这篇文章将为大家详细讲解有关基于Java实现多线程下载并允许断点续传的方法,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
Java是一门面向对象编程语言,可以编写桌面应用程序、Web应用程序、分布式系统和嵌入式系统应用程序。
多线程下载及断点续传的实现是使用 HTTP/1.1 引入的 Range 请求参数,可以访问Web资源的指定区间的内容。虽然实现了多线程及断点续传,但还有很多不完善的地方。
包含四个类:
Downloader: 主类,负责分配任务给各个子线程,及检测进度DownloadFile: 表示要下载的哪个文件,为了能写输入到文件的指定位置,使用 RandomAccessFile 类操作文件,多个线程写同一个文件需要保证线程安全,这里直接调用 getChannel 方法,获取一个文件通道,FileChannel是线程安全的。DownloadTask: 实际执行下载的线程,获取 [lowerBound, upperBound] 区间的数据,当下载过程中出现异常时要通知其他线程(使用 AtomicBoolean),结束下载Logger: 实时记录下载进度,以便续传时知道从哪开始。感觉这里做的比较差,为了能实时写出日志及方便地使用Properties类的load/store方法格式化输入输出,每次都是打开后再关闭。
演示:
随便找一个文件下载:
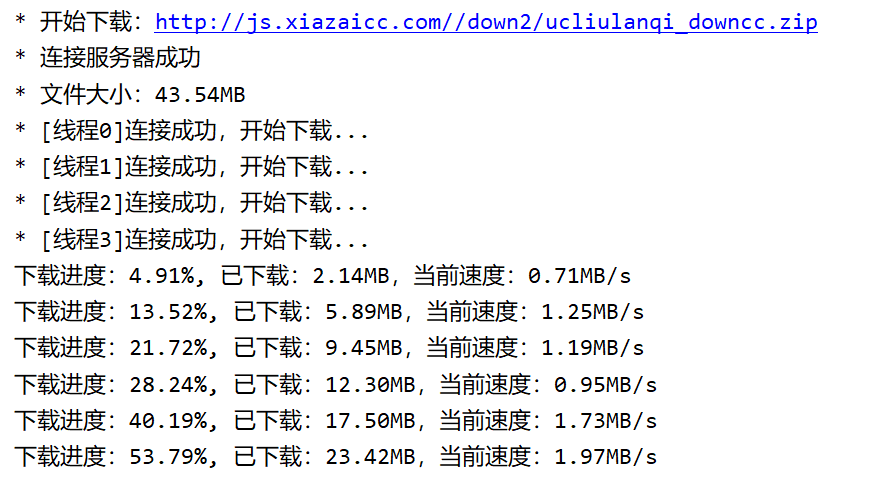
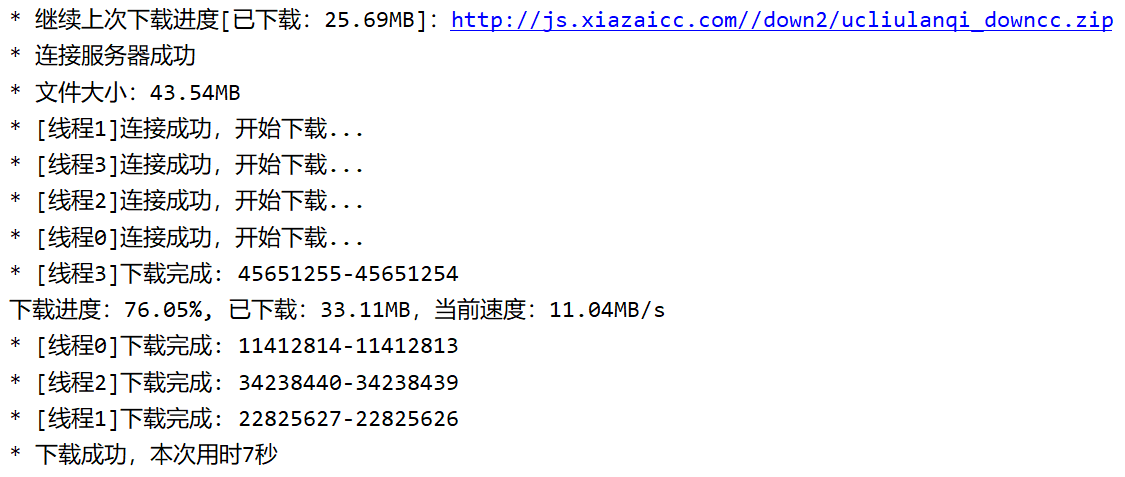
强行结束程序并重新运行:
日志文件:
断点续传的关键是记录各个线程的下载进度,这里细节比较多,花了很久。只需要记录每个线程请求的Range区间极客,每次成功写数据到文件时,就更新一次下载区间。下面是下载完成后的日志内容。
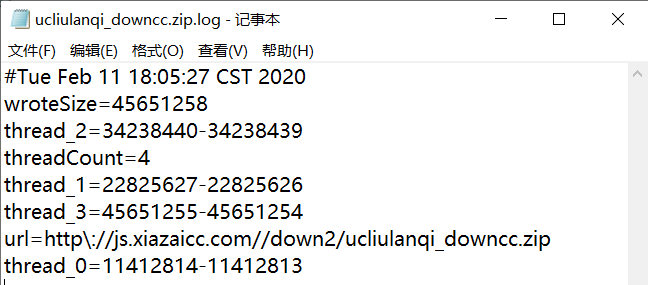
代码:
Downloader.java
package downloader;
import java.io.*;
import java.net.*;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.concurrent.atomic.AtomicBoolean;
public class Downloader {
private static final int DEFAULT_THREAD_COUNT = 4; // 默认线程数量
private AtomicBoolean canceled; // 取消状态,如果有一个子线程出现异常,则取消整个下载任务
private DownloadFile file; // 下载的文件对象
private String storageLocation;
private final int threadCount; // 线程数量
private long fileSize; // 文件大小
private final String url;
private long beginTime; // 开始时间
private Logger logger;
public Downloader(String url) {
this(url, DEFAULT_THREAD_COUNT);
}
public Downloader(String url, int threadCount) {
this.url = url;
this.threadCount = threadCount;
this.canceled = new AtomicBoolean(false);
this.storageLocation = url.substring(url.lastIndexOf('/')+1);
this.logger = new Logger(storageLocation + ".log", url, threadCount);
}
public void start() {
boolean reStart = Files.exists(Path.of(storageLocation + ".log"));
if (reStart) {
logger = new Logger(storageLocation + ".log");
System.out.printf("* 继续上次下载进度[已下载:%.2fMB]:%s\n", logger.getWroteSize() / 1014.0 / 1024, url);
} else {
System.out.println("* 开始下载:" + url);
}
if (-1 == (this.fileSize = getFileSize()))
return;
System.out.printf("* 文件大小:%.2fMB\n", fileSize / 1024.0 / 1024);
this.beginTime = System.currentTimeMillis();
try {
this.file = new DownloadFile(storageLocation, fileSize, logger);
if (reStart) {
file.setWroteSize(logger.getWroteSize());
}
// 分配线程下载
dispatcher(reStart);
// 循环打印进度
printDownloadProgress();
} catch (IOException e) {
System.err.println("x 创建文件失败[" + e.getMessage() + "]");
}
}
/**
