前言
现在很多web应用,做过web项目的童鞋都知道,web结果由html+js+css组成,html结构都有一定的规范,数据动态交互可以通过js实现。
有些时候,需要抓取某一个你感兴趣的网站信息,一个网站信息肯定是通过某一个url,发送http请求,根据地址定位的,当知道这个地址,可以获取到很多的网络响应,需要认真分析,找到你那一个合适的地址,最后通过这个地址返回一个html给你,我们可以得到这个html,分析结构,解析这个结构获取你要的数据。Html的结构解析往往是复杂繁琐的,我们可以使用java的支持包:jsoup,可以完成发送请求,解析html等功能,得到你感兴趣的数据。
下面就以一个彩票网站为例来简单说明整体操作流程,分为以下几大步骤:
1:根据官网,定位到自己感兴趣的模块:双色球:
本人选择的500彩票网站:请根据以下步骤,找到双色球板块。
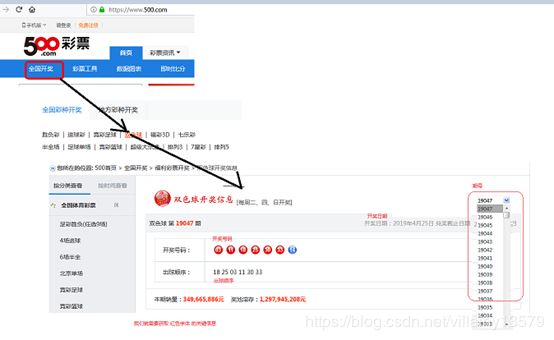
2:分析页面,找到它的入口地址
发现右侧有一个下拉选择框,这个是历史双色球开奖期号。改变这个值,浏览器会重新去请求这期的开奖信息,确定地址是:
http://kaijiang.500.com/shtml/ssq/选择期号.shtml
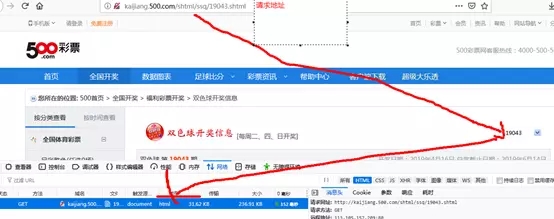
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven工程,导入jsoup的依赖:在你java类中,向2地址发送请求:获取返回的页面数据:

返回的html页面内容比较多,就不贴在这里的,下面直接对这个页面分析(特别说明,每一个html的结构不是一成不变的,有可能当读者看到这篇文章的时候,网站修改了网页结构,那么你需要重新分析,当然,估计这个网站修改网页结构的可能性比较小。。。。。。)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球+1个篮球组成,通过分析网页,是通过class来表示的,网页源码如下:
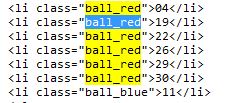
通过以下代码,获取到6个红球:

同理,可以获取到1个篮球。
根据这个原理,你可以获取你想要的很多的数据:以下是本人获取的数据

以上是个人对java中简单抓取网页数据的分享,感兴趣的童鞋可以自己的实践一下,实践出真知。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





