假设我们在一台主从机器上配置了200G内存,但是业务需求是需要500G的时候,主从结构+哨兵可以实现高可用故障切换+冗余备份,但是并不能解决数据容量的问题,用哨兵,redis每个实例也是全量存储,每个redis存储的内容都是完整的数据,浪费内存且有木桶效应
为了最大化利用内存,可以采用cluster群集,就是分布式存储。即每台redis存储不同的内容
优点是分区逻辑可控,缺点是需要自己处理数据路由、高可用、故障转移等问题,比如在redis2.8之前通常的做法是获取某个key的hashcode,然后取余分布到不同节点,不过这种做法无法很好的支持动态伸缩性需求,一旦节点的增或者删操作,都会导致key无法在redis中命中
优点是简化客户端分布式逻辑和升级维护便利,缺点是加重架构部署复杂度和性能损耗,比如twemproxy、Codis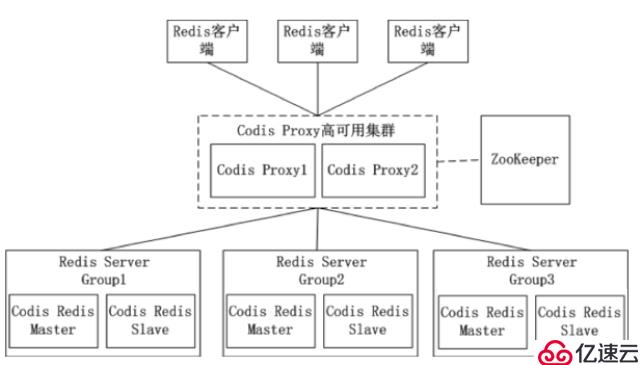
它非常优雅地解决了 Redis 集群方面的问题,部署方便简单,因此理解应用好 Redis Cluster 将极大地解放我们使用分布式 Redis 的工作量。
Redis Cluster 是 Redis 的分布式解决方案,在3.0版本正式推出,有效地解决了 Redis 分布式方面的需求。当遇到单机内存、并发、流量等瓶颈时,可以采用 Cluster 架构方案达到负载均衡的目的
架构图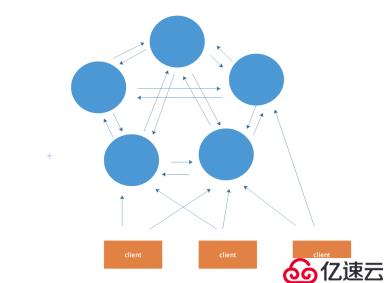
在这个图中,每一个蓝色的圈都代表着一个redis的服务器节点。它们任何两个节点之间都是相互连通的。客户端可以与任何一个节点相连接,然后就可以访问集群中的任何一个节点,对其进行存取和其他操作
Redis 集群提供了以下两个好处:
当集群中的一部分节点失效或者无法进行通讯时, 仍然可以继续处理命令请求的能力,拥有自动故障转移的能力
如果你的数据量很少,主要是承载高并发高性能的场景,比如你的缓存一般就几个G,单机足够了
Replication:一个mater,多个slave,要几个slave跟你的要求的读吞吐量有关系,结合sentinal集群,去保证redis主从架构的高可用性,就可以了
redis cluster:主要是针对海量数据+高并发+高可用的场景,海量数据,如果你的数据量很大,那么建议就用redis cluste
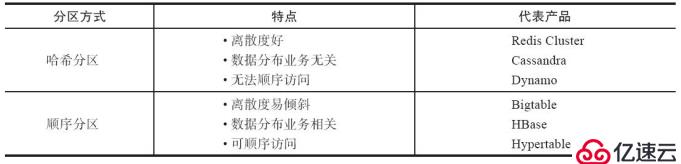
分布式数据库首先要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整体数据的一个子集
顺序分布就是把一整块数据分散到很多机器中,如下图所示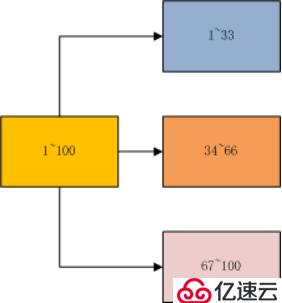
顺序分布一般都是平均分配的
如下图所示,1~100这整块数字,通过 hash 的函数,取余产生的数。这样可以保证这串数字充分的打散,也保证了均匀的分配到各台机器上
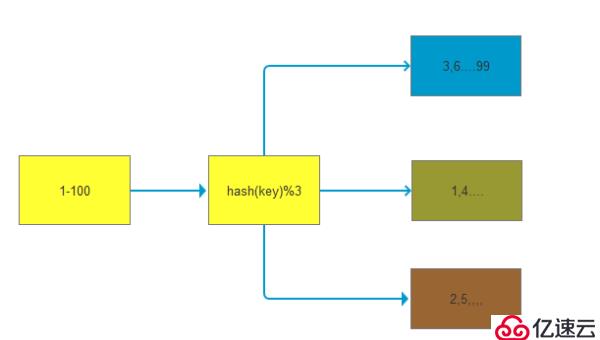
哈希分布和顺序分布只是场景上的适用。哈希分布不能顺序访问,比如你想访问1~100,哈希分布只能遍历全部数据,同时哈希分布因为做了 hash 后导致与业务数据无关了
顺序分布是会导致数据倾斜的,主要是访问的倾斜。每次点击会重点访问某台机器,这就导致最后数据都到这台机器上了,这就是顺序分布最大的缺点
但哈希分布其实是有个问题的,当我们要扩容机器的时候,专业上称之为“节点伸缩”,这个时候,因为是哈希算法,会导致数据迁移
因为redis-cluster使用的就是哈希分区规则所以分析下几种分区形式
使用特定的数据(包括redis的键或用户ID),再根据节点数量N,使用公式:hash(key)%N计算出一个0~(N-1)值,用来决定数据映射到哪一个节点上。即哈希值对节点总数取余。余数x,表示这条数据存放在第(x+1)个节点上。
