Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。而对于爬虫来说,使用Selenium操控浏览器来爬取网上的数据那么肯定是爬虫中的杀手武器。这里,我将介绍selenium + 谷歌浏览器的一般使用。首先会介绍如何安装部署环境,然后贴出一些本人所使用的一些方法,最后给出github地址,供大家下载。
1. selenium 环境配置
selenium 官网地址:http://www.seleniumhq.org/download/
导入selenium 的 jar 包有多种方式,这里介绍两个:
第一种是直接下载,然后将下载中的 jar 包复制到eclipse或者idea中,然后添加即可
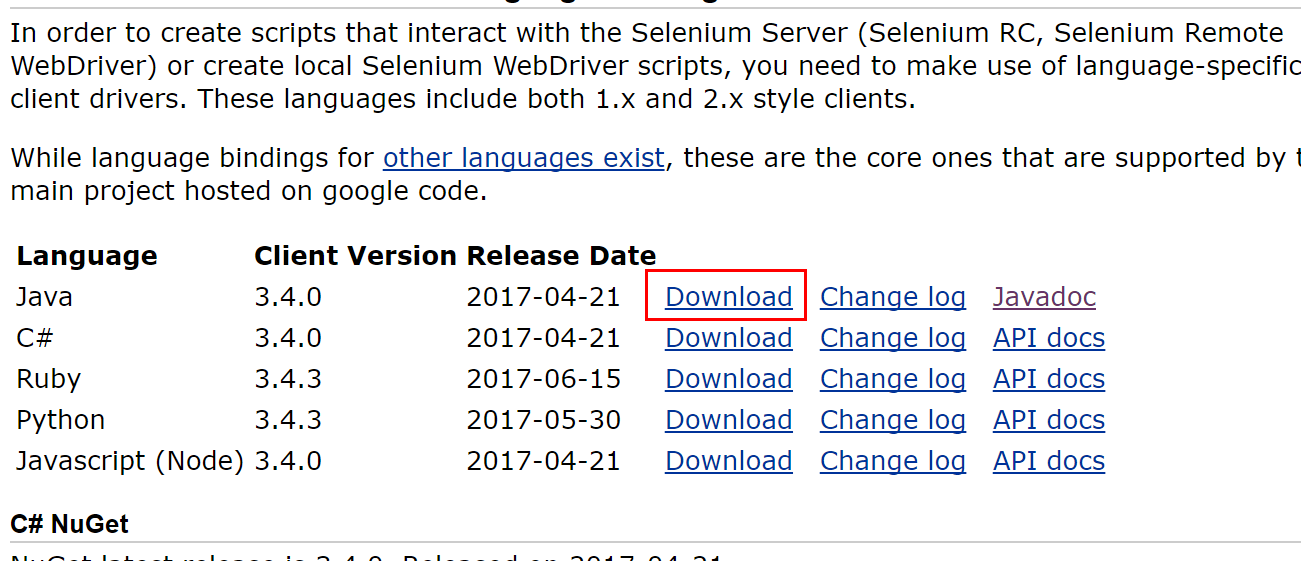
第二种是使用maven
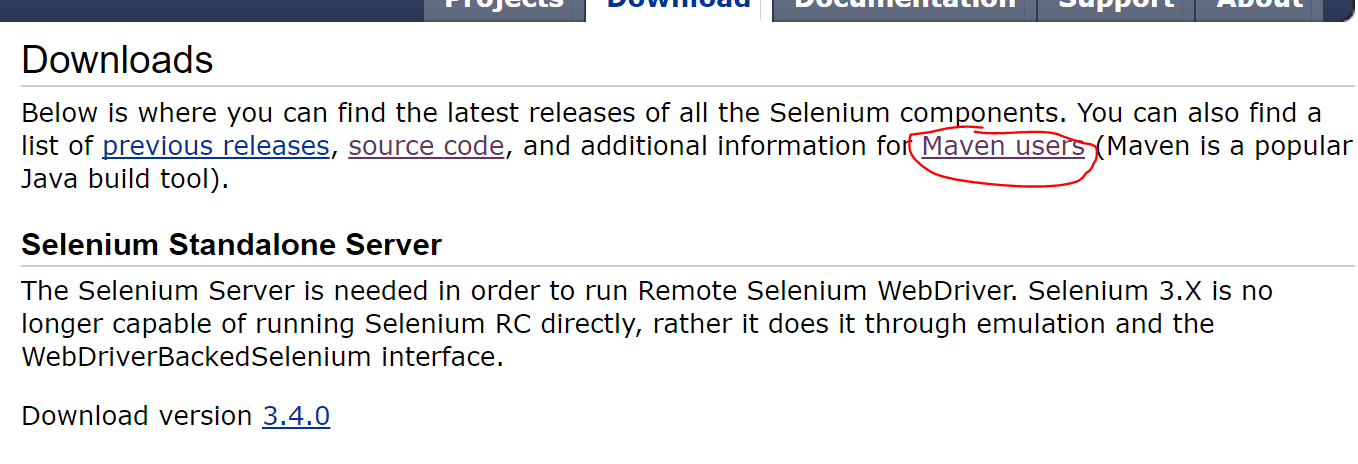
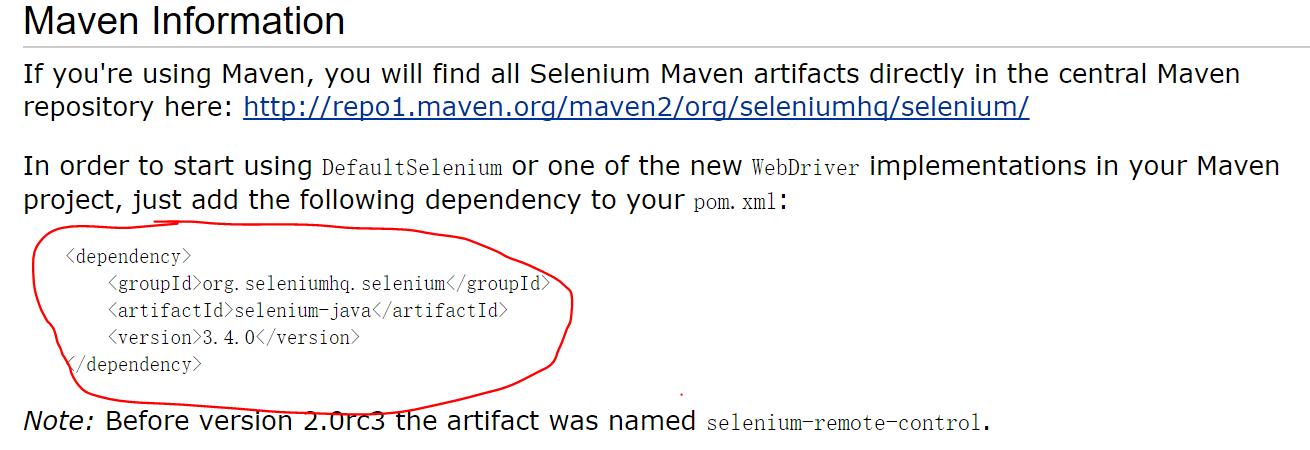
2. 下载github代码并且进行测试
谷歌浏览使用的版本是:60.0.3112.78,这里注意,谷歌浏览器和谷歌驱动需要匹配。
具体可以见:https://www.jb51.net/article/151629.htm

idea使用的版本是:2016.12
Java使用的版本是:1.8
