
Part1:写在最前
在副本集架构中,当我们面临写多读少,且大多数写为update操作时,WT引擎的瓶颈初显。这直接导致业务反馈写入操作耗时较久等异常。为此,Percona版本的MongoDB里支持rocksDB存储引擎,应对写比较多的时候会显得更加从容。
Part2:背景
在业务大量更新的场景中我们发现WT存储引擎的disk lantency会比较高,在尝试调大cache_size和并发数、eviction后效果不佳,因此我们尝试使用rocksDB引擎代替。
Part3:措施
将write concern从majority变更为1,观察效果
w: 数据写入到number个节点才向用客户端确认{w: 0} 对客户端的写入不需要发送任何确认,适用于性能要求高,但不关注正确性的场景
{w: 1} 默认的writeConcern,数据写入到Primary就向客户端发送确认
{w: “majority”} 数据写入到副本集大多数成员后向客户端发送确认,适用于对数据安全性要求比较高的场景,该选项会降低写入性能
j: 写入操作的journal持久化后才向客户端确认默认为”{j: false},如果要求Primary写入持久化了才向客户端确认,则指定该选项为true
之前开了majority,慢的同时,在3.2.6版本后,也会同时开启journal日志的磁盘写入,导致磁盘耗时增加,进而导致写入更慢,把writeconcern改到1,可以提升写入速率
相关参数
writeConcernMajorityJournalDefault
Part4:日志抓取
2018-08-21T01:00:50.096+0800 I COMMAND [conn4072412] command kgcxxxt.$cmd command: update { update: "col", ordered: true, writeConcern: { w: "majority" }, $db: "kgcxxxt" } numYields:0 reslen:295 locks:{ Global: { acquireCount: { r: 2, w: 2 } }, Database: { acquireCount: { w: 2 } }, Collection: { acquireCount: { w: 1 } }, oplog: { acquireCount: { w: 1 } } } protocol:op_query 137ms
