前言
简单来说机器学习的核心步骤在于“获取学习数据;选择机器算法;定型模型;评估模型,预测模型结果”,下面本人就以判断日报内容是否合格为例为大家简单的阐述一下C#的机器学习。
第一步:问题分析
根据需求可以得出我们的模型是以日报的内容做为学习的特征确定的,然后通过模型判断将该目标对象预测为是否符合标准(合格与不合格),简单来说就是一种分类场景(此场景结果属于二元分类,不是A就是B),那么也就确定了核心算法为分类算法当然还有其它的分类算法有兴趣的可以自己去了解一下在这里就不多做说明了。
第二步:环境准备
其他的代码编译运行的环境并没有太多要求,你只需要引用C#机器学习的NuGet 包,名为Microsoft.ML 具体的安装步骤在此就不做详细介绍了。
第三步:准备数据
这里会准备两个数据集 一个定型模型的数据集(可以称之为学习资料)wikipedia-detox-250-line-data.tsv数据实例部分展示如下(你的数据按照这种排列格式即可该该格式的定义取决于你的输入数据集类的结构在下面会讲到):
Sentiment SentimentText
第一天上班 无事
完成了领导的安排任务
编写了一些代码然后写了一些杂七杂八的文档
和一般的码农做了一样的事情
和产品经理一起做了一些项目上的事情
早上来的时候就开始讨论需求,然后开始写代码,快下班的时候完成了整个过程的文档分享
***项目的整体编排会议,设计图的首页以及我的个人中心制作
**项目需求的对接,需求的梳理,实体结构的定义,数据库的迁移,脑图的完善
1、**项目的模板消息代码编写,2、**项目管理后台的模板发送完善,定型模型数据集准备好之后还有一个评估模型的测试数据集(可以称之为标准答案)wikipedia-detox-250-line-test.tsv格式与上面展示的评估数据集一样
定型数据的数据越丰富算法的回归曲线方程就会越接近理想的模型方程,你的模型预测结果就会越符合你的要求。
第四步:定义特征类
根据分享的模型确定其分析的特征项并定义为相关的类并且需要引用机器学习的包using Microsoft.ML.Data;,由此模型定义的数据集类如下(结果可看注释):
/// <summary>
/// 输入数据集类
/// </summary>
public class SentimentData
{
/// <summary>
/// 日志是否合格的值(0:为合格,1:不合格)
/// </summary>
[Column(ordinal: "0", name: "Label")]
public float Sentiment;
/// <summary>
/// 日报内容
/// </summary>
[Column(ordinal: "1")]
public string SentimentText;
}
/// <summary>
/// 预测结果集类
/// </summary>
public class SentimentPrediction
{
/// <summary>
/// 预测值(是否合格)
/// </summary>
[ColumnName("PredictedLabel")]
public bool Prediction { get; set; }
/// <summary>
/// 或然率(结果分布概率)
/// </summary>
[ColumnName("Probability")]
public float Probability { get; set; }
}第一个SentimentData类为输入数据集类,指的就是根据定型的数据集的特征项定义的集类,第二个SentimentPrediction类为预测结果集类,也就是你所需要的结果的类定义 该类的结构一般受你所使用的学习算法影响,根据你的学习管道输出的结果以及个人需求的综合考虑来定义。输入集类带的Column属性标注其在数据集的格式位置的编排以及何为Label值。预测集的PredictedLabel在预测和评估过程中使用。
第五步:代码实现
首先定义以指定这些路径和 _textLoader 变量,用来读取数据或者是保存实验数据,具体如下所示:
_trainDataPath 具有用于定型模型的数据集路径。
_testDataPath 具有用于评估模型的数据集路径。
_modelPath 具有在其中保存定型模型的路径。
_textLoader 是用于加载和转换数据集的 TextLoader。

然后定义程序的入口(main函数)以及相应的处理方法:
定义SaveModelAsFile方法将模型保存为 .zip 文件代码如下所示:
private static void SaveModelAsFile(MLContext mlContext, ITransformer model)
{
using (var fs = new FileStream(_modelPath, FileMode.Create, FileAccess.Write, FileShare.Write))
mlContext.Model.Save(model, fs);
Console.WriteLine("模型保存路径为{0}", _modelPath);
Console.ReadLine();
}定义Train方法选择学习方法并且创建相应的学习管道,输出定型后的模型model代码如下所示:
public static ITransformer Train(MLContext mlContext, string dataPath)
{
IDataView dataView = _textLoader.Read(dataPath);
//数据特征化(按照管道所需的格式转换数据)
var pipeline = mlContext.Transforms.Text.FeaturizeText(inputColumnName: "SentimentText", outputColumnName: "Features")
//根据学习算法添加学习管道
.Append(mlContext.BinaryClassification.Trainers.FastTree(numLeaves: 50, numTrees: 50, minDatapointsInLeaves: 20));
//得到模型
var model = pipeline.Fit(dataView);
Console.WriteLine();
//返回定型模型
return model;
}模型定型之后,我们需要创建一个方法(Evaluate)来评测该模型的质量,根据你自己的标准测试数据集与该模型的符合程度来判断,并且输出相应的指标,该指标参数根据你所调用的评估方法返回具体的根据你的算法方程返回相应的方程的参数 。代码如下所示:
public static void Evaluate(MLContext mlContext, ITransformer model)
{
var dataView = _textLoader.Read(_testDataPath);
Console.WriteLine("===============用测试数据评估模型的准确性===============");
var predictions = model.Transform(dataView);
//评测定型模型的质量
var metrics = mlContext.BinaryClassification.Evaluate(predictions, "Label");
Console.WriteLine();
Console.WriteLine("模型质量量度评估");
Console.WriteLine("--------------------------------");