* 分配器,决定每个线程下载哪个区间的数据
*/
private void dispatcher(boolean reStart) {
long blockSize = fileSize / threadCount; // 每个线程要下载的数据量
long lowerBound = 0, upperBound = 0;
long[][] bounds = null;
int threadID = 0;
if (reStart) {
bounds = logger.getBounds();
}
for (int i = 0; i < threadCount; i++) {
if (reStart) {
threadID = (int)(bounds[i][0]);
lowerBound = bounds[i][1];
upperBound = bounds[i][2];
} else {
threadID = i;
lowerBound = i * blockSize;
// fileSize-1 !!!!! fu.ck,找了一下午的错
upperBound = (i == threadCount - 1) ? fileSize-1 : lowerBound + blockSize;
}
new DownloadTask(url, lowerBound, upperBound, file, canceled, threadID).start();
}
}
/**
* 循环打印进度,直到下载完毕,或任务被取消
*/
private void printDownloadProgress() {
long downloadedSize = file.getWroteSize();
int i = 0;
long lastSize = 0; // 三秒前的下载量
while (!canceled.get() && downloadedSize < fileSize) {
if (i++ % 4 == 3) { // 每3秒打印一次
System.out.printf("下载进度:%.2f%%, 已下载:%.2fMB,当前速度:%.2fMB/s\n",
downloadedSize / (double)fileSize * 100 ,
downloadedSize / 1024.0 / 1024,
(downloadedSize - lastSize) / 1024.0 / 1024 / 3);
lastSize = downloadedSize;
i = 0;
}
try {
Thread.sleep(1000);
} catch (InterruptedException ignore) {}
downloadedSize = file.getWroteSize();
}
file.close();
if (canceled.get()) {
try {
Files.delete(Path.of(storageLocation));
} catch (IOException ignore) {
}
System.err.println("x 下载失败,任务已取消");
} else {
System.out.println("* 下载成功,本次用时"+ (System.currentTimeMillis() - beginTime) / 1000 +"秒");
}
}
/**
* @return 要下载的文件的尺寸
*/
private long getFileSize() {
if (fileSize != 0) {
return fileSize;
}
HttpURLConnection conn = null;
try {
conn = (HttpURLConnection)new URL(url).openConnection();
conn.setConnectTimeout(3000);
conn.setRequestMethod("HEAD");
conn.connect();
System.out.println("* 连接服务器成功");
} catch (MalformedURLException e) {
throw new RuntimeException("URL错误");
} catch (IOException e) {
System.err.println("x 连接服务器失败["+ e.getMessage() +"]");
return -1;
}
return conn.getContentLengthLong();
}
public static void main(String[] args) throws IOException {
new Downloader("http://js.xiazaicc.com//down2/ucliulanqi_downcc.zip").start();
}
}DownloadTask.java
package downloader;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
import java.nio.ByteBuffer;
import java.nio.channels.Channels;
import java.nio.channels.ReadableByteChannel;
import java.util.concurrent.atomic.AtomicBoolean;
class DownloadTask extends Thread {
private final String url;
private long lowerBound; // 下载的文件区间
private long upperBound;
