这篇文章将为大家详细讲解有关JAVA8流之概念和收集器的示例分析,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
在没有流以前,处理集合里面的数据一般都会用到显示的迭代器。用一下前面学生的例子吧。目标是获得学分大于5的前俩位同学。
package com.aomi;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import static java.util.stream.Collectors.toList;
public class Main {
public static void main(String[] args) {
// TODO Auto-generated method stub
List<Student> stus = getSources();
Iterator<Student> ite = stus.iterator();
List<String> names = new ArrayList<>();
int limit = 2;
while (ite.hasNext() && limit > 0) {
Student stu = ite.next();
if (stu.getScore() > 5) {
names.add(stu.getName());
limit--;
}
}
for (String name : names) {
System.out.println(name);
}
}
public static List<Student> getSources() {
List<Student> students = new ArrayList<>();
Student stu1 = new Student();
stu1.setName("lucy");
stu1.setSex(0);
stu1.setPhone("13700227892");
stu1.setScore(9);
Student stu2 = new Student();
stu2.setName("lin");
stu2.setSex(1);
stu2.setPhone("15700227122");
stu2.setScore(9);
Student stu3 = new Student();
stu3.setName("lili");
stu3.setSex(0);
stu3.setPhone("18500227892");
stu3.setScore(8);
Student stu4 = new Student();
stu4.setName("dark");
stu4.setSex(1);
stu4.setPhone("16700555892");
stu4.setScore(6);
students.add(stu1);
students.add(stu2);
students.add(stu3);
students.add(stu4);
return students;
}
}如果用流的话是这样子的。
public static void main(String[] args) {
// TODO Auto-generated method stub
List<Student> stus = getSources();
List<String> names = stus.stream()
.filter(st -> st.getScore() > 5)
.limit(2)
.map(st -> st.getName())
.collect(toList());
for (String name : names) {
System.out.println(name);
}
}把这俩段代码相比较主要是为了说明一个概念:以前做法都是在外部迭代,最为体现就是笔者在外面定义了一个集合names 。而流却什么也没有,现在我们应该能清楚感受到流是在内部迭代。也就是说流已经帮你做好了迭代。我们只要传入相关的函数就可以得到想要的结果。至于内部迭代的好处,笔者没有办法亲身的感受,唯一的感觉就是代码变的简单明了了。但是官方说Stream库为了我们在内部迭代里面做了很多优化和充公利用性能的操作。比如并行操作。所以笔者就听官方了。
事实上,在用流的过程中,我们用到很多方法函数。比如上面的limit方法,filter方法等。这个定义为流操作。但是不管是什么操作,你必须要有一个数据源吧。总结如下:
数据源:用于生成流的数据,比如集合。
流操作:类似于limit方法,filter方法。
流还有一种特点——部分流操作是没有执行的。一般都是在collect函数执行的时候,才开始执行个个函数。所以我们可以细分一下流操作:
数据源:用于生成流的数据,比如集合。
中间操作:类似于limit方法,filter方法。这些操作做变了一个操作链,有一点流水线的概念。
终端操作:执行上面的操作链。比如collect函数。
从上面的讲解我们就可以感觉流好像是先收集相关的目标操作,什么意思呢?就是先把要做的事情计划一下,最后一声令下执行。而下这个命令是collect函数。这一点跟.NET的Linq是很像的。同时记得他只能执行一次。也就是说这个流执行一次之后,就不可能在用了。
笔者列一下以前的用到的函数
forEach:终端
collect:终端
count:终端
limit:中间
filter:中间
map:中间
sorted:中间
到目前为止我们用到的流都是通过集合来建一个流。笔者对此从来没有讲过。现在笔者来讲些构建流的方式。
在stream库里面为我们提供了这样子一个方法——Stream.of
package com.aomi;
import java.util.Optional;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
// TODO Auto-generated method stub
