为啥要用HahSet?
假如我们现在想要在一大堆数据中查找X数据。LinkedList的数据结构就不说了,查找效率低的可怕。ArrayList哪,如果我们不知道X的位置序号,还是一样要全部遍历一次直到查到结果,效率一样可怕。HashSet天生就是为了提高查找效率的。
背景
上午刚到公司,准备开始一天的摸鱼之旅时突然收到了一封监控中心的邮件。
心中暗道不好,因为监控系统从来不会告诉我应用完美无 bug,其实系统挺猥琐。
打开邮件一看,果然告知我有一个应用的线程池队列达到阈值触发了报警。
由于这个应用出问题非常影响用户体验;于是立马让运维保留现场 dump 线程和内存同时重启应用,还好重启之后恢复正常。于是开始着手排查问题。
分析
首先了解下这个应用大概是做什么的。
简单来说就是从 MQ 中取出数据然后丢到后面的业务线程池中做具体的业务处理。
而报警的队列正好就是这个线程池的队列。
跟踪代码发现构建线程池的方式如下:
ThreadPoolExecutor executor = new ThreadPoolExecutor(coreSize, maxSize,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());;
put(poolName,executor);采用的是默认的 LinkedBlockingQueue 并没有指定大小(这也是个坑),于是这个队列的默认大小为 Integer.MAX_VALUE。
由于应用已经重启,只能从仅存的线程快照和内存快照进行分析。
内存分析
先利用 MAT 分析了内存,的到了如下报告。
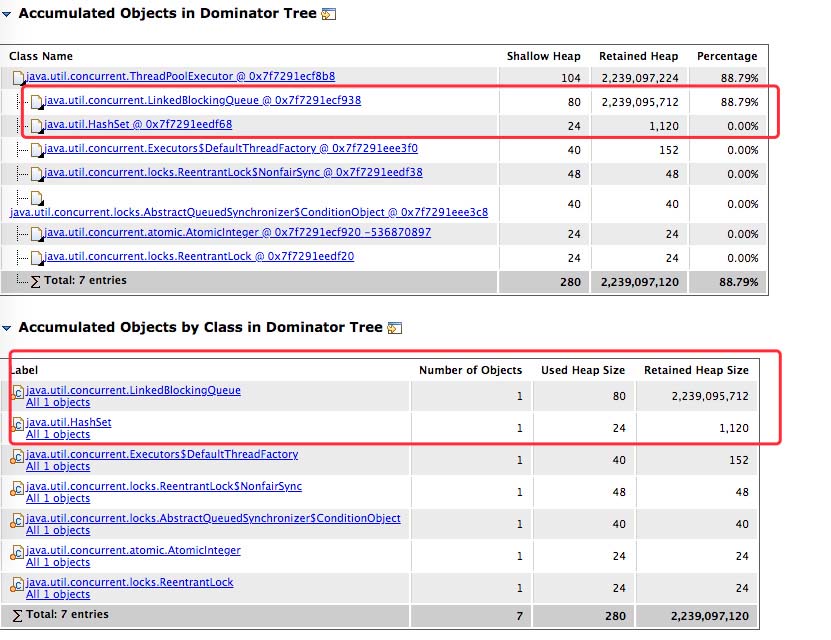
其中有两个比较大的对象,一个就是之前线程池存放任务的 LinkedBlockingQueue,还有一个则是 HashSet。
当然其中队列占用了大量的内存,所以优先查看,HashSet 一会儿再看。
由于队列的大小给的够大,所以结合目前的情况来看应当是线程池里的任务处理较慢,导致队列的任务越堆越多,至少这是目前可以得出的结论。
线程分析
再来看看线程的分析,这里利用fastthread.io 这个网站进行线程分析。
因为从表现来看线程池里的任务迟迟没有执行完毕,所以主要看看它们在干嘛。
正好他们都处于 RUNNABLE 状态,同时堆栈如下:

发现正好就是在处理上文提到的 HashSet,看这个堆栈是在查询 key 是否存在。通过查看 312 行的业务代码确实也是如此。
这里的线程名字也是个坑,让我找了好久。
定位
分析了内存和线程的堆栈之后其实已经大概猜出一些问题了。
这里其实有一个前提忘记讲到:
这个告警是凌晨三点发出的邮件,但并没有电话提醒之类的,所以大家都不知道。
到了早上上班时才发现并立即 dump 了上面的证据。
所有有一个很重要的事实:这几个业务线程在查询 HashSet 的时候运行了 6 7 个小时都没有返回。
通过之前的监控曲线图也可以看出:
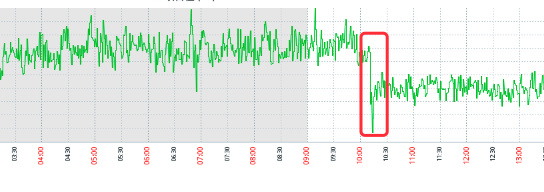
操作系统在之前一直处于高负载中,直到我们早上看到报警重启之后才降低。
同时发现这个应用生产上运行的是 JDK1.7 ,所以我初步认为应该是在查询 key 的时候进入了 HashMap 的环形链表导致 CPU 高负载同时也进入了死循环。
为了验证这个问题再次 review 了代码。
整理之后的伪代码如下:
//线程池
