.зүҲжң¬ 2
.ж”ҜжҢҒеә“ shell
.ж”ҜжҢҒеә“ EDataStructure
.ж”ҜжҢҒеә“ iext
.зЁӢеәҸйӣҶ зӘ—еҸЈзЁӢеәҸйӣҶ1
.еӯҗзЁӢеәҸ _жҢүй’®_жөҸи§Ҳ_иў«еҚ•еҮ»
зј–иҫ‘жЎҶ_зӣ®еҪ•.еҶ…е®№ пјқ жөҸи§Ҳж–Ү件еӨ№ (вҖңйҖүжӢ©зӣ®еҪ•пјҡвҖқ, еҒҮ)
.еӯҗзЁӢеәҸ жһҡдёҫж–Ү件
.еҸӮж•° зӣ®еҪ•, ж–Үжң¬еһӢ
.еұҖйғЁеҸҳйҮҸ йҳҹеҲ—, йҳҹеҲ—
.еұҖйғЁеҸҳйҮҸ иҠӮзӮ№, иҠӮзӮ№
.еұҖйғЁеҸҳйҮҸ иҠӮзӮ№1, иҠӮзӮ№
.еұҖйғЁеҸҳйҮҸ и·Ҝеҫ„, ж–Үжң¬еһӢ
.еұҖйғЁеҸҳйҮҸ ж–Ү件еӨ№еҗҚз§°, ж–Үжң¬еһӢ
.еұҖйғЁеҸҳйҮҸ ж–Ү件еҗҚ, ж–Үжң¬еһӢ
.еұҖйғЁеҸҳйҮҸ ж–Ү件数зӣ®, ж•ҙж•°еһӢ
иҠӮзӮ№.еҠ е…ҘеұһжҖ§ (вҖңpathвҖқ, зӣ®еҪ•)
' жҠҠеҲқе§Ӣзӣ®еҪ•еҠ еҲ°йҳҹеҲ—
йҳҹеҲ—.еҺӢе…Ҙ (иҠӮзӮ№)
.еҲӨж–ӯеҫӘзҺҜйҰ– (йҳҹеҲ—.жҳҜеҗҰдёәз©ә () пјқ еҒҮ)
' еј№еҮәйҳҹеҲ—жңҖеүҚдёҖдёӘе…ғзҙ дҪңдёәзӣ®еҪ•,еҜ№иҜҘзӣ®еҪ•иҝӣиЎҢж–Ү件еӨ№жһҡдёҫе’Ңж–Ү件жһҡдёҫ
йҳҹеҲ—.еј№еҮә (иҠӮзӮ№1)
иҠӮзӮ№1.еҸ–ж–Үжң¬еҖј (вҖңpathвҖқ, и·Ҝеҫ„)
и·Ҝеҫ„ пјқ йҖүжӢ© (еҸ–ж–Үжң¬еҸіиҫ№ (и·Ҝеҫ„, 1) вү вҖң\вҖқ, и·Ҝеҫ„ пјӢ вҖң\вҖқ, и·Ҝеҫ„)
ж–Ү件еӨ№еҗҚз§° пјқ еҜ»жүҫж–Ү件 (и·Ҝеҫ„ пјӢ вҖң*.*вҖқ, #еӯҗзӣ®еҪ•)
.еҲӨж–ӯеҫӘзҺҜйҰ– (ж–Ү件еӨ№еҗҚз§° вү вҖңвҖқ)
.еҰӮжһңзңҹ (ж–Ү件еӨ№еҗҚз§° вү вҖң.вҖқ дё” ж–Ү件еӨ№еҗҚз§° вү вҖң..вҖқ)
