一、环境准备
1.安装java环境:
yum install java-1.8.0-openjdk* -y
2.添加elk执行用户:
groupadd -g 77 elk useradd -u 77 -g elk -d /home/elk -s /bin/bash elk
3.在 /etc/security/limits.conf 追加以下内容:
elk soft memlock unlimited
elk hard memlock unlimited
* soft nofile 65536
* hard nofile 1310724.执行生效
sysctl -p5.配置主机名
hostnamectl set-hostname monitor-elk
echo "10.135.3.135 monitor-elk" >> /etc/hosts二、服务部署
1.服务端:
1)下载ELK相关的源码包:
wget "https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.2.2.tar.gz"
wget "https://artifacts.elastic.co/downloads/logstash/logstash-5.2.2.tar.gz"
wget "https://artifacts.elastic.co/downloads/kibana/kibana-5.2.2-linux-x86_64.tar.gz"
wget "http://mirror.bit.edu.cn/apache/kafka/0.10.2.0/kafka_2.12-0.10.2.0.tgz"
wget "http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz"2)创建elk目录,并将以上源码包解压至该目录:
mkdir /usr/local/elk
mkdir -p /data/elasticsearch/
chown -R elk.elk /data/elasticsearch/
mkdir -p /data/{kafka,zookeeper}
mv logstash-5.2.2 logstash && mv kibana-5.2.2-linux-x86_64 kibana && mv elasticsearch-5.2.2 elasticsearch && mv filebeat-5.2.2-linux-x86_64 filebeat && mv kafka_2.12-0.10.2.0 kafka && mv zookeeper-3.4.9 zookeeper
chown -R elk.elk /usr/local/elk/程序目录列表如下:
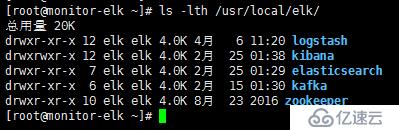
3)修改以下程序的相应配置文件
①kibana:
[root@monitor-elk ~]# cat /usr/local/elk/kibana/config/kibana.yml |grep -v "^#\|^$"
server.host: "localhost"
elasticsearch.url: "http://localhost:9200"
elasticsearch.requestTimeout: 30000
logging.dest: /data/elk/logs/kibana.log
[root@monitor-elk ~]#②elasticsearch:
[root@monitor-elk ~]# cat /usr/local/elk/elasticsearch/config/elasticsearch.yml |grep -v "^#\|^$"
node.name: node01
path.data: /data/elasticsearch/data
path.logs: /data/elk/logs/elasticsearch
bootstrap.memory_lock: true
network.host: 127.0.0.1
http.port: 9200
[root@monitor-elk ~]# /usr/local/elk/elasticsearch/config/jvm.options
#修改以下参数
-Xms1g
-Xmx1g③logstash:
[root@monitor-elk ~]# cat /usr/local/elk/logstash/config/logs.ymlinput {
#使用kafka的数据作为日志数据源
kafka
{
bootstrap_servers => ["127.0.0.1:9092"]
topics => "beats"
codec => json
}
}
filter {
#过滤数据,如果日志数据里面包含有该IP地址,将会被丢弃
if [message] =~ "123.151.4.10" {
drop{}
}
# 转码,转成正常的url编码,如中文
# urldecode {
# all_fields => true
# }
# nginx access
#通过type来判断传入的日志类型
if [type] == "hongbao-nginx-access" or [type] == "pano-nginx-access" or [type] == "logstash-nginx-access" {
grok {
#指定自定义的grok表达式路径
patterns_dir => "./patterns"