缺点:当节点数量N变化时(扩容或者收缩),数据和节点之间的映射关系需要重新计算,这样的话,按照新的规则映射,要么之前存储的数据找不到,要么之前数据被重新映射到新的节点(导致以前存储的数据发生数据迁移)
实践:常用于数据库的分库分表规则,一般采用预分区的方式,提前根据数据量规划好分区数,比如划分为512或1024张表,保证可支撑未来一段时间的数据量,再根据负载情况将表迁移到其他数据库中
一致性哈希分区(Distributed Hash Table)实现思路是为系统中每个节点分配一个 token,范围一般在0~232,这些 token 构成一个哈希环。数据读写执行节点查找操作时,先根据 key 计算 hash 值,然后顺时针找到第一个大于等于该哈希值的 token 节点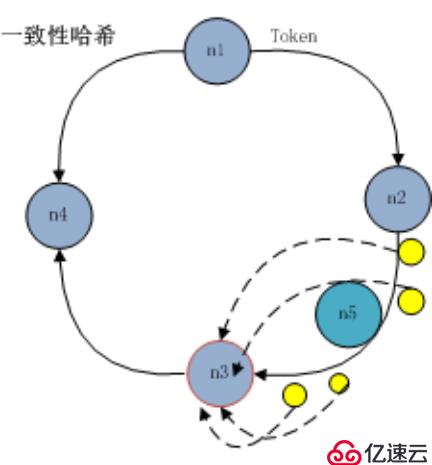
上图就是一个一致性哈希的原理解析。
假设我们有 n1~n4 这四台机器,我们对每一台机器分配一个唯一 token,每次有数据(图中×××代表数据),一致性哈希算法规定每次都顺时针漂移数据,也就是图中×××的数 据都指向 n3。
这个时候我们需要增加一个节点 n5,在 n2 和 n3 之间,数据还是会发生漂移(会偏移到大于等于的节点),但是这个时候你是否注意到,其实只有 n2~n3 这部分的数据被漂移,其他的数据都是不会变的,这种方式相比节点取余最大的好处在于加入和删除节点只影响哈希环中相邻的节点,对其他节点无影响
缺点:每个节点的负载不相同,因为每个节点的hash是根据key计算出来的,换句话说就是假设key足够多,被hash算法打散得非常均匀,但是节点过少,导致每个节点处理的key个数不太一样,甚至相差很大,这就会导致某些节点压力很大
实践:加减节点会造成哈希环中部分数据无法命中,需要手动处理或者忽略这部分数据,因此一致性哈希常用于缓存场景。
虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有数据映射到一个固定范围的整数集合中,整数定义为槽(slot)。这个范围一般远远大于节点数,比如 Redis Cluster 槽范围是0~16383。槽是集群内数据管理和迁移的基本单位。采用大范围槽的主要目的是为了方便数据拆分和集群扩展。每个节点会负责一定数量的槽,下图所示。
当前集群有5个节点,每个节点平均大约负责3276个槽。由于采用高质量的哈希算法,每个槽所映射的数据通常比较均匀,将数据平均划分到5个节点进行数据分区。Redis Cluster 就是采用虚拟槽分区,下面就介绍 Redis 数据分区方法。

每当 key 访问过来,Redis Cluster 会计算哈希值是否在这个区间里。它们彼此都知道对应的槽在哪台机器上,这样就能做到平均分配了
介绍完 Redis 集群分区规则之后,下面我们开始搭建 Redis 集群。搭建集群工作需要以下三个步骤:
| 容器名称 | 容器 IP 地址 | 映射端口号 | 服务运行模式 |
|---|---|---|---|
| redis-master10 | 172.50.0.10 | 6400->6400、16400->16400 | master |
| redis-master11 | 172.50.0.11 | 6401->6401、16401->16401 | master |
| redis-master12 | 172.50.0.12 | 6402->6402 | master |
| redis-slave10 | 172.30.0.10 | 6403->6403 | slave |
| redis-slave11 | 172.30.0.11 | 6404->6404 | slave |
| redis-slave12 | 172.30.0.12 | 6405->6405 | slave |