private AtomicBoolean canceled;
private DownloadFile downloadFile;
private int threadId;
DownloadTask(String url, long lowerBound, long upperBound, DownloadFile downloadFile,
AtomicBoolean canceled, int threadID) {
this.url = url;
this.lowerBound = lowerBound;
this.upperBound = upperBound;
this.canceled = canceled;
this.downloadFile = downloadFile;
this.threadId = threadID;
}
@Override
public void run() {
ReadableByteChannel input = null;
try {
ByteBuffer buffer = ByteBuffer.allocate(1024 * 1024 * 2); // 2MB
input = connect();
System.out.println("* [线程" + threadId + "]连接成功,开始下载...");
int len;
while (!canceled.get() && lowerBound <= upperBound) {
buffer.clear();
len = input.read(buffer);
downloadFile.write(lowerBound, buffer, threadId, upperBound);
lowerBound += len;
}
if (!canceled.get()) {
System.out.println("* [线程" + threadId + "]下载完成" + ": " + lowerBound + "-" + upperBound);
}
} catch (IOException e) {
canceled.set(true);
System.err.println("x [线程" + threadId + "]遇到错误[" + e.getMessage() + "],结束下载");
} finally {
if (input != null) {
try {
input.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 连接WEB服务器,并返回一个数据通道
* @return 返回通道
* @throws IOException 网络连接错误
*/
private ReadableByteChannel connect() throws IOException {
HttpURLConnection conn = (HttpURLConnection)new URL(url).openConnection();
conn.setConnectTimeout(3000);
conn.setRequestMethod("GET");
conn.setRequestProperty("Range", "bytes=" + lowerBound + "-" + upperBound);
// System.out.println("thread_"+ threadId +": " + lowerBound + "-" + upperBound);
conn.connect();
int statusCode = conn.getResponseCode();
if (HttpURLConnection.HTTP_PARTIAL != statusCode) {
conn.disconnect();
throw new IOException("状态码错误:" + statusCode);
}
return Channels.newChannel(conn.getInputStream());
}
}DownloadFile.java
package downloader;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.util.concurrent.atomic.AtomicLong;
class DownloadFile {
private final RandomAccessFile file;
private final FileChannel channel; // 线程安全类
private AtomicLong wroteSize; // 已写入的长度
private Logger logger;
DownloadFile(String fileName, long fileSize, Logger logger) throws IOException {
this.wroteSize = new AtomicLong(0);
this.logger = logger;
this.file = new RandomAccessFile(fileName, "rw");
file.setLength(fileSize);
channel = file.getChannel();
}
/**
* 写数据
* @param offset 写偏移量
* @param buffer 数据
* @throws IOException 写数据出现异常
*/
void write(long offset, ByteBuffer buffer, int threadID, long upperBound) throws IOException {