#指定自定义的正则表达式名称解析日志内容,拆分成各个字段
match => { "message" => "%{NGINXACCESS}" }
#解析完毕后,移除默认的message字段
remove_field => ["message"]
}
#使用geoip库解析IP地址
geoip {
#指定解析后的字段作为数据源
source => "clientip"
fields => ["country_name", "ip", "region_name"]
}
date {
#匹配日志内容里面的时间,如 05/Jun/2017:03:54:01 +0800
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
#将匹配到的时间赋值给@timestamp字段
target => "@timestamp"
remove_field => ["timestamp"]
}
}
# tomcat access
if [type] == "hongbao-tomcat-access" or [type] == "ljq-tomcat-access" {
grok {
patterns_dir => "./patterns"
match => { "message" => "%{TOMCATACCESS}" }
remove_field => ["message"]
}
geoip {
source => "clientip"
fields => ["country_name", "ip", "region_name"]
}
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
remove_field => ["timestamp"]
}
}
# tomcat catalina
if [type] == "hongbao-tomcat-catalina" {
grok {
match => {
"message" => "^(?<log_time>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2},\d{3}) (?<level>\w*) (?<log_data>.+)"
}
remove_field => ["message"]
}
date {
match => ["log_time","yyyy-MM-dd HH:mm:ss,SSS"]
target => "@timestamp"
remove_field => ["log_time"]
}
}
}
output {
#将解析失败的记录写入到指定的文件中
if "_grokparsefailure" in [tags] {
file {
path => "/data/elk/logs/grokparsefailure-%{[type]}-%{+YYYY.MM}.log"
}
}
# nginx access
#根据type日志类型分别输出到elasticsearch不同的索引
if [type] == "hongbao-nginx-access" {
#将处理后的结果输出到elasticsearch
elasticsearch {
hosts => ["127.0.0.1:9200"]
#指定输出到当天的索引
index => "hongbao-nginx-access-%{+YYYY.MM.dd}"
}
}
if [type] == "pano-nginx-access" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "pano-nginx-access-%{+YYYY.MM.dd}"
}
}
if [type] == "logstash-nginx-access" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "logstash-nginx-access-%{+YYYY.MM.dd}"
}
}
# tomcat access
if [type] == "hongbao-tomcat-access" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "hongbao-tomcat-access-%{+YYYY.MM.dd}"
}
}
if [type] == "ljq-tomcat-access" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "ljq-tomcat-access-%{+YYYY.MM.dd}"
}
}
# tomcat catalina
if [type] == "hongbao-tomcat-catalina" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "hongbao-tomcat-catalina-%{+YYYY.MM.dd}"
}
}
}[root@monitor-elk ~]#
配置正则表达式
[root@monitor-elk ~]# cp /usr/local/elk/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.0.2/patterns/grok-patterns /usr/local/elk/logstash/config/patterns
[root@monitor-elk ~]# tail -5 /usr/local/elk/logstash/config/patterns