Redis 集群一般由多个节点组成,节点数量至少为6个才能保证组成完整高可用的集群。每个节点需要开启配置 cluster-enabled yes,让 Redis 运行在集群模式下,上面的配置都相应的给到redis的配置文件当中并启动。
其他配置和单机模式一致即可,配置文件命名规则 redis-{port}.conf,准备好配置后启动所有节点,第一次启动时如果没有集群配置文件,它会自动创建一份,文件名称采用 cluster-config-file 参数项控制,建议采用 node-{port}.conf 格式定义,也就是说会有两份配置文件
当集群内节点信息发生变化,如添加节点、节点下线、故障转移等。节点会自动保存集群状态到配置文件中。需要注意的是,Redis 自动维护集群配置文件,不要手动修改,防止节点重启时产生集群信息错乱
配置文件信息如下:
文件内容记录了集群初始状态,这里最重要的是节点 ID,它是一个40位16进制字符串,用于唯一标识集群内一个节点,节点 ID 在集群初始化时只创建一次,节点重启时会加载集群配置文件进行重用,结合做相应的集群操作,而 Redis 的运行 ID 每次重启都会变化
构建镜像用到的 Dockerfile 信息
FROM centos:latest
MAINTAINER peter "ttone2@vip.qq.com"
RUN groupadd -r redis && useradd -r -g redis redis
RUN yum -y update && yum -y install epel-release \
&& yum -y install redis && yum -y install wget \
&& yum -y install net-tools \
&& yum -y install ruby && yum -y install rubygems
RUN wget https://rubygems.org/downloads/redis-3.2.1.gem && gem install -l ./redis-3.2.1.gem \
&& rm -f redis-3.2.1.gem
COPY ./config/redis-trib.rb /usr/bin
COPY ./config/redis.sh /usr/bin
RUN mkdir -p /config && chmod 775 /usr/bin/redis.sh && chmod 775 /usr/bin/redis-trib.rb创建单独的网络
主节点网卡
docker network create -d bridge --subnet 172.50.0.0/16 redis-cluster_redis-master
从节点网卡
docker network create -d bridge --subnet 172.30.0.0/16 redis-cluster_redis-salve依次执行新建容器命令:
docker run -itd --name redis-master10 -v /home/work/redis-cluster/config/:/config --workdir /config --net redis-cluster_redis-master -e PORT=6400 -p 6400:6400 -p 16400:16400 --ip 172.50.0.10 redis-cluster
docker run -itd --name redis-master11 -v /home/work/redis-cluster/config/:/config --workdir /config --net redis-cluster_redis-master -e PORT=6401 -p 6401:6401 -p 16401:16401 --ip 172.50.0.11 redis-cluster
...
