这篇文章将为大家详细讲解有关node.js中怎么读取docx文本,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
其实docx就是一个zip包,然后封装了一些xml文件。可以直接将docx的包改后缀为.zip来打开观看。
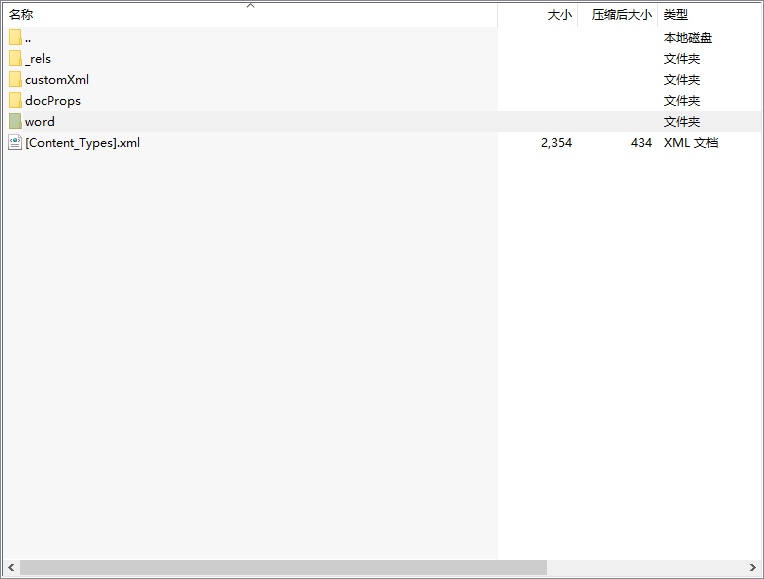
进入word文件夹
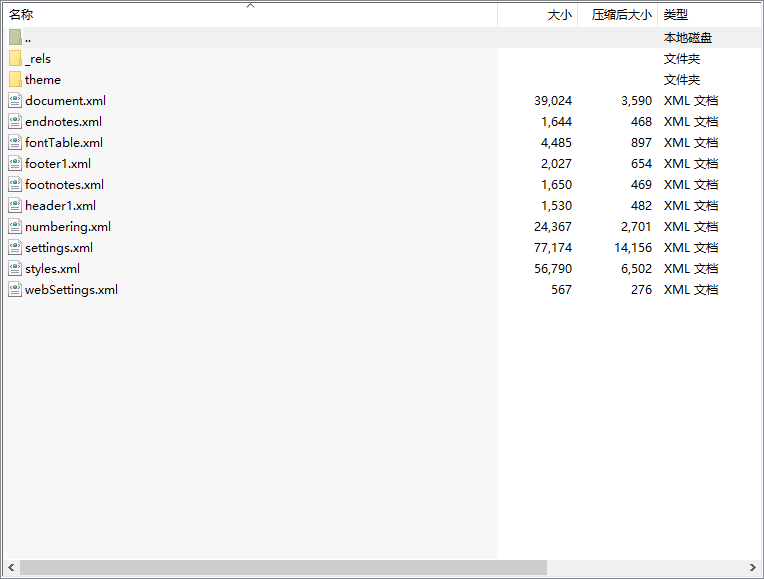
里面有几个主要的文件。
document.xml 这个就是文档的主要内容
numbering.xml 这个就是标题号,以及标题号的一些属性
styles.xml 这个就是样式列表
打开document.xml 你就会发现,所有的文本都是用 <w:t>标签包着的。这个就是本文的关键
代码
首先,需要通过npm安装一个能查看zip文件的包:adm-zip;
然后,写下下列代码即可
const fs = require("fs");
const AdmZip = require('adm-zip'); //引入查看zip文件的包
const zip = new AdmZip(filePath); //filePath为文件路径
let contentXml = zip.readAsText("word/document.xml");//将document.xml读取为text内容;
let str = "";
contentXml .match(/<w:t>[\s\S]*?<\/w:t>/ig).forEach((item)=>{
str += item.slice(5,-6)});
fs.writeFile("./2.txt",str,(err)=>{//将./2.txt替换为你要输出的文件路径
if(err)throw err;
});最近正在用node.js去解析docx的工作。先将最简单的写在上面。回头有空再继续分享
最新更新
之前随手写的代码,今天测试发现用更新后的代码比源代码的效率提升十倍以上。
//原代码
//str += item.replace("<w:t>","").replace("</w:t>","");
//更新代码
str += item.slice(5,-6)附上测试代码
var str = "<w:t>sdfjpasif aefnmasd;lf asdfsdf</w:t>";
var arr = [];
for(var i=0;i<50000;i++){
arr.push(str);
}
console.time("replactest");
arr.forEach((item)=>{
item.replace(/<w:t>/,"").replace(/<\/w:t>/,"");
});
console.timeEnd("replactest");
//replactest: 20.560ms
console.time("replactest2");
arr.forEach((item)=>{
item.replace(/<\/*w:t>/g,"");
});
console.timeEnd("replactest2");
//replactest2: 14.926ms
console.time("replactest3");
arr.forEach((item)=>{
item.replace(/(^<w:t>)|(<\/w:t>$)/g,"");
});
console.timeEnd("replactest3");
//replactest3: 14.402ms
console.time("slice");
arr.forEach((item)=>{
item.slice(5,-6);
});
console.timeEnd("slice");
//slice: 1.718ms关于node.js中怎么读取docx文本就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