buffer.flip();
int length = buffer.limit();
while (buffer.hasRemaining()) {
channel.write(buffer, offset);
}
wroteSize.addAndGet(length);
logger.updateLog(threadID, length, offset + length, upperBound); // 更新日志
}
/**
* @return 已经下载的数据量,为了知道何时结束整个任务,以及统计信息
*/
long getWroteSize() {
return wroteSize.get();
}
// 继续下载时调用
void setWroteSize(long wroteSize) {
this.wroteSize.set(wroteSize);
}
void close() {
try {
file.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}Logger.java
package downloader;
import java.io.*;
import java.util.Properties;
class Logger {
private String logFileName; // 下载的文件的名字
private Properties log;
/**
* 重新开始下载时,使用该构造函数
* @param logFileName
*/
Logger(String logFileName) {
this.logFileName = logFileName;
log = new Properties();
FileInputStream fin = null;
try {
log.load(new FileInputStream(logFileName));
} catch (IOException ignore) {
} finally {
try {
fin.close();
} catch (Exception ignore) {}
}
}
Logger(String logFileName, String url, int threadCount) {
this.logFileName = logFileName;
this.log = new Properties();
log.put("url", url);
log.put("wroteSize", "0");
log.put("threadCount", String.valueOf(threadCount));
for (int i = 0; i < threadCount; i++) {
log.put("thread_" + i, "0-0");
}
}
synchronized void updateLog(int threadID, long length, long lowerBound, long upperBound) {
log.put("thread_"+threadID, lowerBound + "-" + upperBound);
log.put("wroteSize", String.valueOf(length + Long.parseLong(log.getProperty("wroteSize"))));
FileOutputStream file = null;
try {
file = new FileOutputStream(logFileName); // 每次写时都清空文件
log.store(file, null);
} catch (IOException e) {
e.printStackTrace();
} finally {
if (file != null) {
try {
file.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 获取区间信息
* ret[i][0] = threadID, ret[i][1] = lowerBoundID, ret[i][2] = upperBoundID
* @return
*/
long[][] getBounds() {
long[][] bounds = new long[Integer.parseInt(log.get("threadCount").toString())][3];
int[] index = {0};
log.forEach((k, v) -> {
String key = k.toString();
if (key.startsWith("thread_")) {
String[] interval = v.toString().split("-");
bounds[index[0]][0] = Long.parseLong(key.substring(key.indexOf("_") + 1));
bounds[index[0]][1] = Long.parseLong(interval[0]);
bounds[index[0]++][2] = Long.parseLong(interval[1]);
}
});
return bounds;
}
long getWroteSize() {
return Long.parseLong(log.getProperty("wroteSize"));
}
}关于“基于Java实现多线程下载并允许断点续传的方法”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