首先在github上下载代码,地址为:https://github.com/lunaMoon1010/SeleniumDemo
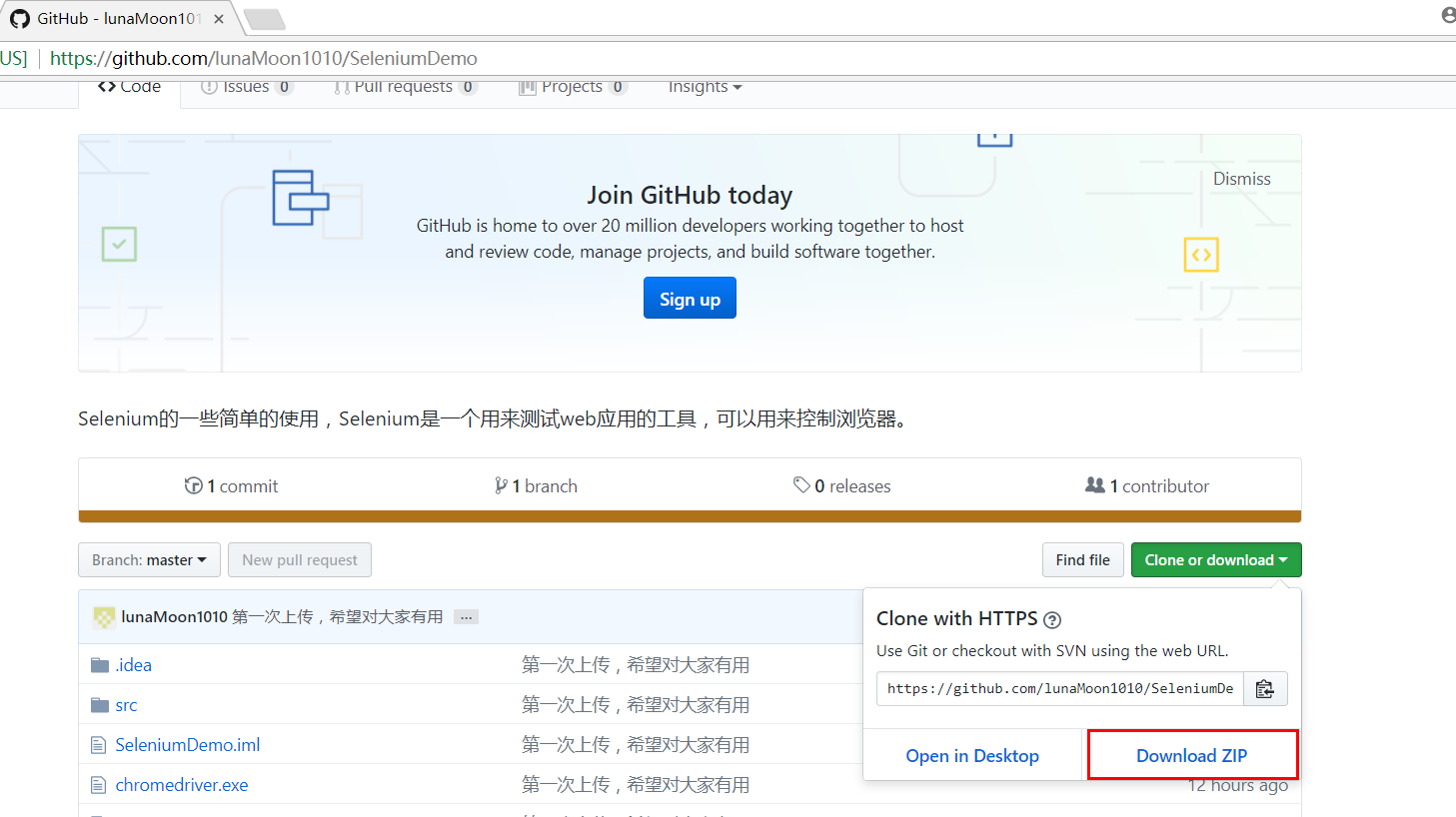
导入项目
1、解压后,使用idea导入该项目
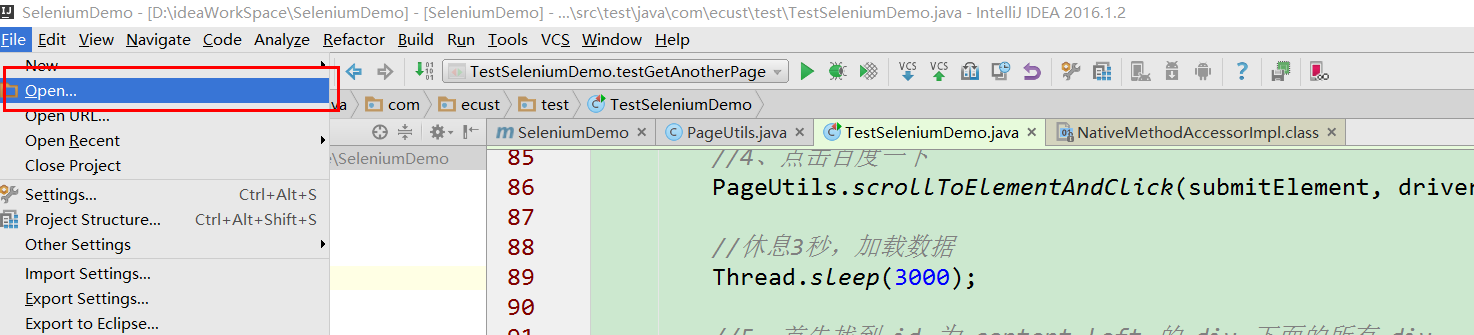
2、选择刚刚解压的项目
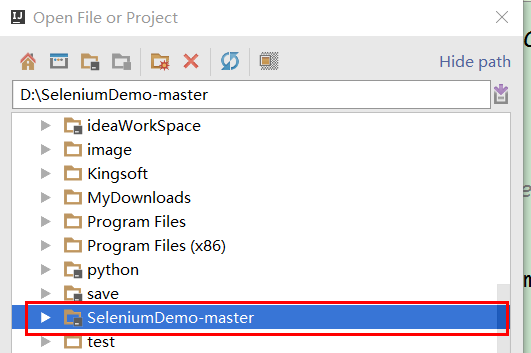
3、让maven导入jar包,maven简单来说是一个jar包管理插件,通过配置的方式在maven仓库下载你所需要的jar包

运行代码进行测试
1、测试HelloWorld,方法里面具体的内容请到方法里面查看,注释都是有写的
/**
* 用来测试第一个代码,访问百度
*/
@Test
public void testHelloWorld() throws Exception {
//开启个浏览器并且输入链接
WebDriver driver = PageUtils.getChromeDriver("https://www.baidu.com/");
//得到浏览器的标题
System.out.println(driver.getTitle());
Thread.sleep(5000);
//关闭浏览器 下面是关闭所有标签页,还有一个代码是 driver.close();, 关闭当前标签页
driver.quit();
