这期内容当中小编将会给大家带来有关Java中怎么读写字符流文件,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
基类 Reader/Writer
在正式学习字符流基类之前,我们需要知道 Java 中是如何表示一个字符的。
首先,Java 中的默认字符编码为:UTF-8,而我们知道 UTF-8 编码的字符使用 1 到 4 个字节进行存储,越常用的字符使用越少的字节数。
而 char 类型被定义为两个字节大小,也就是说,对于通常的字符来说,一个 char 即可存储一个字符,但对于一些增补字符集来说,往往会使用两个 char 来表示一个字符。
Reader 作为读字符流的基类,它提供了最基本的字符读取操作,我们一起看看。
先看看它的构造器:
protected Object lock;
protected Reader() {
this.lock = this;
}
protected Reader(Object lock) {
if (lock == null) {
throw new NullPointerException();
}
this.lock = lock;
}Reader 是一个抽象类,所以毋庸置疑的是,这些构造器是给子类调用的,用于初始化 lock 锁对象,这一点我们后续会详细解释。
public int read() throws IOException {
char cb[] = new char[1];
if (read(cb, 0, 1) == -1)
return -1;
else
return cb[0];
}
public int read(char cbuf[]) throws IOException {
return read(cbuf, 0, cbuf.length);
}
abstract public int read(char cbuf[], int off, int len)基本的读字符操作都在这了,第一个方法用于读取一个字符出来,如果已经读到了文件末尾,将返回 -1,同样的以 int 作为返回值类型接收,为什么不用 char?原因是一样的,都是由于 -1 这个值的解释不确定性。
第二个方法和第三个方法是类似的,从文件中读取指定长度的字符放置到目标数组当中。第三个方法是抽象方法,需要子类自行实现,而第二个方法却又是基于它的。
还有一些方法也是类似的:
public long skip(long n):跳过 n 个字符
public boolean ready():下一个字符是否可读
public boolean markSupported():见 reset 方法
public void mark(int readAheadLimit):见 reset 方法
public void reset():用于实现重复读操作
abstract public void close():关闭流
这些个方法其实都见名知意,并且和我们的 InputStream 大体上都差不多,都没有什么核心的实现,这里不再赘述,你大致知道它内部有些个什么东西即可。
Writer 是写的字符流,它用于将一个或多个字符写入到文件中,当然具体的 write 方法依然是一个抽象的方法,待子类来实现,所以我们这里亦不再赘述了。
适配器 InpustStramReader/OutputStreamWriter
适配器字符流继承自基类 Reader 或 Writer,它们算是字符流体系中非常重要的成员了。主要的作用就是,将一个字节流转换成一个字符流,我们先以读适配器为例。
首先就是它最核心的成员:
private final StreamDecoder sd;StreamDecoder 是一个解码器,用于将字节的各种操作转换成字符的相应操作,关于它我们会在后续的介绍中不间断的提到它,这里不做统一的解释。
然后就是构造器:
public InputStreamReader(InputStream in) {
super(in);
try {
sd = StreamDecoder.forInputStreamReader(in, this, (String)null);
} catch (UnsupportedEncodingException e) {
throw new Error(e);
}
}
public InputStreamReader(InputStream in, String charsetName)
throws UnsupportedEncodingException
{
super(in);
if (charsetName == null)
throw new NullPointerException("charsetName");
sd = StreamDecoder.forInputStreamReader(in, this, charsetName);
}这两个构造器的目的都是为了初始化这个解码器,都调用的方法 forInputStreamReader,只是参数不同而已。我们不妨看看这个方法的实现:
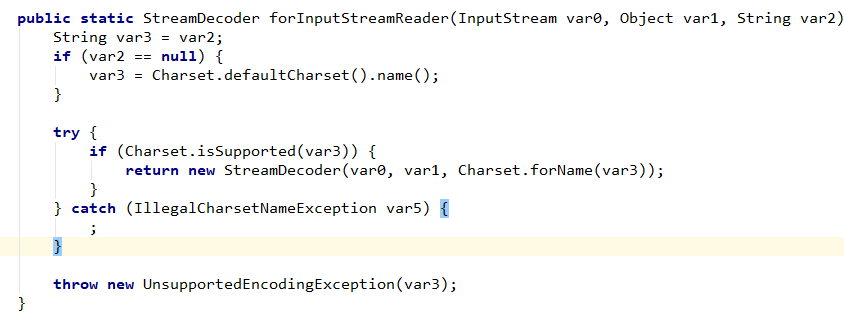
这是一个典型的静态工厂模式,三个参数,var0 和 var1 没什么好说的,分别代表的是字节流实例和适配器实例。
而参数 var2 其实代表的是一种字符编码的名称,如果为 null,那么将使用系统默认的字符编码:UTF-8 。
最终我们能够得到一个解码器实例。
接着介绍的所有方法几乎都是依赖的这个解码器而实现的。
public String getEncoding() {
return sd.getEncoding();
}
public int read() throws IOException {
return sd.read();
}
public int read(char cbuf[], int offset, int length){
return sd.read(cbuf, offset, length);
}
public void close() throws IOException {
sd.close();
}解码器中相关的方法的实现代码还是相对复杂的,这里我们不做深入的研究,但大体上的实现思路就是:「字节流读取 + 解码」的过程。
当然了,OutputStreamWriter 中必然也存在一个相反的 StreamEncoder 实例用于编码字符。
除了这一点外,其余的操作并没有什么不同,或是通过字符数组向文件中写入,或是通过字符串向文件中写入,又或是通过 int 的低 16 位向文件中写入。
文件字符流 FileReader/Writer
文件的字符流可以说非常简单了,除了构造器,就不存在任何其他方法了,完全依赖文件字节流。
我们以 FileReader 为例,
FileReader 继承自 InputStreamReader,有且仅有以下三个构造器:
public FileReader(String fileName) throws FileNotFoundException {
super(new FileInputStream(fileName));
}
public FileReader(File file) throws FileNotFoundException {
super(new FileInputStream(file));
}
public FileReader(FileDescriptor fd) {
super(new FileInputStream(fd));
}理论上来说,所有的字符流都应当以我们的适配器为基类,因为只有它提供了字符到字节之间的转换,无论你是写或是读都离不开它。
而我们的 FileReader 并没有扩展任何一个自己的方法,父类 InputStreamReader 中预实现的字符操作方法对他来说已经足够,只需要传入一个对应的字节流实例即可。
FileWriter 也是一样的,这里不再赘述了。
字符数组流 CharArrayReader/Writer
字符数组和字节数组流是类似的,都是用于解决那种不确定文件大小,而需要读取其中大量内容的情况。
由于它们内部提供动态扩容机制,所以既可以完全容纳目标文件,也可以控制数组大小,不至于分配过大内存而浪费了大量内存空间。
先以 CharArrayReader 为例
protected char buf[];
public CharArrayReader(char buf[]) {
this.buf = buf;
this.pos = 0;
this.count = buf.length;
}
public CharArrayReader(char buf[], int offset, int length){
//....
