多模字符串匹配算法在这里指的是在一个字符串中寻找多个模式字符字串的问题。一般来说,给出一个长字符串和很多短模式字符串,如何最快最省的求出哪些模式字符串出现在长字符串中是我们所要思考的。该算法广泛应用于关键字过滤、入侵检测、病毒检测、分词等等问题中。多模问题一般有Trie树,AC算法,WM算法等等。
背景
在做实际工作中,最简单也最常用的一种自然语言处理方法就是关键词匹配,例如我们要对n条文本进行过滤,那本身是一个过滤词表的,通常进行过滤的代码如下
for (String document : documents) {
for (String filterWord : filterWords) {
if (document.contains(filterWord)) {
//process ...
}
}
}如果文本的数量是n,过滤词的数量是k,那么复杂度为O(nk);如果关键词的数量较多,那么支行效率是非常低的。
计算机科学中,Aho–Corasick算法是由AlfredV.Aho和MargaretJ.Corasick发明的字符串搜索算法,用于在输入的一串字符串中匹配有限组“字典”中的子串。它与普通字符串匹配的不同点在于同时与所有字典串进行匹配。算法均摊情况下具有近似于线性的时间复杂度,约为字符串的长度加所有匹配的数量。然而由于需要找到所有匹配数,如果每个子串互相匹配(如字典为a,aa,aaa,aaaa,输入的字符串为aaaa),算法的时间复杂度会近似于匹配的二次函数。
原理
在一般的情况下,针对一个文本进行关键词匹配,在匹配的过程中要与每个关键词一一进行计算。也就是说,每与一个关键词进行匹配,都要重新从文档的开始到结束进行扫描。AC自动机的思想是,在开始时先通过词表,对以下三种情况进行缓存:
按照字符转移成功进行跳转(success表)
按照字符转移失败进行跳转(fail表)
匹配成功输出表(output表)
因此在匹配的过程中,无需从新从文档的开始进行匹配,而是通过缓存直接进行跳转,从而实现近似于线性的时间复杂度。
构建
构建的过程分三个步骤,分别对success表,fail表,output表进行构建。其中output表在构建sucess和fail表进行都进行了补充。fail表是一对一的,output表是一对多的。
按照字符转移成功进行跳转(success表)
sucess表实际就是一棵trie树,构建的方式和trie树是一样的,这里就不赘述。
按照字符转移失败进行跳转(fail表)
设这个节点上的字母为C,沿着他父亲的失败指针走,直到走到一个节点,他的儿子中也有字母为C的节点。然后把当前节点的失败指针指向那个字母也为C的儿子。如果一直走到了root都没找到,那就把失败指针指向root。使用广度优先搜索BFS,层次遍历节点来处理,每一个节点的失败路径。
匹配成功输出表(output表)
匹配
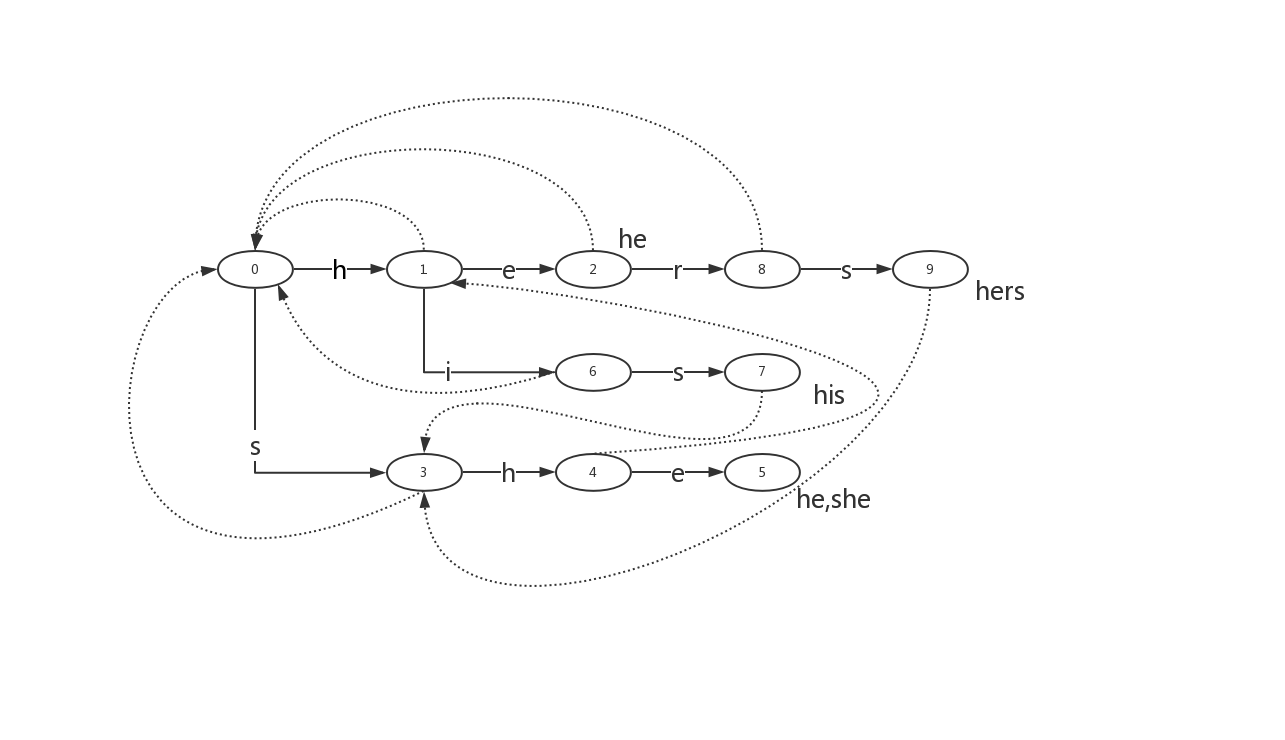
举例说明,按顺序先后添加关键词he,she,,his,hers。在匹配ushers过程中。先构建三个表,如下图,实线是sucess表,虚线是fail表,结点后的单词是ourput表。
代码
import java.util.*;
/**
*/
public class ACTrie {
private Boolean failureStatesConstructed = false;
//是否建立了failure表
private Node root;
//根结点
public ACTrie() {
this.root = new Node(true);
}
/**
* 添加一个模式串
* @param keyword
*/
public void addKeyword(String keyword) {
if (keyword == null || keyword.length() == 0) {
return;
}
Node currentState = this.root;
for (Character character : keyword.toCharArray()) {
currentState = currentState.insert(character);
}
currentState.addEmit(keyword);
}
/**
* 模式匹配
*
* @param text 待匹配的文本
* @return 匹配到的模式串
*/
public Collection<Emit> parseText(String text) {
checkForConstructedFailureStates();
Node currentState = this.root;
List<Emit> collectedEmits = new ArrayList<>();
for (int position = 0; position < text.length(); position++) {
Character character = text.charAt(position);
currentState = currentState.nextState(character);
Collection<String> emits = currentState.emit();
if (emits == null || emits.isEmpty()) {
continue;
}
for (String emit : emits) {
collectedEmits.add(new Emit(position - emit.length() + 1, position, emit));
}
}
return collectedEmits;
}
/**
* 检查是否建立了failure表
*/
private void checkForConstructedFailureStates() {
if (!this.failureStatesConstructed) {
constructFailureStates();
}
}
/**
* 建立failure表
*/
private void constructFailureStates() {
Queue<Node> queue = new LinkedList<>();
// 第一步,将深度为1的节点的failure设为根节点
//特殊处理:第二层要特殊处理,将这层中的节点的失败路径直接指向父节点(也就是根节点)。
for (Node depthOneState : this.root.children()) {
depthOneState.setFailure(this.root);
queue.add(depthOneState);
}
this.failureStatesConstructed = true;
