺеӯҳеңЁеқҸйҒ“зҡ„зЎ¬зӣҳи®ҫеӨҮпјҢеә”дҪҝз”Ёе…¶д»–е®ҢеҘҪзҡ„зЎ¬зӣҳиҝӣиЎҢжӣҝжҚўгҖӮ
вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ” жң¬ж–ҮиҮіжӯӨз»“жқҹпјҢж„ҹи°ўйҳ…иҜ» вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”





