这篇文章主要介绍java中文分词之正向最大匹配法的示例分析,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
前言
基于词典的正向最大匹配算法(最长词优先匹配),算法会根据词典文件自动调整最大长度,分词的好坏完全取决于词典。
所谓词典正向最大匹配就是将一段字符串进行分隔,其中分隔 的长度有限制,然后将分隔的子字符串与字典中的词进行匹配,如果匹配成功则进行下一轮匹配,直到所有字符串处理完毕,否则将子字符串从末尾去除一个字,再进行匹配,如此反复。
算法流程图如下:
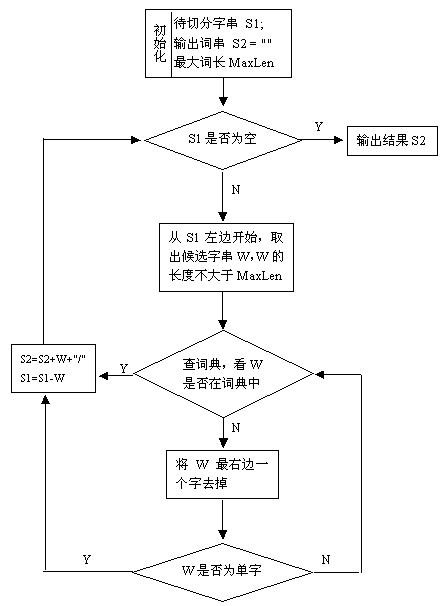
下面给大家主要讲一下中文分词里面算法的简单实现,废话不多说了,现在先上代码
示例代码
package com;
import java.util.ArrayList;
import java.util.List;
public class Segmentation1 {
private List<String> dictionary = new ArrayList<String>();
private String request = "北京大学生前来应聘";
public void setDictionary() {
dictionary.add("北京");
dictionary.add("北京大学");
dictionary.add("大学");
dictionary.add("大学生");
dictionary.add("生前");
dictionary.add("前来");
dictionary.add("应聘");
}
public String leftMax() {
String response = "";
String s = "";
for(int i=0; i<request.length(); i++) {
s += request.charAt(i);
if(isIn(s, dictionary) && aheadCount(s, dictionary)==1) {
response += (s + "/");
s = "";
} else if(aheadCount(s, dictionary) > 0) {
} else {
response += (s + "/");
s = "";
}
}
return response;
}
private boolean isIn(String s, List<String> list) {
for(int i=0; i<list.size(); i++) {
if(s.equals(list.get(i))) return true;
}
return false;
}
private int aheadCount(String s, List<String> list) {
int count = 0;
for(int i=0; i<list.size(); i++) {
if((s.length()<=list.get(i).length()) && (s.equals(list.get(i).substring(0, s.length())))) count ++;
}
return count;
}
public static void main(String[] args) {
Segmentation1 seg = new Segmentation1();
seg.setDictionary();
String response1 = seg.leftMax();
System.out.println(response1);
}
}可以看到运行结果是:北京大学/生前/来/应聘/
算法的核心就是从前往后搜索,然后找到最长的字典分词。
以上是“java中文分词之正向最大匹配法的示例分析”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