docker run -itd --name redis-slave11 -v /home/work/redis-cluster/config/:/config --workdir /config --net redis-cluster_redis-slave -e PORT=6404 -p 6404:6404 -p 16404:16404 --ip 172.30.0.11 redis-cluster
docker run -itd --name redis-slave12 -v /home/work/redis-cluster/config/:/config --workdir /config --net redis-cluster_redis-slave -e PORT=6405 -p 6405:6405 -p 16405:16405 --ip 172.30.0.12 redis-cluster由于使用的命令行方式创建的,entrypoint和CMD命令没办法得到执行,所以需要进入到每台机器里去开启 Redis 服务.
[root@izuf64gdegum84eku07pljz config]# docker exec -it redis-master11 bash
[root@c101670ac2f4 config]# ./redis.sh &节点握手是指一批运行在集群模式下的节点通过 Gossip 协议彼此通信,达到感知对方的过程。节点握手是集群彼此通信的第一步,由客户端发起命令:cluster meet{ip}{port}
关于Gossip可以看看文章的介绍
通过命令 cluster meet 127.0.0.1 6380让节点6379和6380节点进行握手通信。cluster meet 命令是一个异步命令,执行之后立刻返回。内部发起与目标节点进行握手通信
1)节点6379本地创建6380节点信息对象,并发送 meet 消息
2)节点6380接受到 meet 消息后,保存6379节点信息并回复 pong 消息
3)之后节点6379和6380彼此定期通过 ping/pong 消息进行正常的节点通信
[root@63d7fd48dc81 config]# redis-cli -p 6400
127.0.0.1:6400> cluster meet 47.101.139.0 6401
OK
127.0.0.1:6400> cluster meet 47.101.139.0 6402
OK
127.0.0.1:6400> cluster meet 47.101.139.0 6403
OK
127.0.0.1:6400> cluster meet 47.101.139.0 6404
OK
127.0.0.1:6400> cluster meet 47.101.139.0 6405
OK
127.0.0.1:6400>通过cluster nodes 命令确认6个节点都彼此感知并组成集群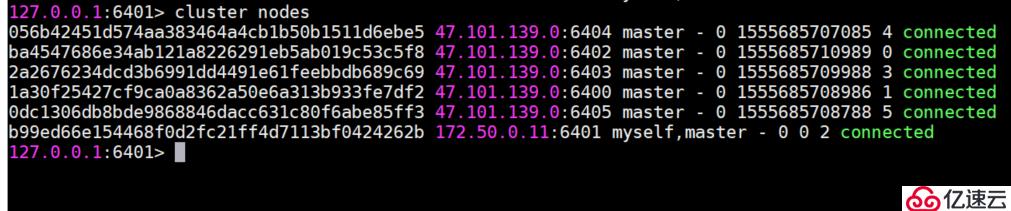
注意:
1、每个Redis Cluster节点会占用两个TCP端口,一个监听客户端的请求,默认是6379,另外一个在前一个端口加上10000,比如16379,来监听数据的请求,节点和节点之间会监听第二个端口,用一套二进制协议来通信。
节点之间会通过套协议来进行失败检测,配置更新,failover认证等等。
为了保证节点之间正常的访问,需要注意防火墙的配置。
2、节点建立握手之后集群还不能正常工作,这时集群处于下线状态,所有的数据读写都被禁止
作为一个完整的集群,需要主从节点,保证当它出现故障时可以自动进行故障转移。集群模式下,Reids 节点角色分为主节点和从节点。
首次启动的节点和被分配槽的节点都是主节点,从节点负责复制主节点槽信息和相关的数据。
使用 cluster replicate {nodeId} 命令让一个节点成为从节点。其中命令执行必须在对应的从节点上执行,将当前节点设置为 node_id 指定的节点的从节点
[root@izuf64gdegum84eku07pljz config]# redis-cli -h 47.101.139.0 -p 6403 cluster replicate 1a30f25427cf9ca0a8362a50e6a313b933fe7df2
[root@izuf64gdegum84eku07pljz config]# redis-cli -h 47.101.139.0 -p 6404 cluster replicate b99ed66e154468f0d2fc21ff4d7113bf0424262b
[root@izuf64gdegum84eku07pljz config]# redis-cli -h 47.101.139.0 -p 6405 cluster replicate ba4547686e34ab121a8226291eb5ab019c53c5f8结果:
127.0.0.1:6401> cluster nodes
056b42451d574aa383464a4cb1b50b1511d6ebe5 47.101.139.0:6404 slave b99ed66e154468f0d2fc21ff4d7113bf0424262b 0 1555686394258 4 connected
ba4547686e34ab121a8226291eb5ab019c53c5f8 47.101.139.0:6402 master - 0 1555686390247 0 connected
2a2676234dcd3b6991dd4491e61feebbdb689c69 47.101.139.0:6403 slave 1a30f25427cf9ca0a8362a50e6a313b933fe7df2 0 1555686394759 3 connected