....
....
2018-08-21T01:00:50.096+0800 I COMMAND [conn4072176] command kgcxxxt.$cmd command: update { update: "col", ordered: true, writeConcern: { w: "majority" }, $db: "kgcxxxt" } numYields:0 reslen:295 locks:{ Global: { acquireCount: { r: 2, w: 2 } }, Database: { acquireCount: { w: 2 } }, Collection: { acquireCount: { w: 1 } }, oplog: { acquireCount: { w: 1 } } } protocol:op_query 137ms
Part5:监控
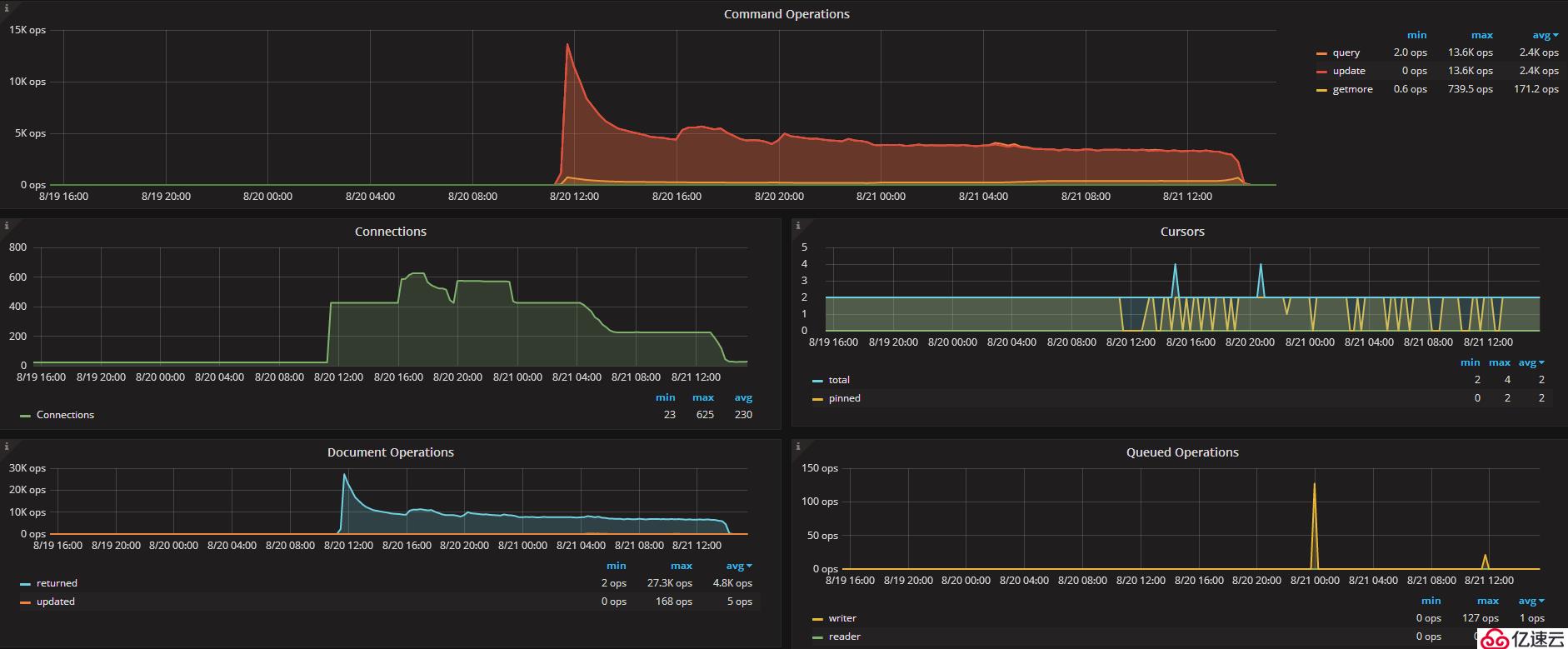
替换为write concern 1后,qps提高到15k
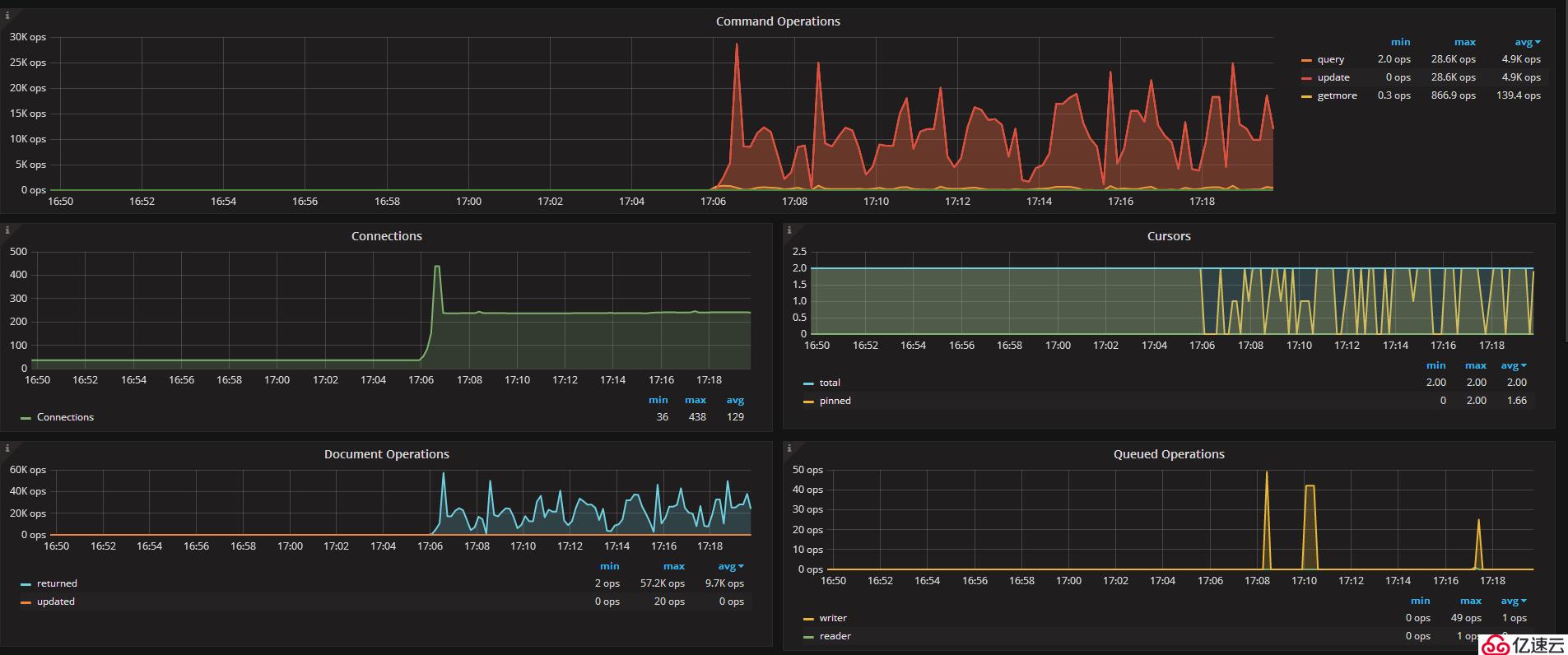
Part6:调大相关参数
尝试调大cache_size和eviction
db.adminCommand({setParameter: 1, wiredTigerEngineRuntimeConfig: "cache_size=90G"})
db.adminCommand({setParameter: 1, wiredTigerEngineRuntimeConfig: "eviction=(threads_min=1,threads_max=8)"})可以看出,在调大参数后排队的情况降下来了
但是这一好景不长,没过多久依旧出现了我们不希望看到的情况,因此后续我们决定采用rocksDB引擎。
Part1:整体架构
原有集群为3节点副本集架构,均使用WT存储引擎。我们将其中一台从库换为rocksDB存储引擎,观察disk lantancy情况。
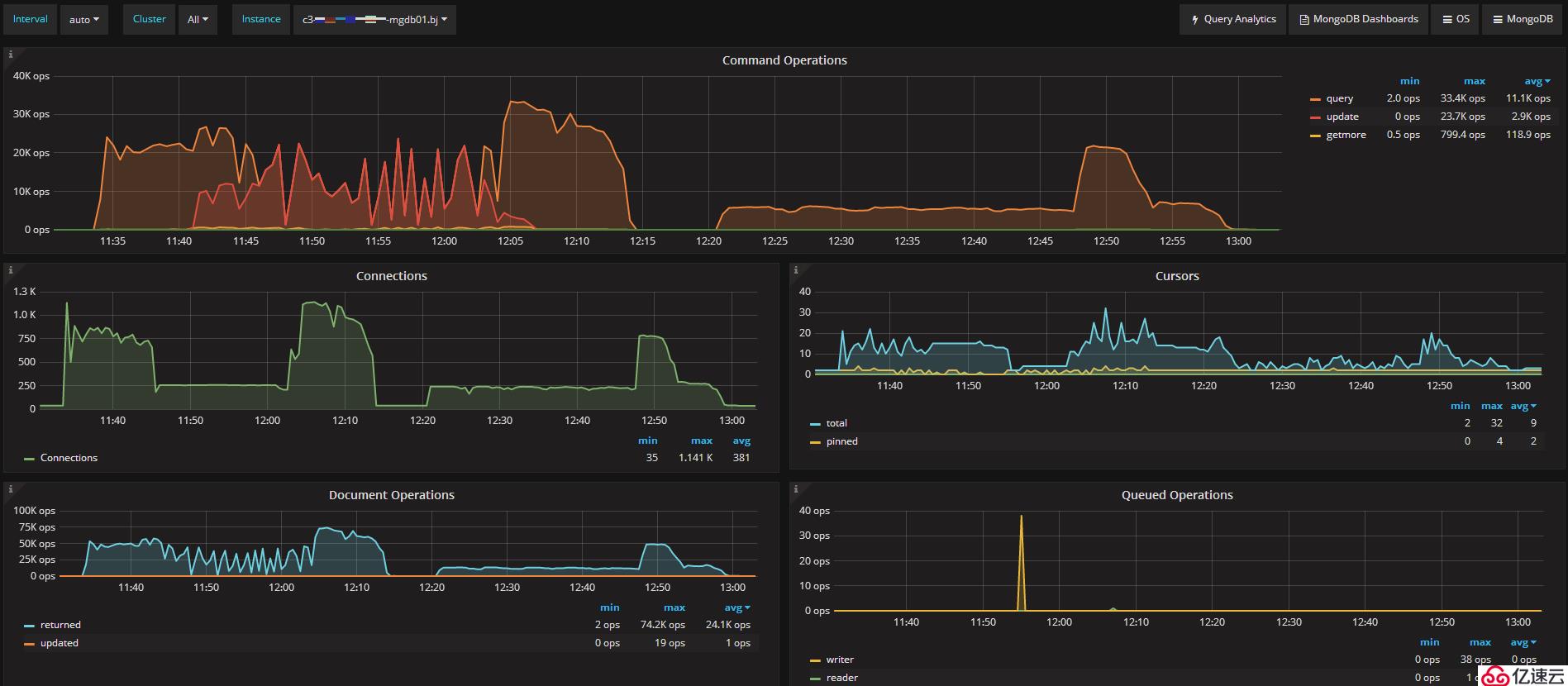
如上图所示,可以看出主节点的QPS情况。
Part2:rocksDB引擎从库