# Nginx
NGINXACCESS %{COMBINEDAPACHELOG} %{QS:x_forwarded_for}
# Tomcat
TOMCATACCESS %{COMMONAPACHELOG}
[root@monitor-elk ~]# chown elk.elk /usr/local/elk/logstash/config/patterns4)配置zookeeper:
cp /usr/local/elk/zookeeper/conf/zoo_sample.cfg /usr/local/elk/zookeeper/conf/zoo.cfg修改配置文件中的数据存储路径
vim /usr/local/elk/zookeeper/conf/zoo.cfg
dataDir=/data/zookeeper备份并修改脚本 /usr/local/elk/zookeeper/bin/zkEnv.sh
修改以下变量的参数
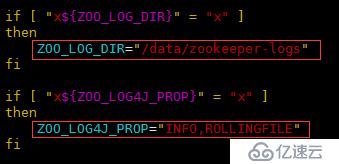
ZOO_LOG_DIR="/data/zookeeper-logs"
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"备份并修改日志配置 /usr/local/elk/zookeeper/conf/log4j.properties
修改以下变量的参数
zookeeper.root.logger=INFO, ROLLINGFILE
log4j.appender.ROLLINGFILE=org.apache.log4j.DailyRollingFileAppender# 每天轮转日志启动zookeeper:
/usr/local/elk/zookeeper/bin/zkServer.sh start5)配置kafka:
修改配置文件 /usr/local/elk/kafka/config/server.properties 的以下参数
log.dirs=/data/kafka
zookeeper.connect=localhost:2181备份并修改脚本 /usr/local/elk/kafka/bin/kafka-run-class.sh
在“base_dir=$(dirname $0)/.. ”的下一行追加LOG_DIR变量,并指定日志输出路径
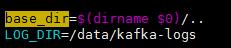
LOG_DIR=/data/kafka-logs创建日志存储目录:
mkdir -p /data/kafka-logs
mkdir -p /data/elk/logs
chown -R elk.elk /data/elk/logs启动kafka:
nohup /usr/local/elk/kafka/bin/kafka-server-start.sh /usr/local/elk/kafka/config/server.properties &>> /data/elk/logs/kafka.log &需要注意的是主机名一定要有配置在/etc/hosts文件中,否则kafka会无法启动
[root@monitor-elk ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.135.3.135 monitor-elk6)配置supervisor
①安装supervisor:
yum install supervisor -y
设置服务开机自启动(server程序也会一起启动):
systemctl enable supervisord.service②修改配置
a.创建日志存储路径:
mkdir -p /data/supervisor
chown -R elk.elk /data/supervisor/b.修改主配置文件 /etc/supervisord.conf
logfile=/data/supervisor/supervisord.logc.创建elk程序对应的supervisor配置文件,并添加以下配置内容:
[root@monitor-elk ~]# cat /etc/supervisord.d/elk.ini
[program:elasticsearch]
directory=/usr/local/elk/elasticsearch
command=su -c "/usr/local/elk/elasticsearch/bin/elasticsearch" elk
autostart=true
startsecs=5
autorestart=true
startretries=3
priority=10
[program:logstash]
directory=/usr/local/elk/logstash
command=/usr/local/elk/logstash/bin/logstash -f /usr/local/elk/logstash/config/logs.yml
user=elk
autostart=true
startsecs=5
autorestart=true
startretries=3
redirect_stderr=true
stdout_logfile=/data/elk/logs/logstash.log
stdout_logfile_maxbytes=1024MB
stdout_logfile_backups=10
priority=11
[program:kibana]