Console.WriteLine($"精度: {metrics.Accuracy:P2}");
Console.WriteLine($"Auc: {metrics.Auc:P2}");
Console.WriteLine("=============== 模型结束评价 ===============");
Console.ReadLine();
//评测完成之后开始保存定型的模型
SaveModelAsFile(mlContext, model);
}定义单个数据的预测方法(Predict)与批处理预测的方法(PredictWithModelLoadedFromFile):
单个数据集的预测代码如下所示:
private static void Predict(MLContext mlContext, ITransformer model)
{
//创建包装器
var predictionFunction = model.CreatePredictionEngine<SentimentData, SentimentPrediction>(mlContext);
SentimentData sampleStatement = new SentimentData
{
SentimentText = "爱车新需求开发;麦扣日志监控部分页面数据绑定;"
};
//预测结果
var resultprediction = predictionFunction.Predict(sampleStatement);
Console.WriteLine();
Console.WriteLine("===============单个测试数据预测 ===============");
Console.WriteLine();
Console.WriteLine($"日报内容: {sampleStatement.SentimentText} | 是否合格: {(Convert.ToBoolean(resultprediction.Prediction) ? "合格" : "不合格")} | 符合率: {resultprediction.Probability} ");
Console.WriteLine("=============== 预测结束 ===============");
Console.WriteLine();
Console.ReadLine();
}批处理数据集预测方法代码如下所示:
public static void PredictWithModelLoadedFromFile(MLContext mlContext)
{
IEnumerable<SentimentData> sentiments = new[]
{
new SentimentData
{
SentimentText = "1、完成爱车年卡代码编写 2、与客户完成需求对接"
},
new SentimentData
{
SentimentText = "没有工作内容"
}
};
ITransformer loadedModel;
using (var stream = new FileStream(_modelPath, FileMode.Open, FileAccess.Read, FileShare.Read))
{
loadedModel = mlContext.Model.Load(stream);
}
// 创建预测(也称之为创建预测房屋)
var sentimentStreamingDataView = mlContext.Data.ReadFromEnumerable(sentiments);
var predictions = loadedModel.Transform(sentimentStreamingDataView);
// 使用模型预测结果值为1(不合格)还是0 (合格)
var predictedResults = mlContext.CreateEnumerable<SentimentPrediction>(predictions, reuseRowObject: false);
Console.WriteLine();
Console.WriteLine("=============== 多样本加载模型的预测试验 ===============");
var sentimentsAndPredictions = sentiments.Zip(predictedResults, (sentiment, prediction) => (sentiment, prediction));
foreach (var item in sentimentsAndPredictions)
{
Console.WriteLine($"日报内容: {item.sentiment.SentimentText} | 是否合格: {(Convert.ToBoolean(item.prediction.Prediction) ? "合格" : "不合格")} | 符合率: {item.prediction.Probability} ");
}
Console.WriteLine("=============== 预测结束 ===============");
Console.ReadLine();
}在以上的方法定义完成之后开始进行方法的调用:
public static void Main(string[] args)
{
//创建一个MLContext,为ML作业提供一个上下文
MLContext mlContext = new MLContext(seed: 0);
//初始化_textLoader以将其重复应用于所需要的数据集
_textLoader = mlContext.Data.CreateTextLoader(
columns: new TextLoader.Column[]
{
new TextLoader.Column("Label", DataKind.Bool,0),
new TextLoader.Column("SentimentText", DataKind.Text,1)
},
separatorChar: '\t',
hasHeader: true
);
//定型模型
var model = Train(mlContext, _trainDataPath);
//评测模型
Evaluate(mlContext, model);
//单个数据预测
Predict(mlContext, model);
//批处理预测数据
PredictWithModelLoadedFromFile(mlContext);
}准备代码之后,你的小小的机器人就要开始学习啦,好吧开始编译运行吧。。。。。。
运行产生结果为:
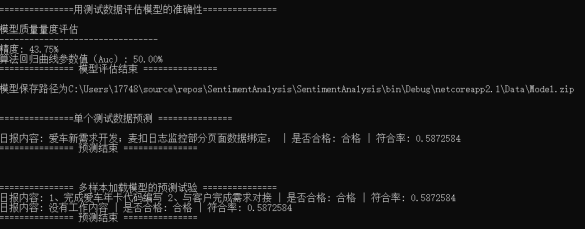
由于训练的数据集特征化参数的准确性以及数据的涵盖广度不够导致定义的模型质量非常的不理想因此我们可以看到 我们的预测结果也是不够符合我们的理想状态,可见我们小机器的学习之路是非常漫长的过程啊。
由此次的机器学习的小小实践本人也深有体会,机器就像一个小孩一样首先你得根据他的性格(特征化参数)确定应该给予他什么样的学习环境(学习算法创建的学习管道)并提供学习资料(定型机器学习模型数据集),然后为其确定一个发展目标(评估模型数据集),并且不断的进行考试(单个数据的预测与批量数据的预测),考试需要特定的考试场地(预测所需要调用的方法)。通过该种方式让机器不断的学习不断的精进。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