我们将其中一台从库配置为rocksDB引擎,RocksDB相对WT一大改进是采用LSM树存储引擎。Wiredtiger 基于 btree 结构组织数据,在一些极端场景下,因为 Cache eviction 及写入放大的问题,可能导致 Write hang,细节可以到 MongoDB jira 上了解相关的issue,针对这些问题 MongoDB 官方团队一直在优化,我们也看到 Wiredtiger 稳定性在不断提升;而 RocksDB 是基于 LSM tree 结构组织数据,其针对写入做了优化,将随机写入转换成了顺序写入,能保证持续高效的数据写入。在替换其中一台从库为rocksDB引擎后,我们将其与另外一台WT引擎的从库进行disk lantency的对比。
下图为使用lsm Tree 结构的rocksDB存储引擎从库的disk lantency,可以看出都在1ms内。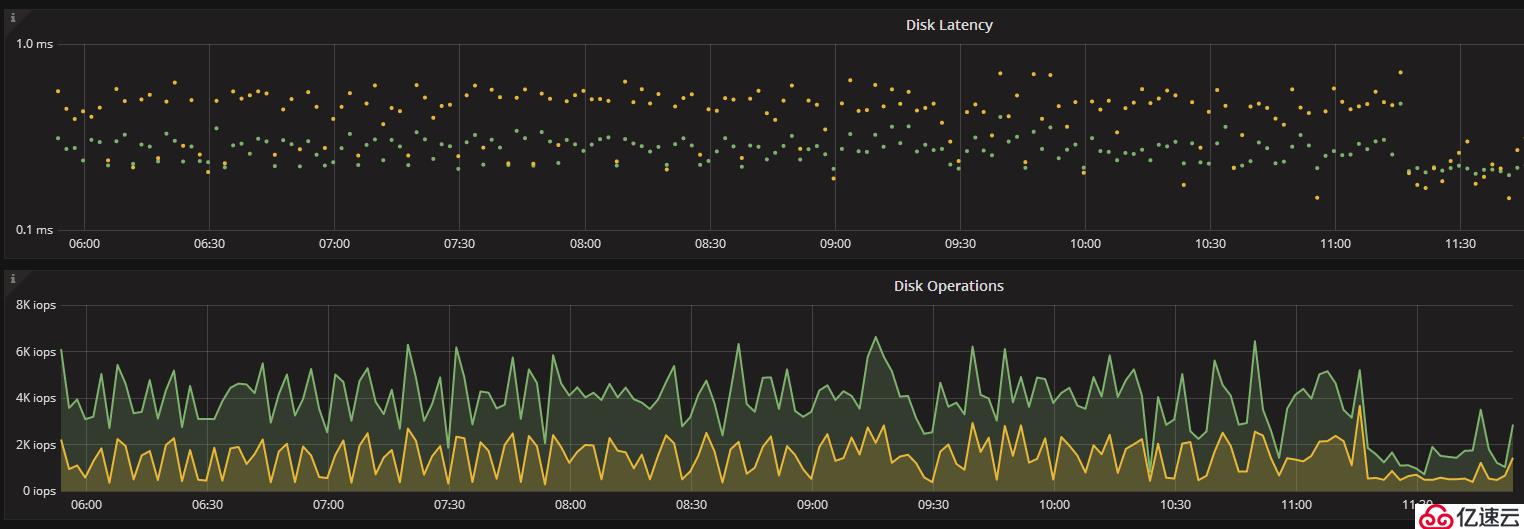
其qps如下图所示,repl_delete在3k左右且连续稳定。
Part3:WT引擎从库
下图为使用WT存储引擎从库,其disk lantency和主库一样,写入的lantency达到了8ms,读也有4ms
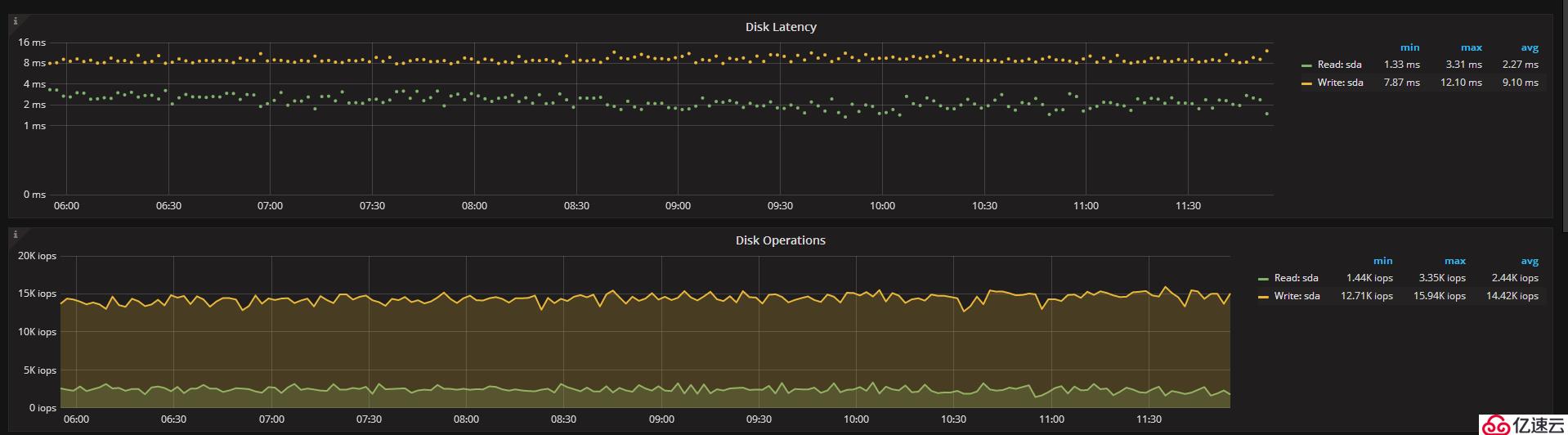
其qps在2.3k左右,且监控出现断点,从库出现因压力大登录超时的情况。
Part4:RocksDB引擎配置参数
storage: engine: rocksdb useDeprecatedMongoRocks: true dbPath: /home/work/mongodb/mongo_28000/data/db_28000 indexBuildRetry: true journal: enabled: true commitIntervalMs: 100 rocksdb: cacheSizeGB: 10 compression: snappy maxWriteMBPerSec: 1024 configString: write_buffer_size=512M;level0_slowdown_writes_trigger=12;min_write_buffer_number_to_merge=2; crashSafeCounters: false counters: true singleDeleteIndex: false
注释1