Stream stream = Stream.of("I", "am", "aomi");
Optional<String> firstWord = stream.findFirst();
if(firstWord.isPresent())
{
System.out.println("第一个字:"+firstWord.get());
}
}
}运行结果:
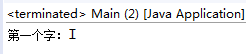
去看一下of方法的代码。如下
public static<T> Stream<T> of(T... values) {
return Arrays.stream(values);
}说明我们可能指定一个类型来建一个流。上面可以修改为
Stream<String> stream = Stream.of("I", "am", "aomi");findFirst函数用于表示返回第一个值。那就是可能数据源是一个空呢?所以他有可以会返回null。所以就是用一个叫Optional类的表示可以为空。这样子我们就可以用Optional类的方法进一步做安全性的操作。比如判断有没有值(isPresent())
笔者想要建一个int类型的数组流玩玩。为了方便笔者便试给一下上面的代码。却发现报错了。
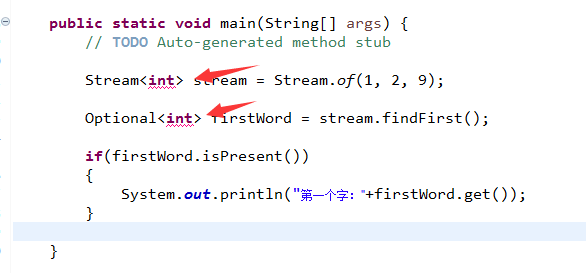
如果我把int改为Integer呢?没有问题了。所以注意要用引用类型的。int类型对应为Integer类型。
package com.aomi;
import java.util.Optional;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
// TODO Auto-generated method stub
Stream<Integer> stream = Stream.of(1, 2, 9);
Optional<Integer> firstWord = stream.findFirst();
if(firstWord.isPresent())
{
System.out.println("第一个字:"+firstWord.get());
}
}
}运行结果:

那想要用int类型呢?什么办呢?改改
package com.aomi;
import java.util.OptionalInt;
import java.util.stream.IntStream;
public class Main {
public static void main(String[] args) {
// TODO Auto-generated method stub
IntStream stream = IntStream.of(1, 2, 9);
OptionalInt firstWord = stream.findFirst();
if(firstWord.isPresent())
{
System.out.println("第一个字:"+firstWord.getAsInt());
}
}
}运行结果:

我们以上面的例子来一个猜测:是不是Double类型,只要修改为DoubleStream就行呢?试试。
package com.aomi;
import java.util.OptionalDouble;
import java.util.stream.DoubleStream;
public class Main {
public static void main(String[] args) {
// TODO Auto-generated method stub
DoubleStream stream = DoubleStream.of(1.3, 2.3, 9.5);
OptionalDouble firstWord = stream.findFirst();
if(firstWord.isPresent())
{
System.out.println("第一个字:"+firstWord.getAsDouble());
}
}
}运行结果:

结果很明显,我们的猜测是对的。所以见意如果你操作的流是一个int或是double的话,请进可能的用XxxStream 来建流。这样子在流的过程中不用进行拆装和封装了。必竟这是要性能的。在看一下如果数据源是一个数组的情况我们如何生成流呢?
public static Collector<CharSequence, ?, String> joining(CharSequence delimiter,
CharSequence prefix,
CharSequence suffix) {
return new CollectorImpl<>(
() -> new StringJoiner(delimiter, prefix, suffix),
StringJoiner::add, StringJoiner::merge,
StringJoiner::toString, CH_NOID);
}在看一个叫toList函数的代码。
public static <T>
Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add,
(left, right) -> { left.addAll(right); return left; },
CH_ID);
}我们发现他会共同的返回一个Collector类型。从上面我们就可以知道他的任务就是用去处理最后数据。我们把他定为收集器。让我们看一下收集器的接口代码吧;
public interface Collector<T, A, R> {
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
BinaryOperator<A> combiner();
Function<A, R> finisher();
Set<Characteristics> characteristics();