directory=/usr/local/elk/kibana
command=/usr/local/elk/kibana/bin/kibana
user=elk
autostart=true
startsecs=5
autorestart=true
startretries=3
priority=12
[root@monitor-elk ~]#③启动supervisor:
systemctl start supervisord查看程序进程和日志:
ps aux|grep -v grep|grep "elasticsearch\|logstash\|kibana"tip:
重启配置的单个程序,如:
supervisorctl restart logstash
重启配置的所有程序:
supervisorctl restart all重载配置(只重启配置变动的对应程序,其他配置未变动的程序不重启):
supervisorctl update7)配置nginx
①安装nginx
yum install nginx -y
②配置nginx代理:
[root@monitor-elk ~]# cat /etc/nginx/conf.d/kibana.conf
upstream kibana {
server 127.0.0.1:5601 max_fails=3 fail_timeout=30s;
}
server {
listen 8080;
server_name localhost;
location / {
proxy_pass http://kibana/;
index index.html index.htm;
#auth
auth_basic "kibana Private";
auth_basic_user_file /etc/nginx/.htpasswd;
}
}
[root@monitor-elk ~]# grep listen /etc/nginx/nginx.conf
listen 8000 default_server;
listen [::]:8000 default_server;
[root@monitor-elk ~]#③创建nginx认证:
[root@monitor-elk ~]# yum install httpd -y
[root@monitor-elk ~]# htpasswd -cm /etc/nginx/.htpasswd elk
New password:
Re-type new password:
Adding password for user elk
[root@monitor-elk ~]# systemctl start nginx
[root@monitor-elk ~]# systemctl enable nginx8)配置ik中文分词:
①安装maven:
wget "http://mirror.bit.edu.cn/apache/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz"
tar -zxf apache-maven-3.3.9-bin.tar.gz
mv apache-maven-3.3.9 /usr/local/maven
echo "export MAVEN_HOME=/usr/local/maven" >> /etc/bashrc
echo "export PATH=$PATH:$MAVEN_HOME/bin" >> /etc/bashrc
. /etc/bashrc②编译安装ik(注意下载对应版本):
wget "https://github.com/medcl/elasticsearch-analysis-ik/archive/v5.2.2.zip"
unzip v5.2.2.zip
cd elasticsearch-analysis-ik-5.2.2/
mvn package
mkdir /usr/local/elk/elasticsearch/plugins/ik
cp target/releases/elasticsearch-analysis-ik-5.2.2.zip /usr/local/elk/elasticsearch/plugins/ik/
cd /usr/local/elk/elasticsearch/plugins/ik/
unzip elasticsearch-analysis-ik-5.2.2.zip
rm -f elasticsearch-analysis-ik-5.2.2.zip
chown -R elk.elk ../ik
supervisorctl restart elasticsearch③创建索引模板:
要使用ik分词,需要在创建指定的索引前(不管是通过命令手动还是logstash配置来创建)先创建索引模板,否则使用默认的模板即可:
cd /usr/local/elk/logstash创建并编辑文件 logstash.json ,添加以下内容:
{
"order" : 1,
"template" : "tomcatcat-*",
"settings" : {
"index" : {
"refresh_interval" : "5s"
}
},
"mappings" : {
"_default_" : {
"dynamic_templates" : [
{
"string_fields" : {
"mapping" : {
"norms" : false,