#storage Options storage: engine: "rocksdb" useDeprecatedMongoRocks: true ##percona 3.6版本需要加 dbPath: /home/work/mongodb/mongo_10001/data rocksdb: cacheSizeGB: 10 # 默认是30% of physical memory compression: snappy maxWriteMBPerSec: 1024 #单位MB,rocks writes to storage 的速度,降低这个值可以减少读延迟刺尖,但该值太低会降低写入速度 configString: write_buffer_size=512M;level0_slowdown_writes_trigger=12;min_write_buffer_number_to_merge=2; crashSafeCounters: false #指定crash之后是否正确计数,开启这个选项可能影响性能 counters: true #(默认开)指定是否使用advanced counters,关闭它可以提高写性能 singleDeleteIndex: false
在添加 configString: write_buffer_size=512M;level0_slowdown_writes_trigger=12;min_write_buffer_number_to_merge=2; 参数后,磁盘延迟进一步降低,iops也进一步降低
这里需要注意的是,percona从3.6版本起不建议使用rocksdb,可能在下一个大版本移除,至于是否选用,要根据实际情况出发,最好能够拉上业务一起进行一个压测,满足业务需求的,就是最好的。
https://www.percona.com/doc/percona-server-for-mongodb/LATEST/mongorocks.html
注释2
rocksdb参数的调节一般是在三个因素之间做平衡:写放大、读放大、空间放大 1.flush选项: write_buffer_size: memtable的最大size,如果超过了这个值,RocksDB就会将其变成immutablememtable,并在使用另一个新的memtable max_write_buffer_number: 最大memtable的个数,如果activememtablefull了,并且activememtable加上immutablememtable的个数已经到了这个阀值,RocksDB就会停止后续的写入。