}构造器核心任务就是初始化一个字符数组到内部的 buf 属性中,以后所有对该字符数组流实例的读操作都基于 buf 这个字符数组。
关于 CharArrayReader 的其他方法以及 CharArrayWriter,这里不再赘述了,和上篇的字节数组流基本类似。
除此之外,这里还涉及一个 StringReader 和 StringWriter,其实本质上和字符数组流是一样的,毕竟 String 的本质就是 char 数组。
缓冲数组流 BufferedReader/Writer
同样的,BufferedReader/Writer 作为一种缓冲流,也是装饰者流,用于提供缓冲功能。大体上类似于我们的字节缓冲流,这里我们简单介绍下。
private Reader in;
private char cb[];
private static int defaultCharBufferSize = 8192;
public BufferedReader(Reader in, int sz){..}
public BufferedReader(Reader in) {
this(in, defaultCharBufferSize);
}cb 是一个字符数组,用于缓存从文件流中读取出来的部分字符,你可以在构造器中初始化这个数组的长度,否则将使用默认值 8192 。
public int read() throws IOException {..}
public int read(char cbuf[], int off, int len){...}关于 read,它依赖成员属性 in 的读方法,而 in 作为一个 Reader 类型,内部往往又依赖的某个 InputStream 实例的读方法。
所以说,几乎所有的字符流都离不开某个字节流实例。
关于 BufferedWriter,这里也不再赘述了,大体上都是类似的,只不过一个是读一个是写而已,都围绕着内部的字符数组进行。
标准打印输出流
打印输出流主要有两种,PrintStream 和 PrintWriter,前者是字节流,后者是字符流。
这两个流算是对各自类别下的流做了一个集成,内部封装有丰富的方法,但实现也稍显复杂,我们先来看这个 PrintStream 字节流:
主要的构造器有这么几个:
public PrintStream(OutputStream out)
public PrintStream(OutputStream out, boolean autoFlush)
public PrintStream(OutputStream out, boolean autoFlush, String encoding)
public PrintStream(String fileName)
显然,简单的构造器会依赖复杂的构造器,这已经算是 jdk 设计「老套路」了。区别于其他字节流的一点是,PrintStream 提供了一个标志 autoFlush,用于指定是否自动刷新缓存。
接着就是 PrintStream 的写方法:
public void write(int b)
public void write(byte buf[], int off, int len)
除此之外,PrintStream 还封装了大量的 print 的方法,写入不同类型的内容到文件中,例如:
public void print(boolean b)
public void print(char c)
public void print(int i)
public void print(long l)
public void print(float f)
等等
当然,这些方法并不会真正的将数值的二进制写入文件,而只是将它们所对应的字符串写入文件,例如:
print(123);最终写入文件的不是 123 所对应的二进制表述,而仅仅是 123 这个字符串,这就是打印流。
PrintStream 使用的缓冲字符流实现所有的打印操作,如果指明了自动刷新,则遇到换行符号「\n」会自动刷新缓冲区。
所以说,PrintStream 集成了字节流和字符流中所有的输出方法,其中 write 方法是用于字节流操作,print 方法用于字符流操作,这一点需要明确。
至于 PrintWriter,它就是全字符流,完全针对字符进行操作,无论是 write 方法也好,print 方法也好,都是字符流操作。
总结一下,我们花了三篇文章讲解了 Java 中的字节流和字符流操作,字节流基于字节完成磁盘和内存之间的数据传输,最典型的就是文件字符流,它的实现都是本地方法。有了基本的字节传输能力后,我们还能够通过缓冲来提高效率。
而字符流的最基本实现就是,InputStreamReader 和 OutputStreamWriter,理论上它俩就已经能够完成基本的字符流操作了,但也仅仅局限于最基本的操作,而构造它们的实例所必需的就是「一个字节流实例」+「一种编码格式」。
所以,字符流和字节流的关系也就如上述的等式一样,你写一个字符到磁盘文件中所必需的步骤就是,按照指定编码格式编码该字符,然后使用字节流将编码后的字符二进制写入文件中,读操作是相反的。
上述就是小编为大家分享的Java中怎么读写字符流文件了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