"type" : "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"match_mapping_type" : "text",
"match" : "*"
}
}
],
"_all" : {
"norms" : false,
"enabled" : true
},
"properties" : {
"@timestamp" : {
"include_in_all" : false,
"type" : "date"
},
"log_data": {
"include_in_all" : true,
"type" : "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word",
"boost" : 8
},
"@version" : {
"include_in_all" : false,
"type" : "keyword"
}
}
}
},
"aliases" : { }
}'添加完毕后,执行curl命令创建索引模板
curl -XPUT 'http://localhost:9200/_template/tomcatcat' -d @logstash.json执行成功后会返回结果 {"acknowledged":true}
④热更新配置:
有些词语ik无法识别分词,如公司名称、服务名称之类
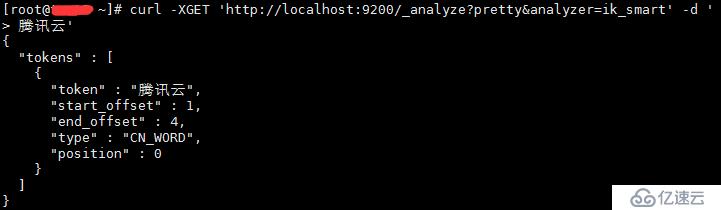
curl -XGET 'http://localhost:9200/_analyze?pretty&analyzer=ik_smart' -d '
腾讯云'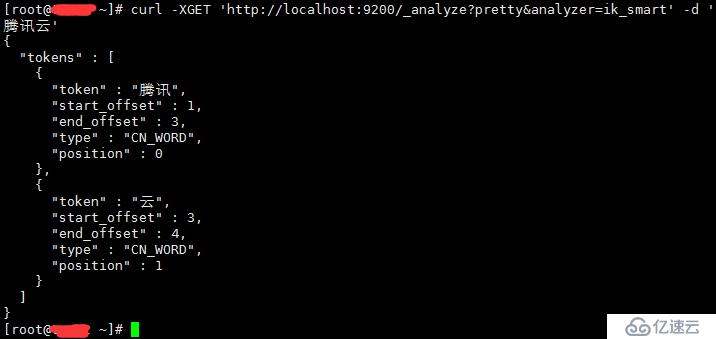
这时需要自己自定义词库,ik支持分词热更新的方式(不需要重启elasticsearch),每分钟自动检测一次
在nginx根路径下创建一个utf8格式的文本文件 ik.txt ,将自己需要分词的词语写入ik.txt,一行一词:
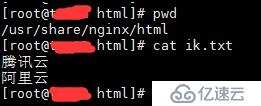
然后修改/usr/local/elk/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://127.0.0.1:8000/ik.txt</entry>配置完毕重启elasticsearch,再次获取分词结果:
2.客户端:
1)下载filebeat:
wget "https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.2.2-linux-x86_64.tar.gz"解压filebeat-5.2.2-linux-x86_64.tar.gz至/usr/local/elk/目录,并重命名为filebeat
mkdir /usr/local/elk/
mkdir -p /data/elk/logs/
echo "10.135.3.135 elk" >> /etc/hosts2)配置filebeat:
[root@test2 filebeat]# cat logs.yml
filebeat.prospectors:
-
#指定需要监控的日志文件路径,可以使用*匹配
paths:
- /data/nginx/log/*_access.log
#指定文件的输入类型为log(默认)
input_type: log
#设定日志类型
document_type: pano-nginx-access
#从文件的末尾开始监控文件新增的内容,并按行依次发送
tail_files: true
#将日志内容输出到kafka
output.kafka:
hosts: ["10.135.3.135:9092"]
topic: beats
compression: Snappy
[root@test2 filebeat]#
[root@test3 filebeat]# cat logs.yml
filebeat.prospectors:
-
paths:
- /usr/local/tomcat/logs/*access_log.*.txt
input_type: log
document_type: hongbao-tomcat-access
tail_files: true
-
paths:
- /usr/local/tomcat/logs/catalina.out
input_type: log
document_type: hongbao-tomcat-catalina
#多行匹配模式,后接正则表达式,这里表示匹配时间,如 2017-06-05 10:00:00,713
multiline.pattern: '^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2},\d{3}'
#将未匹配到的行合并到上一行,如java的错误日志
multiline.negate: true
#将未匹配到的行添加到上一行的末尾
multiline.match: after
tail_files: true
output.kafka:
hosts: ["10.135.3.135:9092"]
topic: beats
compression: Snappy
[root@test3 filebeat]#3)启动filebeat
nohup /usr/local/elk/filebeat/filebeat -e -c /usr/local/elk/filebeat/logs.yml -d "publish" &>> /data/elk/logs/filebeat.log &三、kibana web端配置