// 第二步,为深度 > 1 的节点建立failure表,这是一个bfs 广度优先遍历
/**
* 构造失败指针的过程概括起来就一句话:设这个节点上的字母为C,沿着他父亲的失败指针走,直到走到一个节点,他的儿子中也有字母为C的节点。
* 然后把当前节点的失败指针指向那个字母也为C的儿子。如果一直走到了root都没找到,那就把失败指针指向root。
* 使用广度优先搜索BFS,层次遍历节点来处理,每一个节点的失败路径。
*/
while (!queue.isEmpty()) {
Node parentNode = queue.poll();
for (Character transition : parentNode.getTransitions()) {
Node childNode = parentNode.find(transition);
queue.add(childNode);
Node failNode = parentNode.getFailure().nextState(transition);
childNode.setFailure(failNode);
childNode.addEmit(failNode.emit());
}
}
}
private static class Node{
private Map<Character, Node> map;
private List<String> emits;
//输出
private Node failure;
//失败中转
private Boolean isRoot = false;
//是否为根结点
public Node(){
map = new HashMap<>();
emits = new ArrayList<>();
}
public Node(Boolean isRoot) {
this();
this.isRoot = isRoot;
}
public Node insert(Character character) {
Node node = this.map.get(character);
if (node == null) {
node = new Node();
map.put(character, node);
}
return node;
}
public void addEmit(String keyword) {
emits.add(keyword);
}
public void addEmit(Collection<String> keywords) {
emits.addAll(keywords);
}
/**
* success跳转
* @param character
* @return
*/
public Node find(Character character) {
return map.get(character);
}
/**
* 跳转到下一个状态
* @param transition 接受字符
* @return 跳转结果
*/
private Node nextState(Character transition) {
Node state = this.find(transition);
// 先按success跳转
if (state != null) {
return state;
}
//如果跳转到根结点还是失败,则返回根结点
if (this.isRoot) {
return this;
}
// 跳转失败的话,按failure跳转
return this.failure.nextState(transition);
}
public Collection<Node> children() {
return this.map.values();
}
public void setFailure(Node node) {
failure = node;
}
public Node getFailure() {
return failure;
}
public Set<Character> getTransitions() {
return map.keySet();
}
public Collection<String> emit() {
return this.emits == null ? Collections.<String>emptyList() : this.emits;
}
}
private static class Emit{
private final String keyword;
//匹配到的模式串
private final int start;
private final int end;
/**
* 构造一个模式串匹配结果
* @param start 起点
* @param end 重点
* @param keyword 模式串
*/
public Emit(final int start, final int end, final String keyword) {
this.start = start;
this.end = end;
this.keyword = keyword;
}
/**
* 获取对应的模式串
* @return 模式串
*/
public String getKeyword() {
return this.keyword;
}
@Override
public String toString() {
return super.toString() + "=" + this.keyword;
}
}
public static void main(String[] args) {
ACTrie trie = new ACTrie();
trie.addKeyword("hers");
trie.addKeyword("his");
trie.addKeyword("she");
trie.addKeyword("he");
Collection<Emit> emits = trie.parseText("ushers");
for (Emit emit : emits) {
System.out.println(emit.start + " " + emit.end + "\t" + emit.getKeyword());
}
}
}总结
以上就是本文关于多模字符串匹配算法原理及Java实现代码的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站:
Java 蒙特卡洛算法求圆周率近似值实例详解
java算法实现红黑树完整代码示例
java实现的各种排序算法代码示例
如有不足之处,欢迎留言指出。感谢朋友们对本站的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