}
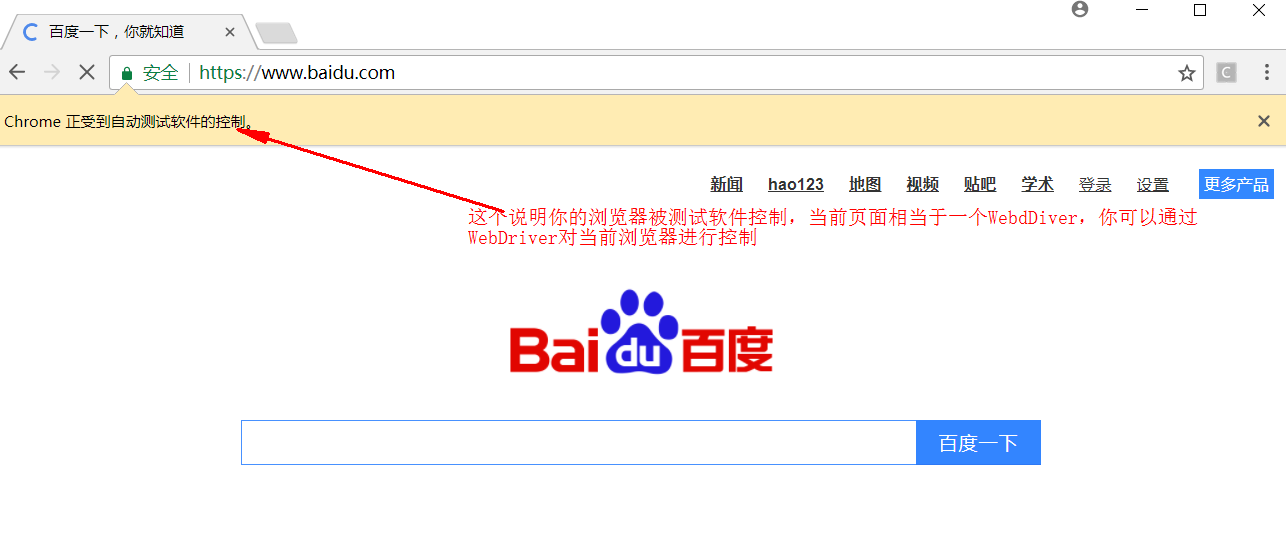
如果你运行出现下图情况,说明你环境上没有问题了
2、测试自动输入
/**
* 测试向input标签输入值
*/
@Test
public void testInputStrByJS(){
//开启个浏览器并且输入链接
WebDriver driver = PageUtils.getChromeDriver("https://www.baidu.com/");
//向input输入值
PageUtils.inputStrByJS(driver, "kw", "月之暗面 博客园");
}
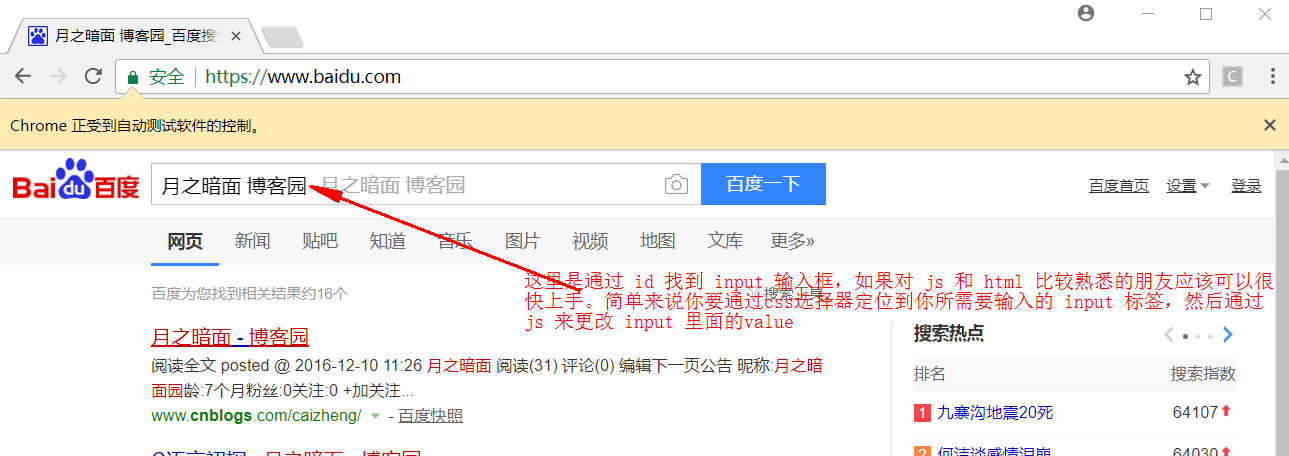
如果出现下面情况说明你测试成功了
3、测试点击
/**
* 测试点击
*/
@Test
public void testScrollToElementAndClick() throws Exception {
//1、开启个浏览器并且输入链接
WebDriver driver = PageUtils.getChromeDriver("https://www.baidu.com/");
//2、向百度输入框输入需要查询的值
PageUtils.inputStrByJS(driver, "kw", "月之暗面 博客园");
//3、得到百度一下的标签
