hashing(散列法或哈希法)的概念
散列法(Hashing)是一种将字符组成的字符串转换为固定长度(一般是更短长度)的数值或索引值的方法,称为散列法,也叫哈希法。由于通过更短的哈希值比用原始值进行数据库搜索更快,这种方法一般用来在数据库中建立索引并进行搜索,同时还用在各种解密算法中。
HashMap概念和底层结构
HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。HashMap储存的是键值对,HashMap很快。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
数组:存储区间连续,占用内存严重,寻址容易,插入删除困难;
链表:存储区间离散,占用内存比较宽松,寻址困难,插入删除容易;
Hashmap综合应用了这两种数据结构,实现了寻址容易,插入删除也容易。
hashMap的结构示意图如下:
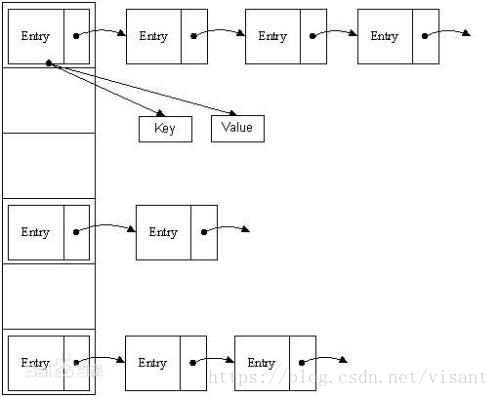
HashMap的基本存储原理以及存储内容的组成
基本原理:先声明一个下标范围比较大的数组来存储元素。另外设计一个哈希函数(也叫做散列函数)来获得每一个元素的Key(关键字)的函数值(即数组下标,hash值)相对应,数组存储的元素是一个Entry类,这个类有三个数据域,key、value(键值对),next(指向下一个Entry)。
例如, 第一个键值对A进来。通过计算其key的hash得到的index=0。记做:Entry[0] = A。
第二个键值对B,通过计算其index也等于0, HashMap会将B.next =A,Entry[0] =B,
第三个键值对 C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方事实上存取了A,B,C三个键值对,它们通过next这个属性链接在一起。我们可以将这个地方称为桶。 对于不同的元素,可能计算出了相同的函数值,这样就产生了“冲突”,这就需要解决冲突,“直接定址”与“解决冲突”是哈希表的两大特点。
HashMap的工作原理以及存取方法过程
HashMap的工作原理 :HashMap是基于散列法(又称哈希法hashing)的原理,使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,返回的hashCode用于找到bucket(桶)位置来储存Entry对象。”HashMap是在bucket中储存键对象和值对象,作为Map.Entry。并不是仅仅只在bucket中存储值。
HashMap具体的存取过程如下:
put键值对的方法的过程是:
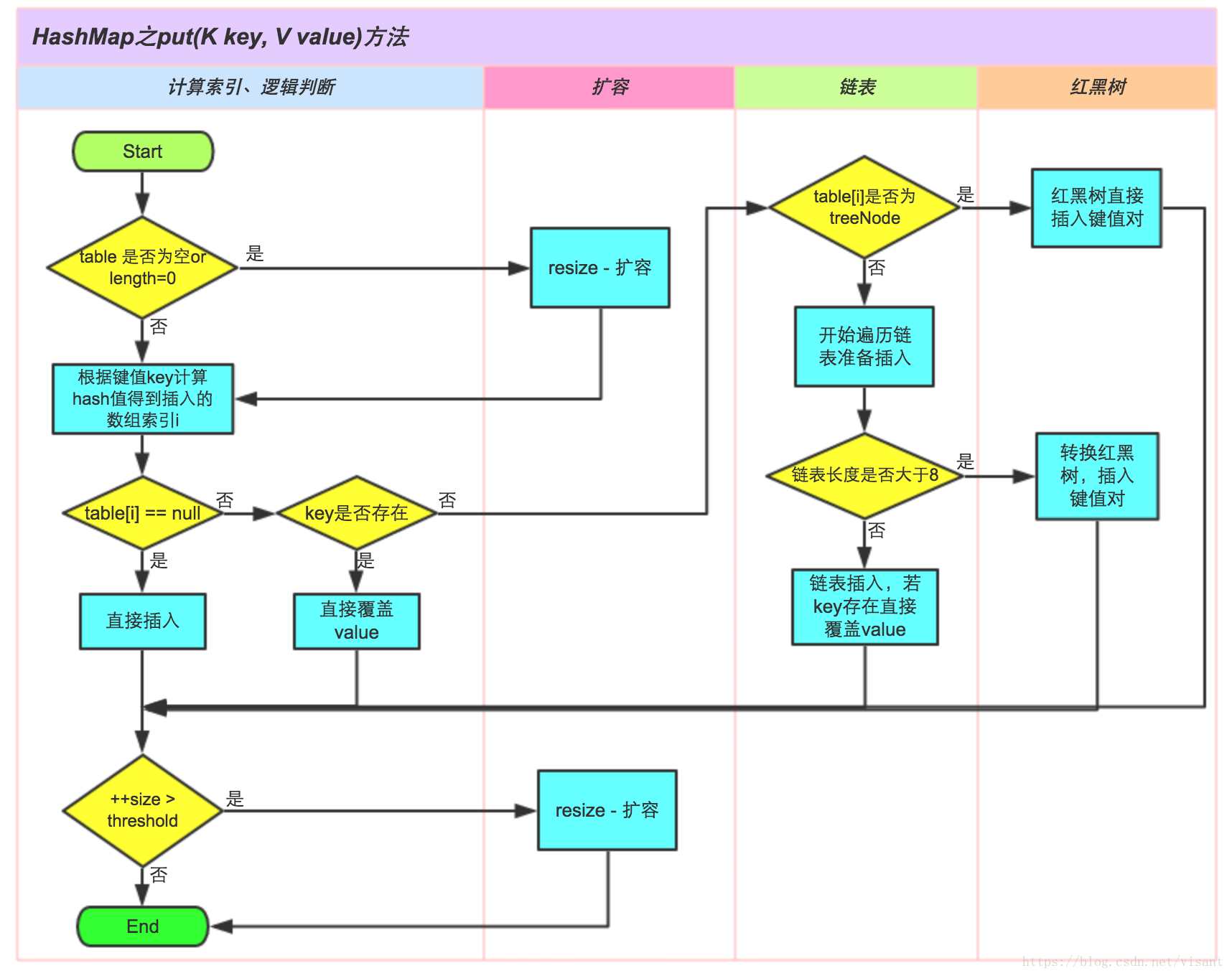
get值方法的过程是:
1、指定key 通过hash函数得到key的hash值
int hash=key.hashCode();
2、调用内部方法 getNode(),得到桶号(一般都为hash值对桶数求模)
int index =hash%Entry[].length;
3、比较桶的内部元素是否与key相等,若都不相等,则没有找到。相等,则取出相等记录的value。
4、如果得到 key 所在的桶的头结点恰好是红黑树节点,就调用红黑树节点的 getTreeNode() 方法,否则就遍历链表节点。getTreeNode 方法使通过调用树形节点的 find()方法进行查找。由于之前添加时已经保证这个树是有序的,因此查找时基本就是折半查找,效率很高。
5、如果对比节点的哈希值和要查找的哈希值相等,就会判断 key 是否相等,相等就直接返回;不相等就从子树中递归查找。
HashMap中直接地址用hash函数生成;解决冲突,用比较函数解决。如果每个桶内部只有一个元素,那么查找的时候只有一次比较。当许多桶内没有值时,许多查询就会更快了(指查不到的时候)。
HashMap中的碰撞探测(collision detection)以及碰撞的解决方法
当两个对象的hashcode相同时,它们的bucket位置相同,‘碰撞'会发生。因为HashMap使用LinkedList存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在LinkedList中。这两个对象就算hashcode相同,但是它们可能并不相等。 那如何获取这两个对象的值呢?当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,遍历LinkedList直到找到值对象。找到bucket位置之后,会调用keys.equals()方法去找到LinkedList中正确的节点,最终找到要找的值对象使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法的话,将会减少碰撞的发生,提高效率。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择。
如何重新调整HashMap的大小
“如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?”
默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
以上所述是小编给大家介绍的HashMap原理的理解详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对亿速云网站的支持!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