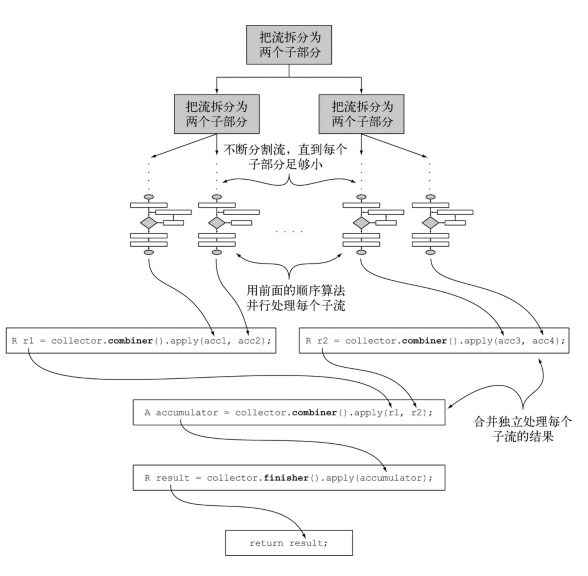
}光看前面四个方法是不是有一点熟悉的感觉。想要说明这个五个方法的作用。就必须明白一个概念——并行归约。前面笔者讲过流是一个内部迭代,也说Stream库为我们做一个很多优化的事情。其中一个就是并行。他用到了JAVA 7引入的功能——分支/合并框架。也就是说流会以递归的方式拆分成很多子流,然后子流可以并行执行。最后在俩俩的子流的结果合并成一个最终结果。而这俩俩合并的行为就叫归约 。如图下。引用于《JAVA8实战》
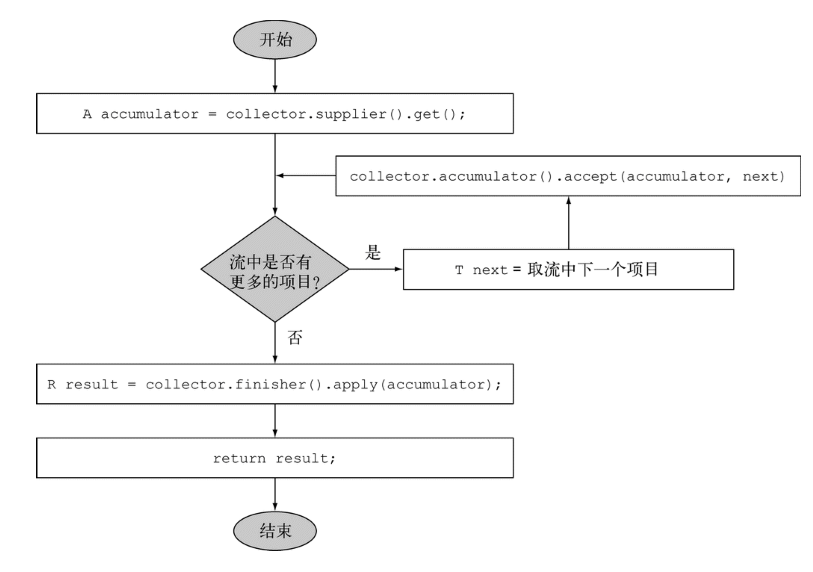
我们必须根据图上的意思来走。子流的图里面会调用到Collector类的三个方法。
supplier方法:用创建数据存储的地方。
accumulator方法:用于子流执行过程的迭代工作。即是遍历每一项都会执行。所以可以这里做一些工作。
finisher方法:返回最后的结果,你可以在这里进一步处理结果。
每一个子流结束这之后,就是俩俩合并。这个时候就要看流的机制图了。
combiner方法:会传入每一个子流的结果过来,我们就可以在这里在做一些工作。
finisher方法:返回最后的结果。同上面子流的一样子。
好像没有characteristics什么事情。不是这样子的。这个方法是用来说明当前这个流具备哪些优化。这样子执行流的时候,就可以很清楚的知道要以什么样子的方式执行了。比如并行。
他是一个enum类。值如下
UNORDERED:这个表示执行过程中结果不受归约和遍历的影响
CONCURRENT:表示可以多个线和调用accumulator方法。并且可以执行并行。当然前无序数据的才并行。除非收集器标了UNORDERED。
IDENTITY_FINISH:表示这是一个恒等函数,就是做了结果也一样子。不用做了可以跳过了。
由了上面的讲说明,我们在来写一个自己的收集器吧——去除相同的单词
DistinctWordCollector类:
package com.aomi;
import java.util.ArrayList;
import java.util.Collections;
import java.util.EnumSet;
import java.util.List;
import java.util.Set;
import java.util.function.BiConsumer;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.function.Supplier;
import java.util.stream.Collector;
public class DistinctWordCollector implements Collector<String, List<String>, List<String>> {
@Override
public Supplier<List<String>> supplier() {
// TODO Auto-generated method stub
return () -> new ArrayList<String>();
}
/**
* 子流的处理项的过程
*/
@Override
public BiConsumer<List<String>, String> accumulator() {
// TODO Auto-generated method stub
return (List<String> src, String val) -> {
if (!src.contains(val)) {
src.add(val);
}
};
}
/**
* 俩俩并合的执行函数
*/
@Override
public BinaryOperator<List<String>> combiner() {
// TODO Auto-generated method stub
return (List<String> src1, List<String> src2) -> {
for (String val : src2) {
if (!src1.contains(val)) {
src1.add(val);
}
}
return src1;
};
}
@Override
public Function<List<String>, List<String>> finisher() {
// TODO Auto-generated method stub
return Function.identity();
}
@Override
public Set<Characteristics> characteristics() {
// TODO Auto-generated method stub
return Collections.unmodifiableSet(EnumSet.of(Characteristics.IDENTITY_FINISH, Characteristics.CONCURRENT));
}
}Main:
public static void main(String[] args) {
// TODO Auto-generated method stub
List<String> words = Arrays.asList("aomi","lili","lucy","aomi","Nono");
List<String> vals = words.stream().collect(new DistinctWordCollector());
for (String val : vals) {
System.out.println(val);
}
}运行结果

结果确定就是我们想要的——去掉了重复的aomi
关于“JAVA8流之概念和收集器的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





