这篇文章给大家介绍使用hbase的优点有哪些,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
hbase是运行在Hadoop上的NoSQL数据库,它是一个分布式的和可扩展的大数据仓库,也就是说HBase能够利用HDFS的分布式处理模式,并从Hadoop的MapReduce程序模型中获益。这意味着在一组商业硬件上存储许多具有数十亿行和上百万列的大表。除去Hadoop的优势,HBase本身就是十分强大的数据库,它能够融合key/value存储模式带来实时查询的能力,以及通过MapReduce进行离线处理或者批处理的能力。总的来说,Hbase能够让你在大量的数据中查询记录,也可以从中获得综合分析报告。
谷歌曾经面对过一个挑战的问题:如何能在整个互联网上提供实时的搜索结果?答案是它本质上需要将互联网缓存,并重新定义在这样庞大的缓存上快速查找的新方法。为了达到这个目的,定义如下技术:
·谷歌文件系统GFS:可扩展分布式文件系统,用于大型的、分布式的、数据密集型的应用程序。
·BigTable:分布式存储系统,用于管理被设计成规模很大的结构化数据:来自数以千计商用服务器的PB级别的数据。
·MapReduce:一个程序模型,用于处理和生成大数据集的相关实现。
在谷歌发布这些技术的文档之后,不久以后我们就看到了它们的开源实现版本,就在2007年,MikeCafarella发布了BigTable开源实现的代码,他称其为HBase,自此,HBase成为Apache的顶级项目,并运行在Facebook,Twitter,Adobe……仅举几个例子。
HBase不是一个关系型数据库,它需要不同的方法定义你的数据模型,HBase实际上定义了一个四维数据模型,下面就是每一维度的定义:
·行键:每行都有唯一的行键,行键没有数据类型,它内部被认为是一个字节数组。
·列簇:数据在行中被组织成列簇,每行有相同的列簇,但是在行之间,相同的列簇不需要有相同的列修饰符。在引擎中,HBase将列簇存储在它自己的数据文件中,所以,它们需要事先被定义,此外,改变列簇并不容易。
·列修饰符:列簇定义真实的列,被称之为列修饰符,你可以认为列修饰符就是列本身。
·版本:每列都可以有一个可配置的版本数量,你可以通过列修饰符的制定版本获取数据。
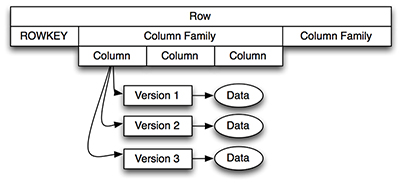
Figure1.HBaseFour-Dimensional Data Model
如图1中所示,通过行键获取一个指定的行,它由一个或多个列簇构成,每个列簇有一个或多个列修饰符(图1中称为列),每列又可以有一个或多个版本。为了获取指定数据,你需要知道它的行键、列簇、列修饰符以及版本。当设计HBase数据模型时,对考虑数据是如何被获取是十分有帮助的。你可以通过以下两种方式获得HBase数据:
·通过他们的行键,或者一系列行键的表扫描。
·使用map-reduce进行批操作
这种双重获取数据的方法使得HBase变得十分强大,典型地,在Hadoop中存储数据意味着它对离线或批处理方式分析是有益的(尤其是批处理分析),但是,对实时获取是不必要的。HBase通过key/value存储来支持实时分析,以及通过map-reduce支持批处理分析。让我们首先来看实时数据获取,作为key/value存储,key是行键,value是列簇的集合,如图2所示。
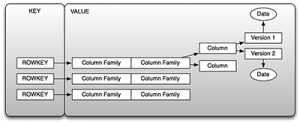
Figure2.HBaseas a Key/Value Store
如你在图2中看到的,key是我们所提到过的行键,value是列簇的集合。你可以通过key检索到value,或者换句话说,你可以通过行键“得到”行,或者你能通过给定起始和终止行键检索一系列行,这就是前面提到的表扫描。你不能实时的查询一个列的值,这就引出了一个重要的话题:行键的设计。
有两个原因令行键的设计十分重要:
·表扫描是对行键的操作,所以,行键的设计控制着你能够通过HBase执行的实时/直接获取量。
·当在生产环境中运行HBase时,它在HDFS上部运行,数据基于行键通过HDFS,如果你所有的行键都是以user-开头,那么很有可能你大部分数据都被分配一个节点上(违背了分布式数据的初衷),因此,你的行键应该是有足够的差异性以便分布式地通过整个部署。
你定义行键的方式取决于你想怎样存取那些行。如果你想以用户为基础存储数据,那么一个策略是利用字节队列在HBase中存储行键,所以我们可以创建一个用户ID的哈希(例如MD5或SHA-1),然后在哈希后面附上时间(long类型)。使用哈希有两个重点:(1)是它能够将value分散开,数据能够分布式地通过簇,(2)是它确保key的长度是一致的,以更加容易在表扫描中使用。
讲了足够多的理论,下面部分向你展示如何搭建HBase环境,并如何通过命令行使用。
你可以从Apache网站下载HBase,在写本文时,最新的版本是0.98.5,HBase团队推荐你在UNIX/Linux环境下安装HBase,如果你想在Windows下运行,你需要先安装Cygwin,并在这上运行HBase。当你下载完这些文件,解压到硬盘上。此外,你还需要安装Java环境,如果你还没有,从Oracle网站下载Java环境。在环境配置中添加名为HBASE_HOME的变量,值为你解压HBase文件的根目录,随后,执行bin文件夹下的start-hbase.sh脚本,它会在下面目录输出日志文件:
$HBASE_HOME/logs/
你可以在浏览器中输入下面URL测试是否安装正确:
http://localhost:60010
如果安装正确,你应该看到下面界面。
Figure3.HBaseManagement Screen
让我们开始用命令行操作HBase,在HBasebin目录下执行下面命令:
./hbase shell
你应该看到如下类似的输出:
HBase Shell; enter'help' for list of supported commands.