1a30f25427cf9ca0a8362a50e6a313b933fe7df2 47.101.139.0:6400 master - 0 1555686395260 1 connected
0dc1306db8bde9868846dacc631c80f6abe85ff3 47.101.139.0:6405 slave ba4547686e34ab121a8226291eb5ab019c53c5f8 0 1555686393255 5 connected
b99ed66e154468f0d2fc21ff4d7113bf0424262b 172.50.0.11:6401 myself,master - 0 0 2 connectedRedis 集群把所有的数据映射到16384个槽中。每个 key 会映射为一个固定的槽,只有当节点分配了槽,才能响应和这些槽关联的键命令。通过 cluster addslots 命令为节点分配槽
利用 bash 特性批量设置槽(slots),命令如下:
[root@izuf64gdegum84eku07pljz config]# redis-cli -h 47.101.139.0 -p 6400 cluster addslots {0..5461}
[root@izuf64gdegum84eku07pljz config]# redis-cli -h 47.101.139.0 -p 6401 cluster addslots {5462..10922}
[root@izuf64gdegum84eku07pljz config]# redis-cli -h 47.101.139.0 -p 6402 cluster addslots {10923..16383}主节点的槽信息:
127.0.0.1:6401> cluster nodes
056b42451d574aa383464a4cb1b50b1511d6ebe5 47.101.139.0:6404 slave b99ed66e154468f0d2fc21ff4d7113bf0424262b 0 1555687118050 4 connected
ba4547686e34ab121a8226291eb5ab019c53c5f8 47.101.139.0:6402 master - 0 1555687118550 0 connected 10923-16383
2a2676234dcd3b6991dd4491e61feebbdb689c69 47.101.139.0:6403 slave 1a30f25427cf9ca0a8362a50e6a313b933fe7df2 0 1555687115546 3 connected
1a30f25427cf9ca0a8362a50e6a313b933fe7df2 47.101.139.0:6400 master - 0 1555687117549 1 connected 0-5461
0dc1306db8bde9868846dacc631c80f6abe85ff3 47.101.139.0:6405 slave ba4547686e34ab121a8226291eb5ab019c53c5f8 0 1555687116547 5 connected
b99ed66e154468f0d2fc21ff4d7113bf0424262b 172.50.0.11:6401 myself,master - 0 0 2 connected 5462-10922我们依照 Redis 协议手动建立一个集群。它由6个节点构成,3个主节点负责处理槽和相关数据,3个从节点负责故障转移。手动搭建集群便于理解集群建立的流程和细节,但是我们从中发现集群搭建需要很多步骤,当集群节点众多时,必然会加大搭建集群的复杂度和运维成本。因此 Redis 官方提供了 redis-trib.rb 工具方便我们快速搭建集群
-c 集群模式
[root@izuf64gdegum84eku07pljz config]# redis-cli -c -h 47.101.139.0 -p 6400 set mayun alibaba-996
[root@izuf64gdegum84eku07pljz config]# redis-cli -c -h 47.101.139.0 -p 6400 get mayun
"alibaba-996"如果没有指定集群模式,那么会出现如下错误
[root@izuf64gdegum84eku07pljz config]# redis-cli -h 47.101.139.0 -p 6400 set mayun alibaba-996
(error) MOVED 11165 47.101.139.0:6402所有命令:
CLUSTER info:打印集群的信息
CLUSTER nodes:列出集群当前已知的所有节点(node)的相关信息
CLUSTER meet <ip> <port>:将ip和port所指定的节点添加到集群当中
CLUSTER addslots <slot> [slot ...]:将一个或多个槽(slot)指派(assign)给当前节点
CLUSTER delslots <slot> [slot ...]:移除一个或多个槽对当前节点的指派
CLUSTER slots:列出槽位、节点信息
CLUSTER slaves <node_id>:列出指定节点下面的从节点信息
CLUSTER replicate <node_id>:将当前节点设置为指定节点的从节点
CLUSTER saveconfig:手动执行命令保存保存集群的配置文件,集群默认在配置修改的时候会自动保存配置文件
CLUSTER keyslot <key>:列出key被放置在哪个槽上