' еҰӮжһңеңЁеҪ“еүҚзӣ®еҪ•дёӢжүҫеҲ°дәҶж–Ү件еӨ№,еҲҷжҠҠиҜҘж–Ү件еӨ№еҺӢе…ҘеҲ°йҳҹеҲ—,зӯүеҫ…жү«жҸҸиҜҘж–Ү件еӨ№зҡ„дёӢдёҖзә§зӣ®еҪ•е’Ңж–Ү件еҗҚ
иҠӮзӮ№.дҝ®ж”№еұһжҖ§ (вҖңpathвҖқ, и·Ҝеҫ„ пјӢ ж–Ү件еӨ№еҗҚз§°)
йҳҹеҲ—.еҺӢе…Ҙ (иҠӮзӮ№)
.еҰӮжһңзңҹз»“жқҹ
ж–Ү件еӨ№еҗҚз§° пјқ еҜ»жүҫж–Ү件 (, #еӯҗзӣ®еҪ•)
.еҲӨж–ӯеҫӘзҺҜе°ҫ ()
еӨ„зҗҶдәӢ件 ()
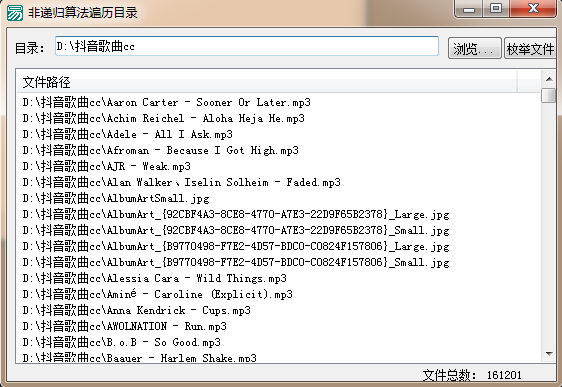
' еҜ»жүҫеҪ“еүҚзӣ®еҪ•зҡ„жүҖжңүж–Ү件
ж–Ү件еҗҚ пјқ еҜ»жүҫж–Ү件 (и·Ҝеҫ„ пјӢ вҖң*.*вҖқ, )
.еҲӨж–ӯеҫӘзҺҜйҰ– (ж–Ү件еҗҚ вү вҖңвҖқ)
и¶…зә§еҲ—иЎЁжЎҶ1.жҸ’е…ҘиЎЁйЎ№ (, и·Ҝеҫ„ пјӢ ж–Ү件еҗҚ, , , , )
ж–Ү件数зӣ® пјқ ж–Ү件数зӣ® пјӢ 1
ж Үзӯҫ3.ж Үйўҳ пјқ еҲ°ж–Үжң¬ (ж–Ү件数зӣ®)
ж–Ү件еҗҚ пјқ еҜ»жүҫж–Ү件 (, )
.еҲӨж–ӯеҫӘзҺҜе°ҫ ()
.еҲӨж–ӯеҫӘзҺҜе°ҫ ()
.еӯҗзЁӢеәҸ _жҢүй’®_жһҡдёҫ_иў«еҚ•еҮ»
и¶…зә§еҲ—иЎЁжЎҶ1.е…ЁйғЁеҲ йҷӨ ()
жһҡдёҫж–Ү件 (зј–иҫ‘жЎҶ_зӣ®еҪ•.еҶ…е®№)
дҝЎжҒҜжЎҶ (вҖңе®ҢжҜ•пјҒвҖқ, 0, )
д»ҘдёҠе°ұжҳҜиҝҷзҜҮж–Үз« зҡ„е…ЁйғЁеҶ…е®№дәҶпјҢеёҢжңӣжң¬ж–Үзҡ„еҶ…е®№еҜ№еӨ§е®¶зҡ„еӯҰд№ жҲ–иҖ…е·ҘдҪңе…·жңүдёҖе®ҡзҡ„еҸӮиҖғеӯҰд№ д»·еҖјпјҢи°ўи°ўеӨ§е®¶еҜ№дәҝйҖҹдә‘зҡ„ж”ҜжҢҒгҖӮеҰӮжһңдҪ жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№иҜ·жҹҘзңӢдёӢйқўзӣёе…ій“ҫжҺҘ