Type "exit" toleave the HBase Shell
Version0.98.5-hadoop2, rUnknown, MonAug4 23:58:06 PDT2014
hbase(main):001:0>创建一个名为PageViews的表,并具有名为info的列簇:
hbase(main):002:0> create'PageViews', 'info'
0 row(s) in 5.3160seconds
=> Hbase::Table- PageViews每张表至少要有一个列簇,因此我们创建了info,现在,看看我们的表,执行下面list命令:
hbase(main):002:0>list
TABLE
PageViews
1 row(s) in 0.0350seconds
=>["PageViews"]如你所见,list命令返回一个名为PageViews的表,我们可以通过describe命令得到表的更多信息:
hbase(main):003:0> describe'PageViews'
DESCRIPTIONENABLED
'PageViews',{NAME => 'info', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER=> 'ROW',
REPLICATION_SCOPE=> '0', VERSIONS => '1', COMPRESSION => 'NONEtrue
',MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS=> 'false',
BLOCKSIZE=> '65536', IN_MEMORY => 'false', BLOCKCACHE =>'true'}
1 row(s) in 0.0480secondsDescribe命令返回表的详细信息,包括列簇的列表,这里我们创建的仅有一个:info,现在为表添加以下数据,下面命令是在info中添加新的行:
hbase(main):004:0> put'PageViews', 'rowkey1', 'info:page', '/mypage'
0 row(s) in 0.0850secondsPut命令插入一条行键为rowkey1的新纪录,指定在info下的page列,插入值为/mypage的记录,我们随后可以通过get命令通过行键rowkey1查询到这条记录:
hbase(main):005:0> get'PageViews', 'rowkey1'
COLUMNCELL
info:pagetimestamp=1410374788088, value=/mypage
1 row(s) in 0.0250seconds你可以看到列info:page,或者更多具体的列,其值为/mypage,并带有时间戳表明该条记录是什么时候插入的。让我们在做表扫描之前再添加一行:
hbase(main):006:0> put'PageViews', 'rowkey2', 'info:page', '/myotherpage'
0 row(s) in 0.0050seconds现在我们有两行记录了,让我们查询出PageViews表的所有记录:
hbase(main):007:0> scan'PageViews'
ROWCOLUMN+CELL
rowkey1column=info:page, timestamp=1410374788088, value=/mypage
rowkey2column=info:page, timestamp=1410374823590,value=/myotherpage
2 row(s) in 0.0350seconds如前面所提到的,我们不能查询本身,但是我们可以对表进行scan操作,如果你执行scantable命令,它会返回表中所有行,这很有可能不是你想要做的。你可以给出行的范围来限制返回的结果,让我们插入一带有s开头行键的新记录:
hbase(main):012:0> put'PageViews', 'srowkey2', 'info:page', '/myotherpage'现在,如果我增加点限制,想查询行键在r和s之间的记录,可以使用如下结构:
hbase(main):014:0> scan'PageViews', { STARTROW => 'r', ENDROW => 's' }
ROWCOLUMN+CELL
rowkey1column=info:page, timestamp=1410374788088, value=/mypage
rowkey2column=info:page, timestamp=1410374823590,value=/myotherpage
2 row(s) in 0.0080seconds这个scan返回了仅有s开头的记录,这个类比是基于全行键上的,所以rowkey1比r大,所有它被返回了。另外,scan的结果包含了所指范围的STARTROW,但不包含ENDROW,注意,ENDROW不是必须指定的,如果我们执行相同查询只给出了STARTROW,那么我们会得到行键比r大的所有记录。
hbase(main):013:0> scan'PageViews', { STARTROW => 'r' }
ROWCOLUMN+CELL
rowkey1column=info:page, timestamp=1410374788088, value=/mypage
rowkey2column=info:page, timestamp=1410374823590,value=/myotherpage
srowkey2column=info:page,timestamp=1410375975965, value=/myotherpage
3 row(s) in 0.0120secondsHBase是一种NoSQL,通常被称为Hadoop Database,它是开源并基于Google BigTable白皮书,HBase运行在HDFS之上,因此使它具有高度可扩展性,并支持Hadoopmap-reduce程序设计模型。HBase有两种访问方式:通过行键进行随机访问;通过map-reduce脱机或批访问。
关于使用hbase的优点有哪些就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