private ExecutorService executor;
private Set<String> set = new hashSet();
private void execute(){
while(true){
//从 MQ 中获取数据
String key = subMQ();
executor.excute(new Worker(key)) ;
}
}
public class Worker extends Thread{
private String key ;
public Worker(String key){
this.key = key;
}
@Override
private void run(){
if(!set.contains(key)){
//数据库查询
if(queryDB(key)){
set.add(key);
return;
}
}
//达到某种条件时清空 set
if(flag){
set = null ;
}
}
}大致的流程如下:
这里有一个很明显的问题,那就是作为共享资源的 Set 并没有做任何的同步处理。
这里会有多个线程并发的操作,由于 HashSet 其实本质上就是 HashMap,所以它肯定是线程不安全的,所以会出现两个问题:
第一个问题相对于第二个还能接受。
通过上文的内存分析我们已经知道这个 set 中的数据已经不少了。同时由于初始化时并没有指定大小,仅仅只是默认值,所以在大量的并发写入时候会导致频繁的扩容,而在 1.7 的条件下又可能会形成环形链表。
不巧的是代码中也有查询操作(contains()),观察上文的堆栈情况:

发现是运行在 HashMap 的 465 行,来看看 1.7 中那里具体在做什么:
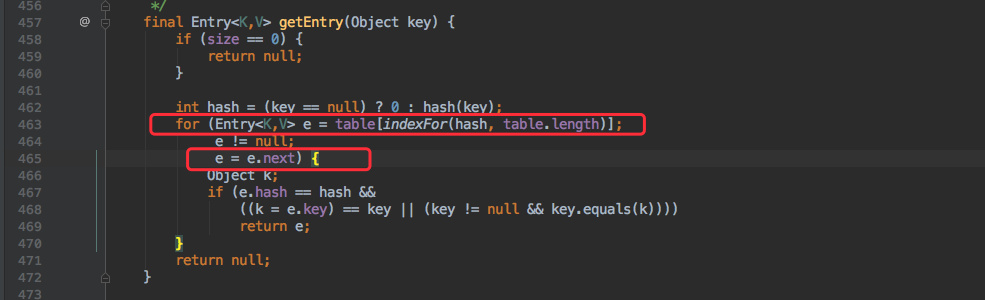
已经很明显了。这里在遍历链表,同时由于形成了环形链表导致这个 e.next 永远不为空,所以这个循环也不会退出了。
到这里其实已经找到问题了,但还有一个疑问是为什么线程池里的任务队列会越堆越多。我第一直觉是任务执行太慢导致的。
仔细查看了代码发现只有一个地方可能会慢:也就是有一个数据库的查询。
把这个 SQL 拿到生产环境执行发现确实不快,查看索引发现都有命中。
但我一看表中的数据发现已经快有 7000W 的数据了。同时经过运维得知 MySQL 那台服务器的 IO 压力也比较大。
所以这个原因也比较明显了:
由于每消费一条数据都要去查询一次数据库,MySQL 本身压力就比较大,加上数据量也很高所以导致这个 IO 响应较慢,导致整个任务处理的就比较慢了。
但还有一个原因也不能忽视;由于所有的业务线程在某个时间点都进入了死循环,根本没有执行完任务的机会,而后面的数据还在源源不断的进入,所以这个队列只会越堆越多!
这其实是一个老应用了,可能会有人问为什么之前没出现问题。
这是因为之前数据量都比较少,即使是并发写入也没有出现并发扩容形成环形链表的情况。这段时间业务量的暴增正好把这个隐藏的雷给揪出来了。所以还是得信墨菲他老人家的话。
总结
至此整个排查结束,而我们后续的调整措施大概如下:
HashMap 的死循环问题在网上层出不穷,没想到还真被我遇到了。现在要满足这个条件还是挺少见的,比如 1.8 以下的 JDK 这一条可能大多数人就碰不到,正好又证实了一次墨菲定律。
好了,以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