1.浏览器访问kibana地址,并输入前面nginx设置的账号密码:
http://10.135.3.135:8080
在访问 Kibana 时,默认情况下将加载 Discover(发现) 页面,并选择默认的索引模式(logstash-*)。 time filter(时间过滤器)默认设置为 last 15 minutes(最近 15 分钟),搜索查询默认设置为 match-all(*)。
服务器资源状态页:
http://10.135.3.135:8080/status
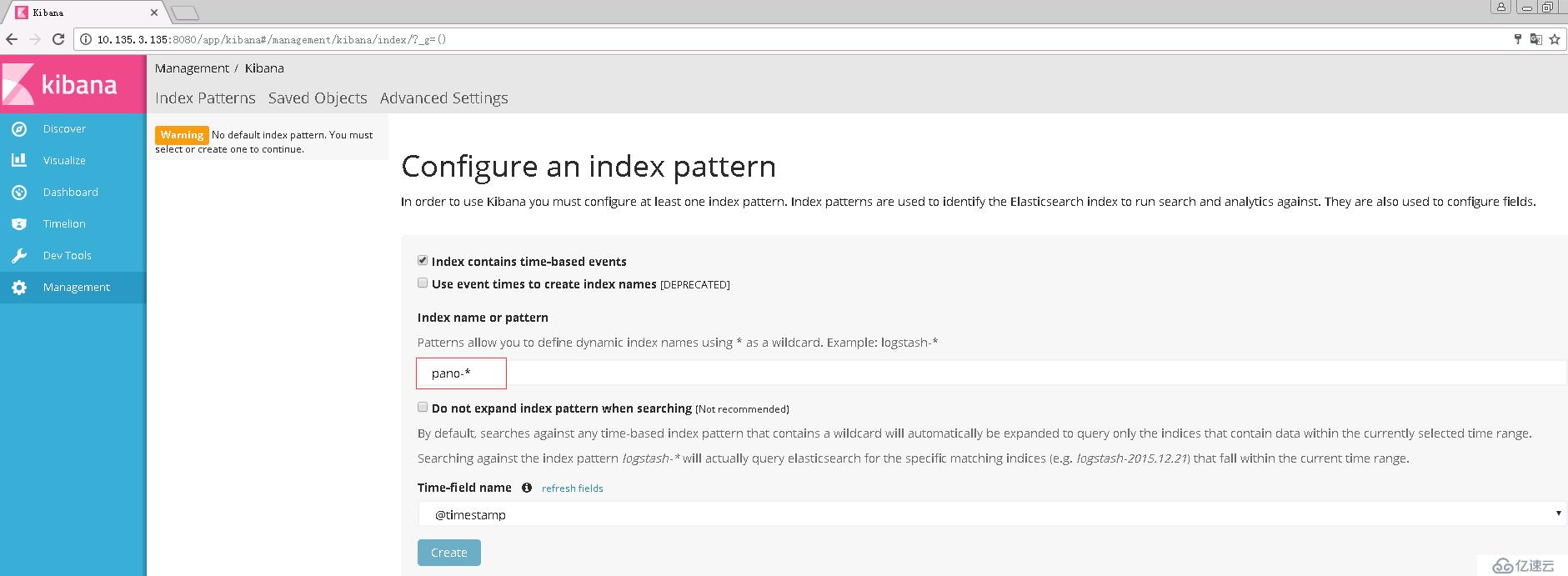
2.建立索引模式
注意,索引模式的名称要和logstash的output生成的索引(也就是说必须存在于Elasticsearch中,而且必须包含有数据)进行匹配,如logstash-*可与logstash-20170330匹配,还可以匹配多个索引(所有以logstash-开头的索引)。
*匹配索引名称中的零个或多个字符
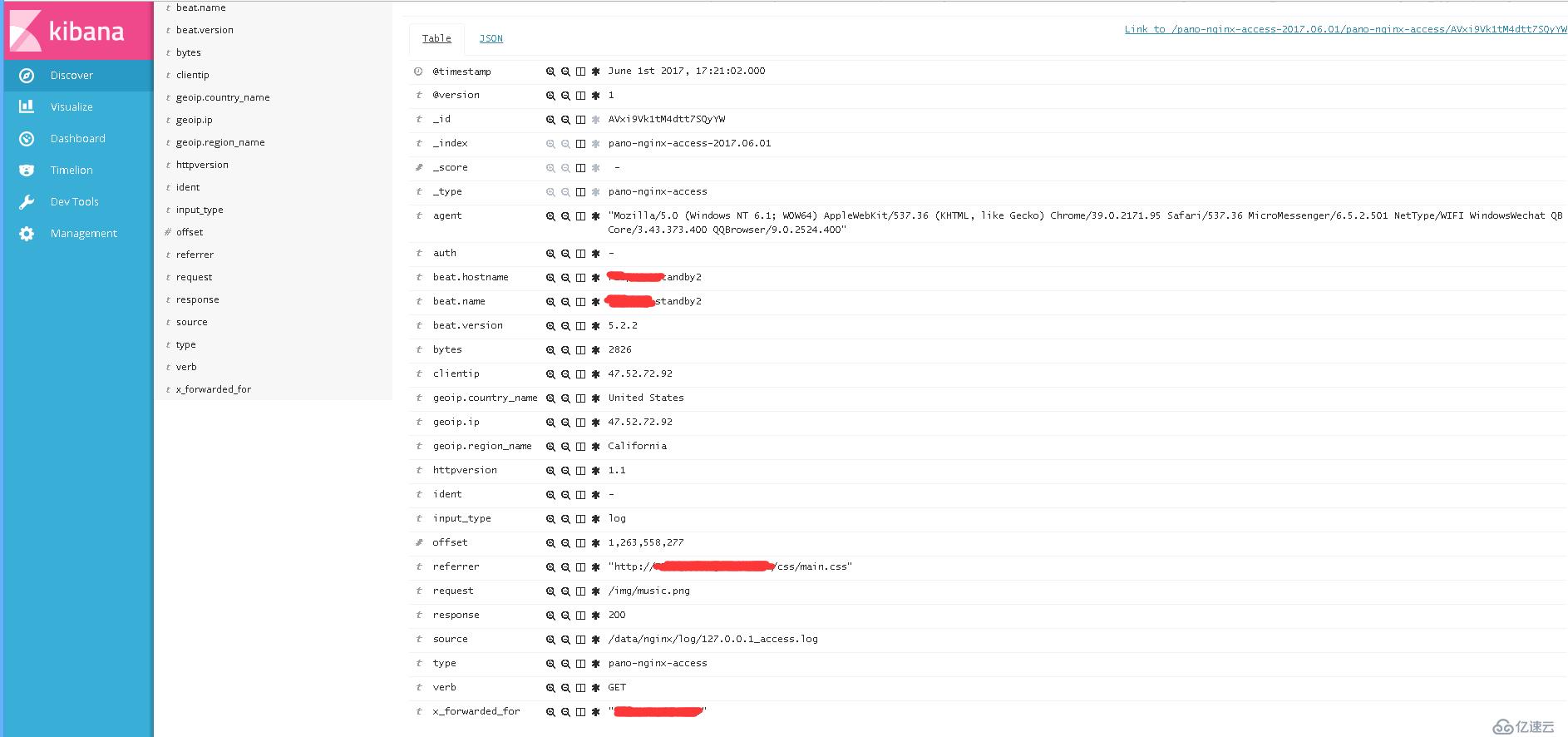
3.索引建立完毕后,点击Discover中的索引模式,即可看到Elasticsearch的日志数据
4.创建可视化图表
绘制可视化图表,将拆分出来的nginx或tomcat访问日志中的字段response状态码进行聚合显示,以图表的形式直观显示各状态码(如200、400等)的统计情况
1)点击 Visualize 中 Vertical Bar Charts(垂直条形图)
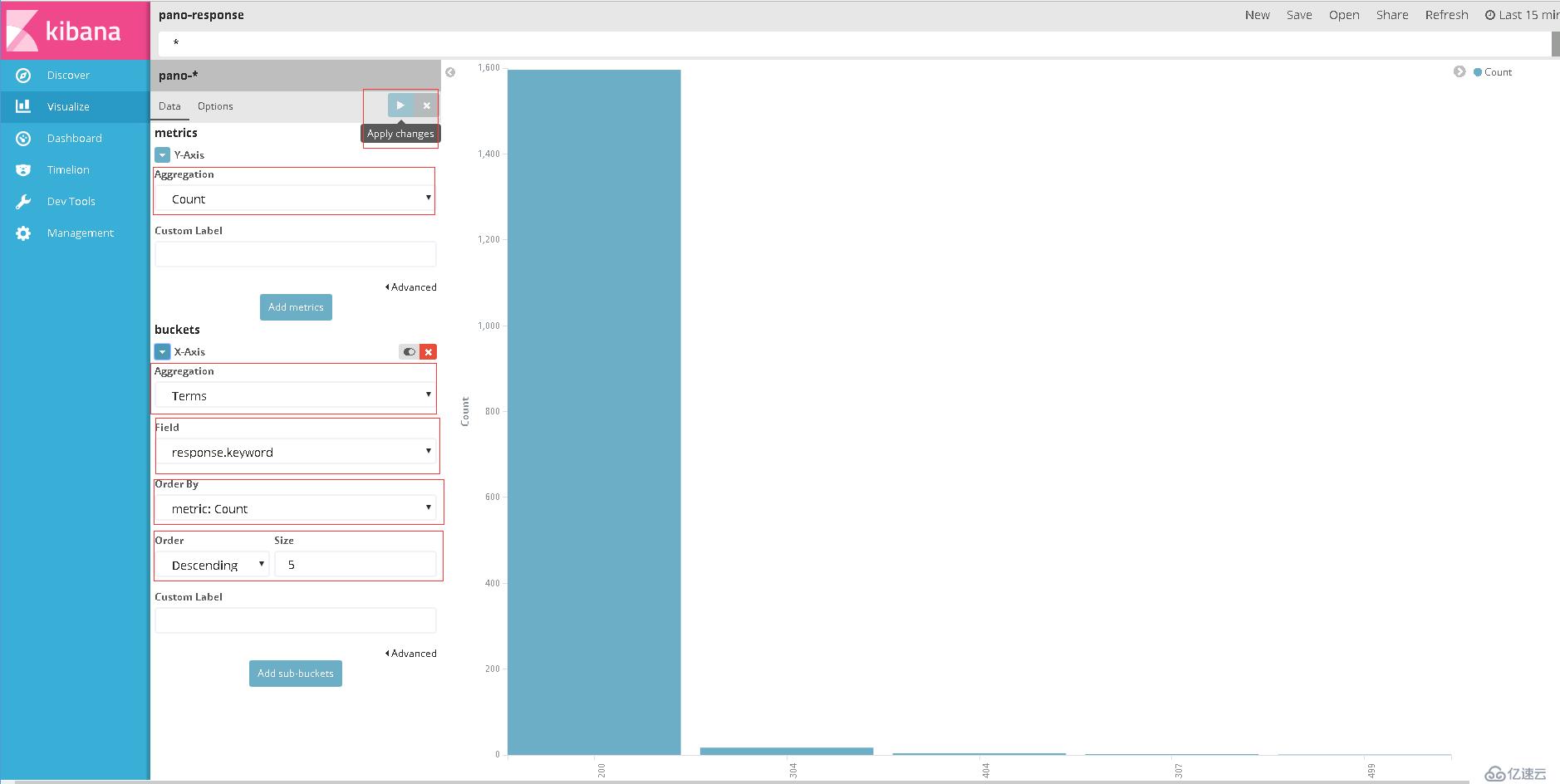
2)选择其中一个索引模式,如 pano-*

3)通过字段 response.keyword 指定 terms(词条)聚合,按从大到小的顺序来显示前五列状态码的总数数据,然后点击 Apply changes 图标 生效。
生效。
图表中,X轴显示的是状态码,Y轴显示的是对应的状态码总数。
4)最后点击右上角的 Save 保存,同时输入一个可视化的名称。
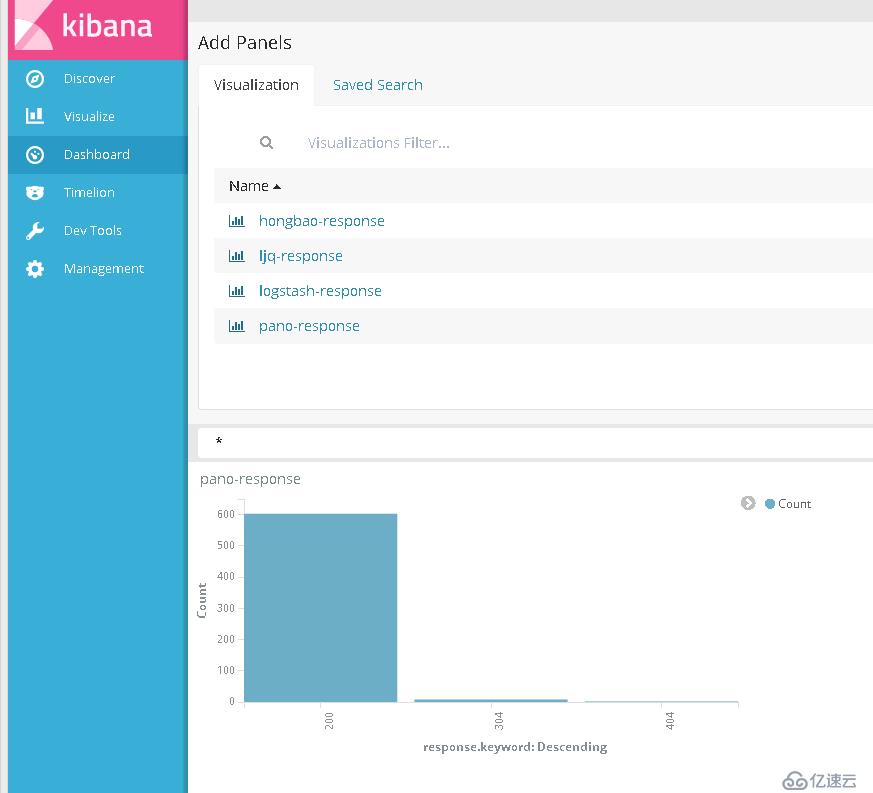
5.创建仪表盘
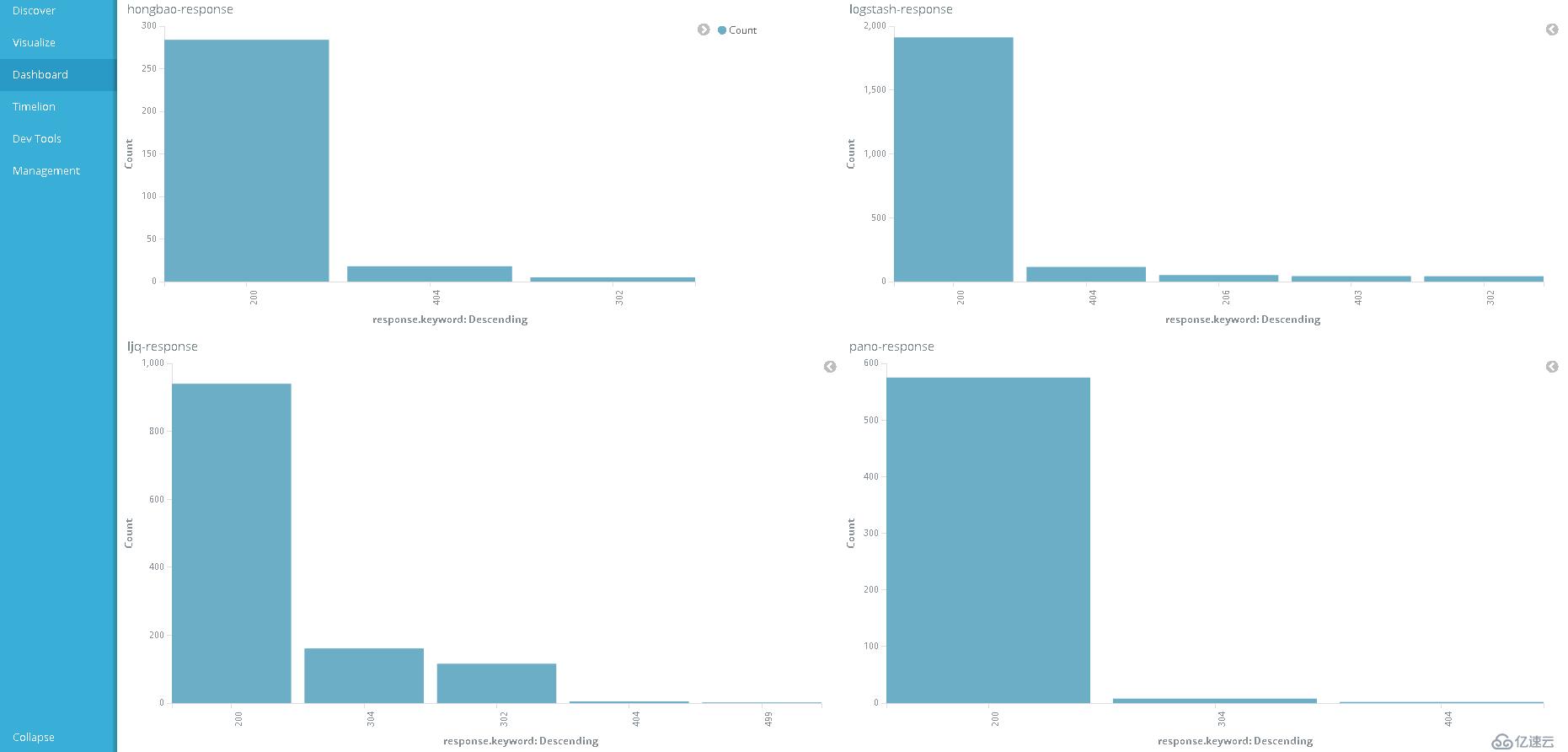
可以将相同业务或类型的可视化对象,集中显示在同一个仪表盘中。
1)点击 add 添加可视化对象到仪表盘,

2)点击创建好的可视化对象,将会排列在在仪表盘的窗口中。对其可视化对象的窗口大小进行合适的调整。
3)添加和调整完毕后,点击右上角的 Save 保存,同时输入一个仪表盘的名称。
4)显示的结果
四、服务监控脚本
1.服务端
1)kafka
[root@monitor-elk ~]# cat /usr/local/scripts/monitor_kafka.sh
#!/bin/bash
#
#############################################
# author:Ellen
# describes:Check kafka program
# version:v1.0
# updated:20170407
#############################################
#
# Configuration information
program_dir=/usr/local/elk/kafka
logfile=/usr/local/scripts/log/monitor_kafka.log
# Check executed user
if [ `whoami` != "root" ];then
echo "Please use root run script!!!"
exit 1
fi
# Check kafka program
num=`ps aux|grep -w $program_dir|grep -vw "grep\|vim\|vi\|mv\|scp\|cat\|dd\|tail\|head\|script\|ls\|echo\|sys_log\|logger\|tar\|rsync\|ssh"|wc -l`
if [ ${num} -eq 0 ];then
echo "[`date +'%F %T'`] [CRITICAL] Kafka program dost not start!!!"|tee -a $logfile
# Send alarm information
#cagent_tools是腾讯云服务器自带的报警插件,该插件可发送短信或邮箱告警,如不需要可注释
/usr/bin/cagent_tools alarm "Kafka program dost not start!!!"
echo "[`date +'%F %T'`] [ INFO ] Begin start kafka program..."|tee -a $logfile
nohup /usr/local/elk/kafka/bin/kafka-server-start.sh /usr/local/elk/kafka/config/server.properties &>> /data/elk/logs/kafka.log &
if [ $? -eq 0 ];then
echo "[`date +'%F %T'`] [ INFO ] Kafka program start successful."|tee -a $logfile
/usr/bin/cagent_tools alarm "Kafka program start successful"