通常这都是写入太快但是flush不及时造成的。 min_write_buffer_number_to_merge: 在flush到level0之前,最少需要被merge的memtable个数。如果这个值是2,那么当至少有两个immutable的memtable的时候,RocksDB会将这两个immutablememtable先merge,再flush到level0。预先merge能减小需要写入的key的数据,譬如一个key在不同的memtable里面都有修改,那么我们可以merge成一次修改。但这个值太大了会影响读取性能,因为Get会遍历所有的memtable来看这个key是否存在。 举例:write_buffer_size=512MB;max_write_buffer_number=5;min_write_buffer_number_to_merge=2; 假设写入速率是16MB/s,那么每32s的时间都会有一个新的memtable生成,每64s的时间就会有两个memtable开始merge。取决于实际的数据,需要flush到level0的大小可能在512MB和1024MB之间,一次flush也可能需要几秒的时间 (取决于盘的顺序写入速度)。最多有5个memtable,当达到这个阀值,RocksDB就会组织后续的写入了。 2.LevelStyleCompaction: level0_slowdown_writes_trigger: 当level0的文件数据达到这个值的时候,就开始进行level0到level1的compaction。所以通常level0的大小就是write_buffer_size*min_write_buffer_number_to_merge*level0_file_num_compaction_trigger。 max_background_compactions: 是指后台压缩的最大并发线程数,默认为1,但为了充分利用你的CPU和存储,可以将该值配置为机器核数 max_background_flushes: 并发执行flush操作的最大线程数,通常设置为1已经是足够了。