CLUSTER flushslots:移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点
CLUSTER countkeysinslot <slot>:返回槽目前包含的键值对数量
CLUSTER getkeysinslot <slot> <count>:返回count个槽中的键
CLUSTER setslot <slot> node <node_id> 将槽指派给指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽,然后再进行指派
CLUSTER setslot <slot> migrating <node_id> 将本节点的槽迁移到指定的节点中
CLUSTER setslot <slot> importing <node_id> 从 node_id 指定的节点中导入槽 slot 到本节点
CLUSTER setslot <slot> stable 取消对槽 slot 的导入(import)或者迁移(migrate)
CLUSTER failover:手动进行故障转移
CLUSTER forget <node_id>:从集群中移除指定的节点,这样就无法完成握手,过期时为60s,60s后两节点又会继续完成握手
CLUSTER reset [HARD|SOFT]:重置集群信息,soft是清空其他节点的信息,但不修改自己的id,hard还会修改自己的id,不传该参数则使用soft方式
CLUSTER count-failure-reports <node_id>:列出某个节点的故障报告的长度
CLUSTER SET-CONFIG-EPOCH:设置节点epoch,只有在节点加入集群前才能设置redis-trib.rb 是采用 Ruby 实现的 Redis 集群管理工具。内部通过 Cluster 相关命令帮我们简化集群创建、检查、槽迁移和均衡等常见运维操作,使用之前需要安装 Ruby 依赖环境。下面介绍搭建集群的详细步骤
内部通过 Cluster 相关命令帮我们简化集群创建、检查、槽迁移和均衡等常见运维操作,使用之前需要安装 Ruby 依赖环境,相关扩展这个在dockerfile文件当中已经写了指令,查看下理解意思就可以了
启动好6个节点之后,使用 redis-trib.rb create 命令完成节点握手和槽分配过程
redis-trib.rb create --replicas 1 47.101.139.0:6400 47.101.139.0:6401 47.101.139.0:6402 47.101.139.0:6403 47.101.139.0:6404 47.101.139.0:6405--replicas 参数指定集群中每个主节点配备几个从节点,这里设置为1,redis-trib.rb 会尽可能保证主从节点不分配在同一机器下,因此会重新排序节点列表顺序。节点列表顺序用于确定主从角色,先主节点之后是从节点。创建过程中首先会给出主从节点角色分配的计划,并且会生成报告
命令说明:
redis-trib.rb help
Usage: redis-trib <command> <options> <arguments ...>
#创建集群
create host1:port1 ... hostN:portN
--replicas <arg> #带上该参数表示是否有从,arg表示从的数量
#检查集群
check host:port
#查看集群信息
info host:port
#修复集群
fix host:port
--timeout <arg>
#在线迁移slot
reshard host:port #个是必传参数,用来从一个节点获取整个集群信息,相当于获取集群信息的入口
--from <arg> #需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递--from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入
--to <arg> #slot需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入。
--slots <arg> #需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入。
--yes #设置该参数,可以在打印执行reshard计划的时候,提示用户输入yes确认后再执行reshard
--timeout <arg> #设置migrate命令的超时时间。
--pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10。
#平衡集群节点slot数量
rebalance host:port
--weight <arg>
--auto-weights
--use-empty-masters
--timeout <arg>
--simulate
--pipeline <arg>
--threshold <arg>
#将新节点加入集群
add-node new_host:new_port existing_host:existing_port
--slave
--master-id <arg>
#从集群中删除节点
del-node host:port node_id
#设置集群节点间心跳连接的超时时间
set-timeout host:port milliseconds
#在集群全部节点上执行命令
call host:port command arg arg .. arg
#将外部redis数据导入集群
import host:port
--from <arg>
--copy
--replace免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