exit 0
else
echo "[`date +'%F %T'`] [CRITICAL] Kafka program start failed!!!"|tee -a $logfile
/usr/bin/cagent_tools alarm "Kafka program start failed!!!Please handle it!!!"
exit 6
fi
else
echo "[`date +'%F %T'`] [ INFO ] Kafka program is running..."|tee -a $logfile
exit 0
fi
[root@monitor-elk ~]#2)zookeeper
[root@monitor-elk ~]# cat /usr/local/scripts/monitor_zookeeper.sh
#!/bin/bash
#
#############################################
# author:Ellen
# describes:Check zookeeper program
# version:v1.0
# updated:20170407
#############################################
#
# Configuration information
program_dir=/usr/local/elk/zookeeper
logfile=/usr/local/scripts/log/monitor_zookeeper.log
# Check executed user
if [ `whoami` != "root" ];then
echo "Please use root run script!!!"
exit 1
fi
# Check zookeeper program
num=`ps aux|grep -w $program_dir|grep -vw "grep\|vim\|vi\|mv\|scp\|cat\|dd\|tail\|head\|ls\|echo\|sys_log\|tar\|rsync\|ssh"|wc -l`
if [ ${num} -eq 0 ];then
echo "[`date +'%F %T'`] [CRITICAL] Zookeeper program dost not start!!!"|tee -a $logfile
# Send alarm information
/usr/bin/cagent_tools alarm "Zookeeper program dost not start!!!"
echo "[`date +'%F %T'`] [ INFO ] Begin start zookeeper program..."|tee -a $logfile
/usr/local/elk/zookeeper/bin/zkServer.sh start
if [ $? -eq 0 ];then
echo "[`date +'%F %T'`] [ INFO ] Zookeeper program start successful."|tee -a $logfile
/usr/bin/cagent_tools alarm "Zookeeper program start successful"
exit 0
else
echo "[`date +'%F %T'`] [CRITICAL] Zookeeper program start failed!!!"|tee -a $logfile
/usr/bin/cagent_tools alarm "Zookeeper program start failed!!!Please handle it!!!"
exit 6
fi
else
echo "[`date +'%F %T'`] [ INFO ] Zookeeper program is running..."|tee -a $logfile
exit 0
fi
[root@monitor-elk ~]#3)添加crontab定时任务
0-59/5 * * * * /usr/local/scripts/monitor_kafka.sh &> /dev/null
0-59/5 * * * * /usr/local/scripts/monitor_zookeeper.sh &> /dev/null2.客户端:
[root@test2 ~]# cat /usr/local/scripts/monitor_filebeat.sh
#!/bin/bash
#
#############################################
# author:Ellen
# describes:Check filebeat program
# version:v1.0
# updated:20170407
#############################################
#
# Configuration information
program_dir=/usr/local/elk/filebeat
logfile=/usr/local/scripts/log/monitor_filebeat.log
# Check executed user
if [ `whoami` != "root" ];then
echo "Please use root run script!!!"