如下是使用 sysbench 进行的一个简单的 insert 测试,insert 的集合默认带一个二级索引,在刚开始 Wiredtiger 的写入性能远超 RocksDB,而随着数据量越来越大,WT的写入能力开始下降,而 RocksDB 的写入一直比较稳定。
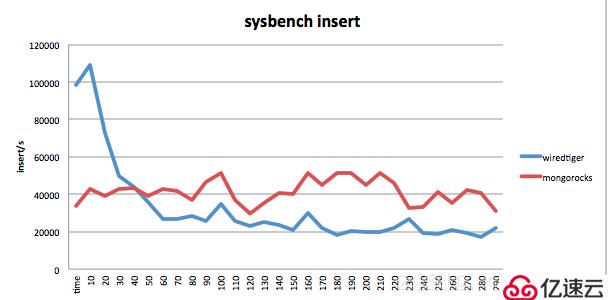
更多 Wiredtiger、Mongorocks 的对比可以参考 Facebook 大神在 Percona Live 上的技术分享。
https://www.percona.com/live/17/sessions/comparing-mongorocks-wiredtiger-and-mmapv1-performance-and-efficiency?spm=a2c4e.11153940.blogcont231377.21.6c457b684BOXvj
——总结——
通过本文,我们了解到RocksDB引擎的特点和与WT存储引擎的disk lantency对比,不同的业务场景不同,因此具体使用什么存储引擎,还需要结合具体业务来进行评估。由于笔者的水平有限,编写时间也很仓促,文中难免会出现一些错误或者不准确的地方,不妥之处恳请读者批评指正。喜欢笔者的文章,右上角点一波关注,谢谢~
参考资料:
https://www.percona.com/doc/percona-server-for-mongodb/LATEST/mongorocks.html
https://yq.aliyun.com/articles/231377
https://www.percona.com/live/17/sessions/comparing-mongorocks-wiredtiger-and-mmapv1-performance-and-efficiency?spm=a2c4e.11153940.blogcont231377.21.6c457b684BOXvj
历经1年时间,和我的挚友张甦先生合著了这本《MongoDB运维实战》,感谢电子工业出版社,感谢张甦先生让我圆了出书梦!感谢友东哥、李丹哥、李彬哥、张良哥的书评!感谢友飞哥、汝林哥在我入职小米以来工作上的指导和帮助!感谢我的爱人李爱璇女士,没有你在背后支持,我不可能完成这项庞大的工程。京东自营有货,喜欢MongoDB的同学欢迎支持!

免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