WebElement submitElement = driver.findElement(By.cssSelector("input#su"));
//4、点击百度一下
PageUtils.scrollToElementAndClick(submitElement, driver);
//休息3秒,加载数据
Thread.sleep(3000);
//5、首先找到 id 为 content_left 的 div 下面的所有 div
List<WebElement> divElements = driver.findElements(By.cssSelector("div#content_left div"));
//6、找到搜索的第一个链接
WebElement aElement = divElements.get(0).findElement(By.cssSelector("div.f13 a[href]"));
//7、点击该链接
PageUtils.scrollToElementAndClick(aElement, driver);
}
如果出现下面情况,说明测试成功了
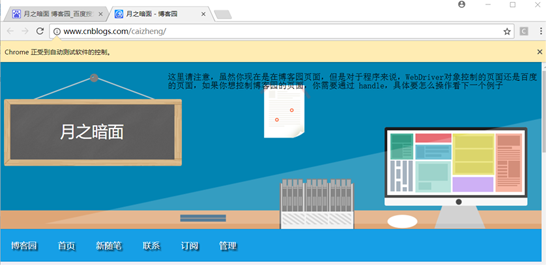
4、测试标签页切换
/**
* 测试切换到另一个标签页
*/
@Test
public void testGetAnotherPage() throws Exception {