exit 1
fi
# Check filebeat program
num=`ps aux|grep -w $program_dir|grep -vw "grep\|vim\|vi\|mv\|cp\|scp\|cat\|dd\|tail\|head\|script\|ls\|echo\|sys_log\|logger\|tar\|rsync\|ssh"|wc -l`
if [ ${num} -eq 0 ];then
echo "[`date +'%F %T'`] [CRITICAL] Filebeat program dost not start!!!"|tee -a $logfile
# Send alarm information
/usr/bin/cagent_tools alarm "Filebeat program dost not start!!!"
echo "[`date +'%F %T'`] [ INFO ] Begin start filebeat program..."|tee -a $logfile
nohup /usr/local/elk/filebeat/filebeat -e -c /usr/local/elk/filebeat/logs.yml -d "publish" &>> /data/elk/logs/filebeat.log &
if [ $? -eq 0 ];then
echo "[`date +'%F %T'`] [ INFO ] Filebeat program start successful."|tee -a $logfile
/usr/bin/cagent_tools alarm "Filebeat program start successful"
exit 0
else
echo "[`date +'%F %T'`] [CRITICAL] Filebeat program start failed!!!"|tee -a $logfile
/usr/bin/cagent_tools alarm "Filebeat program start failed!!!Please handle it!!!"
exit 6
fi
else
echo "[`date +'%F %T'`] [ INFO ] Filebeat program is running..."|tee -a $logfile
exit 0
fi
[root@test2 ~]#3)添加crontab定时任务
0-59/5 * * * * /usr/local/scripts/monitor_filebeat.sh &> /dev/null五、注意事项
1.数据流向
--------------------------------------------------------------------------------------------------
log_files -> filebeat -> kafka-> logstash -> elasticsearch -> kibana
--------------------------------------------------------------------------------------------------
2.每天定时清理elasticsearch索引,只保留30天内的索引
1)编写脚本
[root@monitor-elk ~]# cat /usr/local/scripts/del_index.sh
#!/bin/bash
#
#############################################
# author:Ellen
# describes:Delete elasticsearch history index.
# version:v1.0
# updated:20170407
#############################################
#
# Configuration information
logfile=/usr/local/scripts/log/del_index.log
tmpfile=/tmp/index.txt
host=localhost
port=9200
deldate=`date -d '-30days' +'%Y.%m.%d'`
# Check executed user
if [ `whoami` != "root" ];then
echo "Please use root run script!!!"
exit 1
fi
# Delete elasticsearch index
curl -s "$host:$port/_cat/indices?v"|grep -v health|awk {'print $3'}|grep "$deldate" > $tmpfile
if [ ! -s $tmpfile ];then
echo "[`date +'%F %T'`] [WARNING] $tmpfile is a empty file."|tee -a $logfile
exit 1
fi
for i in `cat /tmp/index.txt`
do
curl -XDELETE http://$host:$port/$i
if [ $? -eq 0 ];then
echo "[`date +'%F %T'`] [ INFO ] Elasticsearch index $i delete successful."|tee -a $logfile
else
echo "[`date +'%F %T'`] [CRITICAL] Elasticsearch index $i delete failed!!!"|tee -a $logfile
/usr/bin/cagent_tools alarm "Elasticsearch index $i delete failed!!!"
exit 6
fi
done
[root@monitor-elk ~]#2)添加crontab定时任务
00 02 * * * /usr/local/scripts/del_index.sh &> /dev/null3.按业务进行建立索引
如hongbao、pano等
4.nginx和tomcat等访问日志使用默认格式
六、相关命令参考
1.列出所有索引
curl -s 'http://localhost:9200/_cat/indices?v'
2.列出节点列表
curl 'localhost:9200/_cat/nodes?v'
3.查询集群健康信息
curl 'localhost:9200/_cat/health?v'
4.查看指定的索引数据(默认返回十条结果)
curl -XGET 'http://localhost:9200/logstash-nginx-access-2017.05.20/_search?pretty'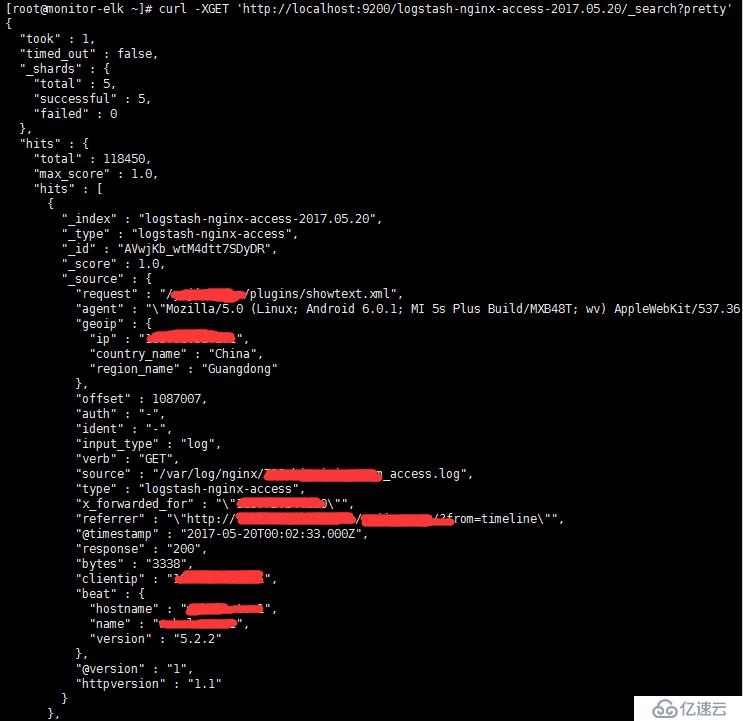
5.删除指定的索引
curl -XDELETE http://localhost:9200/logstash-nginx-access-2017.05.20
6.查询模板
curl -s 'http://localhost:9200/_template'亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