//1、开启个浏览器并且输入链接
WebDriver driver = PageUtils.getChromeDriver("https://www.baidu.com/");
//2、向百度输入框输入需要查询的值
PageUtils.inputStrByJS(driver, "kw", "月之暗面 博客园");
//3、得到百度一下的标签
WebElement submitElement = driver.findElement(By.cssSelector("input#su"));
//4、点击百度一下
PageUtils.scrollToElementAndClick(submitElement, driver);
//休息3秒,加载数据
Thread.sleep(3000);
//5、首先找到 id 为 content_left 的 div 下面的所有 div
List<WebElement> divElements = driver.findElements(By.cssSelector("div#content_left div"));
//6、找到搜索的第一个链接
WebElement aElement = divElements.get(0).findElement(By.cssSelector("div.f13 a[href]"));
//7、点击该链接
PageUtils.scrollToElementAndClick(aElement, driver);
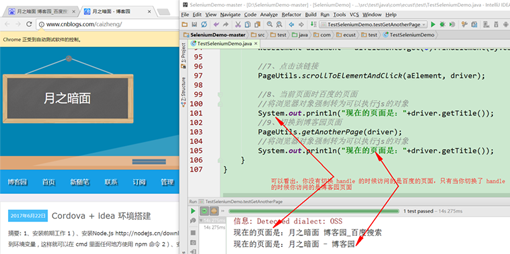
//8、当前页面时百度的页面
//将浏览器对象强制转为可以执行js的对象
System.out.println("现在的页面是:"+driver.getTitle());
//9、切换到博客园页面
PageUtils.getAnotherPage(driver);
//将浏览器对象强制转为可以执行js的对象
System.out.println("现在的页面是:"+driver.getTitle());
}
如果出现下面的情况说明你测试成功了
3.总结
Selenium是一个用于Web应用程序测试的工具。但是也可以用来做爬虫,如果需要得到对应的数据,可以通过 element.getText()的方法得到,element的类型是WebElement。期间可能会有很多错误,但是希望大家能够通过度娘,谷歌等方式一一解决。本人因为能力有限,有不足或错误之处,希望能够被指出。
最后再次填上这个的代码地址:https://github.com/lunaMoon1010/SeleniumDemo
如果要详细怎么使用请访问:http://www.webdriver.org/nav1/
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





